
Heim >Technologie-Peripheriegeräte >KI >Als Sora die Videogenerierung in Gang setzte, begann Meta unter der Leitung chinesischer Autoren, Agent zu verwenden, um das Video automatisch zu schneiden
Als Sora die Videogenerierung in Gang setzte, begann Meta unter der Leitung chinesischer Autoren, Agent zu verwenden, um das Video automatisch zu schneiden

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-20 15:50:03754Durchsuche
In letzter Zeit hat der Bereich der KI-Videotechnologie viel Aufmerksamkeit erregt, insbesondere das von OpenAI eingeführte große Modell der Sora-Videogeneration, das für breite Diskussionen gesorgt hat. Gleichzeitig haben auch groß angelegte KI-Modelle wie Agent im Bereich der Videobearbeitung starke Stärken gezeigt.
Obwohl für die Bearbeitung von Videobearbeitungsaufgaben natürliche Sprache verwendet wird, können Benutzer ihre Absichten ohne manuelle Vorgänge direkt zum Ausdruck bringen. Allerdings erfordern die meisten aktuellen Videobearbeitungstools immer noch viele manuelle Vorgänge und es mangelt ihnen an personalisierter kontextbezogener Unterstützung. Dies führt dazu, dass Benutzer komplexe Videobearbeitungsprobleme selbst lösen müssen.
Der Schlüssel liegt darin, wie man ein Videobearbeitungstool entwirft, das als Kollaborateur fungieren und Benutzer während des Bearbeitungsprozesses kontinuierlich unterstützen kann? In diesem Artikel schlagen Forscher der University of Toronto, Meta (Reality Labs Research) und der University of California, San Diego vor, die multifunktionalen Sprachfunktionen großer Sprachmodelle (LLM) für die Videobearbeitung zu nutzen und die Zukunft zu erkunden Videobearbeitungsparadigma, wodurch die Frustration mit dem manuellen Videobearbeitungsprozess reduziert wird.

- Papiertitel: LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing
- Papieradresse: https://arxiv.org/pdf/2402.10294.pdf
Research Der Autor hat ein Videobearbeitungstool namens LAVE entwickelt, das mehrere von LLM bereitgestellte Sprachverbesserungsfunktionen integriert. LAVE führt ein intelligentes Planungs- und Ausführungssystem auf Basis von LLM ein, das die Freiform-Sprachanweisungen des Benutzers interpretieren, zugehörige Vorgänge planen und ausführen kann, um die Videobearbeitungsziele des Benutzers zu erreichen. Dieses intelligente System bietet konzeptionelle Unterstützung, wie kreatives Brainstorming und Übersichten über Videomaterial, sowie operative Unterstützung, einschließlich semantikbasierter Videoabfrage, Storyboarding und Clip-Zuschnitt.
Um diese Agenten reibungslos zu betreiben, verwendet LAVE ein visuelles Sprachmodell (VLM), um automatisch Sprachbeschreibungen von visuellen Videoeffekten zu generieren. Diese visuellen Erzählungen ermöglichen es LLM, den Videoinhalt zu verstehen und seine Sprachfähigkeiten zu nutzen, um Benutzer bei der Bearbeitung zu unterstützen. Darüber hinaus bietet LAVE zwei interaktive Videobearbeitungsmodi, nämlich Agentenunterstützung und direkte Bedienung. Dieser Dualmodus bietet Benutzern eine größere Flexibilität, um den Betrieb des Agenten nach Bedarf zu verbessern.
Was den Bearbeitungseffekt von LAVE betrifft? Die Forscher führten eine Benutzerstudie mit 8 Teilnehmern durch, darunter Anfänger und erfahrene Redakteure, und die Ergebnisse zeigten, dass die Teilnehmer LAVE verwenden konnten, um zufriedenstellende kollaborative KI-Videos zu erstellen.
Es ist erwähnenswert, dass fünf der sechs Autoren dieser Studie Chinesen sind, darunter Yi Zuo, Bryan Wang, ein Doktorand der Informatik an der University of Toronto, die Metaforscher Yuliang Li, Zhaoyang Lv und Yan Xu , University of California, San Diego Assistenzprofessor Haijun Xia.
LAVE-Benutzeroberfläche (UI)
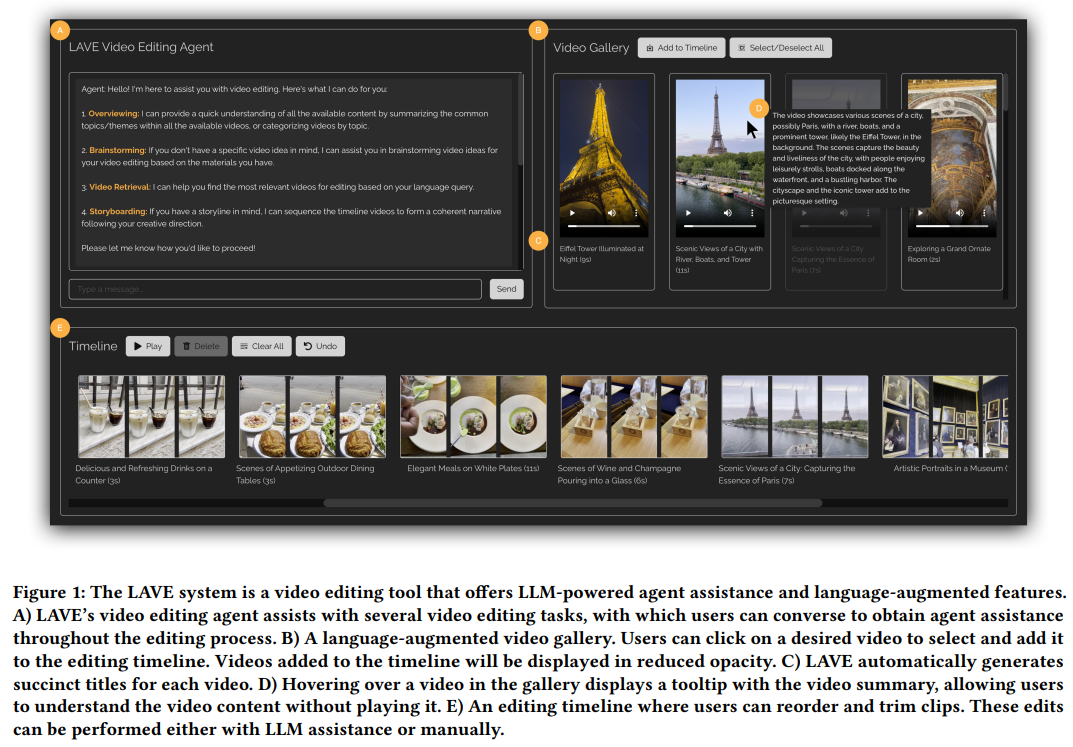
Werfen wir zunächst einen Blick auf das Systemdesign von LAVE, wie in Abbildung 1 unten dargestellt.
Die Benutzeroberfläche von LAVE besteht aus drei Hauptkomponenten:
- Videobibliothek mit erweiterter Sprache, die Videoclips mit automatisch generierten Sprachbeschreibungen anzeigt; Zeitleiste des Clips; der
- Video Clip Agent ermöglicht es dem Benutzer, mit einem Gesprächsagenten zu interagieren und Hilfe von ihm zu erhalten.
- Die Designlogik ist folgende: Wenn der Benutzer mit dem Agenten interagiert, wird der Nachrichtenaustausch in der Chat-Benutzeroberfläche angezeigt. Dabei nimmt der Agent Änderungen an der Videobibliothek und der Clip-Timeline vor. Darüber hinaus können Benutzer die Videobibliothek und die Timeline direkt mit dem Cursor bedienen, ähnlich wie bei herkömmlichen Bearbeitungsoberflächen.
 Videobibliothek zur Sprachverbesserung
Videobibliothek zur Sprachverbesserung
Die Funktionen der Videobibliothek zur Sprachverbesserung sind in Abbildung 3 unten dargestellt.
Wie herkömmliche Tools ermöglicht diese Funktion die Wiedergabe von Clips, bietet jedoch visuelle Kommentare, d. h. automatisch generierte Textbeschreibungen für jedes Video, einschließlich semantischer Titel und Zusammenfassungen. Die Titel helfen dabei, die Clips zu verstehen und zu indizieren, und die Zusammenfassungen bieten einen Überblick über den visuellen Inhalt jedes Clips und helfen Benutzern, die Handlung ihres Bearbeitungsprojekts zu gestalten. Unter jedem Video werden ein Titel und eine Dauer angezeigt.
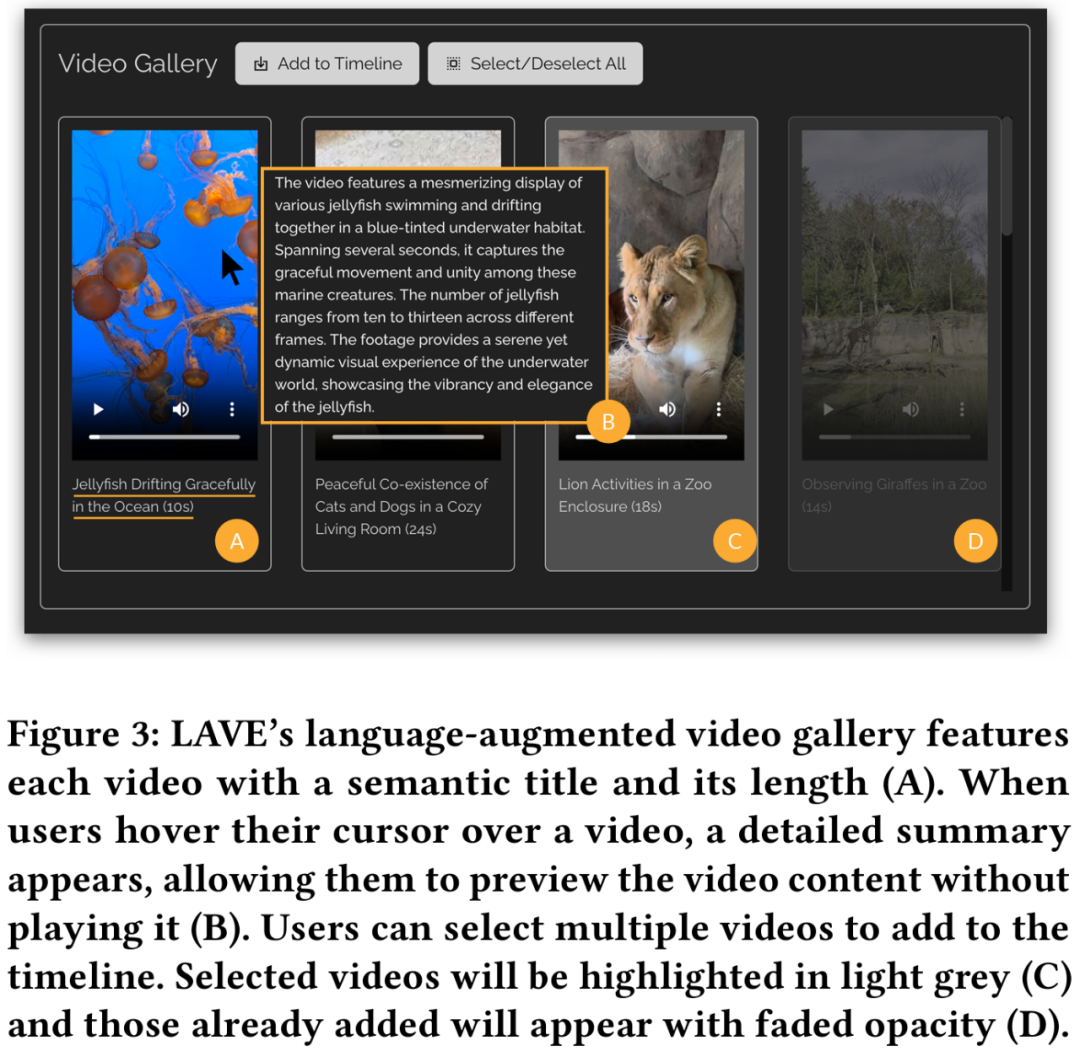
Darüber hinaus ermöglicht LAVE Benutzern die Suche nach Videos mithilfe semantischer Sprachabfragen. Die abgerufenen Videos werden in der Videobibliothek angezeigt und nach Relevanz sortiert. Diese Funktion muss vom Clip Agent ausgeführt werden.
Videoclip-Zeitleiste
Nachdem Sie Videos aus der Videobibliothek ausgewählt und zur Clip-Zeitleiste hinzugefügt haben, werden sie auf der Videoclip-Zeitleiste am unteren Rand der Benutzeroberfläche angezeigt, wie in Abbildung 2 unten dargestellt . Jeder Clip auf der Timeline wird durch ein Feld dargestellt und zeigt drei Miniaturbilder an: das Startbild, das mittlere Bild und das Endbild.
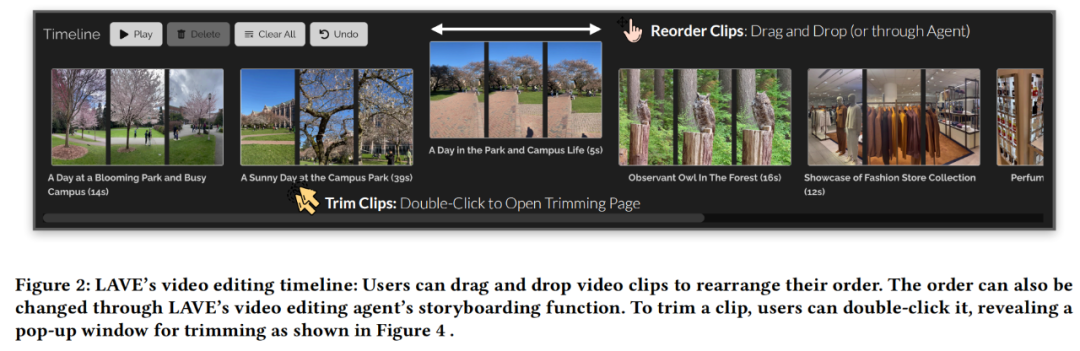
Im LAVE-System repräsentiert jedes Miniaturbild eine Sekunde Material im Clip. Wie bei der Videogalerie werden für jeden Clip ein Titel und eine Beschreibung bereitgestellt. Die Clip-Timeline in LAVE verfügt über zwei Hauptfunktionen: Clip-Sortierung und -Trimmen.
Das Anordnen von Clips auf der Timeline ist eine häufige Aufgabe bei der Videobearbeitung und wichtig für die Erstellung einer zusammenhängenden Erzählung. LAVE unterstützt zwei Sortiermethoden, die auf der Storyboard-Funktion des Videoclip-Agenten basieren. Die andere ist die manuelle Sortierung, bei der jede Videobox per Drag-and-Drop sortiert wird Clips erscheinen.
Zuschneiden ist auch bei der Videobearbeitung wichtig, um wichtige Segmente hervorzuheben und überschüssigen Inhalt zu entfernen. Beim Zuschneiden doppelklickt der Benutzer auf den Clip in der Timeline, wodurch ein Popup-Fenster mit einsekündigen Frames geöffnet wird, wie in Abbildung 4 unten dargestellt.

Video Clip Agent
Der Video Clip Agent von LAVE ist eine chatbasierte Komponente, die die Interaktion zwischen Benutzern und LLM-basierten Agenten erleichtert. Im Gegensatz zu Befehlszeilentools können Benutzer mithilfe einer Freiformsprache mit Agenten interagieren. Der Agent nutzt die sprachliche Intelligenz von LLM, um Unterstützung bei der Videobearbeitung bereitzustellen und spezifische Antworten bereitzustellen, um den Benutzer durch den gesamten Bearbeitungsprozess zu führen und zu unterstützen. Die Agentenassistenzfunktionalität von LAVE wird durch Agentenoperationen bereitgestellt, bei denen jeweils eine systemgestützte Bearbeitungsfunktion ausgeführt wird.
Im Allgemeinen decken die von LAVE bereitgestellten Funktionen den gesamten Arbeitsablauf von der Ideenfindung und Vorplanung bis hin zu den eigentlichen Bearbeitungsvorgängen ab, das System schreibt jedoch keinen strikten Arbeitsablauf vor. Benutzer haben die Flexibilität, Teilmengen der Funktionalität zu nutzen, die ihren Bearbeitungszielen entsprechen. Beispielsweise können Benutzer mit einer klaren redaktionellen Vision und einer klaren Handlung die Ideenfindungsphase umgehen und direkt mit der Bearbeitung beginnen.
Backend-System
Diese Studie verwendet OpenAIs GPT-4, um das Design des LAVE-Backend-Systems zu veranschaulichen, das hauptsächlich zwei Aspekte umfasst: Agentendesign und Implementierung von Bearbeitungsfunktionen, die von LLM gesteuert werden.
Agentendesign
Diese Forschung nutzt die vielfältigen Sprachfunktionen von LLM (d. h. GPT-4), einschließlich Argumentation, Planung und Geschichtenerzählen, um den LAVE-Agenten zu erstellen.
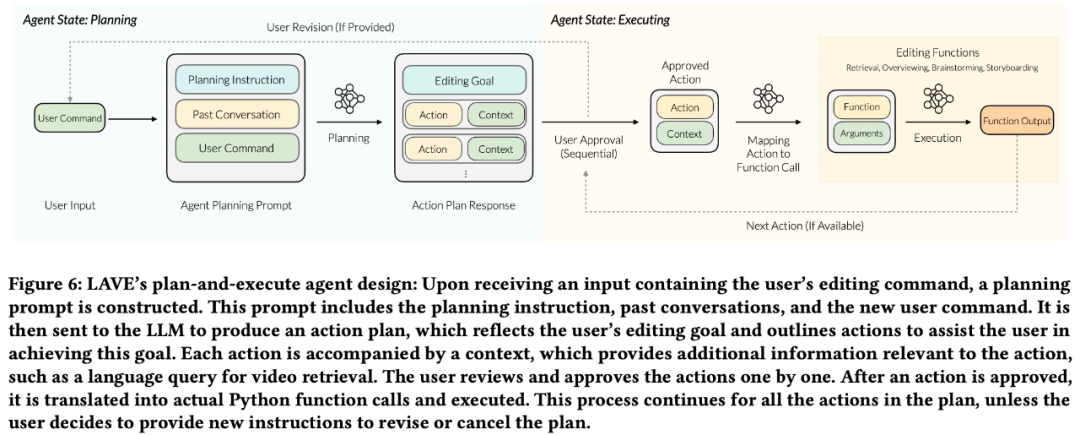
LAVE-Agent hat zwei Zustände: Planung und Ausführung. Dieses Setup hat zwei Hauptvorteile:
- ermöglicht es Benutzern, übergeordnete Ziele festzulegen, die mehrere Aktionen umfassen, sodass nicht wie bei herkömmlichen Befehlszeilentools jede einzelne Aktion detailliert beschrieben werden muss.
- Vor der Ausführung präsentiert der Agent dem Benutzer den Plan, bietet Möglichkeiten zur Änderung und stellt sicher, dass der Benutzer die volle Kontrolle über den Betrieb des Agenten hat. Das Forschungsteam entwarf eine Back-End-Pipeline, um den Planungs- und Ausführungsprozess abzuschließen.
Wie in Abbildung 6 unten dargestellt, erstellt die Pipeline zunächst einen Aktionsplan basierend auf Benutzereingaben. Der Plan wird dann von einer textuellen Beschreibung in Funktionsaufrufe umgewandelt und die entsprechenden Funktionen werden dann ausgeführt.
Implementierung von LLM-gesteuerten Bearbeitungsfunktionen
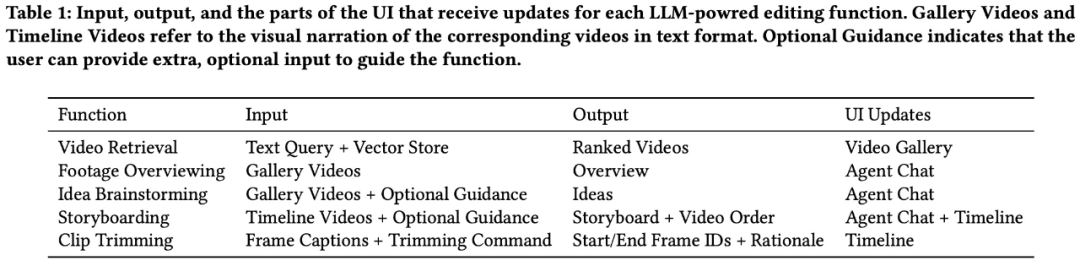
Um Benutzern bei der Erledigung von Videobearbeitungsaufgaben zu helfen, unterstützt LAVE hauptsächlich fünf LLM-gesteuerte Funktionen, darunter:
- Materialübersicht
- Kreatives Brainstorming
- Videoabruf
- Storyboard
- Clip-Zuschnitt
Die ersten vier davon können Der Zugriff erfolgt über den Agenten (Abbildung 5). Mit der Clip-Trimmfunktion können Sie durch Doppelklicken auf den Clip in der Timeline ein Popup-Fenster mit einsekündigen Frames öffnen (Abbildung 4).

Davon wird der sprachbasierte Videoabruf über eine Vektorspeicherdatenbank implementiert, und der Rest wird über LLM-Prompt-Engineering implementiert. Alle Funktionen basieren auf automatisch generierten verbalen Beschreibungen des Originalmaterials, einschließlich Titeln und Zusammenfassungen für jeden Clip in der Videobibliothek (Abbildung 3). Das Forschungsteam bezeichnet die Textbeschreibungen dieser Videos als visuelle Erzählung.

Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonAls Sora die Videogenerierung in Gang setzte, begann Meta unter der Leitung chinesischer Autoren, Agent zu verwenden, um das Video automatisch zu schneiden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wo ist der E-Mail-Speicherort von Foxmail?
- Mit welcher Software können AI-Dateien geöffnet und bearbeitet werden?
- Was bedeutet Cai Computer?
- Was ist der Unterschied zwischen Raid 0 1 5 10
- Das KI-Unternehmen Runway Video Editor Gen-2 startet eine kostenlose Testversion und kann Videos basierend auf Aufforderungswörtern erstellen