
Heim >Technologie-Peripheriegeräte >KI >Großes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen
Großes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-20 15:10:19801Durchsuche
Als Reaktion auf die weiterhin wachsende Nachfrage nach 3D-Kreativwerkzeugen im Metaverse zeigten die Menschen in letzter Zeit großes Interesse an der dreidimensionalen Inhaltsgenerierung (3D AIGC). Gleichzeitig hat die Erstellung von 3D-Inhalten erhebliche Fortschritte in Qualität und Geschwindigkeit gemacht.
Obwohl aktuelle generative Feed-Forward-Modelle 3D-Objekte in Sekundenschnelle generieren können, ist ihre Auflösung durch die intensive Berechnung, die während des Trainings erforderlich ist, begrenzt, was zur Generierung von Inhalten von geringer Qualität führt. Da stellt sich die Frage: Kann ein hochauflösendes, qualitativ hochwertiges 3D-Objekt in nur 5 Sekunden generiert werden?

In diesem Artikel schlugen Forscher der Peking-Universität, des S-Lab der Nanyang Technological University und des Shanghai Artificial Intelligence Laboratory ein „neues LGM-Framework“ vor, nämlich das Large Gaussian Model, das die Transformation von Einzelansichtsbildern realisiert Oder Texteingabe, um in nur 5 Sekunden hochauflösende und hochwertige dreidimensionale Objekte zu generieren.
Derzeit sind sowohl der Code als auch die Modellgewichte Open Source. Die Forscher stellen außerdem eine Online-Demo zur Verfügung, die jeder ausprobieren kann.

- Papiertitel: LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
- Projekthomepage: https://me.kiui.moe/lgm/
- Code : https://github.com/3DTopia/LGM
- Papier: https://arxiv.org/abs/2402.05054
- Online-Demo: https://huggingface.co/spaces/ashawkey/LGM
- Effiziente 3D-Darstellung bei begrenztem Rechenaufwand: Bestehende 3D-Generierungsarbeiten verwenden NeRF basierend auf drei Ebenen als 3D-Darstellung und Rendering Pipeline, die intensive Modellierung von Szenen und die Raytracing-Volumenrendering-Technologie schränken die Trainingsauflösung (128 x 128) erheblich ein, wodurch die Textur des endgültig generierten Inhalts verschwommen und von schlechter Qualität ist.
- 3D-Backbone-Generierungsnetzwerk mit hoher Auflösung: Bestehende 3D-Generierungsarbeiten verwenden dichte Transformatoren als Backbone-Netzwerk, um sicherzustellen, dass die Parametermenge dicht genug ist, um universelle Objekte zu modellieren, was jedoch bis zu einem gewissen Grad geopfert wird Die Trainingsauflösung Dies führt zu einer geringen Qualität des endgültigen dreidimensionalen Objekts.
vorhandenen Text für Mehransichtsbilder oder einzelne Bilder für Mehransichtsbildmodelle zu verwenden . Unterstützt hochwertige Text-zu-3D- und Bild-zu-3D-Aufgaben .
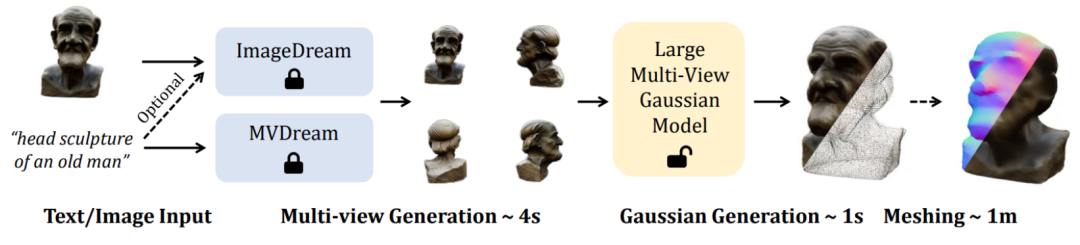
LGM-Kernmodul ein großes Multi-View-Gauß-Modell. Inspiriert durch Gaußsches Sputtern verwendet diese Methode ein effizientes und leichtes asymmetrisches U-Net als Backbone-Netzwerk, um hochauflösende Gaußsche Grundelemente aus Bildern mit vier Ansichten direkt vorherzusagen und schließlich Bilder aus jedem Blickwinkel zu rendern.
Konkret akzeptiert das Backbone-Netzwerk U-Net Bilder aus vier Perspektiven und entsprechenden Plucker-Koordinaten und gibt eine feste Anzahl von Gaußschen Merkmalen aus mehreren Perspektiven aus. Dieser Satz Gaußscher Merkmale wird direkt mit dem endgültigen Gaußschen Element verschmolzen und durch differenzierbares Rendern werden Bilder aus verschiedenen Betrachtungswinkeln erhalten.In diesem Prozess wird ein ansichtsübergreifender Selbstaufmerksamkeitsmechanismus verwendet, um eine Korrelationsmodellierung zwischen verschiedenen Ansichten auf Feature-Maps mit niedriger Auflösung zu implementieren und gleichzeitig einen geringen Rechenaufwand aufrechtzuerhalten.
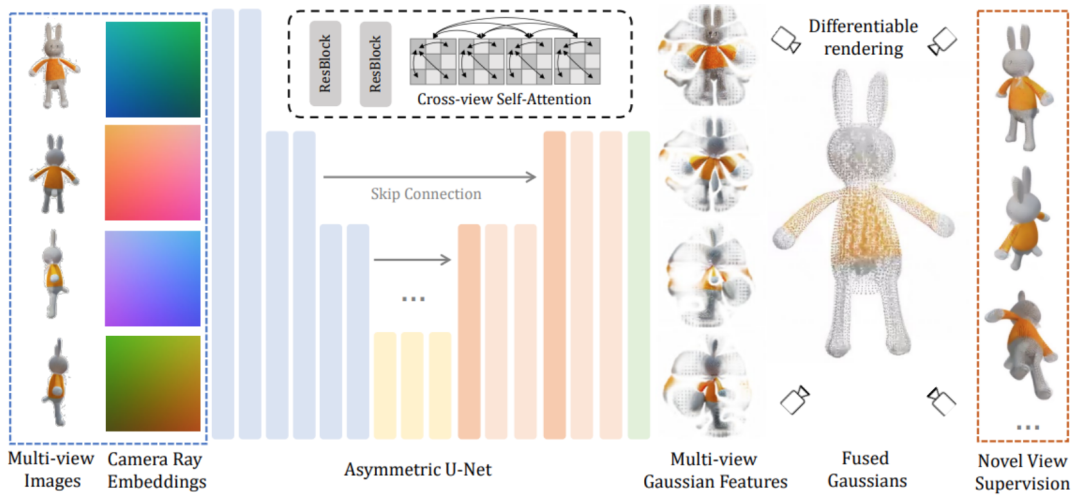
Zuerst werden die im objaversen Datensatz gerenderten dreidimensionalen konsistenten Mehransichtsbilder in der Trainingsphase verwendet, während in der Inferenzphase vorhandene Modelle direkt verwendet werden, um Mehrperspektivenbilder aus Text oder Bildern zu synthetisieren. Da auf der Grundlage des Modells synthetisierte Multi-View-Bilder immer das Problem der Multi-View-Inkonsistenz haben, wird in diesem Artikel eine auf Gitterverzerrung basierende Datenverbesserungsstrategie vorgeschlagen, um die Lücke in diesem Bereich zu schließen: Anwenden von Randomisierung auf die Bilder aus drei Ansichten im Bildraum Verzerrung, um Multi-View-Inkonsistenz zu simulieren. Zweitens: Da die in der Inferenzphase erzeugten Mehransichtsbilder die Konsistenz der dreidimensionalen Geometrie der Kameraperspektive nicht unbedingt garantieren, werden in diesem Artikel auch die Kamerapositionen der drei Perspektiven zufällig gestört, um dieses Phänomen zu simulieren , damit das Modell beim Denken eine bessere Leistung erbringen kann. Die Bühne ist stabiler . Nach Abschluss des Trainings kann LGM mithilfe des vorhandenen Bild-zu-Mehrfachansicht- oder Text-zu-Mehrfachansicht-Diffusionsmodells qualitativ hochwertige Text-zu-3D- und Bild-zu-3D-Aufgaben erfüllen.


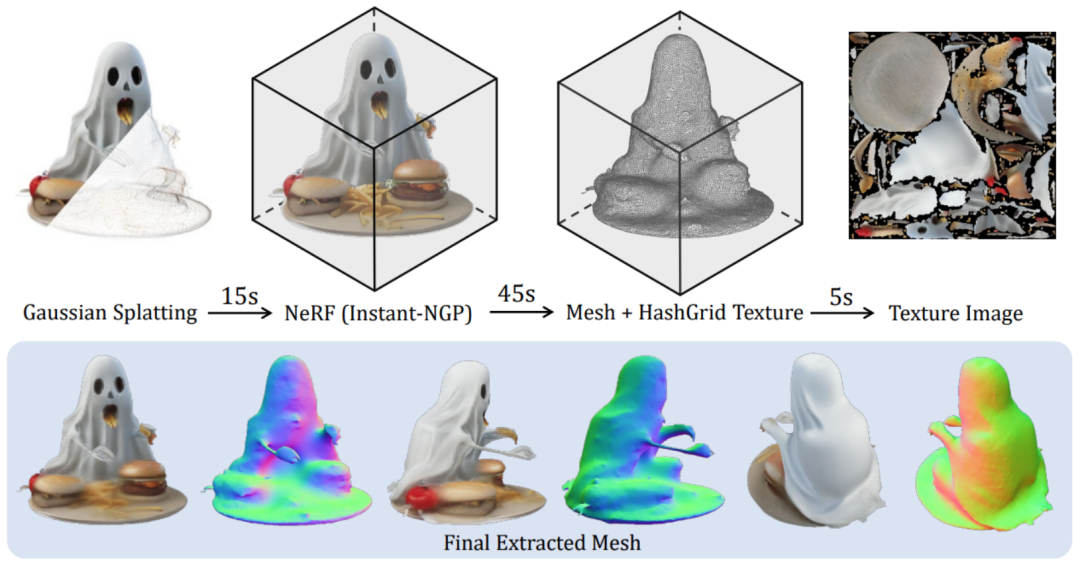
Das obige ist der detaillierte Inhalt vonGroßes Multi-View-Gauß-Modell LGM: Erzeugt hochwertige 3D-Objekte in 5 Sekunden, verfügbar zum Testen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So implementieren Sie die Funktion „Contains' in Python-Strings
- Was ist KI-Technologie?
- Der Vorabend, an dem AIGC Inhalte für das Metaverse produziert
- Um die Entwicklung der Yuanverse-Branche zu unterstützen, wurde dieser Wettbewerb für innovative mobile Kommunikationsanwendungen ins Leben gerufen
- AIGC gestaltet die metaverse Inhaltsökologie neu, Baidu Xirang läutete den Moment des „großen Modells' ein