
Heim >System-Tutorial >LINUX >Verwenden Sie Python, um die gesamten Videoinformationen von Station B zu crawlen
Verwenden Sie Python, um die gesamten Videoinformationen von Station B zu crawlen

- 王林nach vorne
- 2024-02-19 23:45:35792Durchsuche
Ich denke, jeder kennt Station B. Tatsächlich gibt es viele Suchanfragen auf der Crawler-Website von Station B. Allerdings ist das, was ich auf dem Papier lese, letztendlich oberflächlich, und ich weiß definitiv, dass ich es im Detail tun muss, also bin ich hier. Am Ende betrug die Gesamtmenge der gecrawlten Daten 7,6 Millionen .
Vorbereitung
Öffnen Sie zunächst Station B, suchen Sie ein Video auf der Homepage und klicken Sie darauf. Öffnen Sie für den Normalbetrieb die Entwicklertools. Dieses Mal besteht das Ziel darin, Videoinformationen durch Crawlen der von Station B bereitgestellten API zu erhalten, ohne die Webseite zu analysieren. Die Geschwindigkeit beim Parsen der Webseite ist zu langsam und die IP-Adresse wird leicht blockiert.
Überprüfen Sie die JS-Option und drücken Sie F5 zum Aktualisieren
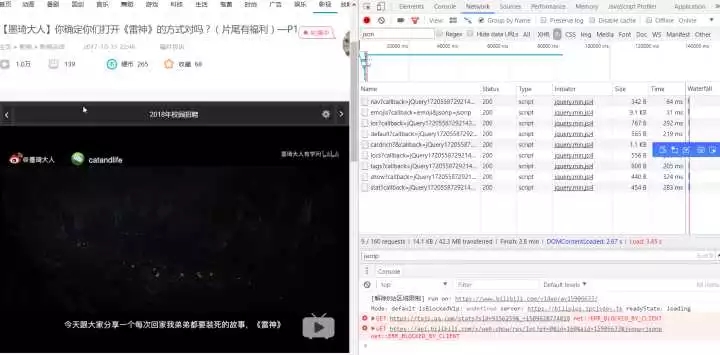
API-Adresse gefunden
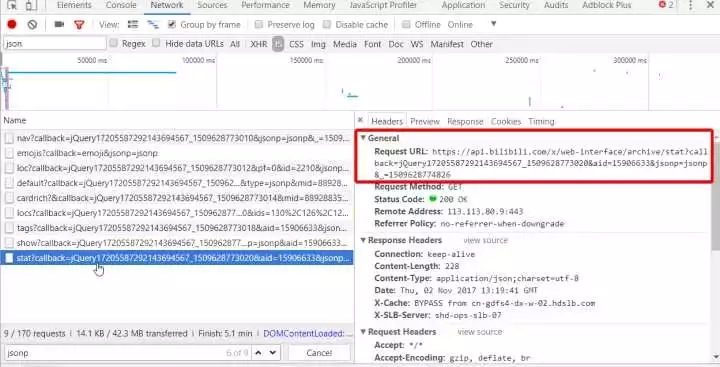
Kopieren Sie es, entfernen Sie unnötigen Inhalt und rufen Sie https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633 ab. Öffnen Sie es mit einem Browser und Sie erhalten die folgenden JSON-Daten
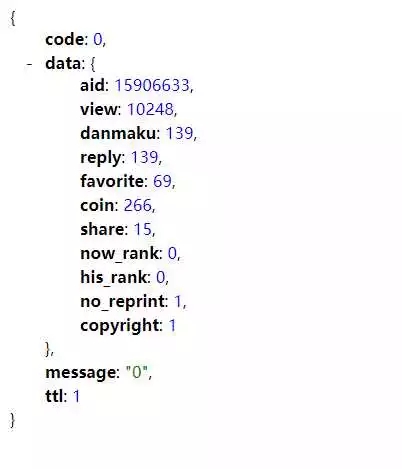
Okay, jetzt kann der Code durch kontinuierliche Iteration per Anfrage abgerufen werden. Um den Crawler effizienter zu machen, kann Multithreading verwendet werden.
Kerncode
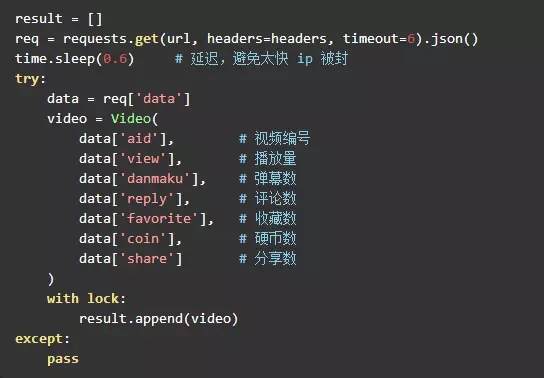
 Der wichtigste Teil des gesamten Projekts besteht aus etwa 20 Codezeilen, was recht prägnant ist.
Der wichtigste Teil des gesamten Projekts besteht aus etwa 20 Codezeilen, was recht prägnant ist.
Der Laufeffekt ist ungefähr so. Die Anzahl gibt an, wie viele Links tatsächlich gecrawlt wurden.
 Was die Verarbeitung nach dem Crawlen angeht, hängt es von Ihren Vorlieben ab. Ich speichere es zuerst als CSV-Datei und fasse es dann zusammen und füge es in die Datenbank ein.
Was die Verarbeitung nach dem Crawlen angeht, hängt es von Ihren Vorlieben ab. Ich speichere es zuerst als CSV-Datei und fasse es dann zusammen und füge es in die Datenbank ein.
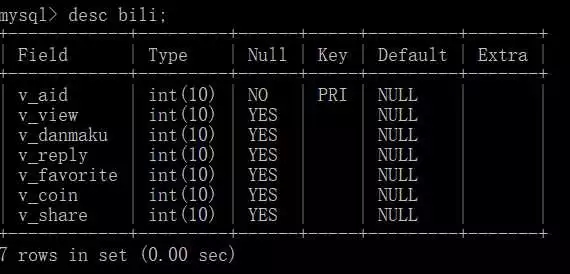 Da ich diesen Inhalt vor ein paar Monaten gecrawlt habe, liegen die Daten tatsächlich etwas zurück.
Da ich diesen Inhalt vor ein paar Monaten gecrawlt habe, liegen die Daten tatsächlich etwas zurück.
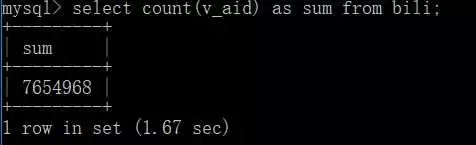
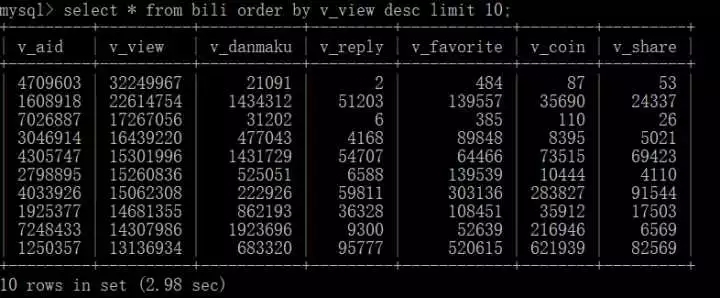
Das obige ist der detaillierte Inhalt vonVerwenden Sie Python, um die gesamten Videoinformationen von Station B zu crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!