
Heim >Technologie-Peripheriegeräte >KI >LeCun warf Sora wütend vor, dass sie die physische Welt nicht verstehen könne! Metas erstes KI-Video „World Model' V-JEPA
LeCun warf Sora wütend vor, dass sie die physische Welt nicht verstehen könne! Metas erstes KI-Video „World Model' V-JEPA

- 王林nach vorne
- 2024-02-19 09:27:07893Durchsuche
Sora wurde sofort nach seinem Erscheinen zum Top-Trend und die Popularität des Themas nahm nur noch zu.
Die leistungsstarke Fähigkeit, realistische Videos zu erstellen, hat viele Menschen dazu gebracht, auszurufen: „Die Realität existiert nicht mehr.“
Sogar der technische Bericht von OpenAI zeigte, dass Sora die physische Welt in Bewegung tiefgreifend verstehen kann und als wahres „Weltmodell“ bezeichnet werden kann.

Und auch Turing-Gigant LeCun, der sich schon immer auf das „Weltmodell“ als Forschungsschwerpunkt konzentriert hat, war an dieser Debatte beteiligt.
Der Grund dafür ist, dass Internetnutzer die Ansichten ausgegraben haben, die LeCun vor ein paar Tagen auf dem WGS-Gipfel geäußert hat: „In Bezug auf KI-Videos wissen wir nicht, was wir tun sollen.“
Er glaubt, dass die Erstellung realistischer Videos, die ausschließlich auf Textaufforderungen basieren, nicht gleichbedeutend damit ist, dass das Modell die physische Welt versteht. Der Ansatz zur Videogenerierung unterscheidet sich stark von Modellen der Welt, die auf kausalen Vorhersagen basieren.

Als nächstes erklärte LeCun ausführlicher:
Obwohl es viele Arten von Videos gibt, die man sich vorstellen kann, muss das Videogenerierungssystem nur „ein“ vernünftiges Beispiel erstellen, um erfolgreich zu sein.
Für ein echtes Video gibt es relativ wenige sinnvolle Folgeentwicklungspfade. Insbesondere unter konkreten Handlungsbedingungen ist es deutlich schwieriger, repräsentative Teile dieser Möglichkeiten zu generieren.
Außerdem ist die Generierung von Folgeinhalten für diese Videos nicht nur teuer, sondern eigentlich sinnlos.
Ein idealerer Ansatz besteht darin, eine „abstrakte Darstellung“ dieser nachfolgenden Inhalte zu erstellen und dabei Szenendetails zu entfernen, die für die von uns möglicherweise ergriffenen Maßnahmen irrelevant sind.
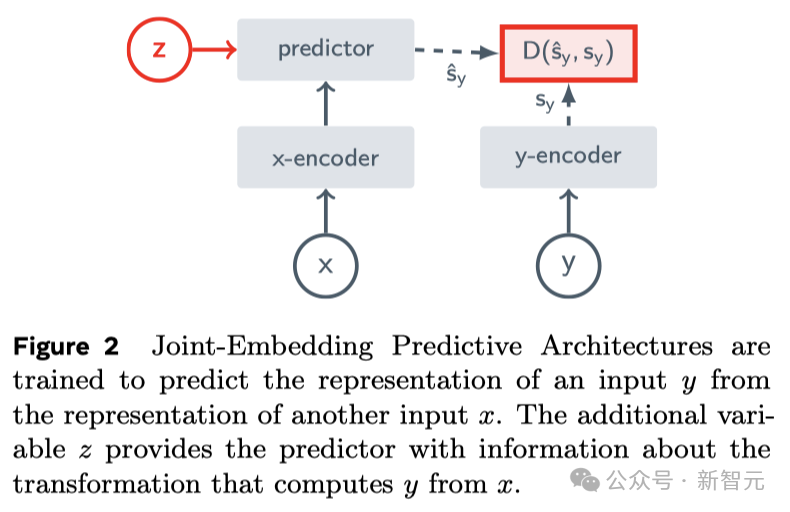
Dies ist die Kernidee von JEPA (Joint Embedding Prediction Architecture). Sie ist nicht generativ, sondern prognostiziert im Darstellungsraum.
Dann nutzte er seine eigene Forschung zu VICReg, I-JEPA, V-JEPA und die Arbeit anderer, um Folgendes zu beweisen:
und die generative Architektur zur Pixelrekonstruktion, wie z. B. Variational Autoencoder (Variational AE), mask Im Vergleich zu Masked AE, Denoising AE usw. kann die „gemeinsame Einbettungsarchitektur“ einen besseren visuellen Eingabeausdruck erzeugen.
Wenn die erlernte Darstellung als Eingabe für den überwachten Kopf in nachgelagerten Aufgaben verwendet wird (ohne Feinabstimmung des Rückgrats), übertrifft die gemeinsame Einbettungsarchitektur die generative Architektur.
Am Tag der Veröffentlichung des Sora-Modells startete Meta ein neues unbeaufsichtigtes „Videovorhersagemodell“ – V-JEPA.
Seit LeCun JEPA erstmals im Jahr 2022 erwähnte, verfügen I-JEPA und V-JEPA über starke Vorhersagefähigkeiten basierend auf Bildern bzw. Videos.
Es behauptet, in der Lage zu sein, die Welt auf „menschliche Art und Weise zu verstehen“ zu sehen und durch abstrakte und effiziente Vorhersagen verdeckte Teile zu generieren.

Papieradresse: https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
V-JEPA Wann Zur Aktion kommt es im Video unten, dort heißt es „Zerreiße das Papier in zwei Hälften.“

Ein weiteres Beispiel: Wenn ein Teil des Videos, das Sie ansehen, blockiert ist, kann V-JEPA unterschiedliche Vorhersagen über den Inhalt des Notebooks treffen.

Es ist erwähnenswert, dass dies die Superkraft ist, die V-JEPA nach dem Ansehen von 2 Millionen Videos erworben hat.
Experimentelle Ergebnisse zeigen, dass nur durch das Lernen von Videomerkmalsvorhersagen eine „effiziente visuelle Darstellung“ erhalten werden kann, die auf der Grundlage der Aktions- und Erscheinungsbeurteilung auf verschiedene Aufgaben anwendbar ist und keine Anpassung der Modellparameter erfordert.
ViT-H/16 erreichte basierend auf dem V-JEPA-Training hohe Werte von 81,9 %, 72,2 % bzw. 77,9 % bei den Benchmarks Kinetics-400, SSv2 und ImageNet1K.
Nachdem V-JEPA 2 Millionen Videos angesehen hat, versteht er die Welt
Das Verständnis des Menschen für die Welt um ihn herum, insbesondere in den frühen Lebensphasen, wird größtenteils durch „Beobachtung“ erlangt.
Nehmen Sie Newtons „Drittes Gesetz der Bewegung“ als Beispiel: Selbst ein Baby oder eine Katze kann natürlich verstehen, dass jedes Objekt irgendwann herunterfällt.
Dieses Verständnis erfordert keine langfristige Anleitung oder das Lesen einer großen Anzahl von Büchern.
Es ist ersichtlich, dass Ihr inneres Weltmodell – ein Situationsverständnis, das auf dem Weltverständnis des Geistes basiert – diese Ergebnisse vorhersagen und äußerst effektiv sein kann.
Yann LeCun sagte, dass V-JEPA ein wichtiger Schritt hin zu einem tieferen Verständnis der Welt sei, mit dem Ziel, Maschinen in die Lage zu versetzen, umfassender zu denken und zu planen.

Im Jahr 2022 schlug er erstmals die Joint Embedding Prediction Architecture (JEPA) vor.
Unser Ziel ist es, fortschrittliche maschinelle Intelligenz (AMI) aufzubauen, die wie Menschen lernen kann, indem sie lernt, sich anpasst und effizient plant, um komplexe Aufgaben zu lösen, indem sie interne Modelle der Welt um sie herum erstellt.

V-JEPA: Nicht-generatives Modell
Völlig anders als das generative KI-Modell Sora ist V-JEPA ein „nicht-generatives Modell“.
Es lernt, indem es versteckte oder fehlende Teile des Videos in einer abstrakten Raumdarstellung vorhersagt.
Dies ähnelt der Image Joint Embedding Prediction Architecture (I-JEPA), die durch den Vergleich abstrakter Darstellungen von Bildern lernt, anstatt direkt „Pixel“ zu vergleichen.
Im Gegensatz zu generativen Methoden, die versuchen, jedes fehlende Pixel zu rekonstruieren, ist V-JEPA in der Lage, schwer vorhersehbare Informationen zu verwerfen. Dieser Ansatz erreicht eine 1,5- bis 6-fache Verbesserung der Trainings- und Probeneffizienz.
V-JEPA verwendet eine selbstüberwachte Lernmethode und verlässt sich beim Vortraining vollständig auf unbeschriftete Daten.
Erst nach dem Vortraining kann das Modell durch Kennzeichnung der Daten an die spezifische Aufgabe angepasst werden.
Daher ist diese Architektur effizienter als frühere Modelle, sowohl im Hinblick auf die Anzahl der erforderlichen beschrifteten Proben als auch auf die Investition in das Lernen aus unbeschrifteten Daten.
Beim Einsatz von V-JEPA blockierten die Forscher den Großteil des Videoinhalts und zeigten nur einen sehr kleinen Teil des „Kontexts“.
Dann wird der Prädiktor gebeten, den fehlenden Inhalt zu ergänzen – nicht durch bestimmte Pixel, sondern in Form einer abstrakteren Beschreibung, um den Inhalt in diesem Darstellungsraum zu ergänzen.
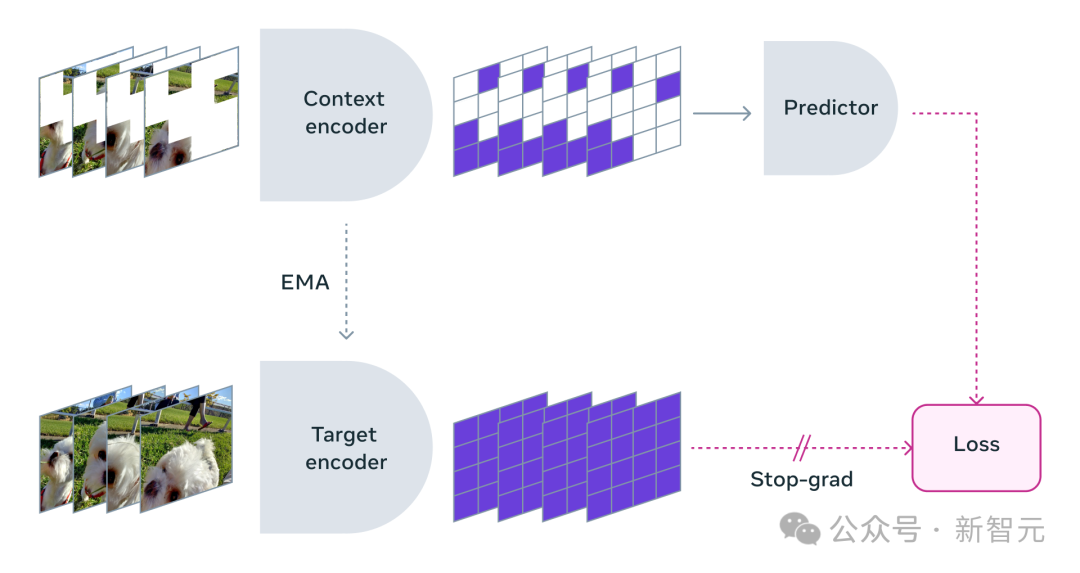
V-JEPA trainiert den visuellen Encoder, indem es versteckte räumlich-zeitliche Regionen im erlernten latenten Raum vorhersagt.
Maskenmethode
V-JEPA ist nicht darauf ausgelegt, bestimmte Arten von Aktionen zu verstehen.
Stattdessen lernte es viel darüber, wie die Welt funktioniert, indem es selbstüberwachtes Lernen auf verschiedene Videos anwendete.
Meta-Forscher haben außerdem sorgfältig eine Maskierungsstrategie entwickelt:
Wenn Sie die meisten Bereiche des Videos nicht blockieren, sondern nur zufällig einige kleine Fragmente auswählen, wird die Lernaufgabe zu einfach und das Modell kann keine komplexen Informationen über die Welt lernen.
Auch hier ist es wichtig zu beachten, dass sich die Dinge in den meisten Videos im Laufe der Zeit weiterentwickeln.
Wenn Sie in kurzer Zeit nur einen kleinen Teil des Videos maskieren, damit das Modell sehen kann, was vorher und nachher passiert ist, verringert sich auch die Lernschwierigkeit und es wird für das Modell schwieriger, interessante Inhalte zu lernen .
Daher wählten die Forscher den Ansatz, Teile des Videos sowohl räumlich als auch zeitlich zu maskieren und so das Modell zu zwingen, die Szene zu lernen und zu verstehen.
Effiziente Vorhersage ohne Feinabstimmung
Die Vorhersage in einem abstrakten Darstellungsraum ist von entscheidender Bedeutung, da sie es dem Modell ermöglicht, sich auf übergeordnete Konzepte des Videoinhalts zu konzentrieren, ohne sich um Details kümmern zu müssen, deren Umsetzung normalerweise unwichtig ist die Aufgabe.
Wenn ein Video einen Baum zeigen würde, wären Ihnen die winzigen Bewegungen jedes Blattes wahrscheinlich egal.
Was Meta-Forscher wirklich begeistert, ist, dass V-JEPA das erste Videomodell ist, das bei der „eingefrorenen Auswertung“ gut abschneidet.
Einfrieren bedeutet, dass nach Abschluss des gesamten selbstüberwachten Vortrainings am Encoder und Prädiktor keine Änderungen mehr vorgenommen werden.
Wenn wir das Modell zum Erlernen neuer Fähigkeiten benötigen, fügen wir einfach eine kleine, spezialisierte Ebene oder ein Netzwerk hinzu, was effizient und schnell ist.
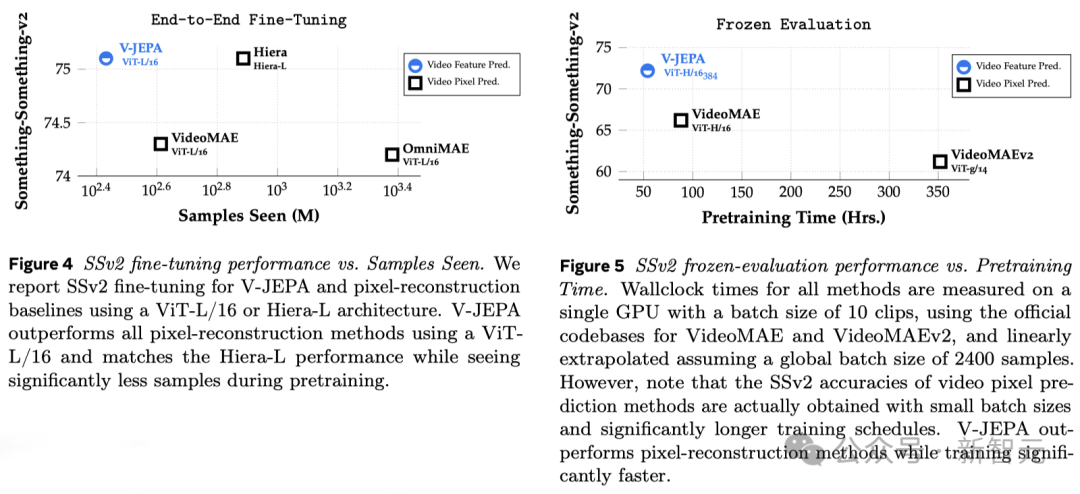
Frühere Forschungen erforderten außerdem eine umfassende Feinabstimmung, d Das Modell muss noch verfeinert werden.
Um es ganz klar auszudrücken: Das fein abgestimmte Modell kann sich nur auf eine bestimmte Aufgabe konzentrieren und sich nicht an andere Aufgaben anpassen.
Wenn Sie möchten, dass das Modell verschiedene Aufgaben lernt, müssen Sie die Daten ändern und spezielle Anpassungen am gesamten Modell vornehmen.
Die Forschung von V-JEPA zeigt, dass es möglich ist, das Modell in einem Durchgang vorab zu trainieren, ohne sich auf gekennzeichnete Daten zu verlassen, und das Modell dann für mehrere verschiedene Aufgaben zu verwenden, wie z. B. Aktionsklassifizierung und feinkörnige Objektinteraktionserkennung und Aktivitätslokalisierung, was neue Möglichkeiten eröffnet.

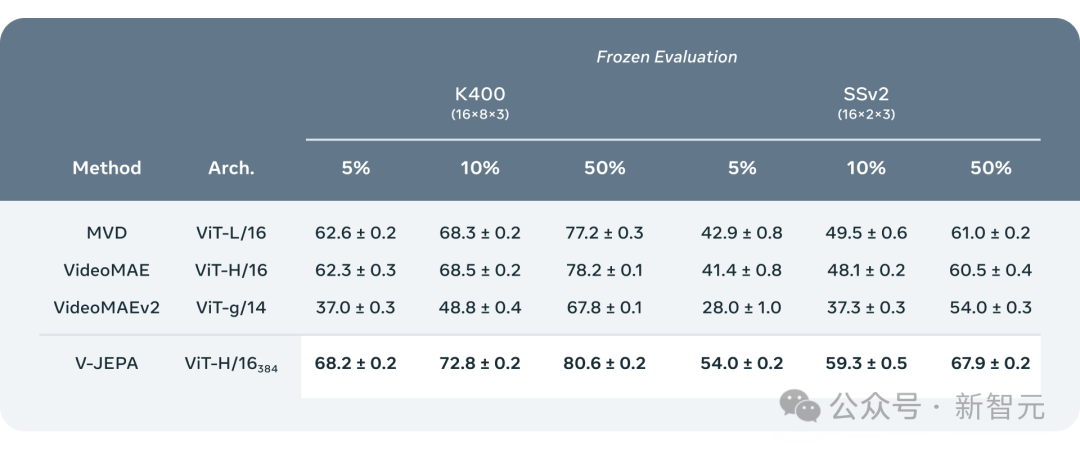
- Few-shot Frozen Evaluation
Die Forscher verglichen V-JEPA mit anderen Videoverarbeitungsmodellen und legten dabei besonderes Augenmerk auf die Leistung, wenn die Daten weniger annotiert sind.
Sie wählten zwei Datensätze aus, Kinetics-400 und Something-Something-v2, und beobachteten die Leistung des Modells bei der Verarbeitung von Videos, indem sie den Anteil der für das Training verwendeten markierten Proben anpassten (jeweils 5 %, 10 % und 50 %). ). Wirksamkeit.
Um die Zuverlässigkeit der Ergebnisse sicherzustellen, wurden bei jedem Verhältnis 3 unabhängige Tests durchgeführt und der Durchschnitt und die Standardabweichung berechnet.
Die Ergebnisse zeigen, dass V-JEPA hinsichtlich der Effizienz der Annotationsnutzung besser ist als andere Modelle. Insbesondere wenn die verfügbaren Annotationsbeispiele für jede Kategorie reduziert werden, wird der Leistungsunterschied zwischen V-JEPA und anderen Modellen deutlicher.

Neue Richtung für zukünftige Forschung: visuelle + akustische Vorhersage
Obwohl das „V“ von V-JEPA für Video steht, konzentrierte es sich bisher hauptsächlich auf die Analyse der „visuellen Elemente“ von Videos .
Natürlich besteht Metas nächste Forschungsrichtung darin, eine multimodale Methode einzuführen, die „visuelle und akustische Informationen“ in Videos gleichzeitig verarbeiten kann.
Als Proof-of-Concept-Modell eignet sich V-JEPA hervorragend zur Identifizierung subtiler Objektinteraktionen in Videos.
Zum Beispiel unterscheiden zu können, ob jemand den Stift weglegt, den Stift aufhebt oder vorgibt, den Stift wegzulegen, ihn aber nicht tatsächlich weglegt.
Diese hochstufige Bewegungserkennung funktioniert jedoch gut für kurze Videoclips (einige Sekunden bis 10 Sekunden).
Daher liegt ein weiterer Schwerpunkt des nächsten Forschungsschritts darauf, wie das Modell über einen längeren Zeitraum planen und vorhersagen kann.
„Weltmodell“ geht noch einen Schritt weiter
Bisher haben sich Metaforscher, die V-JEPA verwenden, hauptsächlich auf die „Wahrnehmung“ konzentriert – das Verstehen der Echtzeitsituation der umgebenden Welt durch die Analyse von Videostreams.
In dieser gemeinsamen eingebetteten Vorhersagearchitektur fungiert der Prädiktor als vorläufiges „physisches Weltmodell“, das uns allgemein sagen kann, was im Video passiert.
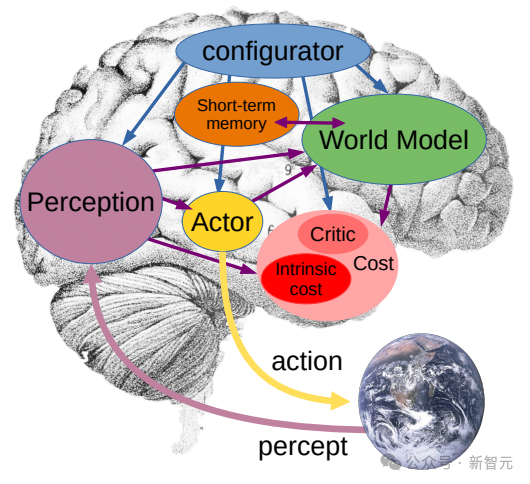
Das nächste Ziel von Meta ist es zu zeigen, wie dieser Prädiktor oder dieses Weltmodell für die Planung und kontinuierliche Entscheidungsfindung verwendet werden kann.
Wir wissen bereits, dass das JEPA-Modell durch das Beobachten von Videos trainiert werden kann, ähnlich wie ein Baby, das die Welt beobachtet, und ohne starke Aufsicht viel lernen kann.
Auf diese Weise kann das Modell mit nur einer geringen Menge an gekennzeichneten Daten schnell neue Aufgaben erlernen und verschiedene Aktionen erkennen.
Langfristig wird das starke Situationsverständnis von V-JEPA für die Entwicklung der verkörperten KI-Technologie und zukünftiger Augmented-Reality-Brillen (AR) in zukünftigen Anwendungen von großer Bedeutung sein.
Denken Sie jetzt darüber nach: Wenn Apple Vision Pro mit dem „Weltmodell“ gesegnet werden kann, wird es noch unbesiegbarer.
Netizen-Diskussion
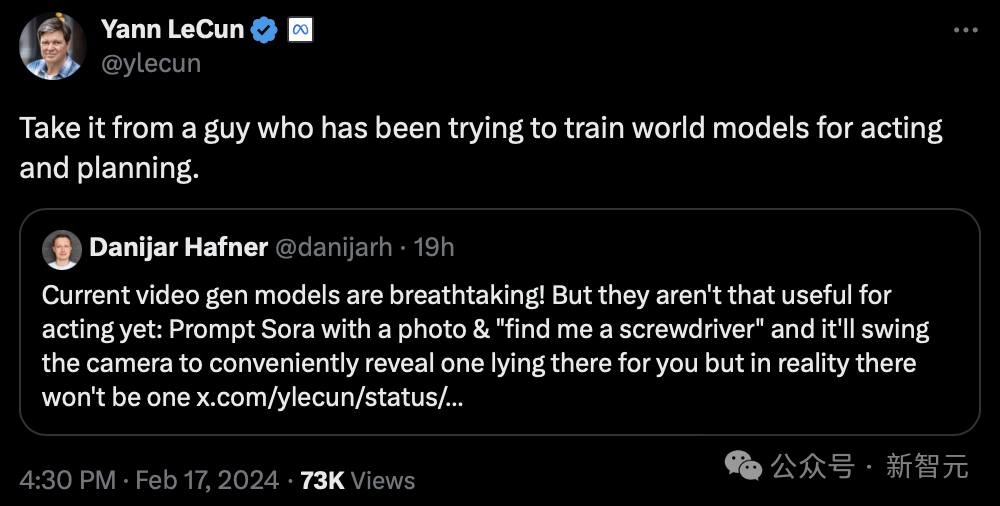
Offensichtlich ist LeCun nicht optimistisch, was generative KI angeht.

„Hören Sie den Rat von jemandem, der versucht hat, ein „Weltmodell“ für Präsentation und Planung zu trainieren.“
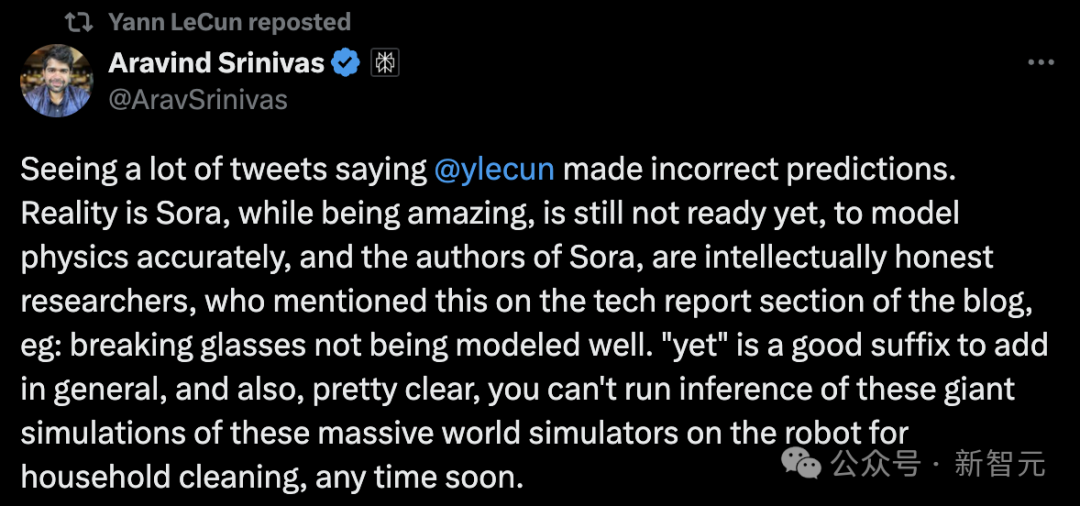
CEO von Perplexity AI sagte:
Sora ist zwar erstaunlich, aber nicht bereit, die Physik genau zu modellieren. Und der Autor von Sora war sehr schlau und erwähnte dies im Abschnitt „Technische Berichte“ des Blogs, dass zerbrochenes Glas nicht gut modelliert werden kann.
Es ist offensichtlich, dass die auf einer solch komplexen Weltsimulation basierenden Überlegungen kurzfristig nicht sofort auf einem Heimroboter ausgeführt werden können.
Tatsächlich ist eine sehr wichtige Nuance, die viele Menschen nicht verstehen, diese:
Die Generierung scheinbar interessanter Inhalte in Text oder Video bedeutet nicht (und erfordert auch nicht), dass man den Inhalt versteht“. Du erzeugst. Ein Agentenmodell, das in der Lage ist, auf Verständnis basierende Schlussfolgerungen zu ziehen, muss definitiv außerhalb großer Modelle oder Diffusionsmodelle liegen.

Aber einige Internetnutzer sagten: „So lernen Menschen nicht.“
„Wir erinnern uns nur an etwas Einzigartiges aus unseren vergangenen Erfahrungen und verlieren dabei alle Details. Wir können die Umgebung auch jederzeit und überall modellieren (Darstellungen erstellen), weil wir sie wahrnehmen. Der wichtigste Teil der Intelligenz ist die Verallgemeinerung von Veränderungen.“

Andere behaupten, es handele sich immer noch um eine Einbettung des interpolierten Latentraums, und man könne bisher auf diese Weise kein „Weltmodell“ aufbauen.

Können Sora und V-JEPA die Welt wirklich verstehen? Was denken Sie?
Das obige ist der detaillierte Inhalt vonLeCun warf Sora wütend vor, dass sie die physische Welt nicht verstehen könne! Metas erstes KI-Video „World Model' V-JEPA. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!