
Heim >System-Tutorial >LINUX >Wie wird die CPU-Auslastung unter Linux berechnet?
Wie wird die CPU-Auslastung unter Linux berechnet?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-15 11:15:111326Durchsuche
Beim Beobachten des Betriebsstatus von Online-Diensten auf einem Online-Server verwenden die meisten Leute gerne zuerst den oberen Befehl, um die Gesamt-CPU-Auslastung des aktuellen Systems zu sehen. Für eine Zufallsmaschine lauten die vom Befehl top angezeigten Auslastungsinformationen beispielsweise wie folgt:

Dieses Ausgabeergebnis ist gelinde gesagt einfach, aber es ist nicht so einfach, alles zu verstehen, auch wenn es komplex ist. Zum Beispiel:
Frage 1: Wie werden die von top ausgegebenen Nutzungsinformationen berechnet?
Frage 2: Die ni-Spalte gibt den CPU-Overhead bei der Verarbeitung aus?
Frage 3: wa steht für io wait. Ist die CPU also während dieser Zeit beschäftigt oder im Leerlauf?
Heute haben wir eine ausführliche Studie zur CPU-Auslastungsstatistik. Durch die heutige Studie werden Sie nicht nur die Implementierungsdetails der CPU-Auslastungsstatistik verstehen, sondern auch ein tieferes Verständnis für Indikatoren wie „nice“ und „io wait“ erhalten.
Heute beginnen wir mit unseren eigenen Gedanken!
1. Denken Sie zuerst darüber nach
Wenn Sie die Linux-Implementierung einmal außer Acht lassen, verfügen Sie, wenn Sie die folgenden Anforderungen haben, über einen Quad-Core-Server, auf dem vier Prozesse laufen.
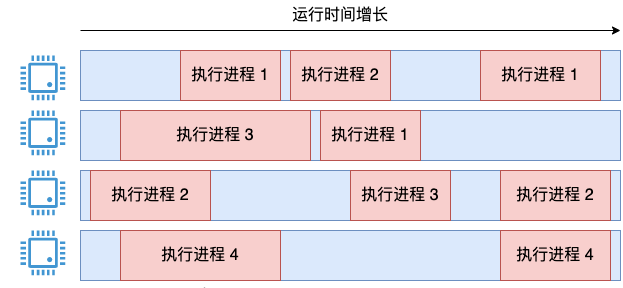
Ermöglicht das Entwerfen und Berechnen der CPU-Auslastung des gesamten Systems. Es unterstützt die Ausgabe wie der Top-Befehl und erfüllt die folgenden Anforderungen:
- Die CPU-Auslastung sollte so genau wie möglich sein
- Es ist notwendig, den aktuellen CPU-Status so weit wie möglich auf der zweiten Ebene widerzuspiegeln.
Du kannst ein paar Minuten innehalten und nachdenken.

Okay, Schluss mit dem Nachdenken. Wenn Sie darüber nachdenken, werden Sie feststellen, dass diese scheinbar einfache Anforderung tatsächlich etwas kompliziert ist.
Eine Idee besteht darin, die Ausführungszeit aller Prozesse zu addieren und sie dann durch die gesamte Systemausführungszeit * 4 zu dividieren.
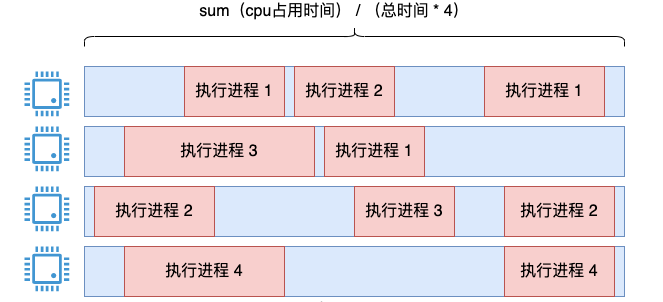
Mit dieser Idee ist es kein Problem, mit dieser Methode die CPU-Auslastung über einen längeren Zeitraum zu zählen, und die Statistiken sind genau genug.
Aber solange Sie top verwendet haben, wissen Sie, dass die von top ausgegebene CPU-Auslastung nicht über einen längeren Zeitraum konstant ist, sondern standardmäßig in Einheiten von 3 Sekunden dynamisch aktualisiert wird (dieses Zeitintervall kann mit -d eingestellt werden). ). Unsere Lösung kann die Gesamtauslastung widerspiegeln, es ist jedoch schwierig, diesen momentanen Zustand abzubilden. Du denkst vielleicht, dass ich es alle 3 Sekunden als eins zählen kann, oder? Aber ab wann beginnt dieser 3-Sekunden-Zeitraum? Die Granularität ist schwer zu kontrollieren.
Der Kern der vorherigen Denkfrage besteht darin, wie man unmittelbare Probleme löst. Wenn es um den Übergangszustand geht, haben Sie vielleicht eine andere Idee. Dann nutze ich das Instant Sampling, um zu sehen, wie viele Kerne gerade ausgelastet sind. Sind zwei der vier Kerne ausgelastet, liegt die Auslastung bei 50 %.
Diese Denkweise geht auch in die richtige Richtung, aber es gibt zwei Probleme:
- Die von Ihnen berechneten Zahlen sind alle Vielfache von 25 %;
- Dieser Momentanwert kann zu starken Schwankungen in der CPU-Auslastungsanzeige führen.
Zum Beispiel das Bild unten:
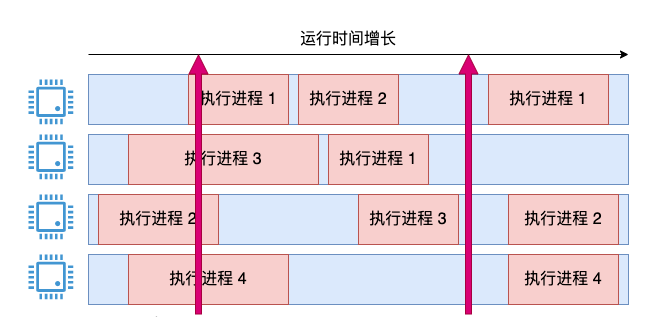
Aus dem momentanen Zustand von t1 beträgt die CPU-Auslastung des Systems zweifellos 100 %, aber aus der Perspektive von t2 beträgt die Auslastung 0 %. Die Idee geht in die richtige Richtung, aber offensichtlich kann diese grobe Rechnung nicht so elegant funktionieren wie das Oberkommando.
Lassen Sie es uns verbessern und die beiden oben genannten Ideen kombinieren, vielleicht können wir unser Problem lösen. In Bezug auf die Stichprobe legen wir den Zeitraum feiner fest, in Bezug auf die Berechnung legen wir den Zeitraum jedoch gröber fest.
Wir führen das Konzept des Einführungszeitraums und des Timings ein, z. B. die Probenahme alle 1 Millisekunde. Wenn die CPU zum Zeitpunkt der Abtastung läuft, wird diese 1 ms als verbraucht erfasst. Zu diesem Zeitpunkt wird eine momentane CPU-Auslastung ermittelt und gespeichert.
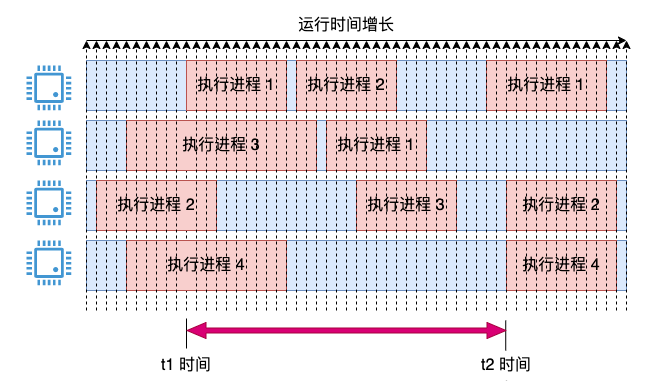
Beim Zählen der CPU-Auslastung innerhalb von 3 Sekunden, z. B. im Zeitbereich t1 und t2 im Bild oben. Addieren Sie dann alle Momentanwerte während dieses Zeitraums und bilden Sie einen Durchschnitt. Dadurch kann das obige Problem gelöst werden, die Statistik ist relativ genau und das Problem, dass der Momentanwert stark schwankt und zu grobkörnig ist (kann sich nur in Einheiten von 25 % ändern), wird vermieden.
Einige Schüler fragen sich vielleicht, was passiert, wenn sich die CPU zwischen zwei Stichproben ändert, wie im Bild unten gezeigt.
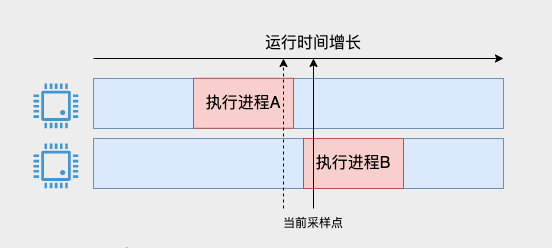
Wenn der aktuelle Abtastpunkt eintrifft, wurde die Ausführung von Prozess A gerade erst abgeschlossen. Er wurde vom vorherigen Abtastpunkt nicht gezählt und kann dieses Mal auch nicht gezählt werden. Bei Prozess B wurde er tatsächlich nur für kurze Zeit gestartet. Es scheint etwas zu viel zu sein, alle 1 ms aufzuzeichnen.
Dieses Problem besteht zwar, aber da unsere Abtastung einmal 1 ms beträgt und wir sie tatsächlich überprüfen und verwenden, befindet sie sich mindestens auf der zweiten Ebene, die Informationen von Tausenden von Abtastpunkten enthält, sodass dieser Fehler nicht auftritt beeinflussen unser Verständnis der Gesamtsituation.
Tatsächlich zählt Linux auf diese Weise die CPU-Auslastung des Systems. Obwohl es Fehler geben kann, reicht es aus, als statistische Daten verwendet zu werden. In Bezug auf die Implementierung akkumuliert Linux alle Momentanwerte in bestimmten Daten, anstatt tatsächlich viele Kopien der Momentandaten zu speichern.
Als nächstes betreten wir Linux, um die spezifische Implementierung der System-CPU-Auslastungsstatistiken zu sehen.
2. Wo sind die Nutzungsdaten von Top Command? Die im vorherigen Abschnitt erwähnte Implementierung von Linux besteht darin, Momentanwerte zu bestimmten Daten zu akkumulieren. Dieser Wert wird vom Kernel über die Pseudodatei /proc/stat dem Benutzerstatus ausgesetzt. Linux verwendet es bei der Berechnung der CPU-Auslastung des Systems.
Insgesamt sind die internen Details der Top-Befehlsarbeit in der folgenden Abbildung dargestellt.
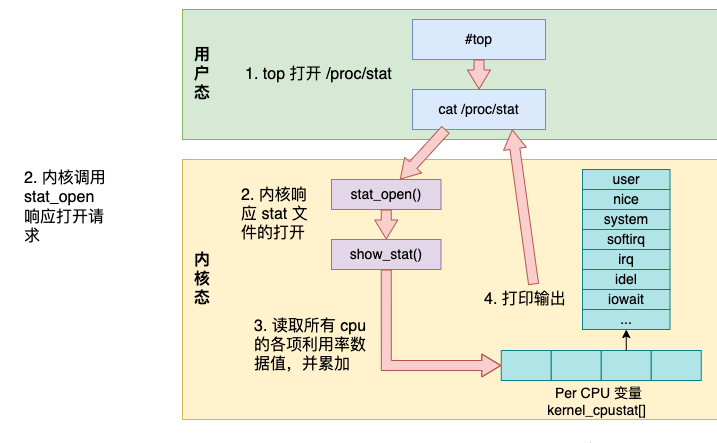
- top-Befehl greift auf /proc/stat zu, um verschiedene CPU-Auslastungswerte zu erhalten
- Der Kernel ruft die Funktion stat_open auf, um den Zugriff auf /proc/stat;
- zu verwalten Die Daten, auf die der Kernel zugreift, stammen aus dem Array kernel_cpustat und werden zusammengefasst
- Ausgabe im Benutzermodus drucken.
- Als nächstes wollen wir jeden Schritt näher erläutern und einen genaueren Blick darauf werfen.
Indem Sie strace verwenden, um die verschiedenen Systemaufrufe des Top-Befehls zu verfolgen, können Sie dessen Aufrufe an die Datei sehen.
# strace top ... openat(AT_FDCWD, "/proc/stat", O_RDONLY) = 4 openat(AT_FDCWD, "/proc/2351514/stat", O_RDONLY) = 8 openat(AT_FDCWD, "/proc/2393539/stat", O_RDONLY) = 8 ...
“Zusätzlich zu /proc/stat gibt es auch /proc/{pid}/stat, aufgeschlüsselt nach jedem Prozess, der zur Berechnung der CPU-Auslastung jedes Prozesses verwendet wird.
“Der Kernel definiert Verarbeitungsfunktionen für jede Pseudodatei. Die Verarbeitungsmethode der Datei /proc/stat ist proc_stat_operations.
//file:fs/proc/stat.c
static int __init proc_stat_init(void)
{
proc_create("stat", 0, NULL, &proc_stat_operations);
return 0;
}
static const struct file_operations proc_stat_operations = {
.open = stat_open,
...
};
proc_stat_operations enthält die dieser Datei entsprechenden Operationsmethoden. Wenn die Datei /proc/stat geöffnet wird, wird stat_open aufgerufen. stat_open ruft nacheinander single_open_size und show_stat auf, um den Dateninhalt auszugeben. Werfen wir einen Blick auf den Code:
//file:fs/proc/stat.c
static int show_stat(struct seq_file *p, void *v)
{
u64 user, nice, system, idle, iowait, irq, softirq, steal;
for_each_possible_cpu(i) {
struct kernel_cpustat *kcs = &kcpustat_cpu(i);
user += kcs->cpustat[CPUTIME_USER];
nice += kcs->cpustat[CPUTIME_NICE];
system += kcs->cpustat[CPUTIME_SYSTEM];
idle += get_idle_time(kcs, i);
iowait += get_iowait_time(kcs, i);
irq += kcs->cpustat[CPUTIME_IRQ];
softirq += kcs->cpustat[CPUTIME_SOFTIRQ];
...
}
//转换成节拍数并打印出来
seq_put_decimal_ull(p, "cpu ", nsec_to_clock_t(user));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(system));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq));
...
}
Im obigen Code durchläuft for_each_possible_cpu die Variable kcpustat_cpu, die CPU-Nutzungsdaten speichert. Bei dieser Variablen handelt es sich um eine Percpu-Variable, die für jeden logischen Kern ein Array-Element vorbereitet. Es speichert verschiedene Ereignisse, die dem aktuellen Kern entsprechen, einschließlich Benutzer, Nice, System, Idel, Iowait, IRQ, Softirq usw.
In dieser Schleife addieren Sie jede Nutzung jedes Kerns. Schließlich werden die Daten über seq_put_decimal_ull ausgegeben.
Beachten Sie, dass im Kernel jede Zeit tatsächlich in Nanosekunden aufgezeichnet wird, bei der Ausgabe jedoch alle in Beat-Einheiten umgewandelt werden. Was die Länge der Beat-Einheit betrifft, werden wir sie im nächsten Abschnitt vorstellen. Kurz gesagt, die Ausgabe von /proc/stat wird aus der Percpu-Variablen kernel_cpustat gelesen.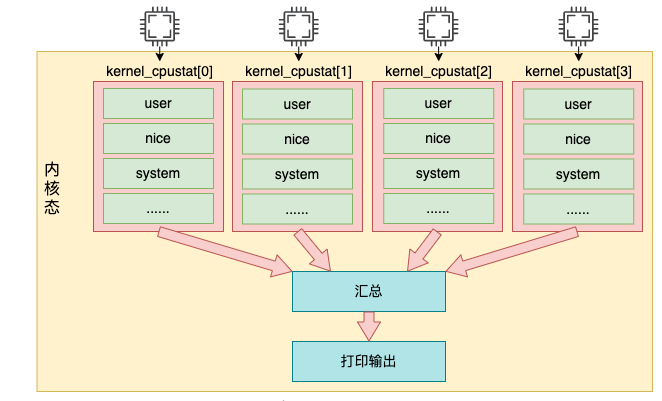
Sehen wir uns an, wann die Daten in dieser Variablen hinzugefügt werden.
三、统计数据怎么来的
前面我们提到内核是以采样的方式来统计 cpu 使用率的。这个采样周期依赖的是 Linux 时间子系统中的定时器。
Linux 内核每隔固定周期会发出 timer interrupt (IRQ 0),这有点像乐谱中的节拍的概念。每隔一段时间,就打出一个拍子,Linux 就响应之并处理一些事情。
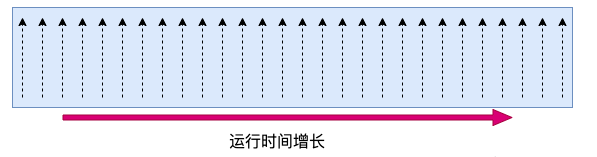
一个节拍的长度是多长时间,是通过 CONFIG_HZ 来定义的。它定义的方式是每一秒有几次 timer interrupts。不同的系统中这个节拍的大小可能不同,通常在 1 ms 到 10 ms 之间。可以在自己的 Linux config 文件中找到它的配置。
# grep ^CONFIG_HZ /boot/config-5.4.56.bsk.10-amd64 CONFIG_HZ=1000
从上述结果中可以看出,我的机器每秒要打出 1000 次节拍。也就是每 1 ms 一次。
每次当时间中断到来的时候,都会调用 update_process_times 来更新系统时间。更新后的时间都存储在我们前面提到的 percpu 变量 kcpustat_cpu 中。
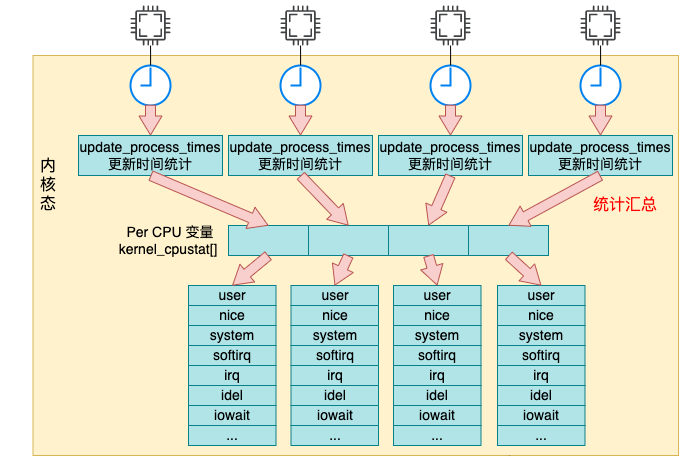
我们来详细看下汇总过程 update_process_times 的源码,它位于 kernel/time/timer.c 文件中。
//file:kernel/time/timer.c
void update_process_times(int user_tick)
{
struct task_struct *p = current;
//进行时间累积处理
account_process_tick(p, user_tick);
...
}
这个函数的参数 user_tick 指的是采样的瞬间是处于内核态还是用户态。接下来调用 account_process_tick。
//file:kernel/sched/cputime.c
void account_process_tick(struct task_struct *p, int user_tick)
{
cputime = TICK_NSEC;
...
if (user_tick)
//3.1 统计用户态时间
account_user_time(p, cputime);
else if ((p != rq->idle) || (irq_count() != HARDIRQ_OFFSET))
//3.2 统计内核态时间
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
//3.3 统计空闲时间
account_idle_time(cputime);
}
在这个函数中,首先设置 cputime = TICK_NSEC, 一个 TICK_NSEC 的定义是一个节拍所占的纳秒数。接下来根据判断结果分别执行 account_user_time、account_system_time 和 account_idle_time 来统计用户态、内核态和空闲时间。
3.1 用户态时间统计
//file:kernel/sched/cputime.c
void account_user_time(struct task_struct *p, u64 cputime)
{
//分两种种情况统计用户态 CPU 的使用情况
int index;
index = (task_nice(p) > 0) ? CPUTIME_NICE : CPUTIME_USER;
//将时间累积到 /proc/stat 中
task_group_account_field(p, index, cputime);
......
}
account_user_time 函数主要分两种情况统计:
- 如果进程的 nice 值大于 0,那么将会增加到 CPU 统计结构的 nice 字段中。
- 如果进程的 nice 值小于等于 0,那么增加到 CPU 统计结构的 user 字段中。
看到这里,开篇的问题 2 就有答案了,其实用户态的时间不只是 user 字段,nice 也是。之所以要把 nice 分出来,是为了让 Linux 用户更一目了然地看到调过 nice 的进程所占的 cpu 周期有多少。
我们平时如果想要观察系统的用户态消耗的时间的话,应该是将 top 中输出的 user 和 nice 加起来一并考虑,而不是只看 user!
接着调用 task_group_account_field 来把时间加到前面我们用到的 kernel_cpustat 内核变量中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
...
}
3.2 内核态时间统计
我们再来看内核态时间是如何统计的,找到 account_system_time 的代码。
//file:kernel/sched/cputime.c
void account_system_time(struct task_struct *p, int hardirq_offset, u64 cputime)
{
if (hardirq_count() - hardirq_offset)
index = CPUTIME_IRQ;
else if (in_serving_softirq())
index = CPUTIME_SOFTIRQ;
else
index = CPUTIME_SYSTEM;
account_system_index_time(p, cputime, index);
}
内核态的时间主要分 3 种情况进行统计。
- 如果当前处于硬中断执行上下文, 那么统计到 irq 字段中;
- 如果当前处于软中断执行上下文, 那么统计到 softirq 字段中;
- 否则统计到 system 字段中。
判断好要加到哪个统计项中后,依次调用 account_system_index_time、task_group_account_field 来将这段时间加到内核变量 kernel_cpustat 中。
//file:kernel/sched/cputime.c
static inline void task_group_account_field(struct task_struct *p, int index,
u64 tmp)
{
__this_cpu_add(kernel_cpustat.cpustat[index], tmp);
}
3.3 空闲时间的累积
没错,在内核变量 kernel_cpustat 中不仅仅是统计了各种用户态、内核态的使用时间,空闲也一并统计起来了。
如果在采样的瞬间,cpu 既不在内核态也不在用户态的话,就将当前节拍的时间都累加到 idle 中。
//file:kernel/sched/cputime.c
void account_idle_time(u64 cputime)
{
u64 *cpustat = kcpustat_this_cpu->cpustat;
struct rq *rq = this_rq();
if (atomic_read(&rq->nr_iowait) > 0)
cpustat[CPUTIME_IOWAIT] += cputime;
else
cpustat[CPUTIME_IDLE] += cputime;
}
在 cpu 空闲的情况下,进一步判断当前是不是在等待 IO(例如磁盘 IO),如果是的话这段空闲时间会加到 iowait 中,否则就加到 idle 中。从这里,我们可以看到 iowait 其实是 cpu 的空闲时间,只不过是在等待 IO 完成而已。
看到这里,开篇问题 3 也有非常明确的答案了,io wait 其实是 cpu 在空闲状态的一项统计,只不过这种状态和 idle 的区别是 cpu 是因为等待 io 而空闲。
四、总结
本文深入分析了 Linux 统计系统 CPU 利用率的内部原理。全文的内容可以用如下一张图来汇总:
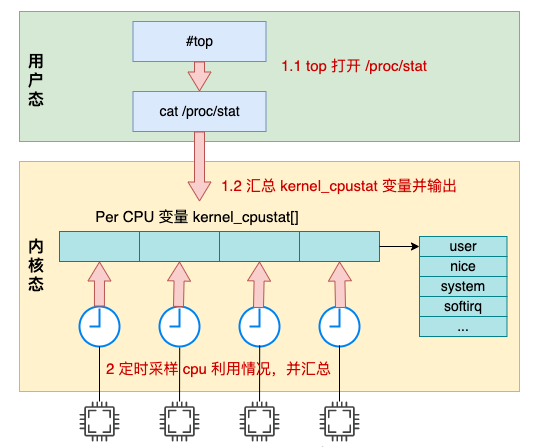
Linux 中的定时器会以某个固定节拍,比如 1 ms 一次采样各个 cpu 核的使用情况,然后将当前节拍的所有时间都累加到 user/nice/system/irq/softirq/io_wait/idle 中的某一项上。
top 命令是读取的 /proc/stat 中输出的 cpu 各项利用率数据,而这个数据在内核中是根据 kernel_cpustat 来汇总并输出的。
回到开篇问题 1,top 输出的利用率信息是如何计算出来的,它精确吗?
/proc/stat 文件输出的是某个时间点的各个指标所占用的节拍数。如果想像 top 那样输出一个百分比,计算过程是分两个时间点 t1, t2 分别获取一下 stat 文件中的相关输出,然后经过个简单的算术运算便可以算出当前的 cpu 利用率。
再说是否精确。这个统计方法是采样的,只要是采样,肯定就不是百分之百精确。但由于我们查看 cpu 使用率的时候往往都是计算 1 秒甚至更长一段时间的使用情况,这其中会包含很多采样点,所以查看整体情况是问题不大的。
另外从本文,我们也学到了 top 中输出的 cpu 时间项目其实大致可以分为三类:
第****一类:用户态消耗时间,包括 user 和 nice。如果想看用户态的消耗,要将 user 和 nice 加起来看才对。
第二类:内核态消耗时间,包括 irq、softirq 和 system。
第三类:空闲时间,包括 io_wait 和 idle。其中 io_wait 也是 cpu 的空闲状态,只不过是在等 io 完成而已。如果只是想看 cpu 到底有多闲,应该把 io_wait 和 idle 加起来才对。
Das obige ist der detaillierte Inhalt vonWie wird die CPU-Auslastung unter Linux berechnet?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!