
Heim >System-Tutorial >LINUX >Wie viele Methoden kennen Sie zur Analyse der Linux-Speichernutzung?
Wie viele Methoden kennen Sie zur Analyse der Linux-Speichernutzung?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-13 18:24:16815Durchsuche
0. Einleitung:
Der Systemspeicher ist ein unverzichtbarer Bestandteil des Hardwaresystems. Durch die regelmäßige Überprüfung der Systemspeicherressourcen können wir schnell feststellen, ob eine abnormale Belegung der Speicherressourcen vorliegt, und einen stabilen Geschäftsbetrieb gewährleisten.
Zum Beispiel: Durch regelmäßige Überprüfung der Speichernutzung des Website-Servers des Unternehmens können Sie sicherstellen, dass die Serverressourcen ausreichen. Wenn Sie feststellen, dass der Serverspeicher ungewöhnlich belegt ist, können Sie das Problem rechtzeitig beheben, um das Problem des fehlenden Zugriffs zu vermeiden der Website oder langsamer Zugriff aufgrund von unzureichendem Speicher.
Daher ist es für Linux-Administratoren sehr wichtig, in ihrer täglichen Arbeit den Speicherzustand unter Linux-Systemen gekonnt überprüfen zu können!
Es ist nicht schwierig, den Betriebsstatus des Speichers zu überprüfen, aber wie kann man ihn in verschiedenen Situationen richtig überprüfen?
Kuiyijun hat mehrere sehr praktische Methoden zum Überprüfen des Linux-Speichers zusammengestellt:
- 1. kostenloser Befehl
- 2. vmstat-Befehl
- 3./proc/meminfo-Befehl
- 4. Top-Befehl
- 5. htop-Befehl
- 6. Prozessspeicherinformationen anzeigen
Linux-Speicherübersichtsbild
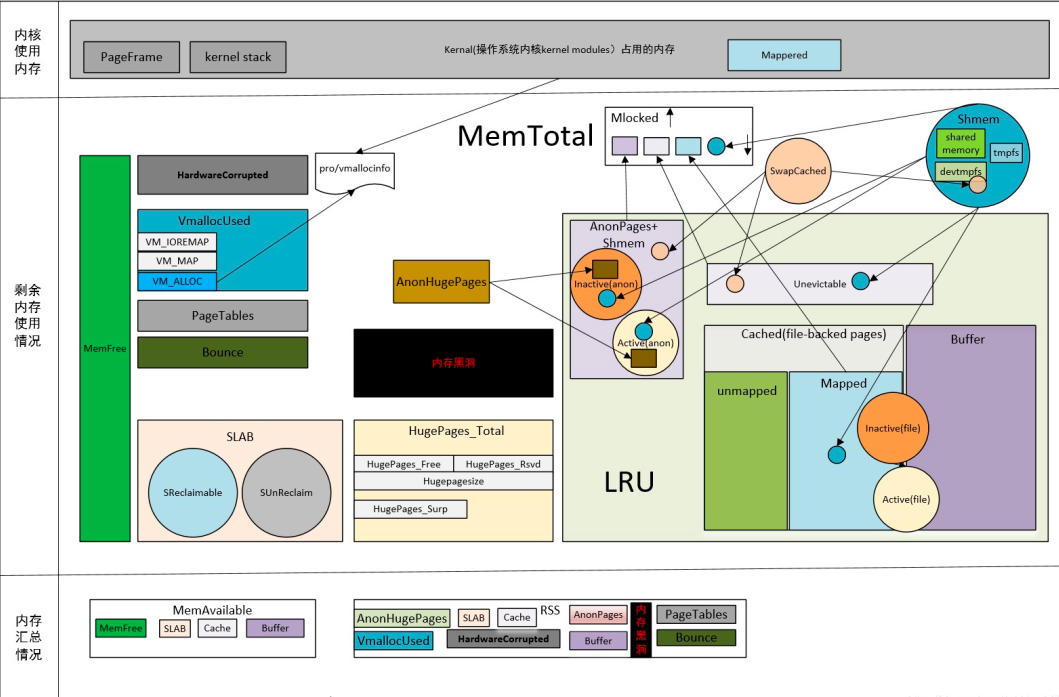
Dieses Diagramm beschreibt gut die Details der Speichernutzung und -zuweisung des Betriebssystems. Es wird jedem empfohlen, dieses Bild zu verwenden, um einige Konzepte des Gedächtnisses zu lernen und zu verstehen.
1. Kostenloser Befehl
Der Befehl free kann die Menge des ungenutzten und belegten Speichers im aktuellen System sowie den vom Kernel verwendeten Speicherpuffer anzeigen.
1. Kostenlose Befehlssyntax:
free [options]
kostenlose Befehlsoptionen:
-b # 以Byte为单位显示内存使用情况; -k # 以KB为单位显示内存使用情况; -m # 以MB为单位显示内存使用情况; -g # 以GB为单位显示内存使用情况。 -o # 不显示缓冲区调节列; -s # 持续观察内存使用状况; -t # 显示内存总和列; -V # 显示版本信息。
2. kostenloses Befehlsbeispiel
free -t # 以总和的形式显示内存的使用信息 free -h -s 10 # 周期性的查询内存使用信息,每10s 执行一次命令 free -h -c 10 #输出10次 在版本 v3.2.8,就是输出一次!需要配合 -s 使用。 在版本 v3.3.10,不加-s,就默认1秒输出一次。 free -V #查看版本号
v3.2.8

v3.3.10

Erklären wir zunächst den Ausgabeinhalt:
| Inhalt | Bedeutung |
|---|---|
| Mem | DieZeile (die zweite Zeile) ist die Speichernutzung |
| Tausch | DieZeile (die dritte Zeile) ist die Nutzung des Swap Space |
| insgesamt | Gesamt verfügbarer physischer Speicher. Im Allgemeinen ist der gesamte physische Speicher, mit Ausnahme einiger reservierter Speicher und des vom Betriebssystem selbst belegten Speichers, die Speichergröße, die das Betriebssystem steuern kann. Dies ist in Version 3.2.8 dasselbe wie in Version 3.3.10. Dieser Wert ist der Wert von MemTotal in /proc/meminfo. |
| gebraucht | Die Spalten zeigen den verwendeten physischen Speicher und Swap-Speicherplatz. In v3.2.8 wird dieser Wert von (total – free) abgeleitet. Man kann sagen, dass das System vom System zugewiesen wurde, aber nicht unbedingt tatsächlich genutzt wird. Sein Speicherplatz kann zurückgefordert und neu zugewiesen werden. In v3.3.10 wird dieser Wert von (gesamt – frei – Cache – Puffer) abgeleitet und ist der tatsächlich aktuell verwendete Speicher. |
| kostenlos | Der physische Speicher, der vom System nicht verwendet wird. Dieser Wert ist der Wert von MemFree in /proc/meminfo |
| geteilt | Gemeinsamer Speicherplatz. Dieser Wert ist der Wert von Shmem in /proc/meminfo |
| Buff/Cache | Die Spaltezeigt die von Puffer und Cache verwendete physische Speichergröße |
| verfügbar | Artikel in v3.3.10. Es scheint, dass es sich bei diesem Wert um nutzbaren Speicher handelt, aber (verfügbar + genutzt) |
| -/+ Puffer/Cache | v3.2.8 hat diese Zeile, v3.3.10 nicht. Unter diesen ist das verwendete Element der Wert von (verwendet – Puffer – zwischengespeichert), dh der Wert von (gesamt – frei – Puffer – zwischengespeichert), also der Wert des tatsächlich verwendeten Speichers. free Dieses Element ist der Wert von (frei + Puffer + zwischengespeichert), was dem Wert des tatsächlich ungenutzten Speichers entspricht. Persönlich denke ich, dass es -/+ buffers/cache gibt, diese Spalte kommt mir recht bekannt vor. . Die Verwendung der neuen Version v3.3.10 ist jedoch klarer. Ich glaube, es gibt viele Leute wie mich, die ein wenig verwirrt waren, als sie zum ersten Mal sahen, dass die Verwendung in Version 3.2.8 so viel Speicher beanspruchte. |
二、vmstat 指令
vmstat命令是最常见的Linux/Unix监控工具,用于查看系统的内存存储信息,是一个报告虚拟内存统计信息的小工具,属于sysstat包。
vmstat 命令报告包括:进程、内存、分页、阻塞 IO、中断、磁盘、CPU。
可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。
这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
1. 命令格式:
vmstat -s(参数)
2. 举例
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@local:~# vmstat 2 1 procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
这表示vmstat每2秒采集数据,按下ctrl + c结束程序,这里采集了3次数据我就结束了程序。
| Kategorie | Projekt | Bedeutung | Anleitung |
|---|---|---|---|
| Procs****(Prozess) | r | Anzahl der Aufgaben, die auf ihre Ausführung warten | Zeigt die Anzahl der Aufgaben an, die ausgeführt werden und auf CPU-Ressourcen warten. Wenn dieser Wert die Anzahl der CPUs überschreitet, kommt es zu einem CPU-Engpass. |
| B | 等待IO的进程数量 | ||
| Memory(内存) | swpd | 正在使用虚拟的内存大小,单位k | |
| free | 空闲内存大小 | ||
| buff | 已用的buff大小,对块设备的读写进行缓冲 | ||
| cache | 已用的cache大小,文件系统的cache | ||
| inact | 非活跃内存大小,即被标明可回收的内存,区别于free和active | 具体含义见:概念补充(当使用-a选项时显示) | |
| active | 活跃的内存大小 | 具体含义见:概念补充(当使用-a选项时显示) | |
| Swap | si | 每秒从交换区写入内存的大小(单位:kb/s) | |
| so | 每秒从内存写到交换区的大小 | ||
| IO | bi | 每秒读取的块数(读磁盘) | 块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) | 块设备每秒发送的块数量,单位是block | |
| system | in | 每秒中断数,包括时钟中断 | 这两个值越大,会看到由内核消耗的cpu时间sy会越多 秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目 |
| cs | 每秒上下文切换数 | ||
| CPU****(以百分比表示) | us | 用户进程执行消耗cpu时间(user time) | us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| sy | Systemprozesse verbrauchen CPU-Zeit (Systemzeit) | Wenn der Wert von sys zu hoch ist, bedeutet dies, dass der Systemkern viele CPU-Ressourcen verbraucht. Dies ist keine harmlose Leistung und wir sollten den Grund überprüfen. Der Referenzwert von us + sy beträgt hier 80 %. Wenn us + sy größer als 80 % ist, bedeutet dies, dass möglicherweise nicht genügend CPU vorhanden ist | |
| Leerlaufzeit (einschließlich IO-Wartezeit) | Im Allgemeinen sind wir+sy+id=100 | ||
| Warten auf die IO-Zeit | Wennwa zu hoch ist, bedeutet dies, dass die E/A-Wartezeit schwerwiegend ist. Dies kann durch eine große Anzahl zufälliger Zugriffe auf die Festplatte verursacht werden oder es liegt möglicherweise ein Engpass in der Bandbreite der Festplatte vor. |
Das obige ist der detaillierte Inhalt vonWie viele Methoden kennen Sie zur Analyse der Linux-Speichernutzung?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das Shell-Skript implementiert die Methode zum Ausführen des Java-Programms jar
- So formatieren Sie eine SQL-Anweisung in Notepad++
- So erstellen Sie Dateien unter Linux
- Eine eingehende Analyse der Systemaufgabeneinstellungen von Linux-Studiennotizen
- Umgang mit abnormaler CPU- und Speicherauslastung bei der PHP-Sprachentwicklung