
Heim >System-Tutorial >LINUX >Erlernen Sie mühelos die Kenntnisse im Parsen und Partitionieren von Linux-Speichern
Erlernen Sie mühelos die Kenntnisse im Parsen und Partitionieren von Linux-Speichern

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-12 15:54:11728Durchsuche
Bei der Verwendung des Linux-Betriebssystems müssen wir häufig Speichergeräte verwalten und konfigurieren. Dabei gehört die Auflösung und Partitionierung von Speichergeräten zu den häufigsten Verwaltungsaufgaben. Wenn wir verstehen, wie Speicheranalyse und -partitionierung durchgeführt werden, können wir Speicherressourcen besser nutzen und die Systemleistung verbessern. In diesem Artikel werden die relevanten Kenntnisse zum Parsen und Partitionieren von Speichergeräten in Linux-Systemen vorgestellt.
Bei der Verwendung von C/C++ für die Multithread-Programmierung in Linux-Systemen ist das häufigste Problem das Multithread-Lesen und Schreiben derselben Variablen. In den meisten Fällen werden solche Probleme durch den Sperrmechanismus gelöst, aber das ist der Fall Die Leistung des Programms hat natürlich große Auswirkungen. Für die Datentypen, die das System nativ unterstützt, können wir atomare Operationen verwenden, um sie zu verarbeiten, was die Leistung des Programms bis zu einem gewissen Grad verbessert. Wie können wir also für benutzerdefinierte Datentypen, deren Systeme keine atomaren Operationen unterstützen, Thread-Sicherheit erreichen, ohne Sperren zu verwenden? In diesem Artikel wird kurz erläutert, wie mit dieser Art von Thread-Sicherheitsproblemen im Hinblick auf die lokale Thread-Speicherung umgegangen werden kann.
1. Datentyp
In C/C++-Programmen gibt es häufig globale Variablen, innerhalb von Funktionen definierte statische Variablen und lokale Variablen. Für lokale Variablen gibt es kein Thread-Sicherheitsproblem, daher fallen sie nicht in den Geltungsbereich dieses Artikels. Globale Variablen und statische Variablen, die in Funktionen definiert sind, sind gemeinsam genutzte Variablen, auf die alle Threads im selben Prozess zugreifen können, sodass sie Probleme beim Lesen und Schreiben mit mehreren Threads haben. Wenn der Inhalt einer Variablen in einem Thread geändert wird, können andere Threads den geänderten Inhalt wahrnehmen und lesen. Dies ist für den Datenaustausch sehr schnell. Aufgrund der Existenz von Multi-Threads kann es jedoch zu unterschiedlichen Inhalten für dieselbe Variable kommen . Zwei oder mehr Threads ändern den Speicherinhalt der Variablen gleichzeitig, und es gibt mehrere Threads, die den Speicherwert lesen, wenn der entsprechende Synchronisierungsmechanismus nicht zum Schutz des Speichers verwendet wird Dies ist unvorhersehbar und kann sogar zum Absturz des Programms führen.
Wenn Sie eine Variable benötigen, auf die bei jedem Funktionsaufruf innerhalb eines Threads zugegriffen werden kann, auf die andere Threads jedoch nicht zugreifen können, ist ein neuer Mechanismus erforderlich, um sie zu implementieren. Wir nennen ihn „Statischer Speicher lokal für einen Thread“ (lokale Thread-Variable). auch Es kann als Thread-spezifische Daten (TSD: Thread-Specific Data) oder Thread-lokaler Speicher (TLS: Thread-Local Storage) bezeichnet werden. Für diese Art von Daten verwaltet jeder Thread im Programm eine Kopie der Variablen, und Operationen an solchen Variablen wirken sich nicht auf andere Threads aus. Wie unten gezeigt: 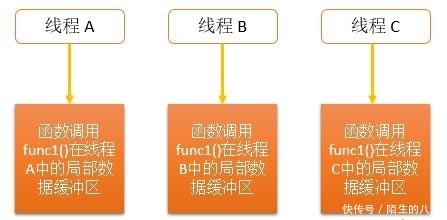
2. Einmalige Initialisierung
Bevor wir threadspezifische Daten erläutern, wollen wir zunächst die einmalige Initialisierung verstehen. Multithread-Programme haben manchmal eine solche Anforderung: Unabhängig davon, wie viele Threads erstellt werden, kann die Initialisierung einiger Daten nur einmal erfolgen. Beispiel: In einem C++-Programm kann während des gesamten Lebenszyklus des Prozesses nur ein Instanzobjekt einer bestimmten Klasse vorhanden sein. Im Falle von Multithreading ist die einmalige Initialisierung erforderlich, um eine sichere Initialisierung des Objekts zu ermöglichen Der Mechanismus ist besonders wichtig. ——In Entwurfsmustern wird diese Implementierung häufig als Singleton-Muster (Singleton) bezeichnet. Linux bietet die folgenden Funktionen, um eine einmalige Initialisierung zu erreichen:
#include
// Returns 0 on success, or a positive error number on error
int pthread_once (pthread_once_t *once_control, void (*init) (void));
利用参数once_control的状态,函数pthread_once()可以确保无论有多少个线程调用多少次该函数,也只会执行一次由init所指向的由调用者定义的函数。init所指向的函数没有任何参数,形式如下:
void init (void)
{
// some variables initializtion in here
}
Darüber hinaus muss der Parameter Once_Control ein Zeiger auf eine Variable vom Typ pthread_once_t sein, der auf eine statische Variable zeigt, die auf PTHRAD_ONCE_INIT initialisiert wurde. Nach C++0x wird eine Funktion std::call_once () mit ähnlichen Funktionen bereitgestellt, deren Verwendung dieser Funktion ähnelt.
3. Thread-API für lokale Daten
Die folgenden Funktionen stehen unter Linux zur Verfügung, um Thread-lokale Daten zu verwalten
#include // Returns 0 on success, or a positive error number on error int pthread_key_create (pthread_key_t *key, void (*destructor)(void *)); // Returns 0 on success, or a positive error number on error int pthread_key_delete (pthread_key_t key); // Returns 0 on success, or a positive error number on error int pthread_setspecific (pthread_key_t key, const void *value); // Returns pointer, or NULL if no thread-specific data is associated with key void *pthread_getspecific (pthread_key_t key);
Die Funktion pthread_key_create() erstellt einen neuen Schlüssel für Thread-lokale Daten und zeigt über den Schlüssel auf den neu erstellten Schlüsselpuffer. Da alle Threads den zurückgegebenen neuen Schlüssel verwenden können, kann der Parameterschlüssel eine globale Variable sein (globale Variablen werden in der C++-Multithread-Programmierung im Allgemeinen nicht verwendet, es werden jedoch separate Klassen verwendet, um Thread-lokale Daten zu kapseln, und jede Variable verwendet eine unabhängige pthread_key_t). Der Destruktor verweist auf eine benutzerdefinierte Funktion mit dem folgenden Format:
void Dest (void *value)
{
// Release storage pointed to by 'value'
}
只要线程终止时与key关联的值不为NULL,则destructor所指的函数将会自动被调用。如果一个线程中有多个线程局部存储变量,那么对各个变量所对应的destructor函数的调用顺序是不确定的,因此,每个变量的destructor函数的设计应该相互独立。
函数pthread_key_delete()并不检查当前是否有线程正在使用该线程局部数据变量,也不会调用清理函数destructor,而只是将其释放以供下一次调用pthread_key_create()使用。在Linux线程中,它还会将与之相关的线程数据项设置为NULL。
由于系统对每个进程中pthread_key_t类型的个数是有限制的,所以进程中并不能创建无限个的pthread_key_t变量。Linux中可以通过PTHREAD_KEY_MAX(定义于limits.h文件中)或者系统调用sysconf(_SC_THREAD_KEYS_MAX)来确定当前系统最多支持多少个键。Linux中默认是1024个键,这对于大多数程序来说已经足够了。如果一个线程中有多个线程局部存储变量,通常可以将这些变量封装到一个数据结构中,然后使封装后的数据结构与一个线程局部变量相关联,这样就能减少对键值的使用。
函数pthread_setspecific()用于将value的副本存储于一数据结构中,并将其与调用线程以及key相关联。参数value通常指向由调用者分配的一块内存,当线程终止时,会将该指针作为参数传递给与key相关联的destructor函数。当线程被创建时,会将所有的线程局部存储变量初始化为NULL,因此第一次使用此类变量前必须先调用pthread_getspecific()函数来确认是否已经于对应的key相关联,如果没有,那么pthread_getspecific()会分配一块内存并通过pthread_setspecific()函数保存指向该内存块的指针。
参数value的值也可以不是一个指向调用者分配的内存区域,而是任何可以强制转换为void的变量值,在这种情况下,先前的pthread_key_create()函数应将参数
destructor设置为NULL
函数pthread_getspecific()正好与pthread_setspecific()相反,其是将pthread_setspecific()设置的value取出。在使用取出的值前最好是将void转换成原始数据类型的指针。
四、深入理解线程局部存储机制
\1. 深入理解线程局部存储的实现有助于对其API的使用。在典型的实现中包含以下数组:
pthread_key_create()返回的pthread_key_t类型值只是对全局数组的索引,该全局数组标记为pthread_keys,其格式大概如下:
数组的每个元素都是一个包含两个字段的结构,第一个字段标记该数组元素是否在用,第二个字段用于存放针对此键、线程局部存储变的解构函数的一个副本,即destructor函数。
\2. 在常见的存储pthread_setspecific()函数参数value的实现中,大多数都类似于下图的实现。图中假设pthread_keys[1]分配给func1()函数,pthread API为每个函数维护指向线程局部存储数据块的一个指针数组,其中每个数组元素都与图线程局部数据键的实现(上图)中的全局pthread_keys中元素一一对应。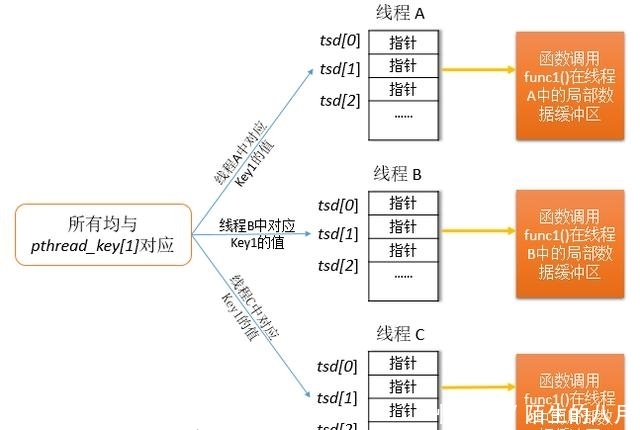
五、总结
使用全局变量或者静态变量是导致多线程编程中非线程安全的常见原因。在多线程程序中,保障非线程安全的常用手段之一是使用互斥锁来做保护,这种方法带来了并发性能下降,同时也只能有一个线程对数据进行读写。如果程序中能避免使用全局变量或静态变量,那么这些程序就是线程安全的,性能也可以得到很大的提升。如果有些数据只能有一个线程可以访问,那么这一类数据就可以使用线程局部存储机制来处理,虽然使用这种机制会给程序执行效率上带来一定的影响,但对于使用锁机制来说,这些性能影响将可以忽略。更高性能的线程局部存储机制就是使用__thread,这个以后再讨论。
需要C/C++ Linux服务器开发学习资料私信“资料”(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
本文介绍了Linux系统中存储设备解析和分区的相关知识,包括使用fdisk命令、使用parted命令、使用mkfs命令等。了解这些知识,可以帮助我们更好地管理和配置存储设备,优化系统性能。希望读者能够根据实际需求选择适合自己的方法,并加以应用。
Das obige ist der detaillierte Inhalt vonErlernen Sie mühelos die Kenntnisse im Parsen und Partitionieren von Linux-Speichern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Einführung in die Python-Implementierung der Linux-Befehlsfunktion xxd -i
- Welche Bücher sollte ich lesen, um mit Linux zu beginnen?
- Welche Befehle gibt es zum Dekomprimieren von Dateien unter Linux?
- So installieren Sie PHP über die Linux-Befehlszeile
- Wo ist das Schriftartenverzeichnis des Linux-Systems?