
Heim >System-Tutorial >LINUX >Linux-Prozessgruppenplanungsmechanismus: So gruppieren und planen Sie Prozesse
Linux-Prozessgruppenplanungsmechanismus: So gruppieren und planen Sie Prozesse

- 王林nach vorne
- 2024-02-11 20:30:101526Durchsuche
Prozessgruppen sind eine Möglichkeit, Prozesse in Linux-Systemen zu klassifizieren und zu verwalten. Sie können Prozesse mit denselben Eigenschaften oder Beziehungen zu einer logischen Einheit zusammenfassen. Die Funktion der Prozessgruppe besteht darin, die Steuerung, Kommunikation und Ressourcenzuweisung von Prozessen zu erleichtern, um die Effizienz und Sicherheit des Systems zu verbessern. Die Prozessgruppenplanung ist ein Mechanismus zur Planung von Prozessgruppen in Linux-Systemen. Sie kann basierend auf den Attributen und Anforderungen der Prozessgruppe geeignete CPU-Zeit und Ressourcen zuweisen und so die Parallelität und Reaktionsfähigkeit des Systems verbessern. Aber verstehen Sie den Linux-Prozessgruppenplanungsmechanismus wirklich? Wissen Sie, wie man Prozessgruppen unter Linux erstellt und verwaltet? Wissen Sie, wie Sie den Prozessgruppenplanungsmechanismus unter Linux verwenden und konfigurieren? In diesem Artikel werden Ihnen die relevanten Kenntnisse des Linux-Prozessgruppenplanungsmechanismus im Detail vorgestellt, damit Sie diese leistungsstarke Kernelfunktion unter Linux besser nutzen und verstehen können.

Ich bin auf ein weiteres magisches Prozessplanungsproblem gestoßen und habe festgestellt, dass sich das System nach 30 Sekunden aufgehängt hat. Der eigentliche Grund für das Zurücksetzen des Systems war, dass der Hardware-Watchdog das System neu gestartet hat normaler Neustartvorgang. Die Rücksetzzeit des Hardware-Dog-Datensatzes wird um 30 Sekunden vorverlegt, wenn der Hund nicht gefüttert wird. Bei der Analyse des Protokolls der seriellen Schnittstelle wurde zu diesem Zeitpunkt ein Satz ausgegeben: „sched: RT-Drosselung aktiviert“.
Wie aus dem Kernelcode der Version Linux-3.0.101-0.7.17 hervorgeht, gibt sched_rt_runtime_exceeded diesen Satz aus. Im Kernel-Prozessgruppenplanungsprozess wird die Prozessplanung in Echtzeit durch rt_rq->rt_throttled eingeschränkt. Lassen Sie uns im Folgenden ausführlich über den Prozessgruppenplanungsmechanismus in Linux sprechen.
Prozessgruppenplanungsmechanismus
Gruppenplanung ist ein Konzept in cgroup, das sich auf die Behandlung von N Prozessen als Ganzes und die Teilnahme am Planungsprozess im System bezieht. Dies spiegelt sich insbesondere im Beispiel wider: Aufgabe A hat 8 Prozesse oder Threads und Aufgabe B hat 2 Prozesse Wenn es noch andere Prozesse oder Threads gibt, müssen Sie die CPU-Auslastung von Aufgabe A so steuern, dass sie nicht höher als 40 % ist, die CPU-Auslastung von Aufgabe B nicht höher als 40 % und die CPU-Auslastung von anderen Aufgaben dürfen nicht weniger als 20 % betragen. Zum Festlegen des Kontrollgruppenschwellenwerts wird Kontrollgruppe A auf 200, Kontrollgruppe B auf 200 und andere Aufgaben standardmäßig auf 100 eingestellt, wodurch die CPU-Steuerungsfunktion realisiert wird.
Im Kernel werden Prozessgruppen von task_group verwaltet, und viele der beteiligten Inhalte sind Kontrollmechanismen für die Entwicklungseinheit. Hier verweisen wir auf den Teil, der sich auf die Gruppenplanung konzentriert .
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
//普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
//公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
Es gibt zwei Arten von Planungseinheiten, nämlich normale Planungseinheiten und Echtzeit-Prozessplanungseinheiten.
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
//当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
//当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq *my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
Werfen wir einen Blick auf die Planungswarteschlange, da die Optionen, die für die Echtzeitplanung und für gewöhnliche Planungswarteschlangen erklärt werden müssen, ähnlich sind. Nehmen Sie die Echtzeit-Warteschlange als Beispiel:
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};
Durch die Analyse der oben genannten drei Strukturen kann das folgende Bild erhalten werden (zum Vergrößern auf das Bild klicken):
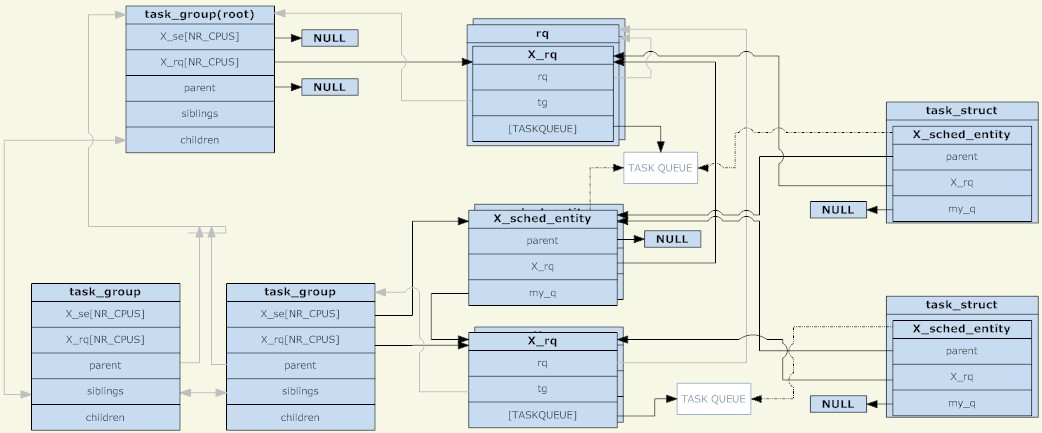
task_group
Wie aus der Abbildung ersichtlich ist, sind die Planungseinheit und die Planungswarteschlange in einem Baumknoten zusammengefasst, der eine weitere separate Baumstruktur darstellt. Es ist jedoch zu beachten, dass die Planungseinheit nur platziert wird, wenn ein TASK_RUNNING-Prozess vorhanden ist in der Planungseinheit in die Versandwarteschlange.
Ein weiterer Punkt ist, dass es vor der Gruppenplanung nur eine Planungswarteschlange auf jeder CPU gab. Damals konnte man verstehen, dass sich alle Prozesse in einer Planungsgruppe befanden. Jetzt hat jede Planungsgruppe eine Planungswarteschlange auf jeder CPU. Während des Planungsprozesses wählte das System ursprünglich eine auszuführende Planungseinheit aus. Wenn die Planung erfolgt, beginnt der Planungsprozess bei der Planungsrichtlinie Einheit ist task_group, sie betritt die task_group. Die Ausführungswarteschlange wählt eine geeignete Planungseinheit aus und findet schließlich eine geeignete Aufgabenplanungseinheit. Der gesamte Prozess ist eine Baumdurchquerung. Die Taskgruppe mit dem TASK_RUNNING-Prozess ist der Knoten des Baums, und die Taskplanungseinheit ist das Blatt des Baums.
Gruppenprozessplanungsstrategie
Der Zweck der Gruppenprozessplanung unterscheidet sich nicht vom ursprünglichen Zweck, der darin besteht, die Prozessplanung in Echtzeit und die normale Prozessplanung, dh die RT- und CFS-Planung, abzuschließen.
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
Das obige ist der detaillierte Inhalt vonLinux-Prozessgruppenplanungsmechanismus: So gruppieren und planen Sie Prozesse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie überprüfe ich die Python-Version im Shell-Skript?
- Welche Linux-Befehle gibt es zum Abfragen von MySQL?
- So dekomprimieren Sie tar.gz unter Linux
- So verwenden Sie Linux-Befehle zum Verschieben/Kopieren von Dateien/Verzeichnissen in ein bestimmtes Verzeichnis
- Wie filtere und klassifiziere ich Protokolle mit Linux-Befehlszeilentools?