
Heim >System-Tutorial >LINUX >Eine vorläufige Studie zum Linux-Kernel-Pruning-Framework
Eine vorläufige Studie zum Linux-Kernel-Pruning-Framework

- 王林nach vorne
- 2024-02-10 17:30:421309Durchsuche
Aufgrund der Instabilität des Betriebssystemkerns, der schlechten Aktualität, Integritätsproblemen und der Notwendigkeit manueller Eingriffe wurde die Linux-Kernel-Bereinigungstechnologie nicht weit verbreitet eingesetzt. Nachdem wir die Einschränkungen der vorhandenen Technologie verstanden haben, versuchen wir, ein Linux-Kernel-Anpassungsframework vorzuschlagen, das diese Probleme möglicherweise lösen kann.
Um das Jahr 2000 herum war der alte Programmierer noch sehr jung und hoffte, Linux als Betriebssystem für Mobiltelefone verwenden zu können. Deshalb kam er auf die Idee, den Kernel anzupassen Der Effekt war recht gut und er konnte das Mobiltelefon bereits auf dem PDA ausführen. Es sind mehr als 20 Jahre vergangen, und Linux hat sich stark verändert, und auch die Technologie und Methoden der Kernel-Bereinigung haben sich stark verändert.
Durch das Bereinigen des Linux-Kernels wird unnötiger Kernel-Code in Zielanwendungen reduziert, was erhebliche Vorteile in Bezug auf Sicherheit und Leistung mit sich bringt (schnelle Startzeit und geringerer Speicherbedarf). Die bestehende Kernel-Bereinigungstechnologie hat jedoch ihre Grenzen. Gibt es eine Rahmenmethode für die Kernel-Bereinigung?
1. Über Kernel-Beschneidung
In den letzten Jahren haben Linux-Betriebssysteme an Komplexität und Umfang zugenommen. Allerdings erfordert eine Anwendung normalerweise nur einen Teil der Betriebssystemfunktionalität, und zahlreiche Anwendungsanforderungen führen zu aufgeblähten Linux-Kerneln. Das Aufblähen des Betriebssystemkerns führt außerdem zu Sicherheitsrisiken, längeren Startzeiten und einer erhöhten Speichernutzung.
Mit der Popularität von Servitization und Microservices ist der Bedarf an Kernel-Anpassung weiter gestiegen. In diesen Szenarien führen virtuelle Maschinen häufig kleine Anwendungen aus und verfügen über einen geringen Kernel-Footprint. Einige Virtualisierungstechnologien stellen den einfachsten Linux-Kernel für die Zielanwendung bereit.
Angesichts der Komplexität von Betriebssystemen ist es etwas unpraktisch, den Kernel durch manuelle Auswahl von Kernelfunktionen anzupassen. Linux verfügt beispielsweise über mehr als 14.000 Konfigurationsoptionen (ab Version 4.14), wobei jedes Jahr Hunderte neuer Optionen eingeführt werden. Kernel-Konfiguratoren (wie KConfig) bieten lediglich eine Benutzeroberfläche zur Auswahl von Konfigurationsoptionen. Aufgrund der schlechten Benutzerfreundlichkeit und der unvollständigen Dokumentation ist es für Benutzer schwierig, eine minimale und praktische Kernelkonfiguration auszuwählen.
Bestehende Kernel-Bereinigungstechniken folgen im Allgemeinen drei Schritten:
- Führen Sie die Arbeitslast der Zielanwendung aus und verfolgen Sie den ausgeführten Kernel-Code, während die Anwendung ausgeführt wird
- Analysieren Sie den Trace und ermitteln Sie den Kernel-Code, der von der Zielanwendung benötigt wird,
- Stellen Sie einen Kernel-Schnitt zusammen, der nur den für Ihre Anwendung erforderlichen Code enthält.
Konfigurationsgesteuert ist ein allgemeiner Ansatz zur Kernelbereinigung. Die meisten vorhandenen Tools verwenden konfigurationsgesteuerte Techniken, da sie eine der wenigen Technologien sind, die stabile Kernel erzeugen können. Durch das konfigurationsgesteuerte Neuladen des Kernels wird der Kernelcode basierend auf den Funktionsmerkmalen reduziert. Die Konfigurationsoptionen entsprechen der Funktionalität des Kernels. Der bereinigte Kernel enthält nur die Funktionalität, die zur Unterstützung der Zielanwendungsarbeitslast erforderlich ist.
Obwohl die Kernel-Pruning-Technik hinsichtlich Sicherheit und Leistung sehr attraktiv ist, hat sie sich in der Praxis noch nicht weit verbreitet. Das liegt nicht an mangelnder Nachfrage; tatsächlich programmieren viele Cloud-Anbieter Linux-Kernel von Hand, um den Code zu reduzieren, aber im Allgemeinen nicht so effektiv wie Kernel-Bereinigungstechniken.
2. Einschränkungen der bestehenden Kernel-Beschneidungstechnologie
Bestehende Kernel-Bereinigungstechnologie weist fünf Haupteinschränkungen auf.
Unsichtbar während der Bootphase. Bestehende Techniken können erst nach dem Kernel-Boot starten und basieren auf ftrace, sodass es keine Möglichkeit gibt, zu beobachten, welcher Kernel-Code während der Boot-Phase geladen wird. Fehlen kritische Module im Kernel, kann der Kernel oft nicht booten und viele Kernel-Funktionsmerkmale können nur durch Beobachtung der Boot-Phase erfasst werden. Darüber hinaus werden Leistungs- und Sicherheitsprobleme nur beim Booten geladen (z. B. CONFIGSCHEDMC und CONFIGSECURITYNETWORK für Multi-Core-Unterstützung), was zu einer verringerten Leistung und Sicherheit führt.
Mangel an schneller Unterstützung für die Anwendungsbereitstellung. Die Bereitstellung einer neuen, auf den Kernel zugeschnittenen Anwendung unter Verwendung bestehender Tools erfordert die Durchführung der drei Schritte Tracing, Analyse und Assemblierung. Dieser Prozess ist zeitaufwändig und kann Stunden oder sogar Tage dauern, was die Agilität der Anwendungsbereitstellung beeinträchtigt.
Die Partikelgröße ist gröber. Mit ftrace kann Kernelcode nur auf Funktionsebene verfolgt werden, und die Granularität ist zu grob, um Konfigurationsoptionen zu verfolgen, die sich auf den Code innerhalb der Funktion auswirken.
Unvollständige Abdeckung. Da dynamisches Tracing verwendet wird, muss die Anwendungsarbeitslast die Codeausführung des Kernels vorantreiben, um die Abdeckung zu maximieren. Allerdings stellt die Benchmark-Abdeckung eine Herausforderung dar, und wenn die Anwendung über Kernel-Code verfügt, der während der Ablaufverfolgung nicht beobachtet wird, kann der beschnittene Kernel zur Laufzeit abstürzen.
Es gibt keinen Unterschied zwischen Ausführungsabhängigkeiten und es kann zu Redundanzen kommen. Auch Code, der möglicherweise nicht wirklich ausgeführt werden muss, kann in die Kernel-Funktionalität einbezogen werden, beispielsweise kann er ein zweites Dateisystem initialisieren.
Die ersten drei Einschränkungen sind überwindbar und können durch verbessertes Design und verbesserte Werkzeuge behoben werden, während die letzten beiden Einschränkungen unvermeidbar sind und über die spezifische Technologie hinausgehende Anstrengungen erfordern.
3. Linux-Kernel-Konfiguration
3.1 Konfigurationsoptionen
Die Kernelkonfiguration besteht aus einer Reihe von Konfigurationsoptionen. Ein Kernelmodul kann über mehrere Optionen verfügen, von denen jede steuert, welcher Code in die endgültige Kernel-Binärdatei aufgenommen wird.
Konfigurationsoptionen steuern unterschiedliche Granularitäten des Kernel-Codes, z. B. Anweisungen und Funktionen, die vom C-Präprozessor implementiert werden, und Objektdateien, die auf Basis von Makefiles implementiert werden. Der C-Präprozessor wählt Codeblöcke basierend auf #ifdef/#ifndef aus, und Konfigurationsoptionen werden als Makrodefinitionen verwendet, um zu bestimmen, ob solche bedingten Codeblöcke im kompilierten Kernel enthalten sind, entweder mit Anweisungsgranularität oder mit Funktionsgranularität. Makefile wird verwendet, um zu bestimmen, ob bestimmte Objektdateien im kompilierten Kernel enthalten sind. CONFIG_CACHEFILES ist beispielsweise die Konfigurationsoption in Makefile.
Konfigurationsoptionen auf Anweisungsebene können nicht durch Tracing auf Funktionsebene identifiziert werden, das von vorhandenen Kernel-Anpassungstools verwendet wird. Tatsächlich sind etwa 30 % des C-Präprozessors in Linux 4.14 Optionen auf Anweisungsebene.
Mit dem rasanten Wachstum des Kernel-Codes und der Funktionsmerkmale nimmt auch die Anzahl der Konfigurationsoptionen im Kernel rapide zu, wobei der Linux-Kernel 3.0 und höher über mehr als 10.000 Konfigurationsoptionen verfügt.
3.2. Konfigurationssprache
Der Linux-Kernel verwendet die Konfigurationssprache KConfig, um dem Compiler mitzuteilen, welcher Code in den kompilierten Kernel aufgenommen werden soll, sodass Konfigurationsoptionen und Abhängigkeiten zwischen ihnen definiert werden können.
Der Wert einer Konfigurationsoption in KConfig kann bool, tristate oder konstant sein. bool bedeutet, dass der Code entweder statisch in eine Kernel-Binärdatei kompiliert oder ausgeschlossen wird, während tristate die Kompilierung des Codes in ein ladbares Kernmodul ermöglicht, d. h. ein eigenständiges Objekt, das zur Laufzeit geladen werden kann. Die Konstante kann eine Zeichenfolge oder einen numerischen Wert für eine Kernel-Codevariable bereitstellen. Eine Option kann von einer anderen Option abhängen, und KConfig verwendet einen rekursiven Prozess, indem Abhängigkeiten rekursiv ausgewählt und aufgehoben werden. Die endgültige Kernelkonfiguration weist gültige Abhängigkeiten auf, kann jedoch von Benutzereingaben abweichen.
3.3. Konfigurationsvorlage
Der Linux-Kernel enthält viele handgefertigte Konfigurationsvorlagen. Aufgrund der fest codierten Natur von Konfigurationsvorlagen und der Notwendigkeit manueller Eingriffe sind sie jedoch nicht an verschiedene Hardwareplattformen anpassbar und verstehen die Anforderungen der Anwendung nicht. Beispielsweise können mit tinyconfig erstellte Kernel nicht auf Standardhardware booten, geschweige denn andere Anwendungen unterstützen. Einige Tools behandeln „localmodconfig“ als Minimalkonfiguration. Allerdings gelten für „localmodconfig“ dieselben Einschränkungen wie für eine statische Konfigurationsvorlage: Es aktiviert keine C-Präprozessor-Konfigurationsoptionen auf Steueranweisungs- oder Funktionsebene und verarbeitet keine ladbaren Kernel.
Die kvmconfig- und xenconfig-Vorlagen sind für Kernel angepasst, die auf KVM und Xen laufen. Sie stellen Domänenwissen wie die zugrunde liegende Virtualisierungs- und Hardwareumgebung bereit.
3.4. Linux-Kernel-Konfiguration in der Cloud
Linux ist der dominierende Betriebssystemkernel in Cloud-Diensten, und Cloud-Anbieter haben den gewöhnlichen Linux-Kernel teilweise aufgegeben. Die Anpassung durch Cloud-Anbieter erfolgt häufig durch das direkte Entfernen ladbarer Kernelmodule. Das Problem beim manuellen Bereinigen von Kernelmodul-Binärdateien besteht darin, dass Abhängigkeiten verletzt werden können. Wichtig ist, dass die Kerne je nach Anwendungsanforderungen weiter angepasst werden können. Beispielsweise ist der Amazon FireCracker-Kernel eine winzige virtuelle Maschine, die für Funktionen als Dienst konzipiert ist und HTTPD als Zielanwendung verwendet. Dies ermöglicht eine stärkere Minimierung der Kernel-Anpassung und gewährleistet gleichzeitig eine höhere Funktionalität und Leistung.
4. Gedanken zum Kernel-Beschneiden
Zur Einschränkung 1: Ist es möglich, die Ablaufverfolgung auf Befehlsebene von QEMU zu verwenden, um Sichtbarkeit in der Startphase zu erreichen? Auf diese Weise kann der Kernel-Code zurückverfolgt und den Kernel-Konfigurationsoptionen zugeordnet werden. Da die Boot-Phase für die Erstellung eines bootfähigen Kernels von entscheidender Bedeutung ist, nutzen Sie die vom Hypervisor bereitgestellten Tracing-Funktionen, um eine durchgängige Beobachtbarkeit zu erreichen und einen stabilen Kernel zu erstellen.
Zur Einschränkung zwei: Basierend auf der Erfahrung im NLP-Deep-Learning kann eine Kombination aus Offline- und Online-Methoden verwendet werden. Bei einer Reihe von Zielanwendungen kann die App-Konfiguration direkt offline generiert und dann mit der Basiskonfiguration kombiniert werden, um eine zu bilden vollständige Kernelkonfiguration Dies führt zu einem abgeschnittenen Kernel. Diese Zusammensetzbarkeit ermöglicht die schrittweise Erstellung neuer Kernel durch Wiederverwendung von Anwendungskonfigurationen und zuvor erstellten Dateien (z. B. Kernelmodulen). Wenn die Konfiguration der Zielanwendung bekannt ist, kann die Kernel-Bereinigung in wenigen Sekunden durchgeführt werden.
Zur Einschränkung drei: Die Verwendung der Ablaufverfolgung auf Befehlsebene kann die Kernel-Konfigurationsoptionen lösen, die die internen Funktionsmerkmale von Funktionen steuern. Der Mehraufwand der Ablaufverfolgung auf Befehlsebene ist für die Ausführung von Testsuiten und Leistungsbenchmarks akzeptabel.
Was Einschränkung vier betrifft: Eine grundlegende Einschränkung bei der Verwendung dynamischer Ablaufverfolgung ist die Unvollkommenheit von Testsuiten und Benchmarks. Viele Open-Source-Anwendungstestsuiten weisen eine geringe Codeabdeckung auf. Durch die Kombination verschiedener Workloads zur Steuerung von Anwendungen kann diese Einschränkung bis zu einem gewissen Grad gemildert werden.
Für Einschränkung fünf können domänenspezifische Informationen verwendet werden, um den Kernel weiter zu laden, indem Kernelmodule entfernt werden, die im Basiskernel ausgeführt werden, aber beim Ausführen der eigentlichen Bereitstellung nicht benötigt werden. Am Beispiel von Xen und KVM kann die Kernelgröße basierend auf den Konfigurationsvorlagen xenconfig und kvmconfig weiter reduziert werden. Durch anwendungsorientierte Kernel-Anpassung kann die Kernel-Größe weiter reduziert und der Kernel-Code sogar umfassend angepasst werden.
5 Vorstudie zum Kernel Clipping Framework
Das Prinzip des Kernel-Anpassungs-Frameworks hat sich nicht geändert. Es verfolgt weiterhin die Kernel-Nutzung der Zielanwendungs-Workload, um die erforderlichen Kernel-Optionen zu ermitteln.
5.1 Kernfunktionen des Kernel-Clipping-Frameworks
Das Kernel-Clipping-Framework kann wahrscheinlich die folgenden Eigenschaften haben:
Durchgängige Sichtbarkeit. Nutzen Sie die Sichtbarkeit des Hypervisors, um eine End-to-End-Beobachtung zu erreichen. Sie können die Kernel-Startphase und die Anwendungsauslastung verfolgen und versuchen, ein maßgeschneidertes Framework für den Linux-Kernel basierend auf QEMU zu erstellen.
Zusammensetzbarkeit. Eine Kernidee besteht darin, die Kombination der Kernel-Konfiguration durch die Aufteilung in mehrere Konfigurationssätze zu ermöglichen, sowohl für das Booten des Kernels in einer bestimmten Bereitstellungsumgebung als auch für die von der Zielanwendung benötigten Konfigurationsoptionen. Konfigurationssätze werden in zwei Typen unterteilt: Basiskonfiguration und Anwendungskonfiguration. Bei einer Basiskonfiguration handelt es sich nicht unbedingt um den Mindestsatz an Konfigurationen, der zum Starten auf einer bestimmten Hardware erforderlich ist, sondern vielmehr um einen Satz von Konfigurationsoptionen, die während der Startphase verfolgt werden. Die Basiskonfiguration kann mit einer oder mehreren Anwendungskonfigurationen kombiniert werden, um die endgültige Kernelkonfiguration zu erstellen.
Wiederverwendbarkeit. Sowohl Basis- als auch Anwendungskonfigurationen können in der Datenbank gespeichert und wiederverwendet werden, solange die Bereitstellungsumgebung und die Anwendungsbinärdateien unverändert bleiben. Diese Wiederverwendbarkeit vermeidet wiederholte Ausführungen der Ablaufverfolgungsarbeitslast und macht die Erstellung von Konfigurationssätzen zu einer einmaligen Aufgabe.
Unterstützen Sie eine schnelle Anwendungsbereitstellung. Bei gegebener Bereitstellungsumgebung und Zielanwendung kann das Kernel-Anpassungs-Framework Basiskonfigurationen und Anwendungskonfigurationen effizient abrufen, sie zur erforderlichen Kernel-Konfiguration kombinieren und dann die resultierende Konfiguration zum Erstellen des veralteten Kernels verwenden.
Feingranulares Konfigurations-Tracing, programmzählerbasiertes Tracing zur Identifizierung von Konfigurationsoptionen basierend auf Codemustern auf niedriger Ebene.
5.2 Architektur des Kernel Clipping Framework
Das Kernel-Clipping-Framework sollte sowohl Offline- als auch Online-Systeme haben. Die Architektur ist wie in der Abbildung unten dargestellt: 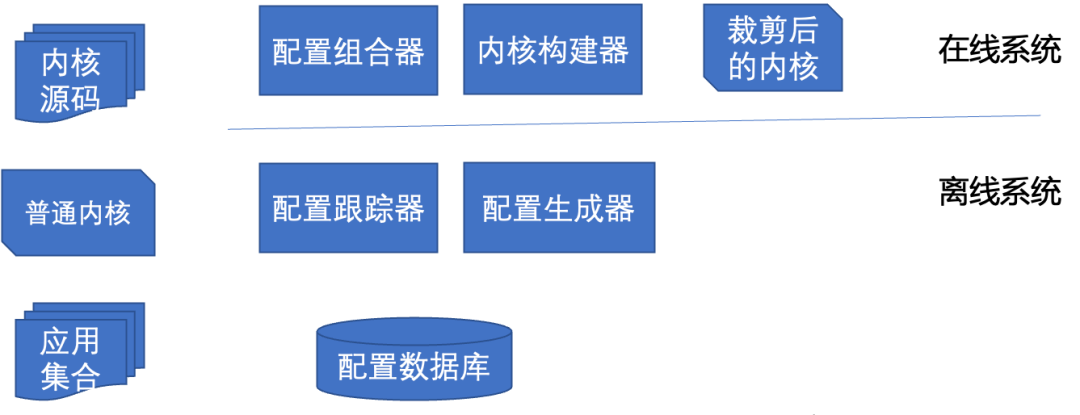
Über das Offline-System wird der Konfigurations-Tracker verwendet, um die für die Bereitstellungsumgebung und -anwendung erforderlichen Konfigurationsoptionen zu verfolgen und aufzuzeichnen. Der Konfigurationsgenerator verarbeitet diese Optionen in Basiskonfigurations- und Anwendungskonfigurationsoptionen und speichert sie in der Konfigurationsdatenbank.
Über das Online-System generiert der Konfigurationskombinator die Basiskonfiguration und die Anwendungskonfiguration, um die Zielkernelkonfiguration zu generieren, und dann generiert der Kernel-Builder den maßgeschneiderten Linux-Kernel
5.3 Machbarkeit der Implementierung des Kernel Clipping Framework
Konfigurationsverfolgung
Der Konfigurations-Tracker des Kernel-Anpassungs-Frameworks verfolgt Konfigurationsoptionen während der Kernel-Ausführung, die von einer Zielanwendung gesteuert wird, und verwendet dabei das PC-Register, um die Adresse der ausführenden Anweisung zu erfassen. Um sicherzustellen, dass der getrackte PC zur Zielanwendung und nicht zu anderen Prozessen (z. B. Hintergrunddiensten) gehört, kann ein angepasstes Init-Skript verwendet werden, das keine anderen Anwendungen startet und lediglich das Dateisystem /tmp, / mountet. proc und /sys, aktivieren Sie die Netzwerkschnittstellen (lo und eth0) und starten Sie schließlich die Anwendung direkt nach dem Kernel-Boot.
Gleichzeitig kann es erforderlich sein, das zufällige Laden der Kernel-Adressraumkonfiguration zu deaktivieren, damit Adressen korrekt dem Quellcode zugeordnet werden können, aber dennoch im beschnittenen Kernel verfügbar sind. Ordnen Sie dann PCs den Quellcodeanweisungen zu. Ladebare Kernelmodule erfordern zusätzliche Verarbeitung. Sie können /proc/module verwenden, um die Startadresse jedes geladenen Kernelmoduls abzurufen und diese PCs Anweisungen in der Kernelmodul-Binärdatei zuzuordnen. Eine Alternative ist die Verwendung von „localmodconfig“. Allerdings stellt „localmodconfig“ nur Informationen auf Modulgranularitätsebene bereit.
Ordnen Sie abschließend die Anweisung der Konfiguration zu. Im C-Präprozessor-basierten Modus wird die C-Quelldatei analysiert, um Präprozessordirektiven zu extrahieren, und anschließend wird überprüft, ob Anweisungen in diesen Direktiven ausgeführt werden. Bestimmt im Makefile-basierten Modus, ob Konfigurationsoptionen auf der Ebene der Objektdateigranularität ausgewählt werden sollen. Wenn beispielsweise eine der entsprechenden Dateien (bind.o, achefiles.o oder daemon.o) verwendet wird, muss CONFIG_CACHEFILES ausgewählt werden.
Konfigurationsgenerierung
Die Basiskonfiguration und die Anwendungskonfiguration werden im Offline-System generiert. Wie ist das Ende der Startup-Phase einzuschätzen? Eine leere Stub-Funktion kann mithilfe von mmap einem vordefinierten Adresssegment zugeordnet werden. Das oben beschriebene Init-Skript ruft die Stub-Funktion auf, bevor die Zielanwendung ausgeführt wird, sodass das Ende der Startphase anhand der vordefinierten Adresse im PC identifiziert werden kann verfolgen.
Das Kernel-Anpassungsframework ruft Konfigurationsoptionen von der Anwendung ab und filtert hardwarebezogene Optionen heraus, die während der Startphase beobachtet werden. Diese Hardwarefunktionen werden basierend auf ihrer Position im Kernel-Quellcode definiert. Es kann nicht ausgeschlossen werden, dass hardwarebedingte Optionen erst während der Anwendungsausführung beobachtet werden, z. B. wenn neue Gerätetreiber geladen werden.
Konfiguration und Montage
Durch die Kombination der Basiskonfiguration mit einer oder mehreren Anwendungskonfigurationen entsteht die endgültige Konfiguration, die zum Erstellen des Kernels verwendet wird. Zunächst werden alle Konfigurationsoptionen zu einer Ausgangskonfiguration zusammengeführt und anschließend die Abhängigkeiten zwischen ihnen mithilfe des SAT-Solvers aufgelöst. Versuchen Sie, Konfigurationsabhängigkeiten als boolesches Erfüllbarkeitsproblem zu modellieren, wobei eine gültige Konfiguration alle angegebenen Abhängigkeiten zwischen Konfigurationsoptionen erfüllt. Die Modellierung der Kernel-Konfiguration basiert auf einem SAT-Solver, da KConfig nicht sicherstellt, dass alle ausgewählten Optionen enthalten sind, sondern stattdessen nicht erfüllte Abhängigkeiten abwählt.
Kernel Build
KBuild für Linux erstellt einen maßgeschneiderten Kernel auf der Grundlage zusammengestellter Konfigurationsoptionen. Inkrementelle Builds können die Build-Zeiten optimieren und auch frühere Build-Ergebnisse (z. B. Objektdateien und Kernel-Module) zwischenspeichern, um redundante Kompilierungen und Links zu vermeiden. Bei einer Konfigurationsänderung werden nur die Module neu erstellt, die Änderungen an den Konfigurationsoptionen vorgenommen haben, während andere Dateien wiederverwendet werden können.
6. Zusammenfassung
Aufgrund der Instabilität des Betriebssystemkerns, der schlechten Aktualität, Integritätsproblemen und der Notwendigkeit manueller Eingriffe wurde die Linux-Kernel-Bereinigungstechnologie nicht weit verbreitet eingesetzt. Nachdem wir die Einschränkungen der vorhandenen Technologie verstanden haben, versuchen wir, ein Linux-Kernel-Anpassungsframework vorzuschlagen, das diese Probleme möglicherweise lösen kann.
Das obige ist der detaillierte Inhalt vonEine vorläufige Studie zum Linux-Kernel-Pruning-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!