
Heim >System-Tutorial >LINUX >Eine kurze Analyse der Linux-Gruppenplanung
Eine kurze Analyse der Linux-Gruppenplanung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-10 17:06:291077Durchsuche
Linux-System ist ein Betriebssystem, das die gleichzeitige Ausführung mehrerer Aufgaben unterstützt. Es kann mehrere Prozesse gleichzeitig ausführen und dadurch die Systemauslastung und -effizienz verbessern. Damit ein Linux-System jedoch eine optimale Leistung erzielen kann, ist es notwendig, seine Prozessplanungsmethode zu verstehen und zu beherrschen. Unter Prozessplanung versteht man die Funktion des Betriebssystems, die Prozessorressourcen basierend auf bestimmten Algorithmen und Strategien dynamisch verschiedenen Prozessen zuweist, um eine gleichzeitige Ausführung mehrerer Aufgaben zu erreichen. In Linux-Systemen gibt es viele Prozessplanungsmethoden, darunter die Gruppenplanung. Gruppenplanung ist eine gruppenbasierte Prozessplanungsmethode, die es verschiedenen Prozessgruppen ermöglicht, Prozessorressourcen in einem bestimmten Verhältnis zu teilen und so ein Gleichgewicht zwischen Fairness und Effizienz zu erreichen. In diesem Artikel wird die Linux-Gruppenplanungsmethode kurz analysiert, einschließlich des Prinzips, der Implementierung, der Konfiguration sowie der Vor- und Nachteile der Gruppenplanung.
Gruppen- und Gruppenplanung
Der Linux-Kernel implementiert die Kontrollgruppenfunktion (cgroup, seit Linux 2.6.24), die das Gruppieren von Prozessen und das anschließende Aufteilen verschiedener Ressourcen nach Gruppen unterstützen kann. Beispiel: Gruppe-1 hat 30 % CPU und 50 % Festplatten-IO, Gruppe-2 hat 10 % CPU und 20 % Festplatten-IO und so weiter. Weitere Informationen finden Sie in den Artikeln zu cgroup.
cgroup unterstützt die Aufteilung vieler Arten von Ressourcen, und CPU-Ressourcen sind eine davon, was zur Gruppenplanung führt.
Im Linux-Kernel wird der herkömmliche Scheduler basierend auf Prozessen geplant. Angenommen, Benutzer A und B teilen sich einen Computer, der hauptsächlich zum Kompilieren von Programmen verwendet wird. Wir können hoffen, dass A und B die CPU-Ressourcen fair teilen können, aber wenn Benutzer A make -j8 (8 Threads paralleles Make) verwendet und Benutzer B make direkt verwendet (vorausgesetzt, dass ihre Make-Programme die Standardpriorität verwenden), wird das Make-Programm von Benutzer A verwendet generiert 8-mal so viele Prozesse wie Benutzer B und belegt somit (ungefähr) 8-mal die CPU von Benutzer B. Da der Scheduler prozessbasiert ist, gilt: Je mehr Prozesse Benutzer A hat, desto größer ist die Wahrscheinlichkeit, dass er geplant wird, und desto konkurrenzfähiger ist er gegenüber der CPU.
Wie kann sichergestellt werden, dass Benutzer A und B die CPU fair teilen? Die Gruppenplanung kann dies tun. Die Prozesse der Benutzer A und B werden in jeweils eine Gruppe unterteilt. Der Planer wählt zunächst eine Gruppe aus den beiden Gruppen aus und wählt dann einen Prozess aus der ausgewählten Gruppe zur Ausführung aus. Wenn die beiden Gruppen die gleichen Chancen haben, ausgewählt zu werden, belegen Benutzer A und B jeweils etwa 50 % der CPU.
Verwandte Datenstrukturen
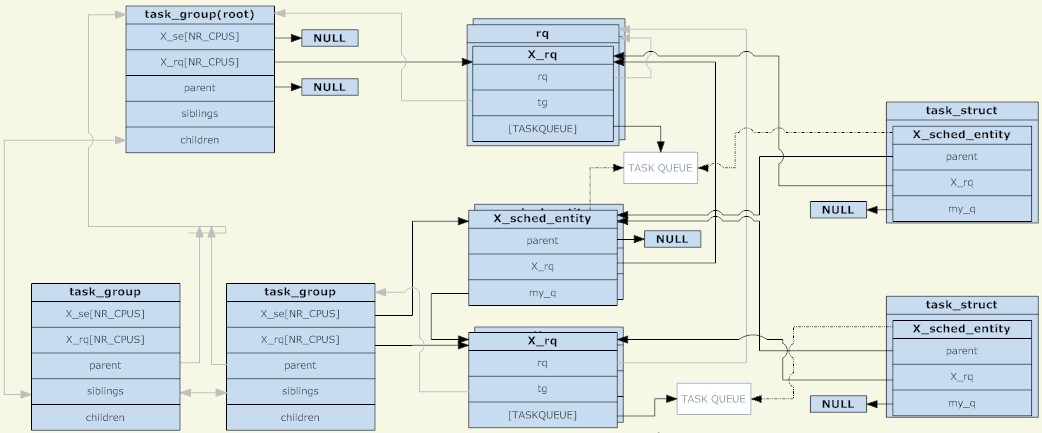
Im Linux-Kernel wird die task_group-Struktur zum Verwalten von Gruppen für die Gruppenplanung verwendet. Alle vorhandenen task_groups bilden eine Baumstruktur (entsprechend der Verzeichnisstruktur von cgroup).
Eine task_group kann Prozesse mit jeder Planungskategorie enthalten (insbesondere Echtzeitprozesse und gewöhnliche Prozesse), daher muss task_group einen Satz Planungsstrukturen für jede Planungsstrategie bereitstellen. Der hier erwähnte Satz von Planungsstrukturen besteht hauptsächlich aus zwei Teilen, der Planungseinheit und der Ausführungswarteschlange (beide werden pro CPU gemeinsam genutzt). Die Planungseinheit wird zur Ausführungswarteschlange einer Taskgruppe hinzugefügt.
Warum gibt es so etwas wie eine Planungseinheit? Da es zwei Arten geplanter Objekte gibt: task_group und task, ist eine abstrakte Struktur erforderlich, um sie darzustellen. Wenn die Planungseinheit eine Taskgruppe darstellt, zeigt ihr Feld „my_q“ auf die Ausführungswarteschlange, die dieser Planungsgruppe entspricht. Andernfalls ist das Feld „my_q“ NULL und die Planungseinheit stellt eine Aufgabe dar. Das Gegenteil von my_q in der Planungsentität ist die Ausführungswarteschlange des übergeordneten Knotens. Dies ist die Ausführungswarteschlange, in der diese Planungsentität platziert werden soll.
Die Planungseinheit und die Ausführungswarteschlange bilden also eine weitere Baumstruktur. Jeder ihrer Nicht-Blattknoten entspricht der Baumstruktur von task_group, und die Blattknoten entsprechen bestimmten Aufgaben. Ebenso wie Prozesse im Nicht-TASK_RUNNING-Status nicht in die Ausführungswarteschlange gestellt werden, wird diese Gruppe (entsprechende Planungseinheit) nicht in die Ausführungswarteschlange der oberen Ebene gestellt, wenn sich in einer Gruppe kein Prozess im Status TASK_RUNNING befindet. Um es klarzustellen: Solange die Planungsgruppe erstellt wird, ist die entsprechende Taskgruppe definitiv in der Baumstruktur vorhanden, die aus der Taskgruppe besteht. Ob die entsprechende Planungseinheit in der Baumstruktur vorhanden ist, die aus der Ausführungswarteschlange und der Planungseinheit besteht, hängt davon ab, ob In dieser Gruppe befindet sich ein Prozess im Status TASK_RUNNING.
Die task_group als Root-Knoten hat keine Planungseinheit. Der Scheduler startet immer von seiner Ausführungswarteschlange, um die nächste Planungseinheit auszuwählen (der Root-Knoten muss der erste sein, der ausgewählt wird, und es gibt keine anderen Kandidaten, daher ist dies für den Root-Knoten nicht der Fall Planungsentitäten sind erforderlich). Die der Task_group des Stammknotens entsprechende Ausführungswarteschlange ist in einer RQ-Struktur verpackt, die zusätzlich zur spezifischen Ausführungswarteschlange auch einige globale statistische Informationen und andere Felder enthält.
Wenn die Planung erfolgt, wählt der Planer eine Planungseinheit aus der Ausführungswarteschlange der Stammaufgabengruppe aus. Wenn diese Planungseinheit eine Aufgabengruppe darstellt, muss der Planer weiterhin eine dieser Gruppe entsprechende Planungseinheit aus der Ausführungswarteschlange auswählen. Diese Rekursion wird fortgesetzt, bis ein Prozess ausgewählt wird. Sofern die Ausführungswarteschlange der Root-Taskgruppe nicht leer ist, wird durch Rekursion auf jeden Fall ein Prozess gefunden. Denn wenn die einer Taskgruppe entsprechende Ausführungswarteschlange leer ist, wird die entsprechende Planungseinheit nicht zur Ausführungswarteschlange hinzugefügt, die ihrem übergeordneten Knoten entspricht.
Schließlich werden für eine Taskgruppe die Planungseinheit und die Ausführungswarteschlange pro CPU gemeinsam genutzt, und eine Planungseinheit (entsprechend der Taskgruppe) wird nur zur Ausführungswarteschlange hinzugefügt, die derselben CPU entspricht. Für eine Aufgabe gibt es nur eine Kopie der Planungseinheit (nicht nach CPU unterteilt). Die Lastausgleichsfunktion des Schedulers kann die Planungseinheit (entsprechend der Aufgabe) aus der Ausführungswarteschlange verschieben, die verschiedenen CPUs entspricht.
Planungsstrategie für die Gruppe
Die Hauptdatenstruktur der Gruppenplanung wurde geklärt, aber hier gibt es immer noch ein sehr wichtiges Problem. Wir wissen, dass Aufgaben ihre entsprechenden Prioritäten haben (statische Priorität oder dynamische Priorität), und der Scheduler wählt Prozesse in der Ausführungswarteschlange basierend auf der Priorität aus. Da also „task_group“ und „task“ beide in Planungseinheiten abstrahiert sind und dieselbe Planung akzeptieren, wie sollte die Priorität von „task_group“ definiert werden? Diese Frage muss speziell von der Planungskategorie beantwortet werden (verschiedene Planungskategorien haben unterschiedliche Prioritätsdefinitionen), insbesondere von RT (Echtzeitplanung) und CFS (vollkommen faire Planung).
Gruppenplanung von Echtzeitprozessen
Wie aus dem Artikel „Eine kurze Analyse der Linux-Prozessplanung“ hervorgeht, ist ein Echtzeitprozess ein Prozess, der Echtzeitanforderungen an die CPU stellt. Seine Priorität hängt mit bestimmten Aufgaben zusammen und wird vollständig vom Benutzer definiert . Der Scheduler wählt immer den auszuführenden Echtzeitprozess mit der höchsten Priorität aus.
Mit der Entwicklung der Gruppenplanung wird die Priorität der Gruppe als „die Priorität des Prozesses mit der höchsten Priorität in der Gruppe“ definiert. Wenn die Gruppe beispielsweise drei Prozesse mit den Prioritäten 10, 20 und 30 enthält, beträgt die Priorität der Gruppe 10 (je kleiner der Wert, desto höher die Priorität).
Die Priorität der Gruppe wird auf diese Weise definiert, was zu einem interessanten Phänomen führt. Wenn eine Aufgabe in die Warteschlange gestellt oder aus der Warteschlange entfernt wird, müssen zuerst alle ihre Vorgängerknoten aus der Warteschlange entfernt und dann von unten nach oben erneut in die Warteschlange gestellt werden. Da die Priorität eines Gruppenknotens von seinen untergeordneten Knoten abhängt, wirkt sich das Ein- und Ausreihen von Aufgaben auf jeden seiner Vorgängerknoten aus.
Wenn der Scheduler also die Planungseinheit aus der task_group des Wurzelknotens auswählt, kann er immer die höchste Priorität unter allen Echtzeitprozessen im Status TASK_RUNNING entlang des richtigen Pfads finden. Diese Implementierung erscheint natürlich, aber wenn Sie sorgfältig darüber nachdenken, welchen Sinn hat es, Echtzeitprozesse auf diese Weise zu gruppieren? Unabhängig von der Gruppierung oder nicht muss der Planer „denjenigen mit der höchsten Priorität unter allen Echtzeitprozessen im Status TASK_RUNNING auswählen“. Hier scheint etwas zu fehlen...
Jetzt müssen wir die beiden Proc-Dateien im Linux-System einführen: /proc/sys/kernel/sched_rt_period_us und /proc/sys/kernel/sched_rt_runtime_us. Diese beiden Dateien legen fest, dass innerhalb eines Zeitraums mit sched_rt_period_us als Zeitraum die Summe der Laufzeit aller Echtzeitprozesse sched_rt_runtime_us nicht überschreiten darf. Die Standardwerte dieser beiden Dateien sind 1s und 0,95s, was bedeutet, dass jede Sekunde ein Zyklus ist. In diesem Zyklus überschreitet die Gesamtlaufzeit aller Echtzeitprozesse 0,95 Sekunden nicht und die verbleibenden mindestens 0,05 Sekunden Sekunden werden für normale Prozesse reserviert. Mit anderen Worten: Der Echtzeitprozess belegt nicht mehr als 95 % der CPU. Bevor diese beiden Dateien erschienen, gab es keine Begrenzung der Laufzeit von Echtzeitprozessen. Wenn sich Echtzeitprozesse immer im Status TASK_RUNNING befänden, könnten normale Prozesse niemals ausgeführt werden. Äquivalent zu sched_rt_runtime_us ist gleich sched_rt_period_us.
Warum gibt es zwei Variablen, sched_rt_runtime_us und sched_rt_period_us? Ist es nicht möglich, direkt eine Variable zu verwenden, die den Prozentsatz der CPU-Auslastung darstellt? Ich denke, das liegt daran, dass viele Echtzeitprozesse tatsächlich periodisch etwas tun, etwa dass ein Sprachprogramm alle 20 ms ein Sprachpaket sendet, ein Videoprogramm alle 40 ms einen Frame aktualisiert und so weiter. Zeiträume sind wichtig, und die bloße Verwendung eines Makro-CPU-Belegungsverhältnisses kann die Prozessanforderungen in Echtzeit nicht genau beschreiben.
Die Gruppierung von Echtzeitprozessen erweitert die Konzepte von sched_rt_runtime_us und sched_rt_period_us. Jede Taskgruppe verfügt über ihre eigene sched_rt_runtime_us und sched_rt_period_us, wodurch sichergestellt wird, dass die Prozesse in ihrer eigenen Gruppe nur so lange innerhalb des Zeitraums von sched_rt_period_us ausgeführt werden können. Das CPU-Belegungsverhältnis beträgt sched_rt_runtime_us/sched_rt_period_us.
Für die Taskgruppe des Stammknotens entsprechen ihre sched_rt_runtime_us und sched_rt_period_us den Werten in den beiden oben genannten Proc-Dateien. Unter der Annahme, dass sich für einen Task_Group-Knoten n Planungsuntergruppen und m Prozesse im Status TASK_RUNNING befinden, sein CPU-Belegungsverhältnis A und das CPU-Belegungsverhältnis dieser n Untergruppen B beträgt, muss B kleiner oder gleich A sein. , und die verbleibende CPU-Zeit von A-B wird den m Prozessen im Status TASK_RUNNING zugewiesen. (Was hier diskutiert wird, ist das CPU-Belegungsverhältnis, da jede Planungsgruppe unterschiedliche Zykluswerte haben kann.)
Um die Logik von sched_rt_runtime_us und sched_rt_period_us zu implementieren, fügt der Kernel die entsprechende Laufzeit zur Planungseinheit des aktuellen Prozesses hinzu, wenn der Kernel die Laufzeit eines Prozesses aktualisiert (z. B. eine Zeitaktualisierung, die durch einen periodischen Taktinterrupt ausgelöst wird). und alle seine Vorgängerknoten. Wenn eine Planungsentität die durch sched_rt_runtime_us begrenzte Zeit erreicht, wird sie aus der entsprechenden Ausführungswarteschlange entfernt und der entsprechende rt_rq wird in den gedrosselten Zustand versetzt. In diesem Zustand tritt die Planungseinheit, die rt_rq entspricht, nicht erneut in die Ausführungswarteschlange ein. Jeder rt_rq verwaltet einen periodischen Timer mit einer Zeitperiode von sched_rt_period_us. Jedes Mal, wenn der Timer ausgelöst wird, subtrahiert seine entsprechende Rückruffunktion einen sched_rt_period_us-Einheitswert von der Laufzeit von rt_rq (belässt die Laufzeit jedoch nicht unter 0) und stellt dann rt_rq aus dem gedrosselten Zustand wieder her.
Es gibt noch eine weitere Frage: Standardmäßig überschreitet die Laufzeit von Echtzeitprozessen im System nicht 0,95 Sekunden pro Sekunde. Wenn der tatsächliche CPU-Bedarf des Echtzeitprozesses weniger als 0,95 Sekunden beträgt (größer oder gleich 0 Sekunden und weniger als 0,95 Sekunden), wird die verbleibende Zeit normalen Prozessen zugewiesen. Und wenn der CPU-Bedarf des Echtzeitprozesses mehr als 0,95 Sekunden beträgt, kann er nur 0,95 Sekunden lang ausgeführt werden und die restlichen 0,05 Sekunden werden anderen normalen Prozessen zugewiesen. Was aber, wenn während dieser 0,05 Sekunden kein gewöhnlicher Prozess die CPU nutzen muss (normale Prozesse, die keinen TASK_RUNNING-Status haben)? Kann der Echtzeitprozess in diesem Fall länger als 0,95 Sekunden laufen, da der normale Prozess keine Anforderungen an die CPU stellt? kann nicht. In den verbleibenden 0,05 Sekunden möchte der Kernel die CPU lieber im Leerlauf lassen, als sie vom Echtzeitprozess nutzen zu lassen. Es ist ersichtlich, dass sched_rt_runtime_us und sched_rt_period_us sehr obligatorisch sind.
Schließlich gibt es noch das Problem mehrerer CPUs. Wie bereits erwähnt, werden für jede Taskgruppe ihre Planungseinheit und ihre Ausführungswarteschlange pro CPU verwaltet. sched_rt_runtime_us und sched_rt_period_us wirken sich auf die Planungseinheit aus. Wenn also N CPUs im System vorhanden sind, beträgt die Obergrenze der tatsächlich vom Echtzeitprozess belegten CPU N*sched_rt_runtime_us/sched_rt_period_us. Das heißt, der Echtzeitprozess kann trotz des Standardlimits von einer Sekunde nur 0,95 Sekunden lang laufen. Aber wenn die CPU bei einem Echtzeitprozess über zwei Kerne verfügt, kann sie immer noch den Bedarf decken, 100 % der CPU zu belegen (z. B. die Ausführung einer Endlosschleife). Dann liegt es auf der Hand, dass 100 % der von diesem Echtzeitprozess belegten CPU aus zwei Teilen bestehen sollten (jede CPU belegt einen Teil, jedoch nicht mehr als 95 %). Um jedoch eine Reihe von Problemen wie Kontextwechsel und Cache-Ungültigmachung zu vermeiden, die durch die Prozessmigration zwischen CPUs verursacht werden, kann die Planungseinheit auf einer CPU Zeit von der entsprechenden Planungseinheit auf einer anderen CPU leihen. Das Ergebnis ist, dass es makroskopisch nicht nur die Einschränkungen von sched_rt_runtime_us erfüllt, sondern auch eine Prozessmigration vermeidet.
Gruppenplanung gewöhnlicher Prozesse
Am Anfang des Artikels wurde erwähnt, dass zwei Benutzer A und B die CPU-Anforderungen gleichmäßig teilen können, auch wenn die Anzahl der Prozesse unterschiedlich ist. Die oben beschriebene Gruppenplanungsstrategie für Echtzeitprozesse scheint jedoch nicht relevant zu sein Dies ist in der Tat die Anforderung, die der Gruppenplaner erfüllen muss.
Verglichen mit Echtzeitprozessen ist die Gruppenplanung gewöhnlicher Prozesse nicht so speziell. Eine Gruppe wird fast als die gleiche Einheit wie ein Prozess behandelt. Sie hat ihre eigene statische Priorität und der Scheduler passt ihre Priorität dynamisch an. Bei einer Gruppe hat die Priorität der Prozesse in der Gruppe keinen Einfluss auf die Priorität der Gruppe. Die Priorität dieser Prozesse wird nur berücksichtigt, wenn die Gruppe vom Planer ausgewählt wird.
Um die Priorität der Gruppe festzulegen, verfügt jede task_group über einen Shares-Parameter (parallel zu den beiden zuvor erwähnten Parametern sched_rt_runtime_us und sched_rt_period_us). Anteile sind keine Prioritäten, sondern das Gewicht der Planungseinheit (so verhält sich der CFS-Scheduler). Es besteht eine Eins-zu-eins-Entsprechung zwischen diesem Gewicht und der Priorität. Die Priorität eines gewöhnlichen Prozesses wird auch in die Gewichtung seiner entsprechenden Planungseinheit umgewandelt, sodass man sagen kann, dass Anteile die Priorität darstellen.
Der Standardwert der Anteile entspricht der Gewichtung, die der Standardpriorität gewöhnlicher Prozesse entspricht. Standardmäßig teilen sich die Gruppe und der Prozess die CPU zu gleichen Teilen.
Beispiel
(Umgebung: Ubuntu 10.04, Kernel 2.6.32, Intel Core2 Dual Core)
Montieren Sie eine cgroup, die nur CPU-Ressourcen aufteilt, und erstellen Sie zwei Untergruppen grp_a und grp_b:
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
Öffnen Sie jeweils drei Shells, fügen Sie grp_a zur ersten und grp_b zu den letzten beiden hinzu:
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der Linux-Gruppenplanung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!