
Heim >System-Tutorial >LINUX >Der CPU-Lastausgleichsmechanismus des Linux-Kernels: Prinzipien, Prozesse und Optimierungen
Der CPU-Lastausgleichsmechanismus des Linux-Kernels: Prinzipien, Prozesse und Optimierungen

- 王林nach vorne
- 2024-02-09 13:50:111239Durchsuche
CPU-Lastausgleich bezieht sich auf die Zuweisung laufender Prozesse oder Aufgaben zu verschiedenen CPUs in einem Mehrkern- oder Mehrprozessorsystem, sodass die Last jeder CPU so weit wie möglich ausgeglichen wird und dadurch die Systemleistung und -effizienz verbessert wird. Der CPU-Lastausgleich ist eine wichtige Funktion des Linux-Kernels. Er ermöglicht es dem Linux-System, die Vorteile von Multi-Core- oder Multi-Prozessoren voll auszunutzen, um sich an verschiedene Anwendungsszenarien und Anforderungen anzupassen. Aber verstehen Sie wirklich den CPU-Lastausgleichsmechanismus des Linux-Kernels? Kennen Sie das Funktionsprinzip, den Prozess und die Optimierungsmethode? In diesem Artikel werden Ihnen die relevanten Kenntnisse des CPU-Lastausgleichsmechanismus des Linux-Kernels im Detail vermittelt, sodass Sie diese leistungsstarke Kernelfunktion unter Linux besser nutzen und verstehen können.
Es wird immer noch durch ein magisches Prozessplanungsproblem verursacht. Bitte beachten Sie die Analyse des Gruppenplanungsmechanismus. Es wurde deutlich, dass während des Neustartvorgangs viele Kernel-Aufrufstapel blockiert sind Die Funktion „double_rq_lock“ und „double_rq_lock“ werden durch „load_balance“ ausgelöst. Ich vermutete, dass es zu diesem Zeitpunkt ein Problem mit der Inter-Core-Planung gab und es in einem bestimmten verantwortlichen Szenario zu einer Multi-Core-Verriegelung kam balancieren und eine Zusammenfassung schreiben.
Kernel-Code-Version: Kernel-3.0.13-0.27.
Die Kernel-Codefunktion beginnt mit der Funktion „load_balance“, indem Sie sich die Funktionen ansehen, die darauf verweisen. Von hier aus finden Sie den folgenden Satz in __schedule.
if (unlikely(!rq->nr_running)) idle_balance(cpu, rq);
Aus dem Obigen ist ersichtlich, wann der Kernel versucht, einen CPU-Lastausgleich durchzuführen: Das heißt, wenn die aktuelle CPU-Ausführungswarteschlange NULL ist.
Es gibt zwei Methoden zum CPU-Lastausgleich: Pull und Push, das heißt, die inaktive CPU zieht einen Prozess aus anderen ausgelasteten CPU-Warteschlangen in die aktuelle CPU-Warteschlange, oder die ausgelastete CPU-Warteschlange schiebt einen Prozess in die inaktive CPU-Warteschlange. Was empty_balance tut, ist Pull. Der spezifische Push wird unten erwähnt.
In empty_balance gibt es ein Proc-Ventil, um zu steuern, ob die aktuelle CPU gezogen wird:
if (this_rq->avg_idle return;
Die Proc-Steuerdatei, die sysctl_sched_migration_cost entspricht, ist /proc/sys/kernel/sched_migration_cost. Der Schalter bedeutet, dass Pull ausgeführt wird, wenn die CPU-Warteschlange länger als 500us inaktiv ist (Standardwert von sysctl_sched_migration_cost).
for_each_domain(this_cpu, sd) durchläuft die Planungsdomäne, in der sich die aktuelle CPU befindet. Es kann intuitiv als eine CPU-Gruppe verstanden werden, ähnlich wie task_group sich auf das Gleichgewicht innerhalb der Gruppe bezieht. Es gibt einen Widerspruch beim Lastausgleich: Die Häufigkeit des Lastausgleichs stimmt nicht mit der Trefferquote des CPU-Cache überein. Die CPU-Planungsdomäne unterteilt jede CPU in Gruppen mit unterschiedlichen Ebenen. Das auf der niedrigen Ebene erreichte Gleichgewicht wird niemals aktualisiert Hohes Niveau für die Verarbeitung, das die Cache-Trefferrate vermeidet.
Das Bild ist wie folgt;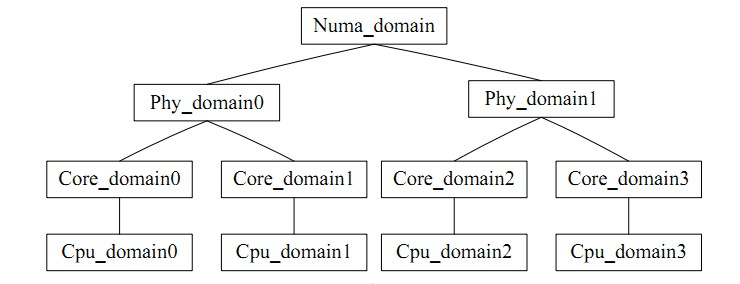
Lassen Sie uns zum Schluss mit Load_balance auf den Punkt kommen.
Erhalten Sie zunächst die am stärksten ausgelastete Planungsgruppe in der aktuellen Planungsdomäne über find_busiest_group. Zuerst aktualisiert update_sd_lb_stats den Status von sd, dh durchläuft den entsprechenden sd und füllt die Strukturdaten wie folgt in sds:
struct sd_lb_stats {
struct sched_group *busiest; /* Busiest group in this sd */
struct sched_group *this; /* Local group in this sd */
unsigned long total_load; /* Total load of all groups in sd */
unsigned long total_pwr; /* Total power of all groups in sd */
unsigned long avg_load; /* Average load across all groups in sd */
/** Statistics of this group */
unsigned long this_load; //当前调度组的负载
unsigned long this_load_per_task; //当前调度组的平均负载
unsigned long this_nr_running; //当前调度组内运行队列中进程的总数
unsigned long this_has_capacity;
unsigned int this_idle_cpus;
/* Statistics of the busiest group */
unsigned int busiest_idle_cpus;
unsigned long max_load; //最忙的组的负载量
unsigned long busiest_load_per_task; //最忙的组中平均每个任务的负载量
unsigned long busiest_nr_running; //最忙的组中所有运行队列中进程的个数
unsigned long busiest_group_capacity;
unsigned long busiest_has_capacity;
unsigned int busiest_group_weight;
do
{
local_group = cpumask_test_cpu(this_cpu, sched_group_cpus(sg));
if (local_group) {
//如果是当前CPU上的group,则进行赋值
sds->this_load = sgs.avg_load;
sds->this = sg;
sds->this_nr_running = sgs.sum_nr_running;
sds->this_load_per_task = sgs.sum_weighted_load;
sds->this_has_capacity = sgs.group_has_capacity;
sds->this_idle_cpus = sgs.idle_cpus;
} else if (update_sd_pick_busiest(sd, sds, sg, &sgs, this_cpu)) {
//在update_sd_pick_busiest判断当前sgs的是否超过了之前的最大值,如果是
//则将sgs值赋给sds
sds->max_load = sgs.avg_load;
sds->busiest = sg;
sds->busiest_nr_running = sgs.sum_nr_running;
sds->busiest_idle_cpus = sgs.idle_cpus;
sds->busiest_group_capacity = sgs.group_capacity;
sds->busiest_load_per_task = sgs.sum_weighted_load;
sds->busiest_has_capacity = sgs.group_has_capacity;
sds->busiest_group_weight = sgs.group_weight;
sds->group_imb = sgs.group_imb;
}
sg = sg->next;
} while (sg != sd->groups);
Das Referenzkriterium für die Auswahl der am stärksten ausgelasteten Gruppe in der Planungsdomäne ist die Summe der Belastungen aller CPUs in der Gruppe. Das Referenzkriterium für die Ermittlung der ausgelasteten Ausführungswarteschlange in der Gruppe ist die Länge der CPU-Ausführungswarteschlange ist die Last. Je größer der Lastwert, desto ausgelasteter ist er. Während des Ausgleichsprozesses werden diese Variablen durch den Vergleich des Auslastungsstatus der aktuellen Warteschlange mit dem zuvor aufgezeichneten Auslastungsstatus zeitnah aktualisiert, sodass der Auslastungsstatus immer auf die am stärksten ausgelastete Gruppe in der Domäne verweist, um die Suche zu erleichtern.
Berechnung der durchschnittlichen Auslastung der Planungsdomäne
sds.avg_load = (SCHED_POWER_SCALE * sds.total_load) / sds.total_pwr; if (sds.this_load >= sds.avg_load) goto out_balanced;
Wenn beim Vergleichen der Lastgröße festgestellt wird, dass die am stärksten ausgelastete Gruppe in der aktuell ausgeführten CPU leer ist oder die aktuell ausgeführte CPU-Warteschlange am stärksten ausgelastet ist oder die Auslastung der aktuellen CPU-Warteschlange nicht unter dem Durchschnitt liegt in dieser Gruppe Wenn die Last unter Last steht oder die unausgeglichene Menge nicht groß ist, wird ein NULL-Wert zurückgegeben, d In der Planungsdomäne muss nur ein kleiner Lastbereich ausgeführt werden. Wenn die Menge der zu übertragenden Aufgaben geringer ist als die durchschnittliche Last jedes Prozesses, wird die am stärksten ausgelastete Planungsgruppe erhalten.
Suchen Sie dann die am stärksten ausgelastete Planungswarteschlange in find_busiest_queue, durchlaufen Sie alle CPU-Warteschlangen in der Gruppe und finden Sie die am stärksten ausgelastete Warteschlange, indem Sie die Auslastungen jeder Warteschlange nacheinander vergleichen.
or_each_cpu(i, sched_group_cpus(group)) {
/*rq->cpu_power表示所在处理器的计算能力,在函式sched_init初始化时,会把这值设定为SCHED_LOAD_SCALE (=Nice 0的Load Weight=1024).并可透过函式update_cpu_power (in kernel/sched_fair.c)更新这个值.*/
unsigned long power = power_of(i);
unsigned long capacity = DIV_ROUND_CLOSEST(power,SCHED_POWER_SCALE);
unsigned long wl;
if (!cpumask_test_cpu(i, cpus))
continue;
rq = cpu_rq(i);
/*获取队列负载cpu_rq(cpu)->load.weight;*/
wl = weighted_cpuload(i);
/*
* When comparing with imbalance, use weighted_cpuload()
* which is not scaled with the cpu power.
*/
if (capacity && rq->nr_running == 1 && wl > imbalance)
continue;
/*
* For the load comparisons with the other cpu's, consider
* the weighted_cpuload() scaled with the cpu power, so that
* the load can be moved away from the cpu that is potentially
* running at a lower capacity.
*/
wl = (wl * SCHED_POWER_SCALE) / power;
if (wl > max_load) {
max_load = wl;
busiest = rq;
}
Durch die obige Berechnung erhalten wir die am stärksten frequentierte Warteschlange.
Wenn die Busiest->nr_running-Nummer größer als 1 ist, wird der Pull-Vorgang ausgeführt. Vor dem Pull werden die move_tasks durch double_rq_lock gesperrt.
double_rq_lock(this_rq, busiest); ld_moved = move_tasks(this_rq, this_cpu, busiest, imbalance, sd, idle, &all_pinned); double_rq_unlock(this_rq, busiest);
Die Prozess-Pull-Aufgabe move_tasks darf fehlschlagen, d. h. move_tasks->balance_tasks. Hier gibt es den Schalter sysctl_sched_nr_migrate, um die Anzahl der Prozessmigrationen zu steuern.
Unten finden Sie die Funktion can_migrate_task, um zu überprüfen, ob der ausgewählte Prozess migriert werden kann. 1. Der migrierte Prozess wird ausgeführt. 3. Der Prozess ist kerngebunden und kann nicht auf die Ziel-CPU migriert werden. Der Prozess Der Cache ist immer noch heiß, und dies dient auch dazu, die Cache-Trefferquote sicherzustellen.
/*关于cache cold的情况下,如果迁移失败的个数太多,仍然进行迁移
* Aggressive migration if:
* 1) task is cache cold, or
* 2) too many balance attempts have failed.
*/
tsk_cache_hot = task_hot(p, rq->clock_task, sd);
if (!tsk_cache_hot ||
sd->nr_balance_failed > sd->cache_nice_tries) {
#ifdef CONFIG_SCHEDSTATS
if (tsk_cache_hot) {
schedstat_inc(sd, lb_hot_gained[idle]);
schedstat_inc(p, se.statistics.nr_forced_migrations);
}
#endif
return 1;
}
Bestimmen Sie, ob der Prozesscache gültig ist, und bestimmen Sie die Bedingung. Die Laufzeit des Prozesses ist größer als der Proc-Kontrollschalter sysctl_sched_migration_cost, entsprechend dem Verzeichnis /proc/sys/kernel/sched_migration_cost_ns
static int
task_hot(struct task_struct *p, u64 now, struct sched_domain *sd)
{
s64 delta;
delta = now - p->se.exec_start;
return delta
在load_balance中,move_tasks返回失败也就是ld_moved==0,其中sd->nr_balance_failed++对应can_migrate_task中的”too many balance attempts have failed”,然后busiest->active_balance = 1设置,active_balance = 1。
if (active_balance) //如果pull失败了,开始触发push操作 stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work);
push整个触发操作代码机制比较绕,stop_one_cpu_nowait把active_load_balance_cpu_stop添加到cpu_stopper每CPU变量的任务队列里面,如下:
void stop_one_cpu_nowait(unsigned int cpu, cpu_stop_fn_t fn, void *arg,
struct cpu_stop_work *work_buf)
{
*work_buf = (struct cpu_stop_work){ .fn = fn, .arg = arg, };
cpu_stop_queue_work(&per_cpu(cpu_stopper, cpu), work_buf);
}
而cpu_stopper则是cpu_stop_init函数通过cpu_stop_cpu_callback创建的migration内核线程,触发任务队列调度。因为migration内核线程是绑定每个核心上的,进程迁移失败的1和3问题就可以通过push解决。active_load_balance_cpu_stop则调用move_one_task函数迁移指定的进程。
上面描述的则是整个pull和push的过程,需要补充的pull触发除了schedule后触发,还有scheduler_tick通过触发中断,调用run_rebalance_domains再调用rebalance_domains触发,不再细数。
void __init sched_init(void)
{
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
}
通过本文,你应该对 Linux 内核的 CPU 负载均衡机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了 CPU 负载均衡机制的作用和影响,以及如何在 Linux 下正确地使用和配置它。我们建议你在使用多核或多处理器的 Linux 系统时,使用 CPU 负载均衡机制来提高系统的性能和效率。同时,我们也提醒你在使用 CPU 负载均衡机制时要注意一些潜在的问题和挑战,如负载均衡策略、能耗、调度延迟等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受 CPU 负载均衡机制的优势和便利。
Das obige ist der detaillierte Inhalt vonDer CPU-Lastausgleichsmechanismus des Linux-Kernels: Prinzipien, Prozesse und Optimierungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!