
Heim >Technologie-Peripheriegeräte >KI >Das Team der Universität Peking schlägt ein neues Paradigma für die Aligner-Ausrichtung vor, um die Leistung von GPT-4/Llama2 ohne RLHF deutlich zu verbessern
Das Team der Universität Peking schlägt ein neues Paradigma für die Aligner-Ausrichtung vor, um die Leistung von GPT-4/Llama2 ohne RLHF deutlich zu verbessern

- PHPznach vorne
- 2024-02-07 22:06:371193Durchsuche
Hintergrund
Obwohl große Sprachmodelle (LLMs) leistungsstarke Fähigkeiten bewiesen haben, können sie auch unvorhersehbare und schädliche Ergebnisse wie beleidigende Antworten, falsche Informationen und durchgesickerte private Daten erzeugen, die den Benutzern und der Gesellschaft Schaden zufügen . Sicherzustellen, dass das Verhalten dieser Modelle mit menschlichen Absichten und Werten übereinstimmt, ist eine dringende Herausforderung.
Obwohl Verstärkungslernen basierend auf menschlichem Feedback (RLHF) eine Lösung darstellt, ist es mit einer komplexen Trainingsarchitektur, einer hohen Parameterempfindlichkeit und einer Instabilität des Belohnungsmodells bei verschiedenen Datensätzen konfrontiert. Diese Faktoren machen die Implementierung, Effektivität und Reproduzierbarkeit der RLHF-Technologie schwierig. Um diese Herausforderungen zu meistern, schlug das Team der Peking-Universität ein neues effizientes Ausrichtungsparadigma vor –
Aligner, dessen Kern darin besteht, das modifizierte Residuum zwischen Antwortausrichtung und Fehlausrichtung zu lernen und so das Umständliche zu umgehen RLHF-Prozess. Basierend auf den Ideen des Residual-Lernens und der skalierbaren Supervision vereinfacht Aligner den Alignment-Prozess. Es verwendet ein Seq2Seq-Modell, um implizite Residuen zu lernen und die Ausrichtung durch Replikation und Residuenkorrekturschritte zu optimieren.
Verglichen mit der Komplexität von RLHF, das das Training mehrerer Modelle erfordert, besteht der Vorteil von Aligner darin, dass die Ausrichtung einfach durch Hinzufügen eines Moduls nach dem auszurichtenden Modell erreicht werden kann. Darüber hinaus hängen die erforderlichen Rechenressourcen in erster Linie vom gewünschten Ausrichtungseffekt und nicht von der Größe des Upstream-Modells ab. Experimente haben gezeigt, dass der Einsatz von Aligner-7B die Nützlichkeit und Sicherheit von GPT-4 deutlich verbessern kann, wobei die Nützlichkeit um 17,5 % und die Sicherheit um 26,9 % zunahm. Diese Ergebnisse zeigen, dass Aligner eine effiziente und effektive Ausrichtungsmethode ist, die eine praktikable Lösung zur Verbesserung der Modellleistung bietet.Darüber hinaus nutzt der Autor mithilfe des Aligner-Frameworks das Überwachungssignal des schwachen Modells (Aligner-13B), um die Leistung des starken Modells (Llama-70B) zu verbessern und so eine Generalisierung von schwach zu stark zu erreichen Bietet eine praktische Lösung für die Superausrichtung.
Papieradresse: https://arxiv.org/abs/2402.02416

- Projekthomepage und Open-Source-Adresse: https://aligner2024.github.io
- Titel: Aligner: Effiziente Ausrichtung durch schwach-starke Korrektur erreichen
- Was ist GNED Answers? Es ist einfacher, falsch ausgerichtete Antworten zu korrigieren, als ausgerichtete Antworten zu generieren. Als effiziente Ausrichtungsmethode verfügt Aligner über die folgenden hervorragenden Funktionen:
Als autoregressives Seq2Seq-Modell führt Aligner eine Abfrage-Antwort-Korrektur (Q-A-C)-Daten durch. Trainieren Sie am Set, um den Unterschied zwischen ausgerichteten Daten zu lernen und nicht ausgerichtete Antworten, wodurch eine genauere Modellausrichtung erreicht wird. Bei der Ausrichtung von 70B LLM reduziert Aligner-7B beispielsweise die Anzahl der Trainingsparameter massiv, was 16,67-mal kleiner als DPO und 30,7-mal kleiner als RLHF ist.

Aufgrund des Plug-and-Play-Charakters von Aligner und seiner Unempfindlichkeit gegenüber Modellparametern kann es Modelle wie GPT3.5, GPT4 und Claude2 ausrichten, die keine Parameter erhalten können. Mit nur einer Schulungssitzung richtet Aligner-7B die Nützlichkeit und Sicherheit von 11 Modellen aus und verbessert sie, darunter Closed-Source-, Open-Source- und sicher/ungesichert ausgerichtete Modelle. Unter anderem verbessert Aligner-7B die Nützlichkeit und Sicherheit von GPT-4 deutlich um 17,5 % bzw. 26,9 %.
Aligner-Gesamtleistung
Der Autor zeigt, dass Aligner verschiedener Größen (7B, 13B, 70B) in API-basierten Modellen und Open-Source-Modellen (einschließlich sicherer und nicht sicherer Ausrichtung) verwendet werden können ) Leistung verbessern. Im Allgemeinen verbessert sich die Leistung von Aligner mit zunehmender Modellgröße allmählich und die Informationsdichte, die es während der Korrektur bereitstellen kann, nimmt allmählich zu, wodurch die korrigierte Antwort auch sicherer und hilfreicher wird.
Wie trainiere ich ein Aligner-Modell?
1. Abfrage-Antwort-Datenerfassung (Q-A)
Der Autor erhält Abfragen aus verschiedenen Open-Source-Datensätzen, darunter Stanford Alpaca, ShareGPT, HH-RLHF und anderen von Benutzern geteilten Konversationen. Diese Fragen durchlaufen einen Prozess der Entfernung doppelter Muster und der Qualitätsfilterung für die anschließende Beantwortung und Generierung korrigierter Antworten. Unkorrigierte Antworten wurden mithilfe verschiedener Open-Source-Modelle wie Alpaca-7B, Vicuna-(7B,13B,33B), Llama2-(7B,13B)-Chat und Alpaca2-(7B,13B) generiert.
2. Antwortkorrektur
Der Autor verwendet GPT-4, Llama2-70B-Chat und manuelle Annotation, um die Q-A-Daten gemäß den 3H-Kriterien großer Sprachmodelle (Hilfreich, Sicherheit, Ehrlichkeit) zu korrigieren. Konzentrierte Antworten.
Bei Antworten, die die Kriterien bereits erfüllen, lassen Sie sie unverändert. Der Modifikationsprozess basiert auf einer Reihe klar definierter Prinzipien, die Einschränkungen für das Training von Seq2Seq-Modellen festlegen, wobei der Schwerpunkt darauf liegt, Antworten hilfreicher und sicherer zu machen. Die Verteilung der Antworten hat sich vor und nach der Korrektur deutlich verändert. Die folgende Abbildung zeigt deutlich die Auswirkungen der Änderung auf den Datensatz:

3. Basierend auf dem obigen Prozess. Der Autor hat einen neuen korrigierten Datensatz erstellt, wobei die Frage des Benutzers darstellt,
die ursprüngliche Antwort auf die Frage ist und
 die korrigierte Antwort basierend auf etablierten Prinzipien ist.
die korrigierte Antwort basierend auf etablierten Prinzipien ist. 
 Der Modelltrainingsprozess ist relativ einfach. Die Autoren trainieren ein bedingtes Seq2Seq-Modell
Der Modelltrainingsprozess ist relativ einfach. Die Autoren trainieren ein bedingtes Seq2Seq-Modell  , parametrisiert durch
, parametrisiert durch , so dass die ursprünglichen Antworten auf die ausgerichteten Antworten umverteilt werden.
 Der Prozess zur Generierung von Alignment-Antworten basierend auf dem vorgelagerten großen Sprachmodell ist:
Der Prozess zur Generierung von Alignment-Antworten basierend auf dem vorgelagerten großen Sprachmodell ist: 
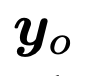
Der Trainingsverlust ist wie folgt:

Der zweite Punkt hat nichts mit den Aligner-Parametern zu tun , und die Aligner-Trainingsziele können abgeleitet werden Für:

Die folgende Abbildung zeigt dynamisch den Zwischenprozess von Aligner:

Es ist erwähnenswert, dass Aligner nicht auf die Parameter von zugreifen muss das Upstream-Modell sowohl während der Trainings- als auch der Inferenzphase. Der Argumentationsprozess von Aligner muss lediglich die Fragen des Benutzers und die ersten Antworten abrufen, die vom vorgelagerten großen Sprachmodell generiert wurden, und dann Antworten generieren, die den menschlichen Werten besser entsprechen.
Durch die Korrektur bestehender Antworten statt direkter Antworten kann sich Aligner problemlos an menschlichen Werten orientieren, wodurch die Anforderungen an die Modellfähigkeiten erheblich reduziert werden.
Aligner im Vergleich zu bestehenden Alignment-Paradigmen
Aligner vs. SFT
Im Gegensatz zu Aligner erstellt SFT direkt eine domänenübergreifende Zuordnung vom semantischen Raum der Abfrage zum semantischen Raum der Antwort Auf vorgelagerten Modellen ist es viel schwieriger, verschiedene Kontexte im semantischen Raum abzuleiten und zu simulieren, als zu lernen, Signale zu korrigieren.
Das Aligner-Trainingsparadigma kann als eine Form des Restlernens (Restkorrektur) betrachtet werden. Der Autor hat das „Kopieren + Korrigieren“-Lernparadigma in Aligner erstellt. Somit erstellt Aligner im Wesentlichen eine Restzuordnung vom Antwort-Semantikraum zum überarbeiteten Antwort-Semantikraum, wobei die beiden Semantikräume verteilungsmäßig näher beieinander liegen.
Zu diesem Zweck erstellte der Autor Q-A-A-Daten in unterschiedlichen Anteilen aus dem Q-A-C-Trainingsdatensatz und trainierte Aligner, das Identitäts-Mapping-Lernen (auch Copy-Mapping genannt) durchzuführen (als „Aufwärmschritt“ bezeichnet). Auf dieser Basis wird der gesamte Q-A-C-Trainingsdatensatz für das Training verwendet. Dieses Restlernparadigma wird auch in ResNet verwendet, um das Problem des Gradientenverschwindens zu lösen, das durch das Stapeln eines zu tiefen neuronalen Netzwerks verursacht wird. Experimentelle Ergebnisse zeigen, dass das Modell die beste Leistung erzielen kann, wenn das Vorheizverhältnis 20 % beträgt.
Aligner vs RLHF
RLHF trainiert ein Belohnungsmodell (RM) anhand des menschlichen Präferenzdatensatzes und verwendet dieses Belohnungsmodell, um die LLMs des PPO-Algorithmus fein abzustimmen, um die LLMs mit dem Verhalten konsistent zu machen der menschlichen Vorlieben.Konkret muss das Belohnungsmodell menschliche Präferenzdaten zur Optimierung vom diskreten in den kontinuierlichen numerischen Raum abbilden, aber im Vergleich zum Seq2Seq-Modell mit starker Generalisierungsfähigkeit im Textraum verfügt diese Art von numerischem Belohnungsmodell über die Generalisierungsfähigkeit von Text Der Raum ist schwach, was zu einer instabilen Wirkung von RLHF auf verschiedene Modelle führt.
Und Aligner lernt den Unterschied (Rest) zwischen ausgerichteten und nicht ausgerichteten Antworten, indem er ein Seq2Seq-Modell trainiert, wodurch der RLHF-Prozess effektiv vermieden und eine bessere Generalisierungsleistung als RLHF erzielt wird.
Aligner vs. Prompt Engineering
Prompt Engineering ist eine gängige Methode, um die Fähigkeiten von LLMs zu stimulieren. Diese Methode weist jedoch einige Schlüsselprobleme auf, wie zum Beispiel: Es ist schwierig, Prompts zu entwerfen, und es braucht Das Modell ist unterschiedlich gestaltet und der endgültige Effekt hängt von den Fähigkeiten des Modells ab. Wenn die Fähigkeiten des Modells zur Lösung der Aufgabe nicht ausreichen, sind möglicherweise mehrere Iterationen erforderlich, wodurch das Kontextfenster verschwendet wird Das kleine Modell wirkt sich auf die Wirkung des Prompt-Word-Projekts aus, und bei großen Modellen erhöht die Besetzung eines zu langen Kontexts die Schulungskosten erheblich.Aligner selbst kann die Ausrichtung jedes Modells unterstützen. Nach einem Training kann es 11 verschiedene Modelltypen ausrichten, ohne das Kontextfenster des Originalmodells zu belegen. Es ist erwähnenswert, dass Aligner nahtlos mit bestehenden Methoden des Prompt Word Engineering kombiniert werden kann, um einen 1+1>2-Effekt zu erzielen.
Generell: Aligner weist folgende wesentliche Vorteile auf:
1. Verglichen mit dem auf diesem Modell basierenden komplexen Belohnungsmodelllern- und Reinforcement Learning (RL)-Feinabstimmungsprozess von RLHF ist der Implementierungsprozess von Aligner direkter und einfacher zu bedienen. Rückblickend auf die zahlreichen technischen Parameteranpassungsdetails bei RLHF und die inhärente Instabilität und Hyperparameterempfindlichkeit des RL-Algorithmus vereinfacht Aligner die technische Komplexität erheblich.
2.Aligner hat weniger Trainingsdaten und einen offensichtlichen Ausrichtungseffekt. Das Training eines Aligner-7B-Modells basierend auf 20K-Daten kann die Nützlichkeit von GPT-4 um 12 % und die Sicherheit um 26 % verbessern und die Nützlichkeit des Vicuna 33B-Modells um 29 % und die Sicherheit um 45,3 % verbessern. RLHF erfordert mehr Präferenzdaten und verfeinerte Parameteranpassungen, um diesen Effekt zu erzielen.
3.Aligner muss die Modellgewichte nicht berühren. Während sich RLHF bei der Modellausrichtung als wirksam erwiesen hat, beruht es auf dem direkten Training des Modells. Die Anwendbarkeit von RLHF ist angesichts nicht-Open-Source-API-basierter Modelle wie GPT-4 und deren Feinabstimmungsanforderungen bei nachgelagerten Aufgaben begrenzt. Im Gegensatz dazu erfordert Aligner keine direkte Manipulation der ursprünglichen Parameter des Modells und erreicht eine flexible Ausrichtung durch die Externalisierung der Ausrichtungsanforderungen in ein unabhängiges Ausrichtungsmodul.
4.Aligner ist gegenüber Modelltypen gleichgültig. Unter dem RLHF-Framework erfordert die Feinabstimmung für verschiedene Modelle (z. B. Llama2, Alpaca) nicht nur die erneute Erfassung von Präferenzdaten, sondern auch die Anpassung der Trainingsparameter in der Belohnungsmodell-Trainings- und RL-Phase. Aligner kann die Ausrichtung jedes Modells durch einmaliges Training unterstützen. Beispielsweise kann Aligner-7B mit nur einer Schulungssitzung am korrigierten Datensatz 11 verschiedene Modelle ausrichten (einschließlich Open-Source-Modellen, API-Modellen wie GPT) und die Leistung in Bezug auf Nützlichkeit und Sicherheit um 21,9 % bzw. 23,8 % verbessern.
5.Aligners Bedarf an Schulungsressourcen ist flexibler. RLHF Die Feinabstimmung eines 70B-Modells ist immer noch sehr anspruchsvoll für die Rechenressourcen und erfordert die Leistung von Hunderten von GPU-Karten. Denn die RLHF-Methode erfordert auch ein zusätzliches Laden von Belohnungsmodellen, Akteurmodellen und Kritikmodellen entsprechend der Anzahl der Modellparameter. Daher erfordert RLHF im Hinblick auf den Trainingsressourcenverbrauch pro Zeiteinheit tatsächlich mehr Rechenressourcen als vor dem Training.
Im Vergleich dazu bietet Aligner eine flexiblere Trainingsstrategie, die es Benutzern ermöglicht, den Trainingsumfang von Aligner basierend auf ihren tatsächlichen Rechenressourcen flexibel zu wählen. Für die Ausrichtungsanforderung eines 70B-Modells können Benutzer beispielsweise Aligner-Modelle unterschiedlicher Größe (7B, 13B, 70B usw.) basierend auf den tatsächlich verfügbaren Ressourcen auswählen, um eine effektive Ausrichtung des Zielmodells zu erreichen.
Diese Flexibilität reduziert nicht nur den absoluten Bedarf an Rechenressourcen, sondern bietet Benutzern auch die Möglichkeit einer effizienten Ausrichtung unter begrenzten Ressourcen.
Schwach-zu-stark-Generalisierung
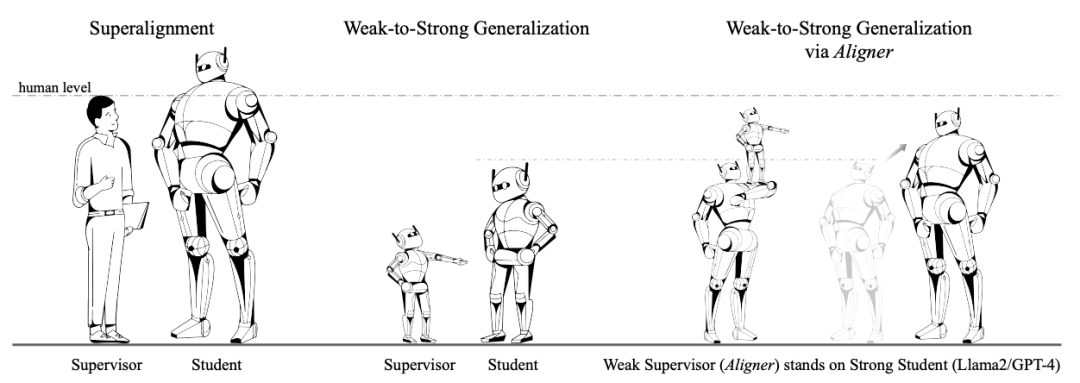
Schwach-zu-stark-Generalisierung Die diskutierte Frage ist, ob die Labels des schwachen Modells verwendet werden können, um das starke Modell zu trainieren, sodass das Ein starkes Modell kann seine Leistung verbessern. OpenAI verwendet diese Analogie, um das Problem der SuperAlignment zu lösen. Insbesondere verwenden sie Ground-Truth-Labels, um schwache Modelle zu trainieren.
OpenAI-Forscher führten beispielsweise zur Aufgabe der Textklassifizierung den Trainingsdatensatz in zwei Teile auf. Die Eingabe- und Grundwahrheitsbezeichnungen der zweiten Hälfte wurden verwendet Die Hälfte der Trainingsdaten behält nur die Eingabe bei und die Beschriftungen werden vom schwachen Modell generiert. Nur die vom schwachen Modell erzeugten schwachen Labels werden verwendet, um beim Training des starken Modells Überwachungssignale für das starke Modell bereitzustellen.
Der Zweck des Trainings eines schwachen Modells unter Verwendung echter Werteetiketten besteht darin, dem schwachen Modell die Möglichkeit zu geben, die entsprechende Aufgabe zu lösen, die Eingaben, die zum Generieren schwacher Etiketten verwendet werden, und die Eingaben, die zum Trainieren des schwachen Modells verwendet werden, jedoch nicht das gleiche. Dieses Paradigma ähnelt dem Konzept des „Lehrens“, das heißt, schwache Modelle zu verwenden, um starke Modelle anzuleiten.
Der Autor schlägt ein neuartiges Paradigma der schwachen bis starken Generalisierung vor, das auf den Eigenschaften von Aligner basiert.
Der Kernpunkt des Autors besteht darin, Aligner als „Aufseher auf den Schultern von Giganten“ fungieren zu lassen. Im Gegensatz zur OpenAI-Methode zur direkten Überwachung des „Riesen“ korrigiert Aligner stärkere Modelle durch schwache bis starke Korrekturen, um dabei genauere Bezeichnungen bereitzustellen.
Konkret enthalten die korrigierten Daten während des Aligner-Trainingsprozesses GPT-4, menschliche Annotatoren und größere Modellanmerkungen. Anschließend generiert der Autor mit Aligner schwache Labels (d. h. Korrekturen) für den neuen Q-A-Datensatz und verwendet die schwachen Labels dann zur Feinabstimmung des Originalmodells.
Experimentelle Ergebnisse zeigen, dass dieses Paradigma die Ausrichtungsleistung des Modells weiter verbessern kann.
Experimentelle Ergebnisse
Aligner vs. SFT/RLHF/DPO
Der Autor verwendete den Trainingsdatensatz „Query-Antwort-Korrektur“ von Aligner, um Alpaca-7B jeweils über die SFT/RLHF/DPO-Methode zu optimieren.
Bei der Leistungsbewertung wurden die Open-Source-Testaufforderungsdatensätze BeaverTails und HarmfulQA verwendet, um die vom fein abgestimmten Modell generierten Antworten mit den vom ursprünglichen Alpaca-7B-Modell generierten Antworten zu vergleichen, wobei Aligner zur Korrektur der Antworten verwendet wurde. In Bezug auf die Nützlichkeit und den Vergleich in Bezug auf die Sicherheit sind die Ergebnisse wie folgt:

Die experimentellen Ergebnisse zeigen, dass Aligner in Bezug auf die Nützlichkeit offensichtliche Vorteile gegenüber ausgereiften LLM-Ausrichtungsparadigmen wie SFT/RLHF/DPO hat und Sicherheit liegen deutlich vorn.
Bei der Analyse spezifischer experimenteller Fälle kann festgestellt werden, dass das mithilfe des RLHF/DPO-Paradigmas verfeinerte Ausrichtungsmodell möglicherweise eher konservative Antworten liefert, um die Sicherheit zu verbessern berücksichtigt, was zu einer Zunahme der Antworten auf gefährliche Informationen führt.
Aligner vs. Prompt Engineering
Vergleichen Sie die Leistungsverbesserung von Aligner-13B und CAI/Selbstkritik-Methoden am gleichen Upstream-Modell. Die experimentellen Ergebnisse sind in der folgenden Abbildung dargestellt: Aligner-13B ist hilfreich nach GPT-4 Die Verbesserung sowohl der Sicherheit als auch des Schutzes ist höher als die der CAI/Selbstkritik-Methode, was zeigt, dass das Aligner-Paradigma offensichtliche Vorteile gegenüber der häufig verwendeten Prompt-Engineering-Methode hat.
Es ist erwähnenswert, dass CAI-Eingabeaufforderungen nur während der Argumentation im Experiment verwendet werden, um sie zu ermutigen, ihre Antworten selbst zu modifizieren, was ebenfalls eine Form der Selbstverfeinerung ist.

Darüber hinaus hat der Autor die Antworten mithilfe der CAI-Methode korrigiert und die Antworten vor und nach Aligner direkt verglichen .

Methode A: CAI + Aligner Methode B: nur CAI
Nachdem Aligner zweimal zum Korrigieren der CAI-korrigierten Antwort verwendet wurde, ist die Antwort in Bezug auf die Sicherheit hilfreich, ohne dass die Sicherheit verloren geht erreicht wurde. Dies zeigt, dass Aligner nicht nur allein im Einsatz äußerst konkurrenzfähig ist, sondern auch mit anderen bestehenden Alignment-Methoden kombiniert werden kann, um seine Leistung weiter zu verbessern.
Schwach-zu-stark-Generalisierung

Methode: schwach-zu-stark Der Trainingsdatensatz besteht aus (q, a, a′)-Tripeln, wobei q die Trainingsdaten von Aligner darstellt Set – 50.000 Fragen, a stellt die vom Alpaca-7B-Modell generierte Antwort dar und a′ stellt die von Aligner-7B gegebene ausgerichtete Antwort (q, a) dar. Im Gegensatz zu SFT, das nur a′ als Grundwahrheitsbezeichnung verwendet, gilt a′ im RLHF- und DPO-Training als besser als a.
Der Autor verwendete Aligner, um die ursprüngliche Antwort im neuen Q-A-Datensatz zu korrigieren, verwendete die korrigierte Antwort als schwache Bezeichnung und nutzte diese schwachen Bezeichnungen als Überwachungssignale, um ein größeres Modell zu trainieren. Dieser Prozess ähnelt dem Trainingsparadigma von OpenAI.
Der Autor trainiert starke Modelle basierend auf schwachen Labels mit drei Methoden: SFT, RLHF und DPO. Die experimentellen Ergebnisse in der obigen Tabelle zeigen, dass bei einer Feinabstimmung des Upstream-Modells durch SFT die schwachen Labels von Aligner-7B und Aligner-13B die Leistung der Llama2-Serie starker Modelle in allen Szenarien verbessern.
Ausblick: Mögliche Forschungsrichtungen von Aligner
Aligner hat als innovative Aligner-Methode großes Forschungspotenzial. In dem Artikel schlug der Autor mehrere Anwendungsszenarien von Aligner vor, darunter:
1 Anwendung von Multi-Turn-Dialogszenarien. In mehrrundigen Gesprächen ist die Herausforderung, mit spärlichen Belohnungen konfrontiert zu werden, besonders ausgeprägt. Bei Frage-und-Antwort-Gesprächen (QA) stehen Supervisionssignale in Skalarform typischerweise erst am Ende des Gesprächs zur Verfügung.
Dieses Sparsity-Problem wird in mehreren Dialogrunden (z. B. kontinuierlichen QS-Szenarien) noch verstärkt, was es schwierig macht, auf Reinforcement Learning basierendem menschlichem Feedback (RLHF) effektiv zu sein. Die Untersuchung des Potenzials von Aligner zur Verbesserung der Dialogausrichtung über mehrere Runden hinweg ist ein Bereich, der einer weiteren Erkundung wert ist.
2. Ausrichtung des menschlichen Wertes auf das Belohnungsmodell. Im mehrstufigen Prozess der Erstellung von Belohnungsmodellen auf der Grundlage menschlicher Vorlieben und der Feinabstimmung großer Sprachmodelle (LLMs) gibt es große Herausforderungen, sicherzustellen, dass LLMs auf bestimmte menschliche Werte ausgerichtet sind (z. B. Fairness, Empathie, usw.).
Durch die Übergabe der Werteausrichtungsaufgabe an das Aligner-Ausrichtungsmodul außerhalb des Modells und die Verwendung eines bestimmten Korpus zum Trainieren von Aligner werden nicht nur neue Ideen für die Werteausrichtung bereitgestellt, sondern es Aligner auch ermöglicht, die Ausgabe des Front-Aligners zu ändern. Endmodell, um bestimmte Werte widerzuspiegeln.
3. Streaming und parallele Verarbeitung von MoE-Aligner. Durch die Spezialisierung und Integration von Alignern können Sie einen leistungsfähigeren und umfassenderen Hybrid Expert (MoE) Aligner erstellen, der mehrere hybride Sicherheits- und Wertausrichtungsanforderungen erfüllen kann. Gleichzeitig ist die weitere Verbesserung der Parallelverarbeitungsfähigkeiten von Aligner zur Reduzierung des Verlusts an Inferenzzeit eine mögliche Entwicklungsrichtung.
4. Fusion während der Modellausbildung. Durch die Integration der Aligner-Schicht nach einer bestimmten Gewichtsschicht kann ein Echtzeiteingriff in die Ausgabe während des Modelltrainings erreicht werden. Diese Methode verbessert nicht nur die Ausrichtungseffizienz, sondern trägt auch dazu bei, den Modelltrainingsprozess zu optimieren und eine effizientere Modellausrichtung zu erreichen.
Teamvorstellung
Diese Arbeit wurde unabhängig vom Forschungsteam von Yang Yaodong am AI Security and Governance Center des Instituts für Künstliche Intelligenz der Universität Peking abgeschlossen. Das Team beschäftigt sich intensiv mit der Ausrichtungstechnologie großer Sprachmodelle, einschließlich des Open-Source-Datensatzes BeaverTails für sichere Ausrichtung auf Millionenebene (NeurIPS 2023) und des sicheren Ausrichtungsalgorithmus SafeRLHF (ICLR 2024 Spotlight). wurde von mehreren Open-Source-Modellen übernommen. Verfasste die branchenweit erste umfassende Übersicht über die Ausrichtung künstlicher Intelligenz und verknüpfte sie mit der Ressourcen-Website www.alignmentsurvey.com (klicken Sie auf den Originaltext, um direkt zu springen), wobei er systematisch die vier Perspektiven „Lernen aus Feedback“, „Lernen unter Verteilungsverschiebung“ und „Assurance“ darlegte , und Governance-Problem. Die Ansichten des Teams zu Alignment und Super-Alignment wurden auf dem Cover der 2024-Ausgabe 5 von Sanlian Life Weekly vorgestellt.
Das obige ist der detaillierte Inhalt vonDas Team der Universität Peking schlägt ein neues Paradigma für die Aligner-Ausrichtung vor, um die Leistung von GPT-4/Llama2 ohne RLHF deutlich zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!