
Heim >Technologie-Peripheriegeräte >KI >Drei Artikel lösen das Problem der „Optimierung und Bewertung der semantischen Segmentierung'! Leuven/Tsinghua/Oxford und andere schlugen gemeinsam eine neue Methode vor
Drei Artikel lösen das Problem der „Optimierung und Bewertung der semantischen Segmentierung'! Leuven/Tsinghua/Oxford und andere schlugen gemeinsam eine neue Methode vor

- 王林nach vorne
- 2024-02-06 21:15:171041Durchsuche
Zu den häufig verwendeten Verlustfunktionen zur Optimierung semantischer Segmentierungsmodelle gehören Soft-Jaccard-Verlust, Soft-Dice-Verlust und Soft-Tversky-Verlust. Diese Verlustfunktionen sind jedoch nicht mit Soft Labels kompatibel und können daher einige wichtige Trainingstechniken wie Label-Glättung, Wissensdestillation, halbüberwachtes Lernen und mehrere Annotatoren nicht unterstützen. Diese Trainingstechniken sind sehr wichtig, um die Leistung und Robustheit semantischer Segmentierungsmodelle zu verbessern. Daher sind weitere Untersuchungen und Optimierungen von Verlustfunktionen erforderlich, um die Anwendung dieser Trainingstechniken zu unterstützen.
Andererseits umfassen häufig verwendete semantische Segmentierungsbewertungsindikatoren mAcc und mIoU. Diese Indikatoren bevorzugen jedoch größere Objekte, was die Bewertung der Sicherheitsleistung des Modells erheblich beeinträchtigt.
Um diese Probleme zu lösen, schlugen Forscher der Universität Leuven und Tsinghua zunächst den JDT-Verlust vor. Der JDT-Verlust ist eine Feinabstimmung der ursprünglichen Verlustfunktion, die den metrischen Jaccard-Verlust, den semimetrischen Dice-Verlust und den kompatiblen Tversky-Verlust umfasst. Der JDT-Verlust entspricht der ursprünglichen Verlustfunktion beim Umgang mit harten Etiketten und ist auch vollständig auf weiche Etiketten anwendbar. Diese Verbesserung macht das Modelltraining genauer und stabiler.
Forscher haben den JDT-Verlust erfolgreich in vier wichtigen Szenarien angewendet: Etikettenglättung, Wissensdestillation, halbüberwachtes Lernen und mehrere Annotatoren. Diese Anwendungen demonstrieren die Leistungsfähigkeit des JDT-Verlusts zur Verbesserung der Modellgenauigkeit und -kalibrierung.
 Bilder
Bilder
Papierlink: https://arxiv.org/pdf/2302.05666.pdf
 Bilder
Bilder
Papierlink: https://arxiv.org/pdf/23 03.16296 .pdf
Darüber hinaus schlugen die Forscher auch feinkörnige Bewertungsindikatoren vor. Diese feinkörnigen Bewertungsmetriken sind weniger voreingenommen gegenüber großen Objekten, liefern umfassendere statistische Informationen und können wertvolle Erkenntnisse für die Modell- und Datensatzprüfung liefern.
Und die Forscher führten eine umfassende Benchmark-Studie durch, die die Notwendigkeit hervorhob, dass Bewertungen nicht auf einer einzigen Metrik basieren dürfen, und entdeckten die wichtige Rolle der neuronalen Netzwerkstruktur und des JDT-Verlusts bei der Optimierung feinkörniger Metriken.
 Pictures
Pictures
paper Link: https://arxiv.org/pdf/2310.19252.pdf
code Links: https://github.com/zifuwanggg/jdtlosses
existing Verlustfunktionen
Da Jaccard Index und Dice Score auf Sets definiert sind, sind sie nicht differenzierbar. Um sie differenzierbar zu machen, gibt es derzeit zwei gängige Ansätze: Einer besteht darin, die Beziehung zwischen der Menge und dem Lp-Modul des entsprechenden Vektors zu verwenden, wie z. B. Soft Jaccard Loss (SJL), Soft Dice Loss (SDL) und Soft Tversky Verlust (STL).
Sie schreiben die Größe der Menge als L1-Modul des entsprechenden Vektors und den Schnittpunkt zweier Mengen als inneres Produkt der beiden entsprechenden Vektoren. Die andere besteht darin, die submodulare Eigenschaft des Jaccard-Index zu verwenden, um eine Lovasz-Erweiterung für die eingestellte Funktion durchzuführen, z. B. den Lovasz-Softmax-Verlust (LSL).
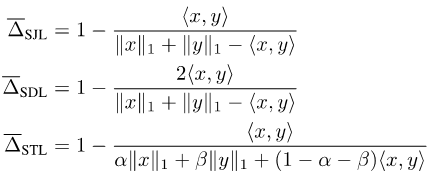 Bilder
Bilder
Diese Verlustfunktionen gehen davon aus, dass die Ausgabe x des neuronalen Netzwerks ein kontinuierlicher Vektor und die Bezeichnung y ein diskreter binärer Vektor ist. Wenn es sich bei der Beschriftung um eine Soft-Beschriftung handelt, das heißt, wenn y kein diskreter Binärvektor mehr, sondern ein kontinuierlicher Vektor ist, sind diese Verlustfunktionen nicht mehr kompatibel.
Nehmen Sie SJL als Beispiel und betrachten Sie einen einfachen Einzelpixel-Fall:
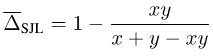 Bild
Bild
Es kann festgestellt werden, dass für jedes y > 0 SJL bei x = 1 minimiert wird und wird maximiert, wenn x = 0. Da eine Verlustfunktion minimiert werden sollte, wenn x = y, ist dies offensichtlich unvernünftig.
Mit Soft Labels kompatible Verlustfunktion
Um die ursprüngliche Verlustfunktion mit Soft Labels kompatibel zu machen, muss bei der Berechnung des Schnittpunkts und der Vereinigung der beiden Sets die symmetrische Differenz der beiden Mengen eingeführt werden:
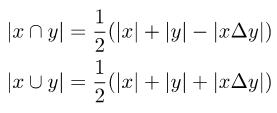 Bild
Bild
Beachten Sie, dass die symmetrische Differenz zwischen zwei Mengen als L1-Modul der Differenz zwischen den beiden entsprechenden Vektoren geschrieben werden kann:
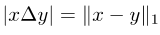 Bilder
Bilder
Zusammenfassend schlagen wir den JDT-Verlust vor. Sie sind eine Variante von SJL, Jaccard Metric Loss (JML), eine Variante von SDL, Dice Semimetric Loss (DML) und eine Variante von STL, Compatible Tversky Loss (CTL).
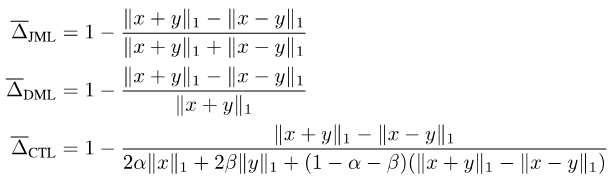 Bilder
Bilder
Eigenschaften des JDT-Verlusts
Wir haben bewiesen, dass der JDT-Verlust die folgenden Eigenschaften hat.
Eigenschaft 1: JML ist eine Metrik und DML ist eine Semimetrik.
Eigenschaft 2: Wenn y ein hartes Etikett ist, entspricht JML SJL, DML entspricht SDL und CTL entspricht STL.
Eigenschaft 3: Wenn y ein Soft-Label ist, sind JML, DML und CTL alle mit Soft-Label kompatibel, d. h. x = y ó f(x, y) = 0.
Aufgrund der Eigenschaft 1 werden sie auch als Jaccard-Metrikverlust und Dice-Semimetrieverlust bezeichnet. Eigenschaft 2 zeigt, dass in allgemeinen Szenarien, in denen nur harte Etiketten für das Training verwendet werden, der JDT-Verlust direkt zum Ersetzen der vorhandenen Verlustfunktion verwendet werden kann, ohne dass Änderungen verursacht werden.
So verwenden Sie JDT-Verlust
Wir haben viele Experimente durchgeführt und einige Vorsichtsmaßnahmen für die Verwendung von JDT-Verlust zusammengefasst.
Hinweis 1: Wählen Sie die entsprechende Verlustfunktion basierend auf dem Bewertungsindex aus. Wenn der Bewertungsindex Jaccard-Index ist, sollte JML ausgewählt werden. Wenn der Bewertungsindex Dice Score ist, sollte DML ausgewählt werden. Wenn Sie falsch-positiven und falsch-negativen Ergebnissen unterschiedliche Gewichte zuweisen möchten, sollte CTL ausgewählt werden. Zweitens sollte bei der Optimierung feinkörniger Bewertungsindikatoren auch der JDT-Verlust entsprechend geändert werden.
Hinweis 2: Kombinieren Sie JDT-Verlust und Verlustfunktion auf Pixelebene (z. B. Kreuzentropieverlust, Fokusverlust). In diesem Artikel wurde festgestellt, dass 0,25 CE + 0,75 JDT im Allgemeinen eine gute Wahl ist.
Hinweis 3: Am besten nutzen Sie eine kürzere Epoche für das Training. Nach dem Hinzufügen des JDT-Verlusts ist im Allgemeinen nur die Hälfte der Epochen des Cross-Entropy-Verlusttrainings erforderlich.
Hinweis 4: Wenn bei der Durchführung eines verteilten Trainings auf mehreren GPUs keine zusätzliche Kommunikation zwischen GPUs stattfindet, werden durch den JDT-Verlust feinkörnige Bewertungsmetriken falsch optimiert, was zu einer schlechten Leistung auf herkömmlichem mIoU führt.
Hinweis 5: Beachten Sie beim Training mit einem Datensatz mit extremer Kategorieunausgewogenheit, dass der JDL-Verlust für jede Kategorie separat berechnet und dann gemittelt wird, was das Training instabil machen kann.
Experimentelle Ergebnisse
Experimente haben gezeigt, dass das Hinzufügen von JDT-Verlusten im Vergleich zur Basislinie des Kreuzentropieverlusts die Genauigkeit des Modells beim Training mit harten Etiketten effektiv verbessern kann. Die Genauigkeit und Kalibrierung des Modells kann durch die Einführung von Soft Labels weiter verbessert werden.
 Bilder
Bilder
Durch das Hinzufügen des JDT-Verlustbegriffs während des Trainings hat dieser Artikel SOTA bei der Wissensdestillation, halbüberwachtem Lernen und Multi-Annotatoren bei der semantischen Segmentierung erreicht.
 Bilder
Bilder
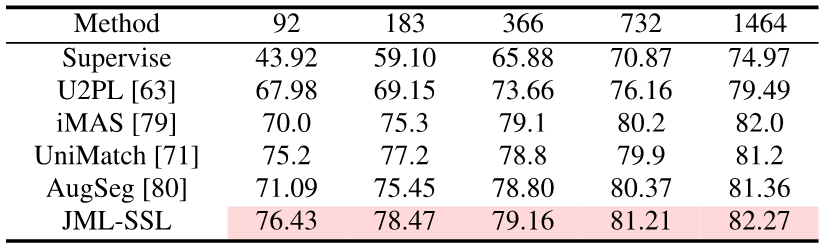 Bilder
Bilder
 Bilder
Bilder
Vorhandene Bewertungsmetriken
Semantische Segmentierung ist eine Klassifizierungsaufgabe auf Pixelebene, also jedes Pixel Genauigkeit: Gesamtpixel- weise Genauigkeit (Acc). Da Acc jedoch auf die Mehrheitskategorie ausgerichtet ist, verwendet PASCAL VOC 2007 einen Bewertungsindex, der die Pixelgenauigkeit jeder Kategorie separat berechnet und sie dann mittelt: mittlere pixelweise Genauigkeit (mAcc).
Aber da mAcc keine Fehlalarme berücksichtigt, wird seit PASCAL VOC 2008 das durchschnittliche Schnitt- und Vereinigungsverhältnis (pro Datensatz mIoU, mIoUD) als Bewertungsindex verwendet. PASCAL VOC war der erste Datensatz, der die semantische Segmentierungsaufgabe einführte, und die darin verwendeten Bewertungsindikatoren wurden in verschiedenen nachfolgenden Datensätzen häufig verwendet.
Konkret kann IoU wie folgt geschrieben werden:
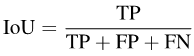 Bilder
Bilder
Um mIoUD zu berechnen, müssen wir zunächst die richtig positiven (TP) und falsch positiven (FP) aller I-Fotos im gesamten Datensatz für jede Kategorie c zählen. FN)
Da mIoUD die TP, FP und FN aller Pixel im gesamten Datensatz summiert, wird es unweigerlich auf diese großen Objekte ausgerichtet sein.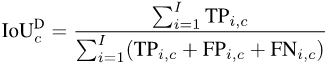 In manchen Anwendungsszenarien mit hohen Sicherheitsanforderungen, wie etwa autonomes Fahren und medizinische Bilder, gibt es oft Objekte, die zwar klein sind, aber nicht ignoriert werden können.
In manchen Anwendungsszenarien mit hohen Sicherheitsanforderungen, wie etwa autonomes Fahren und medizinische Bilder, gibt es oft Objekte, die zwar klein sind, aber nicht ignoriert werden können.
Wie im Bild unten gezeigt, ist die Größe der Autos auf den verschiedenen Fotos offensichtlich unterschiedlich. Daher wird die Vorliebe von mIoUD für große Objekte die Bewertung der Modellsicherheitsleistung erheblich beeinträchtigen.
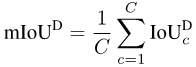 Feinkörnige Bewertungsindikatoren
Feinkörnige Bewertungsindikatoren
Um das Problem von mIoUD zu lösen, schlagen wir feinkörnige Bewertungsindikatoren vor. Diese Indikatoren berechnen die IoU für jedes Foto separat, wodurch die Präferenz für große Objekte effektiv reduziert werden kann.
mIoUI
Für jede Kategorie c berechnen wir einen IoU für jedes Foto i:
Bild
Dann mitteln wir für jedes Foto i den Durchschnitt aller Kategorien, die auf erschienen sind dieses Foto:
Bilder
Zum Schluss mitteln wir die Werte aller Fotos: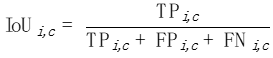 Bilder
Bilder
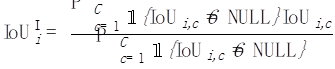 Ähnlich nach der Berechnung des IoU Von jeder Kategorie c auf jedem Foto i können wir alle Fotos mitteln, in denen jede Kategorie c vorkommt:
Ähnlich nach der Berechnung des IoU Von jeder Kategorie c auf jedem Foto i können wir alle Fotos mitteln, in denen jede Kategorie c vorkommt:
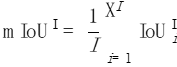
Da nicht alle Kategorien auf allen Fotos angezeigt werden, werden für einige Kombinationen aus Kategorien und Fotos NULL-Werte angezeigt, wie in der Abbildung unten dargestellt. Bei der Berechnung von mIoUI wird zuerst der Durchschnitt der Kategorien und dann der Fotos ermittelt, während bei der Berechnung von mIoUC zuerst der Durchschnitt der Fotos und dann der Kategorien ermittelt wird. Das Ergebnis ist, dass mIoUI möglicherweise auf Kategorien ausgerichtet ist, die häufig vorkommen (z. B. C1 in der Abbildung unten), was im Allgemeinen nicht gut ist. Andererseits kann uns dies bei der Berechnung von mIoUI dabei helfen, das Modell und den Datensatz zu prüfen und zu analysieren, da jedes Foto einen IoU-Wert hat.
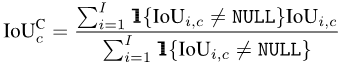
Bilder
Worst-Case-Bewertungsindikatoren
Bei einigen sicherheitsorientierten Anwendungsszenarien sind wir oft mehr auf die Qualität der Worst-Case-Segmentierung bedacht, während feinkörnige Indikatoren ein Vorteil sind die Fähigkeit, entsprechende Worst-Case-Indikatoren zu berechnen. Nehmen wir als Beispiel mIoUC. Eine ähnliche Methode kann auch den entsprechenden Worst-Case-Indikator von mIoUI berechnen.
Für jede Kategorie c sortieren wir zunächst die IoU-Werte aller Fotos, in denen sie aufgetaucht ist (vorausgesetzt, es gibt Ic solche Fotos), in aufsteigender Reihenfolge. Als nächstes setzen wir q auf eine kleine Zahl, beispielsweise 1 oder 5. Dann verwenden wir nur die obersten Ic * q % der sortierten Fotos, um den Endwert zu berechnen:
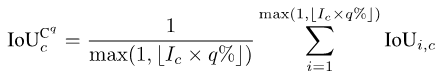 Bilder
Bilder
Nachdem wir den Wert jeder Klasse c haben, können wir wie zuvor nach Kategorie sortieren Durchschnitt Dies dient dazu, die Worst-Case-Metrik von mIoUC zu erhalten.
Experimentelle Ergebnisse
Wir haben 15 Modelle anhand von 12 Datensätzen trainiert und die folgenden Phänomene festgestellt.
Phänomen 1: Kein Modell kann bei allen Bewertungsindikatoren die besten Ergebnisse erzielen. Jeder Bewertungsindex hat einen anderen Schwerpunkt, daher müssen wir mehrere Bewertungsindizes gleichzeitig berücksichtigen, um eine umfassende Bewertung durchzuführen.
Phänomen 2: Es gibt einige Fotos in einigen Datensätzen, die dazu führen, dass fast alle Modelle einen sehr niedrigen IoU-Wert erreichen. Dies liegt zum Teil daran, dass die Fotos selbst sehr anspruchsvoll sind, wie zum Beispiel einige sehr kleine Objekte und einen starken Hell-Dunkel-Kontrast, und zum Teil daran, dass es Probleme mit der Beschriftung dieser Fotos gibt. Daher können uns feinkörnige Bewertungsmetriken bei der Durchführung von Modellprüfungen (Auffinden von Szenarien, in denen Modelle Fehler machen) und Datensatzprüfungen (Auffinden falscher Bezeichnungen) helfen.
Phänomen 3: Die Struktur des neuronalen Netzwerks spielt eine entscheidende Rolle bei der Optimierung feinkörniger Bewertungsindikatoren. Einerseits kann die Verbesserung des Empfangsfelds durch Strukturen wie ASPP (übernommen von DeepLabV3 und DeepLabV3+) dem Modell helfen, große Objekte zu erkennen, wodurch der Wert von mIoUD effektiv verbessert wird Encoder und Decoder Lange Verbindungen (übernommen von UNet und DeepLabV3+) ermöglichen es dem Modell, kleine Objekte zu erkennen, wodurch der Wert feinkörniger Bewertungsindikatoren verbessert wird.
Phänomen 4: Der Wert des Worst-Case-Indikators ist weitaus niedriger als der Wert des entsprechenden Durchschnittsindikators. Die folgende Tabelle zeigt den mIoUC von DeepLabV3-ResNet101 für mehrere Datensätze und die entsprechenden Worst-Case-Indikatorwerte. Eine Frage, die es wert ist, in Zukunft berücksichtigt zu werden, ist: Wie sollten wir die Struktur und Optimierungsmethode des neuronalen Netzwerks entwerfen, um die Leistung des Modells unter den Worst-Case-Indikatoren zu verbessern?
 Bilder
Bilder
Phänomen 5: Die Verlustfunktion spielt eine entscheidende Rolle bei der Optimierung feinkörniger Bewertungsindikatoren. Im Vergleich zum Benchmark des Kreuzentropieverlusts, wie in (0, 0, 0) in der folgenden Tabelle gezeigt, kann die Verwendung der entsprechenden Verlustfunktion die Leistung des Modells bei feinkörnigen Modellen erheblich verbessern, wenn die Bewertungsindikatoren feinkörnig werden Bewertungsindikatoren. Bei ADE20K beträgt der Unterschied im mIoUC-Verlust zwischen JML und Cross Entropy beispielsweise mehr als 7 %.
 Bilder
Bilder
Zukünftige Arbeit
Wir haben den JDT-Verlust nur als Verlustfunktion für die semantische Segmentierung berücksichtigt, sie können jedoch auch auf andere Aufgaben angewendet werden, beispielsweise auf herkömmliche Klassifizierungsaufgaben.
Zweitens werden JDT-Verluste nur im Beschriftungsraum verwendet. Wir glauben jedoch, dass sie verwendet werden können, um den Abstand zwischen zwei beliebigen Vektoren im Merkmalsraum zu minimieren, z. B. durch Ersetzen des Lp-Moduls und des Kosinusabstands.
Referenzen:
https://arxiv.org/pdf/2302.05666.pdf
https://arxiv.org/pdf/2303.16296.pdf
https://arxiv.org/pdf/2310.19252 . pdf
Das obige ist der detaillierte Inhalt vonDrei Artikel lösen das Problem der „Optimierung und Bewertung der semantischen Segmentierung'! Leuven/Tsinghua/Oxford und andere schlugen gemeinsam eine neue Methode vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche wichtigen Indikatoren bestimmen die Leistung eines Mikroprozessors?
- Fußnoten in Word beziehen sich darauf, wo sich der Inhalt der Fußnote befindet?
- Zusammenfassung der Redis-Leistungsüberwachungsindikatoren
- Was sind die wichtigen Indikatoren zur Messung der Leistung der Datenkomprimierungstechnologie?
- Was sind die Genauigkeitsbewertungsindikatoren für die absolute Positionierung?