
Heim >Technologie-Peripheriegeräte >KI >Kausalschlusspraxis in Kuaishou, kurze Videoempfehlung
Kausalschlusspraxis in Kuaishou, kurze Videoempfehlung

- 王林nach vorne
- 2024-02-05 18:20:07634Durchsuche
??

2. Kuaishou-Kurzvideoempfehlungsszenario
Im Kuaishou-Kurzvideoempfehlungsszenario ist die Einzelspalte das Hauptformular. Benutzer durchsuchen Videos mit dem Verhaltensmodus „Nach oben und unten schieben“. Sobald das Video verschoben wird, wird es automatisch abgespielt, ohne dass der Benutzer die Wiedergabe auswählen und dann anklicken muss. Darüber hinaus gibt es viele Formen des Benutzer-Feedbacks, einschließlich Folgen, Liken, Teilen von Kommentaren, Ziehen des Fortschrittsbalkens usw. Mit der Entwicklung des Geschäfts werden interaktive Formulare immer vielfältiger. Zu den Optimierungszielen gehören langfristige Ziele und kurzfristige Ziele. Zu den langfristigen Zielen gehören die Optimierung der Benutzererfahrung und die Beibehaltung der DAU, während kurzfristige Indikatoren verschiedene positive Rückmeldungen von Benutzern abdecken.
Das Empfehlungssystem basiert auf maschinellem Lernen und Deep Learning, und die Protokolle stammen hauptsächlich aus den Merkmalen und Rückmeldungen, die durch das tatsächliche Verhalten der Benutzer generiert werden. Protokolle unterliegen jedoch Einschränkungen und können nur begrenzte Informationen über die aktuellen Interessen des Benutzers wiedergeben. Private Informationen wie richtiger Name, Größe und Gewicht können nicht abgerufen werden. Gleichzeitig basiert der Empfehlungsalgorithmus auf dem vorherigen Lernen und Training des Protokolls und empfiehlt es dann den Benutzern, was die Eigenschaften einer Selbstschleife aufweist. Darüber hinaus ist das Empfehlungssystem aufgrund des breiten und vielfältigen Publikums, der großen Anzahl an Videos und der häufigen Aktualisierungen anfällig für verschiedene Verzerrungen, wie z. B. Beliebtheitsverzerrungen, Verzerrungen bei der Belichtung langer und kurzer Videos usw. Bei kurzen Videoempfehlungen kann die Bias-Modellierung mithilfe der kausalen Inferenztechnologie dabei helfen, Bias zu korrigieren und die Empfehlungseffekte zu verbessern.
2. Kausalinferenztechnologie und Modelldarstellung
Als nächstes werden wir unsere Arbeit mit unserem Bruderteam zum Thema Kausalinferenz und Modelldarstellung teilen.

Empfohlene Systeme führen Modelllernen normalerweise durch die Analyse von Interaktionsprotokollen durch. Das Feedback der Nutzer beruht nicht nur auf der Präferenz für Inhalte, sondern wird auch von der Herdenmentalität beeinflusst. Am Beispiel der Filmauswahl können Benutzer bei ihrer Entscheidung den preisgekrönten Status des Werks oder die Meinungen der Menschen in ihrem Umfeld berücksichtigen. Es gibt Unterschiede in der Herdenmentalität zwischen verschiedenen Benutzern. Einige Benutzer sind subjektiver und unabhängiger, während andere anfälliger für den Einfluss anderer oder der Popularität sind. Daher ist es bei der Zuordnung von Benutzerinteraktionen neben der Berücksichtigung der Interessen des Benutzers auch erforderlich, Faktoren der Herdenpsychologie zu berücksichtigen.
Die meisten vorhandenen Arbeiten behandeln Beliebtheit als statische Abweichung. Beispielsweise bezieht sich die Beliebtheit eines Films nur auf einen Artikel, und die Abweichung zwischen Benutzern wird bei der Modellierung von Benutzer- und Artikelbewertungen nicht berücksichtigt. Beliebtheit wird normalerweise als separates Bewertungselement verwendet, das mit der Anzahl der Expositionen des Elements zusammenhängt, und bei Elementen mit geringerer Beliebtheit besteht eine geringere Verzerrung. Diese Art der Modellierung ist statisch und artikelbezogen. Mit der Anwendung der Kausalinferenztechnologie im Empfehlungsbereich versuchen einige Forschungsarbeiten, dieses Problem durch entkoppelte Darstellung zu lösen und den Unterschied in der Herdenpsychologie zu berücksichtigen, wenn Benutzer Elemente auswählen. Im Vergleich zu bestehenden Methoden kann unsere Methode die Unterschiede in der Herdenmentalität der Benutzer genauer modellieren, wodurch Abweichungen effektiver korrigiert und Empfehlungseffekte verbessert werden.
2. Verwandte Arbeiten
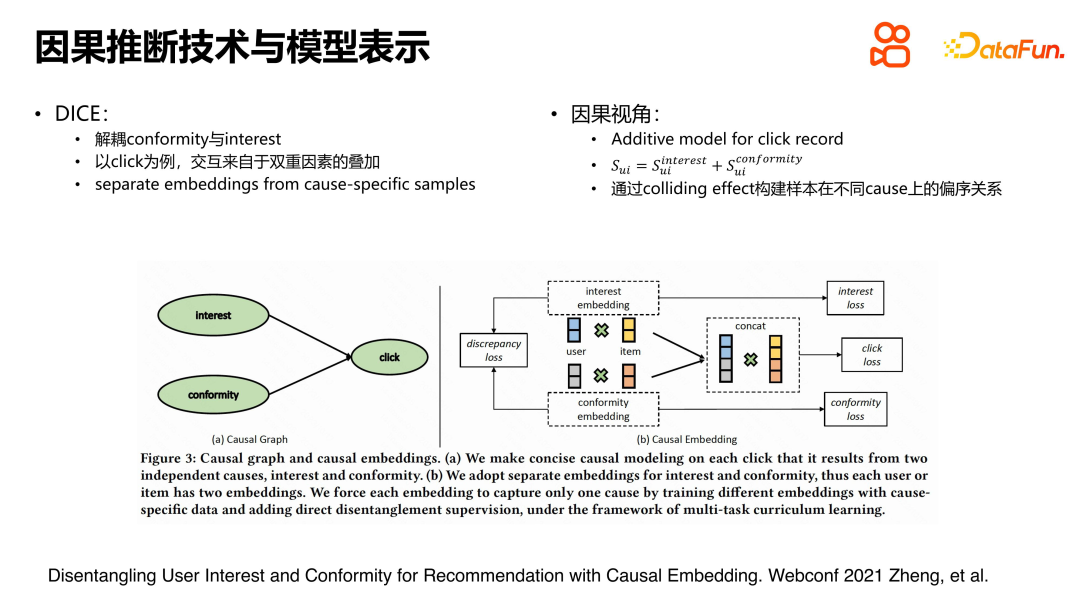
In einem Artikel auf der Webconf2021 wird modelliert, dass die Benutzerinteraktion sowohl vom Interesse des Benutzers an dem Artikel als auch vom Grad der Herdenmentalität beeinflusst wird, die der Artikel bei der Auswahl des Artikels ausübt Artikel. . Das Kausalbeziehungsdiagramm ist links dargestellt und die Beziehung ist relativ einfach. Bei der spezifischen Modellierung werden die Darstellungen von Benutzer und Artikel in Interessendarstellung und Konformitätsdarstellung aufgeteilt. Für die Interessenäußerung wird ein Zinsverlust konstruiert; für die Konformitätsäußerung wird ein Bestätigungsverlust konstruiert; für das Feedbackverhalten wird ein Klickverlust konstruiert. Aufgrund der Aufteilung der Repräsentationsstruktur wird der Zinsverlust als Überwachungssignal zum Erlernen der Interessenrepräsentation verwendet, während der Bestätigungsverlust zur Modellierung der Herdenmentalitätsrepräsentation verwendet wird. Der Klickverlust hängt von zwei Faktoren ab und wird daher durch Verkettung und Schnittmenge konstruiert. Der gesamte Ansatz ist klar und einfach.
Bei der Konstruktion von Zinsverlust und Bestätigungsverlust verwendet diese Forschung auch einige Konzepte und Techniken der kausalen Schlussfolgerung. Wenn beispielsweise ein unpopuläres Video oder Element positive Interaktionen hervorruft, liegt das wahrscheinlich daran, dass es den Benutzern tatsächlich gefallen hat. Dies kann durch eine umgekehrte Verifizierung bestätigt werden: Wenn ein Artikel nicht beliebt ist und Benutzer kein Interesse daran haben, ist es unwahrscheinlich, dass es zu einer positiven Interaktion kommt. Für den Klickverlust wird eine gängige Verarbeitungsmethode angewendet, nämlich der paarweise Verlust. Bezüglich des Kollisionseffekts können interessierte Leser auf das Papier verweisen, um eine detailliertere Konstruktionsmethode zu finden.
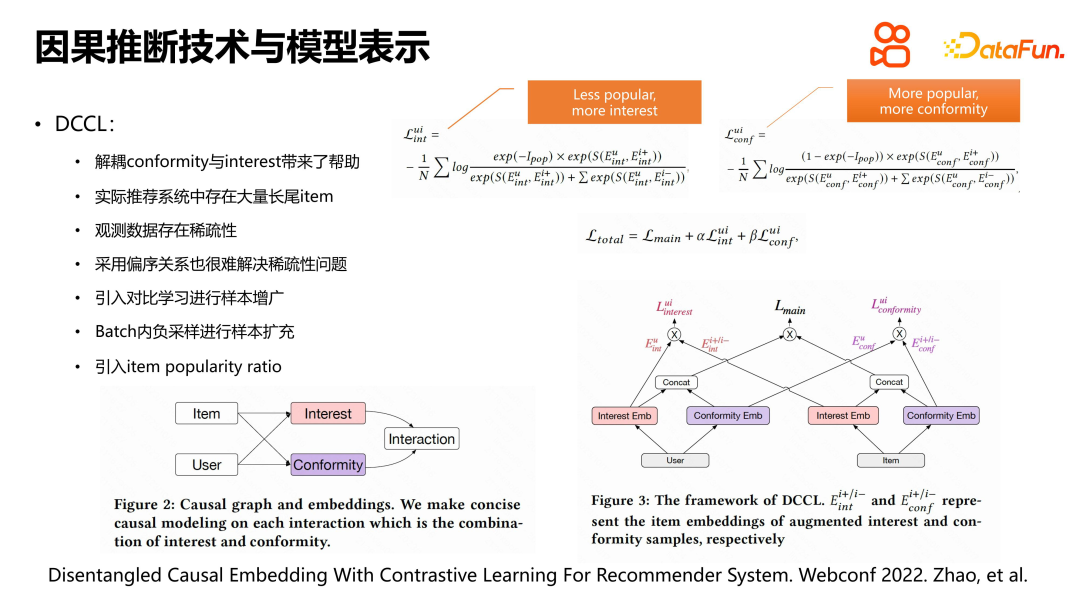
Bei der Lösung komplexer Probleme in Empfehlungssystemen beginnen einige Untersuchungen mit der Modelldarstellung und zielen darauf ab, das Interesse der Benutzer an Artikeln und die Herdenmentalität zu unterscheiden. Allerdings gibt es bei der praktischen Anwendung einige Probleme. Es gibt eine große Anzahl von Videos im Empfehlungssystem und die Belichtungen sind ungleichmäßig verteilt. Head-Videos haben mehr Belichtungen und Long-Tail-Videos haben weniger Belichtungen, was zu spärlichen Daten führt. Sparsity führt zu Lernschwierigkeiten bei Modellen für maschinelles Lernen.
Um dieses Problem zu lösen, haben wir kontrastives Lernen zur Probenvergrößerung eingeführt. Konkret haben wir zusätzlich zur positiven Interaktion zwischen dem Benutzer und dem Artikel auch andere Videos im Verhaltensbereich des Benutzers als negative Beispiele für die Erweiterung ausgewählt. Gleichzeitig haben wir das Ursache-Wirkungs-Diagramm verwendet, um das Modell zu entwerfen und die Interessen- und Konformitätsdarstellungen auf Benutzer- und Artikelseite aufzuteilen. Der Hauptunterschied zwischen diesem Modell und dem herkömmlichen DICE besteht darin, dass es die Methode des kontrastiven Lernens und der Stichprobenerweiterung beim Erlernen der Verluste an Interesse und Bestätigung anwendet und normalisierte Elementpopularitätsverhältnis-Indexterme für Zinsverlust bzw. Bestätigungsverlust erstellt. Auf diese Weise kann das Problem der Datensparsität besser gehandhabt werden und das Interesse und die Herdenmentalität der Benutzer für Artikel unterschiedlicher Beliebtheit genauer modelliert werden.
3. Zusammenfassung
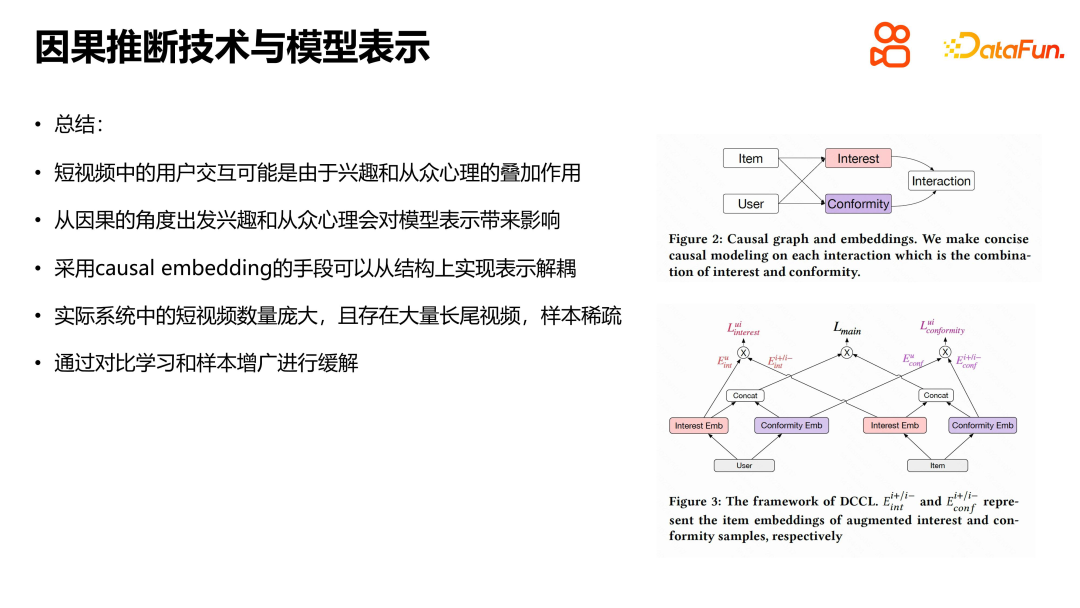
Diese Arbeit basiert auf der Überlagerung von Interesse und Herdenpsychologie in kurzen Videointeraktionen und nutzt kausale Inferenztechnologie und kausale Einbettungsmethoden, um eine Entkopplung der strukturellen Darstellung zu erreichen. Gleichzeitig werden angesichts des spärlichen Problems von Long-Tail-Video-Samples in tatsächlichen Systemen kontrastives Lernen und Methoden zur Probenerweiterung verwendet, um die Spärlichkeit zu lindern. Diese Arbeit kombiniert Online-Repräsentationsmodelle und kausale Schlussfolgerungen, um einen gewissen Konformitätsentkopplungseffekt zu erzielen. Diese Methode zeigte in Offline- und Online-Experimenten gute Ergebnisse und wurde erfolgreich in LTR-Experimenten mit Kuaishou-Empfehlung eingesetzt, was zu bestimmten Effektverbesserungen führte. 3. Schätzung der Betrachtungsdauer und kausale Inferenztechnologie Benutzer: Langfristige Kennzahlen wie Kundenbindung, DAU und wiederkehrende Besuche stehen in engem Zusammenhang. Um das Benutzererlebnis zu verbessern, müssen wir uns bei der Empfehlung von Videos an Benutzer auf Zwischenverhaltensindikatoren konzentrieren. Die Erfahrung zeigt, dass die Wiedergabezeit eine sehr wertvolle Messgröße ist, da die Aufmerksamkeitsspanne der Nutzer begrenzt ist. Indem wir Veränderungen in der Sehzeit der Nutzer beobachten, können wir besser verstehen, welche Faktoren das Seherlebnis der Nutzer beeinflussen.
Die Videolänge ist einer der wichtigen Faktoren, die die Betrachtungszeit beeinflussen. Mit zunehmender Länge des Videos erhöht sich entsprechend auch die Betrachtungszeit des Nutzers, ein zu langes Video kann jedoch zu nachlassenden Randeffekten oder sogar zu einer leichten Verkürzung der Betrachtungszeit führen. Daher muss das Empfehlungssystem einen Gleichgewichtspunkt finden, um die Videolänge zu empfehlen, die den Bedürfnissen des Benutzers entspricht.
Um die Sehzeit zu optimieren, muss das Empfehlungssystem die Sehzeit des Benutzers vorhersagen. Dabei handelt es sich um ein Regressionsproblem, da die Dauer ein kontinuierlicher Wert ist. Allerdings gibt es weniger Arbeit im Zusammenhang mit der Dauer, wahrscheinlich weil das Geschäft mit kurzen Videoempfehlungen relativ neu ist, während die Forschung zu Empfehlungssystemen eine lange Geschichte hat.
Bei der Lösung des Problems der Schätzung der Betrachtungszeit können neben der Videolänge auch andere Faktoren berücksichtigt werden, z. B. Benutzerinteresse, Qualität des Videoinhalts usw. Durch die Berücksichtigung dieser Faktoren wird die Genauigkeit der Vorhersagen verbessert und den Benutzern ein besseres Empfehlungserlebnis geboten. Gleichzeitig müssen wir den Empfehlungsalgorithmus kontinuierlich iterieren und optimieren, um ihn an Veränderungen im Markt und veränderte Benutzerbedürfnisse anzupassen.
2, D2Q
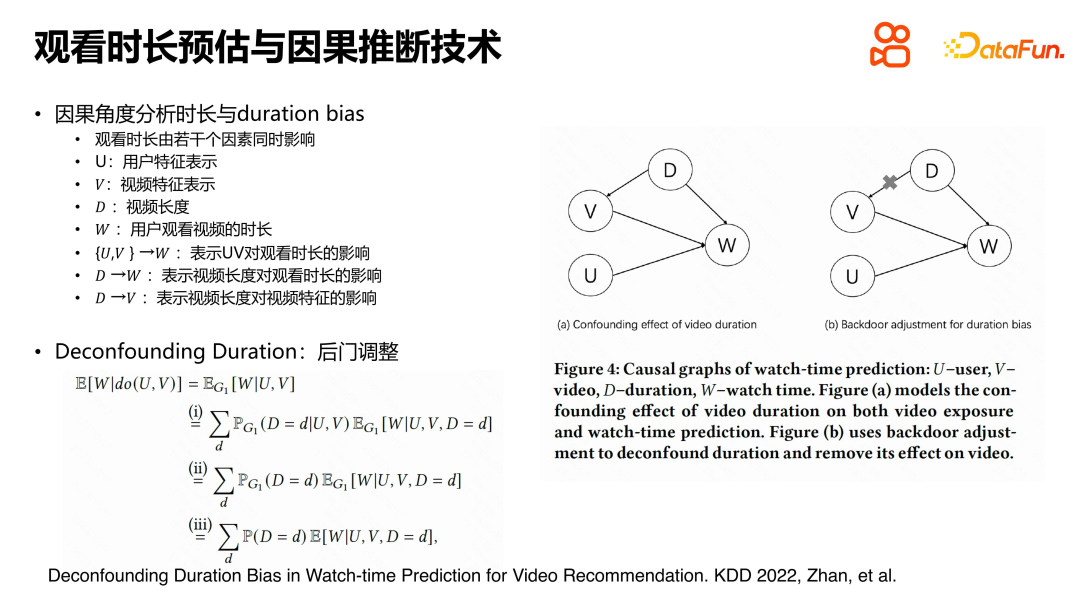
Auf der KDD212-Konferenz haben wir eine neue Methode vorgeschlagen, um das Problem der Dauerschätzung in kurzen Videoempfehlungen zu lösen. Dieses Problem ist hauptsächlich auf das sich selbst verstärkende Phänomen der Dauerverzerrung bei kausalen Schlussfolgerungen zurückzuführen. Um dieses Problem zu lösen, führen wir ein Ursache-Wirkungs-Diagramm ein, um die Beziehung zwischen Benutzern, Videos und Betrachtungsdauer zu beschreiben.
Im Kausaldiagramm stellen U und V die Funktionsdarstellung des Benutzers bzw. des Videos dar, W stellt die Zeitspanne dar, in der der Benutzer das Video ansieht, und D stellt die Länge des Videos dar. Wir haben festgestellt, dass die Dauer aufgrund des selbstzyklischen Generierungsprozesses des Empfehlungssystems nicht nur in direktem Zusammenhang mit der Betrachtungsdauer steht, sondern auch das Erlernen der Videodarstellung beeinflusst.
Um den Einfluss der Dauer auf die Videodarstellung zu eliminieren, haben wir zur Ableitung Do-Kalkül verwendet. Die abschließende Schlussfolgerung zeigt, dass die einfachste und direkteste Methode zur Lösung dieses Problems durch Hintertüranpassung darin besteht, die Betrachtungsdauer für die Samples, die jedem Video mit der Dauer entsprechen, separat zu schätzen. Dadurch kann der Verstärkungseffekt der Dauer auf die Betrachtungsdauer beseitigt werden, wodurch das Problem der Dauerverzerrung bei kausalen Schlussfolgerungen effektiv gelöst wird. Die Kernidee dieser Methode besteht darin, den Fehler von d nach v zu eliminieren und dadurch die Bias-Verstärkung abzuschwächen.

Bei der Lösung des Problems der Dauerschätzung bei kurzen Videoempfehlungen haben wir eine auf kausaler Schlussfolgerung basierende Methode angewendet, um den Fehler von d zu v zu beseitigen und eine Abschwächung der Bias-Verstärkung zu erreichen. Um das Problem der Dauer als kontinuierliche Variable und der Verteilung der Anzahl der Videos zu lösen, gruppieren wir die Videos im Empfehlungspool nach Dauer und verwenden Quantile zur Berechnung. Die Daten innerhalb jeder Gruppe werden aufgeteilt und zum Trainieren des Modells innerhalb der Gruppe verwendet. Während des Trainingsprozesses wird das Quantil, das der Videodauer in jeder Dauergruppe entspricht, zurückgeführt, anstatt die Dauer direkt zurückzurechnen. Dies reduziert die Datensparsamkeit und vermeidet eine Überanpassung des Modells. Suchen Sie bei der Online-Inferenz für jedes Video zunächst die entsprechende Gruppe und berechnen Sie dann das entsprechende Dauerquantil. In der Tabelle können Sie die tatsächliche Sehdauer anhand der Quantile ermitteln. Diese Methode vereinfacht den Online-Argumentationsprozess und verbessert die Genauigkeit der Dauerschätzung. Zusammenfassend lässt sich sagen, dass unsere Methode das Problem der Dauerschätzung bei kurzen Videoempfehlungen effektiv löst, indem sie den Fehler von d bis v eliminiert und eine starke Unterstützung für die Optimierung der Benutzererfahrung bietet.
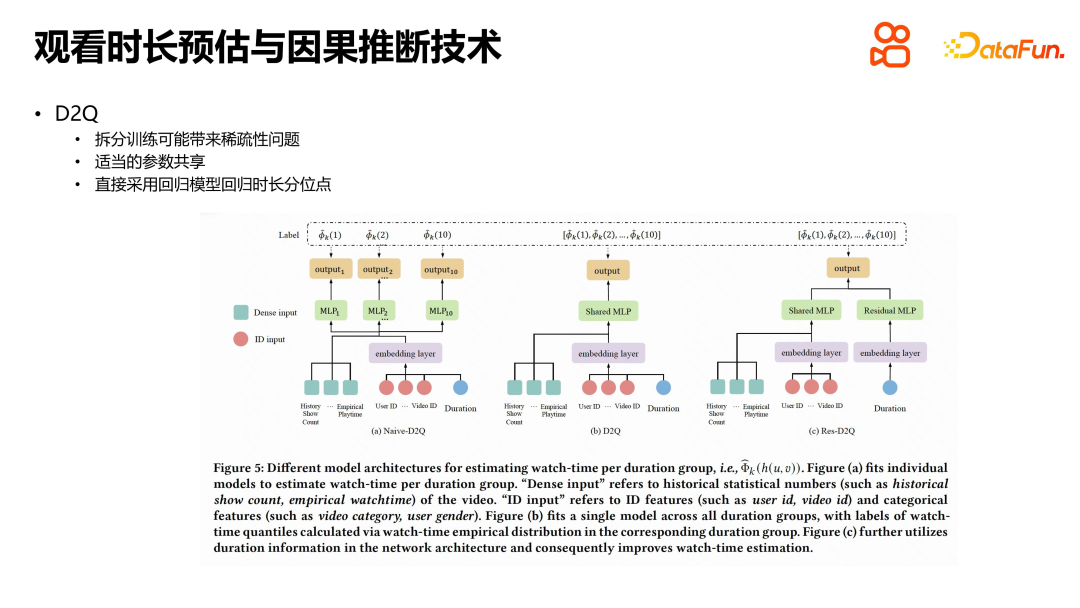
Bei der Lösung des Problems der Dauerschätzung in kurzen Videoempfehlungen haben wir auch eine Methode zur Parameterfreigabe eingeführt, um technische Schwierigkeiten zu reduzieren. Im Split-Training-Prozess besteht ein idealer Ansatz darin, eine vollständige Trennung von Daten, Funktionen und Modellen zu erreichen, was jedoch die Bereitstellungskosten erhöht. Daher haben wir einen einfacheren Weg gewählt, der darin besteht, die Einbettung der zugrunde liegenden Features und Modellparameter der mittleren Ebene zu teilen und sie nur in der Ausgabeebene aufzuteilen. Um den Einfluss der Dauer auf die tatsächliche Betrachtungsdauer weiter zu vergrößern, führen wir eine Restverbindung ein, um die Dauer direkt mit dem Teil zu verbinden, der das Quantil der geschätzten Dauer ausgibt, wodurch der Einfluss der Dauer verstärkt wird. Diese Methode reduziert die technischen Schwierigkeiten und löst effektiv das Problem der Dauerschätzung bei kurzen Videoempfehlungen.
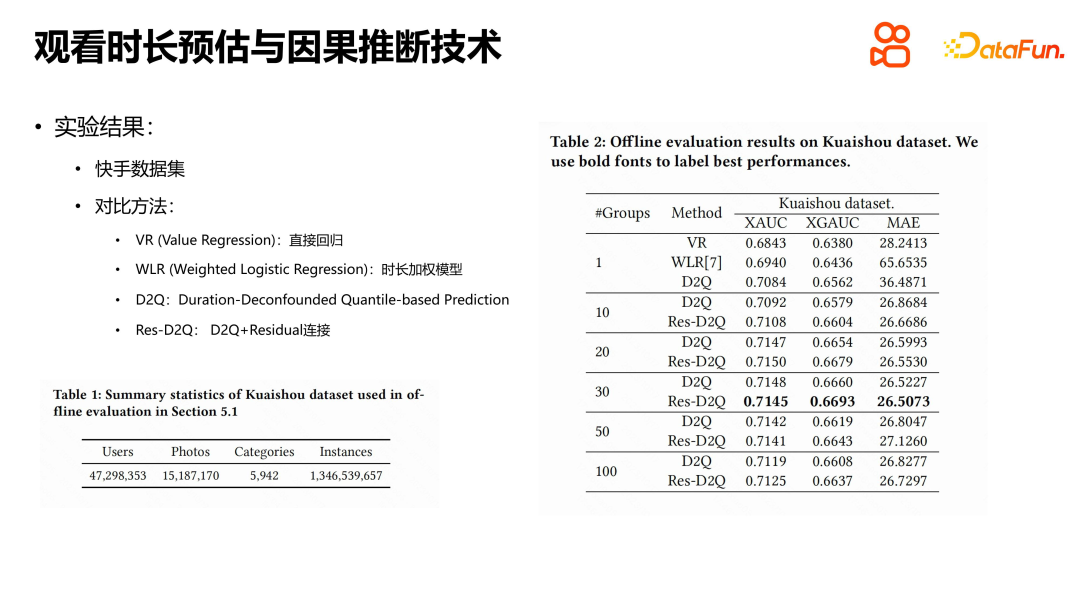
Im Experiment wurde hauptsächlich der von Kuaishou veröffentlichte öffentliche Datensatz verwendet. Durch den Vergleich mehrerer Methoden können wir erkennen, dass die Leistung direkter Regression und dauergewichteter Modelle ihre eigenen Vorzüge hat. Das dauergewichtete Modell ist in Empfehlungssystemen kein Unbekannter. Seine Kernidee besteht darin, die Betrachtungsdauer als Gewicht positiver Stichproben in das Modell einzubeziehen. D2Q und Res-D2Q sind zwei Modellstrukturen, die auf kausalen Schlussfolgerungen basieren, wobei Res-D2Q Restverbindungen einführt. Durch Experimente haben wir herausgefunden, dass die besten Ergebnisse erzielt werden können, wenn Videos nach Dauer in 30 Gruppen gruppiert werden. Im Vergleich zum naiven Regressionsmodell weist die D2Q-Methode erhebliche Verbesserungen auf und kann das Problem der Selbstschleifenverstärkung der Dauerverzerrung bis zu einem gewissen Grad lindern. Aus Sicht des Problems der Dauerschätzung ist die Herausforderung jedoch immer noch nicht vollständig gelöst.
3. TPM
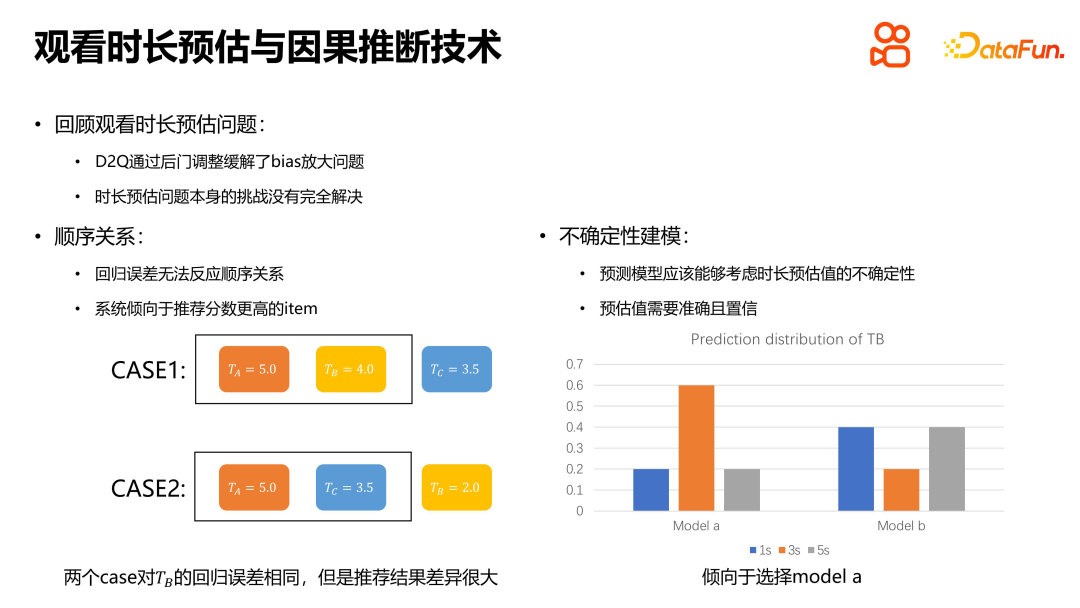
Als Kernproblem im Empfehlungssystem weist das Problem der Zeitdauerschätzung seine eigenen einzigartigen Merkmale und Herausforderungen auf. Erstens kann das Regressionsmodell die sequentielle Beziehung der Empfehlungsergebnisse nicht widerspiegeln, sodass die tatsächlichen Empfehlungsergebnisse selbst bei gleichem Regressionsfehler sehr unterschiedlich sein können. Darüber hinaus muss das Vorhersagemodell nicht nur die Genauigkeit der Schätzung sicherstellen, sondern auch die Zuverlässigkeit der vom Modell gegebenen Schätzung berücksichtigen. Ein vertrauenswürdiges Modell sollte nicht nur genaue Schätzungen liefern, sondern diese Schätzung auch mit hoher Wahrscheinlichkeit liefern. Daher müssen wir bei der Lösung des Problems der Dauerschätzung nicht nur auf die Genauigkeit der Regression achten, sondern auch die Zuverlässigkeit des Modells und die Ordnungsbeziehung der geschätzten Werte berücksichtigen.
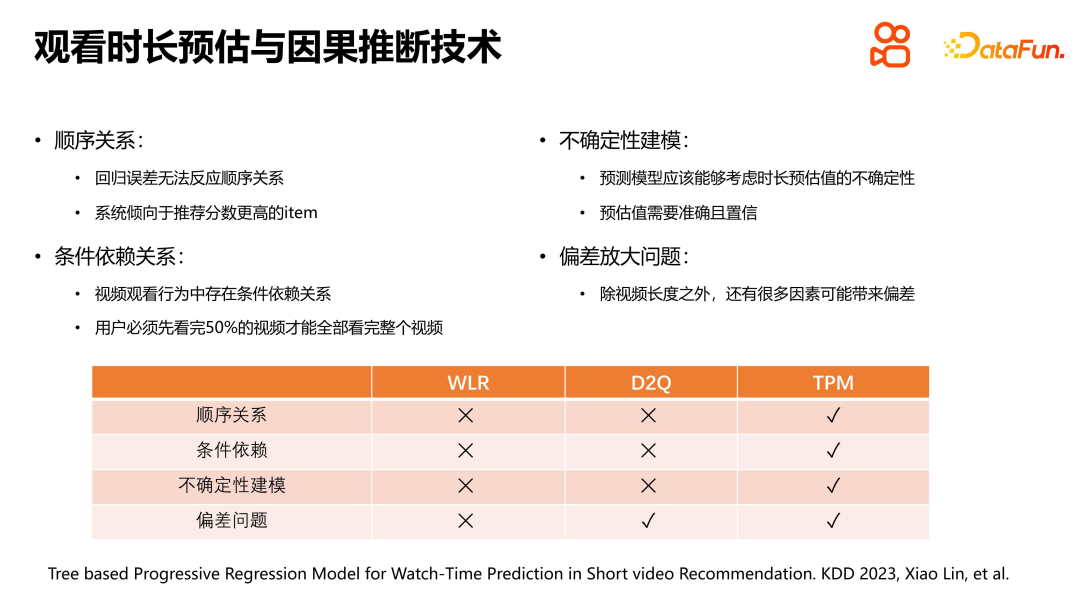
Im Sehverhalten besteht eine bedingte Abhängigkeit vom kontinuierlichen Betrachten von Videos durch den Nutzer. Insbesondere wenn das Ansehen des gesamten Videos ein zufälliges Ereignis ist, ist das Ansehen von 50 % des Videos als erstes ebenfalls ein zufälliges Ereignis, und zwischen ihnen besteht eine strikte bedingte Abhängigkeit. Die Lösung des Bias-Verstärkungsproblems ist bei der Schätzung der Betrachtungszeit sehr wichtig, und die D2Q-Methode löst dieses Problem gut. Im Gegensatz dazu zielt unser vorgeschlagener TPM-Ansatz darauf ab, alle Probleme der Dauerschätzung umfassend abzudecken.
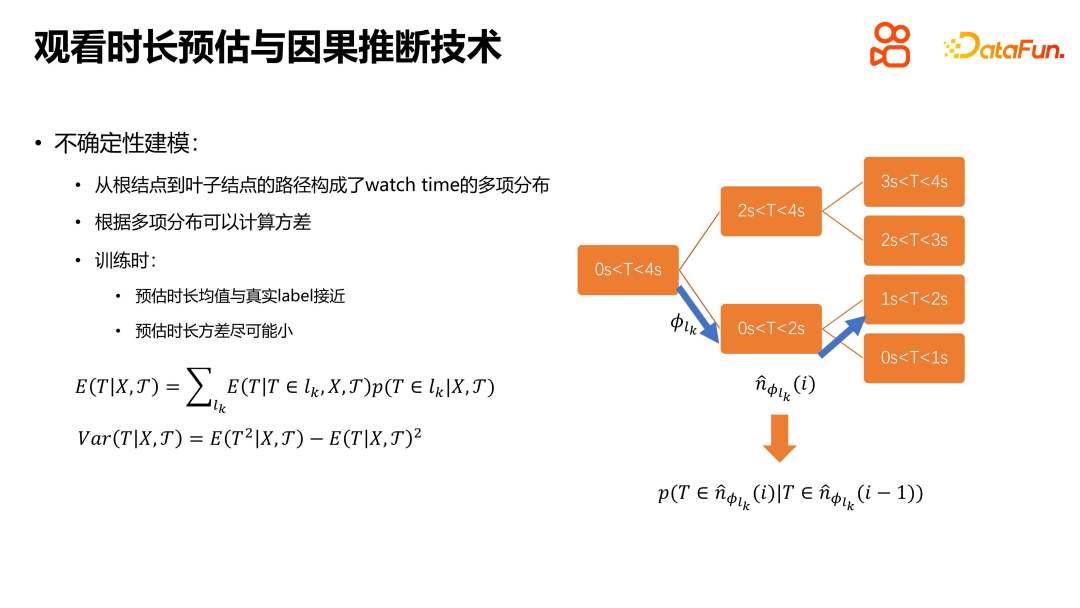
Die Hauptidee der TPM-Methode besteht darin, das Problem der Dauerschätzung in ein diskretes Suchproblem umzuwandeln. Durch die Konstruktion eines vollständigen Binärbaums wird das Problem der Dauerschätzung in mehrere Klassifizierungsprobleme umgewandelt, die bedingt voneinander abhängig sind, und dann wird ein binärer Klassifizierer verwendet, um diese Klassifizierungsprobleme zu lösen. Durch die kontinuierliche Durchführung einer binären Suche nach unten wird die Wahrscheinlichkeit der Betrachtungsdauer innerhalb jedes geordneten Intervalls bestimmt und schließlich eine multinomiale Verteilung der Betrachtungsdauer gebildet. Diese Methode kann das Problem der Unsicherheitsmodellierung effektiv lösen, indem sie den Mittelwert der geschätzten Dauer so nah wie möglich an den wahren Wert bringt und gleichzeitig die Varianz der geschätzten Dauer verringert. Das gesamte Betrachtungszeitproblem oder der gesamte Schätzprozess kann schrittweise durch kontinuierliches Lösen voneinander abhängiger binärer Klassifizierungsprobleme gelöst werden. Diese Methode bietet eine neue Idee und einen neuen Rahmen zur Lösung des Problems der Dauerschätzung, wodurch die Genauigkeit und Zuverlässigkeit der Schätzung verbessert werden kann.
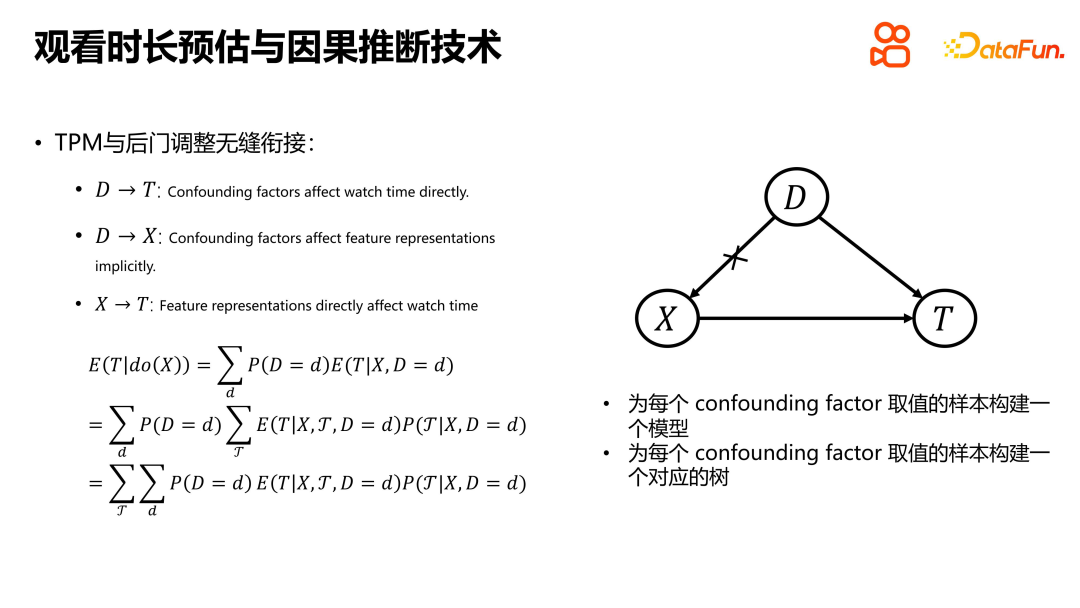
Mit der Einführung der Idee, die kritische Dauer von TPM zu modellieren, wurde die nahtlose Verbindung zwischen TPM und der Hintertüranpassung von D2Q demonstriert. Hier wird ein einfaches Ursache-Wirkungs-Diagramm verwendet, um benutzer- und artikelseitige Merkmale mit Störfaktoren zu verknüpfen. Um die Hintertüranpassung in TPM zu implementieren, ist es notwendig, für jede Stichprobe ein entsprechendes Modell mit einem Störfaktorwert zu erstellen und für jeden Störfaktor einen entsprechenden TPM-Baum zu erstellen. Sobald diese beiden Schritte abgeschlossen sind, kann das TPM nahtlos mit der Hintertürverstellung verbunden werden. Durch diese Art der Verbindung kann das Modell Störfaktoren besser verarbeiten und so die Vorhersagegenauigkeit und -zuverlässigkeit verbessern.
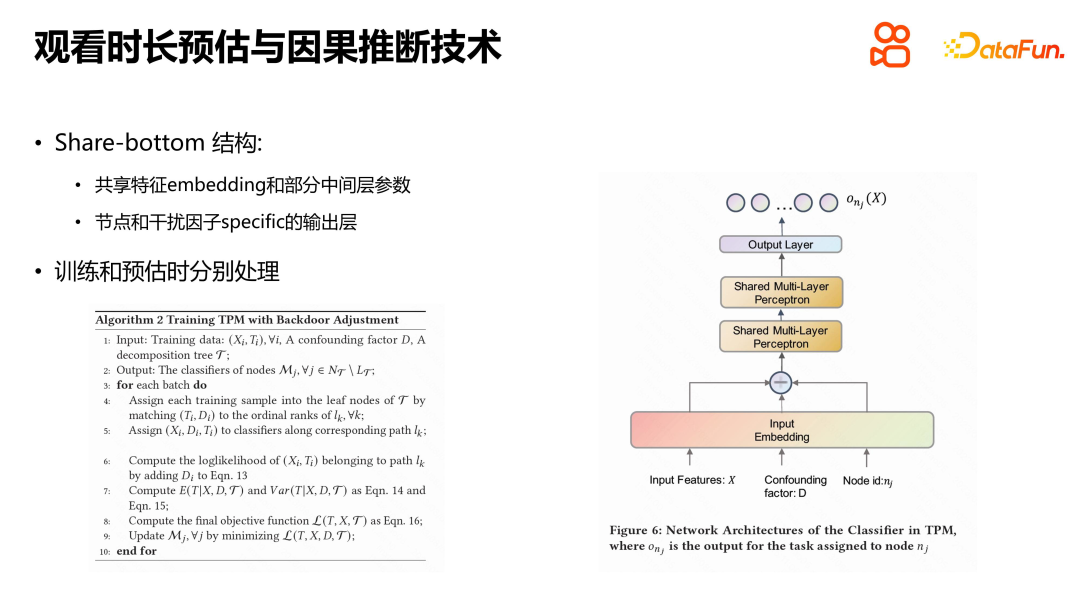
Die spezifische Lösung besteht darin, für jeden Störfaktor auf tiefer Ebene ein entsprechendes Modell zu erstellen. Dies führt auch zu den Problemen der Datenspärlichkeit und es sind zu viele Modellparameter erforderlich, um die einzelnen Stichproben zu konvertieren Jeder Störfaktor wird in dasselbe Modell integriert, aber die zugrunde liegende Einbettungsdarstellung, die Zwischenparameter usw. des Modells werden alle gemeinsam genutzt und beziehen sich nur auf die tatsächlichen Knoten und Interferenzfaktorwerte in der Ausgabeschicht. Während des Trainings müssen Sie für das Training nur den echten Blattknoten finden, der jeder Trainingsprobe entspricht. Da wir bei der Schätzung nicht wissen, zu welchem Blattknoten die Betrachtungsdauer gehört, müssen wir von oben nach unten durchlaufen und eine gewichtete Summe der Wahrscheinlichkeit jedes Blattknotens, in dem sich die Betrachtungsdauer befindet, und der erwarteten Dauer von durchführen den entsprechenden Blattknoten, um die tatsächliche Anzeigezeit zu erhalten. Durch diese Verarbeitungsmethode kann das Modell besser mit Störfaktoren umgehen und die Vorhersagegenauigkeit und -zuverlässigkeit verbessern.
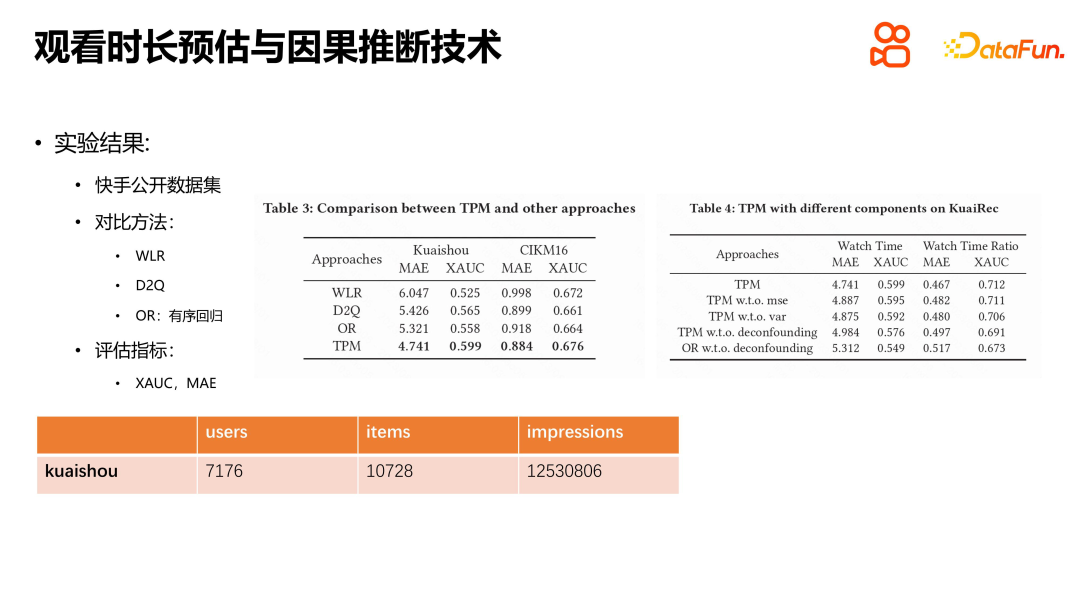
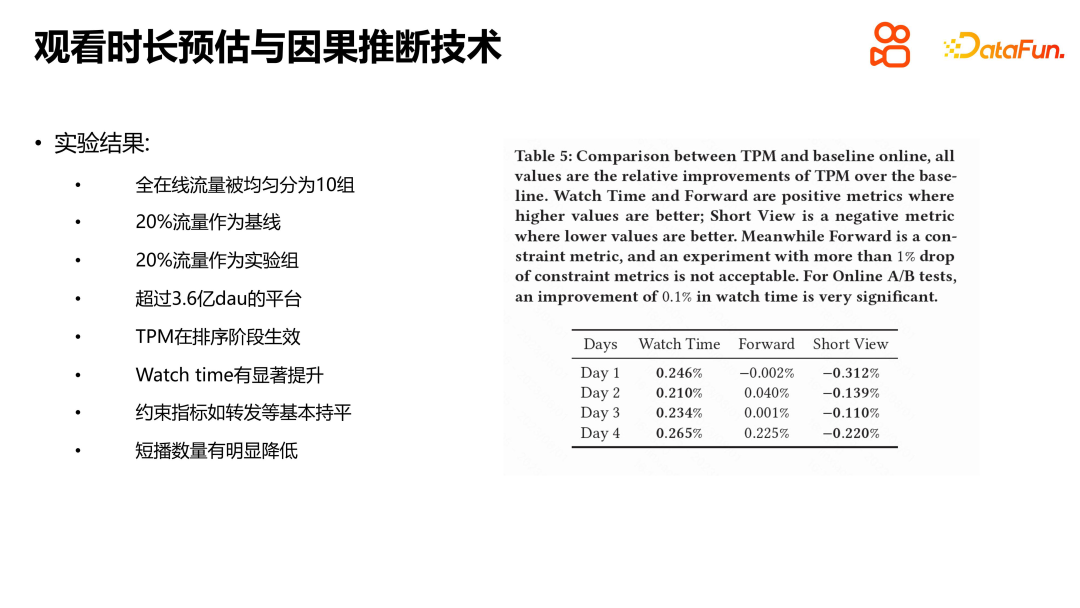
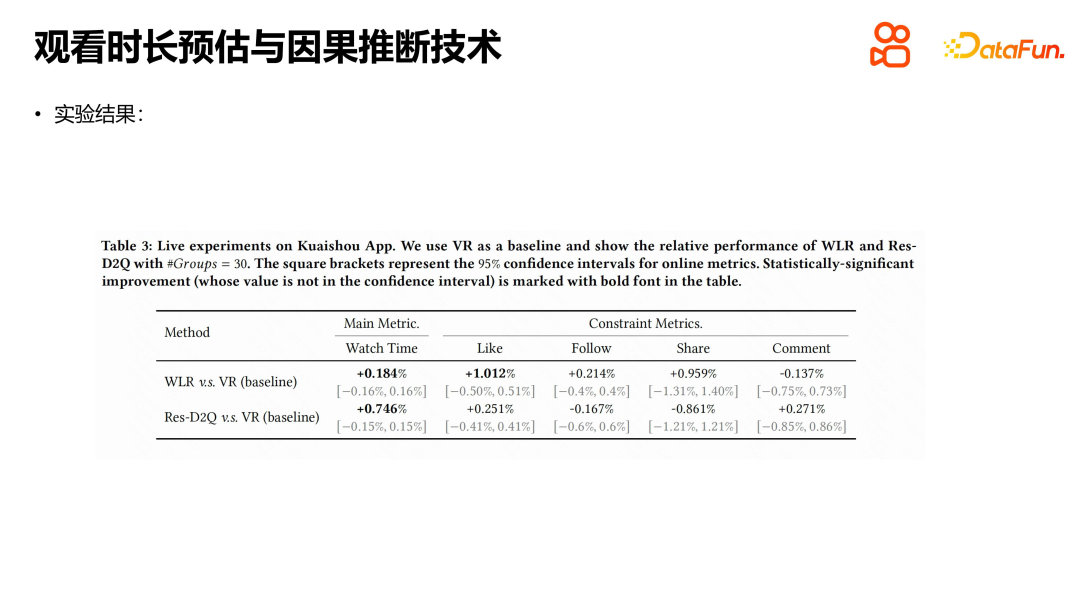
Wir haben Experimente mit dem öffentlichen Datensatz von Kuaishou und dem Datensatz CIKM16 zur Verweildauer durchgeführt und dabei Methoden wie WLR, D2Q und OR verglichen. Die Ergebnisse zeigten, dass TPM erhebliche Vorteile hat. Jedes Modul hat seine spezifische Rolle, und wir haben auch Standardexperimente durchgeführt. Die experimentellen Ergebnisse zeigen, dass jedes Modul eine Rolle spielt. Wir haben auch online mit TPM experimentiert. Die Versuchsbedingungen bestanden darin, den ausgewählten Datenverkehr von Kuaishou gleichmäßig in zehn Gruppen aufzuteilen, und 20 % des Datenverkehrs wurden als Basis für den Vergleich mit der Online-Versuchsgruppe verwendet. Experimentelle Ergebnisse zeigen, dass TPM die Sehzeit der Benutzer in der Sortierphase erheblich verlängern kann, während andere Indikatoren im Wesentlichen gleich bleiben. Es ist erwähnenswert, dass auch negative Indikatoren wie die Anzahl der Benutzer-Kurzwellen zurückgegangen sind, was unserer Meinung nach in einem gewissen Zusammenhang mit der Genauigkeit der Dauerschätzungen und der Verringerung der Unsicherheit bei den Schätzungen steht. Die Anschauungsdauer ist der Kernindikator der Kurzvideo-Empfehlungsplattform, und die Einführung von TPM ist von großer Bedeutung für die Verbesserung der Benutzererfahrung und der Plattformindikatoren.
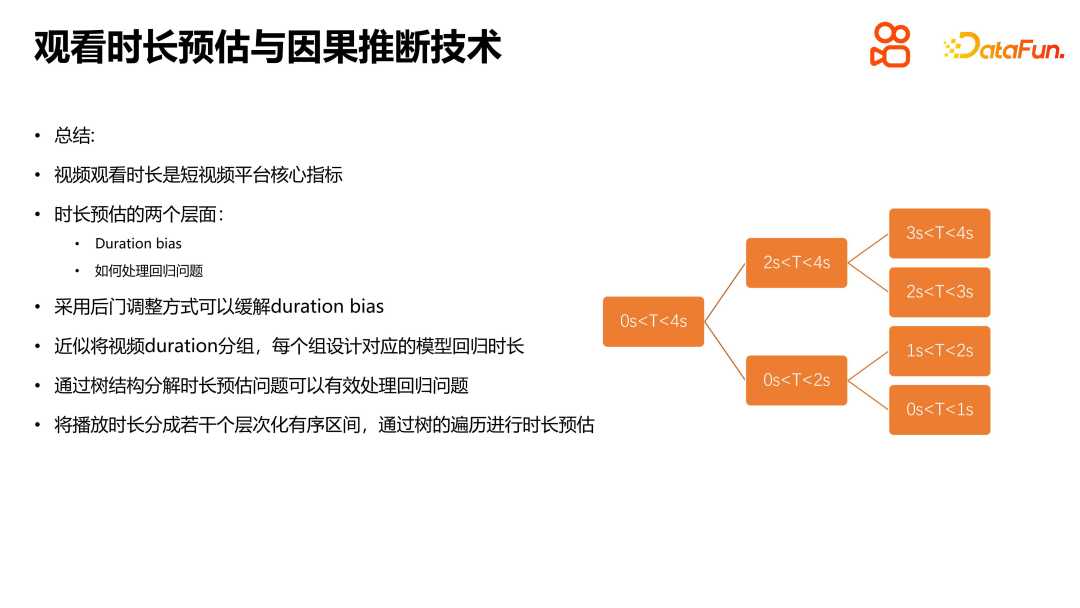
Fassen wir diesen Teil der Einleitung zusammen. Bei Kurzvideo-Empfehlungsplattformen ist die Betrachtungszeit der zentrale Indikator. Bei der Lösung dieses Problems sind zwei Ebenen zu berücksichtigen: Die eine ist das Bias-Problem, einschließlich der Bias der Dauer und der Bias der Beliebtheit, das in der Selbstschleife des gesamten Systemverbindungsprotokolls zum Training gelöst werden muss, und die andere ist das Problem der Dauerschätzung , was selbst ein kontinuierlicher Wert ist. Vorhersageprobleme entsprechen normalerweise Regressionsproblemen. Für spezielle Regressionsprobleme bei der Dauerschätzung müssen jedoch spezielle Methoden verwendet werden. Erstens kann das Bias-Problem durch eine Hintertüranpassung gemildert werden. Die spezifische Methode besteht darin, die Dauer zu gruppieren und für jede Gruppe ein entsprechendes Modell für die Regression zu entwerfen. Zweitens kann zur Lösung des Regressionsproblems der Dauerschätzung eine Baumstruktur verwendet werden, um die Dauerschätzung in mehrere hierarchisch geordnete Intervalle zu zerlegen. Durch den Baumdurchquerungsprozess kann das Problem entlang des Pfads von oben zu den Blattknoten zerlegt werden . und lösen. Bei der Schätzung wird die Dauer durch Baumdurchquerung geschätzt. Diese Verarbeitungsmethode kann das Regressionsproblem der Dauerschätzung effektiver lösen und die Genauigkeit und Zuverlässigkeit der Vorhersage verbessern.
4. Zukunftsausblick
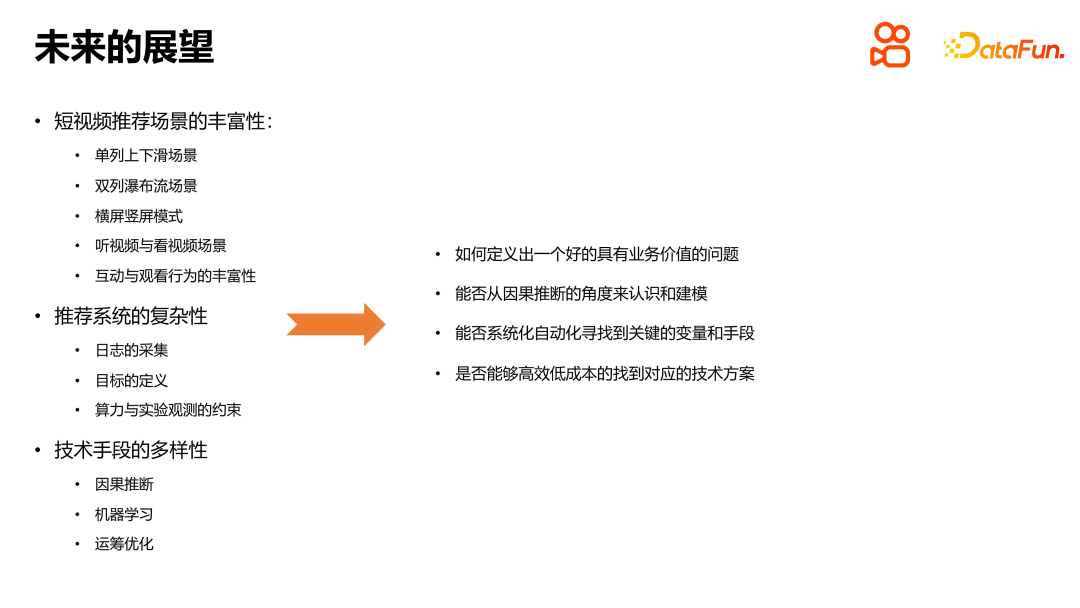
Mit der Beschleunigung der technologischen Entwicklung wird die Welt, in der wir leben, immer komplexer. In Kuaishous Kurzvideo-Empfehlungsszenario ist die Komplexität des Empfehlungssystems immer deutlicher geworden. Um bessere Empfehlungen abgeben zu können, müssen wir die Anwendung kausaler Schlussfolgerungen in Empfehlungssystemen eingehend untersuchen. Zunächst müssen wir ein Problem mit geschäftlichem Wert definieren, beispielsweise die Schätzung der Wiedergabezeit. Wir können dieses Problem dann aus der Perspektive einer kausalen Schlussfolgerung verstehen und modellieren. Durch die Methode der Kausalanpassung oder Kausalinferenz können wir Bias-Probleme wie Dauer-Bias und Beliebtheits-Bias besser analysieren und lösen. Darüber hinaus können wir auch technische Mittel wie maschinelles Lernen und Betriebsoptimierung nutzen, um Probleme wie Systemkomplexität und Szenenverteilung zu lösen. Um effiziente Lösungen zu erreichen, müssen wir einen systematischen und automatisierten Weg zur Problemlösung finden. Dies verbessert nicht nur die Arbeitseffizienz, sondern bringt auch einen dauerhaften Mehrwert für das Unternehmen. Schließlich müssen wir uns auf die Skalierbarkeit und Kosteneffizienz der Technologie konzentrieren, um die Machbarkeit und Nachhaltigkeit der Lösung sicherzustellen.
Zusammenfassend ist die Anwendung kausaler Schlussfolgerungen in Empfehlungssystemen eine herausfordernde und potenzielle Forschungsrichtung. Durch kontinuierliche Erkundung und Praxis können wir die Wirksamkeit des Empfehlungssystems kontinuierlich verbessern, den Benutzern ein besseres Erlebnis bieten und einen größeren Wert für das Unternehmen schaffen.
Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Vielen Dank an alle.
5. Frage-und-Antwort-Runde
Q1: Im Vergleich zu D2Q hat TPM bei der Regression einige Verbesserungen vorgenommen, um Dauerabhängigkeiten besser zu nutzen. Ich würde gerne fragen, worauf sich die Abhängigkeitsbeziehung hier bezieht?
A1: Der Übergang vom Kopfknoten zum Blattknoten kann als kontinuierlicher Entscheidungsprozess ähnlich wie bei MDP betrachtet werden. Bedingte Abhängigkeit bedeutet, dass die Entscheidung der nächsten Schicht auf den Ergebnissen der vorherigen Schicht basiert. Um beispielsweise den Blattknoten zu erreichen, bei dem es sich um das Intervall [0,1] handelt, müssen Sie zunächst den Zwischenknoten durchlaufen, bei dem es sich um das Intervall [0,2] handelt. Diese Abhängigkeit wird in der tatsächlichen Online-Schätzung durch jeden Klassifikator realisiert, der nur entscheidet, ob ein bestimmter Knoten zum nächsten Blattknoten gehen soll. Es ist wie im Beispiel der Altersschätzung: Zuerst wird gefragt, ob das Alter älter als 50 ist, und dann abhängig von der Antwort gefragt, ob es älter als 25 ist. Hier liegt eine bedingte Abhängigkeit implizit vor, d. h. jünger als 50 Jahre ist Voraussetzung für die Beantwortung der zweiten Frage.
F2: Wird die Verwendung des Baummodells zu Schwierigkeiten bei den Kosten für Modelltraining und Online-Inferenz führen?
A2: Im Vergleich der Vorteile von TPM und D2Q liegt der Hauptvorteil in der Aufteilung der Probleme. TPM nutzt zeitliche Informationen besser und teilt das Problem in mehrere binäre Klassifizierungsprobleme mit relativ ausgewogenen Stichproben auf, was zur Lernbarkeit des Modelltrainings und -lernens beiträgt. Im Gegensatz dazu können Regressionsprobleme durch Ausreißer und andere Ausreißer beeinflusst werden, was zu einer größeren Lerninstabilität führt. In praktischen Anwendungen haben wir viele praktische Arbeiten durchgeführt, einschließlich der Beispielkonstruktion und Berechnung von TF-Diagrammknotenbeschriftungen. Bei der Online-Bereitstellung verwenden wir ein Modell, dessen Ausgabedimension jedoch die Anzahl der Zwischenknotenklassifikatoren ist. Für jedes Video wählen wir nur eine der Dauergruppen aus und berechnen die Ausgabe des entsprechenden Klassifikators. Dann wird die Verteilung auf den Blattknoten durch eine Schleife berechnet und schließlich wird eine gewichtete Summe durchgeführt. Obwohl die Modellstruktur relativ einfach ist, können die Klassifikatoren jeder Dauergruppe und jedes Nicht-Blattknotens die zugrunde liegende Einbettungs- und Zwischenschicht gemeinsam nutzen, sodass sie sich bei der Vorwärtsinferenz mit Ausnahme der Ausgabeschicht nicht wesentlich vom normalen Modell unterscheidet.
Das obige ist der detaillierte Inhalt vonKausalschlusspraxis in Kuaishou, kurze Videoempfehlung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!