
Heim >Technologie-Peripheriegeräte >KI >CMUÐ gelingt ein Durchbruch: Der Roboterhund verfügt über einen vollen Beweglichkeitswert und kann Hindernisse mit extrem hoher Geschwindigkeit überwinden, wodurch Geschwindigkeit und Sicherheit kombiniert werden!
CMUÐ gelingt ein Durchbruch: Der Roboterhund verfügt über einen vollen Beweglichkeitswert und kann Hindernisse mit extrem hoher Geschwindigkeit überwinden, wodurch Geschwindigkeit und Sicherheit kombiniert werden!

- 王林nach vorne
- 2024-02-05 16:33:15860Durchsuche
CMU- und ETH-Teams arbeiteten zusammen, um ein neues Framework namens „Agile But Safe“ (ABS) zu entwickeln, das eine Lösung für vierbeinige Roboter bietet, um Hochgeschwindigkeitsbewegungen in komplexen Umgebungen zu erreichen. Das Framework zeigt nicht nur eine hohe Effizienz bei der Kollisionsvermeidung, sondern erreicht auch eine beispiellose Geschwindigkeit von 3,1 Millisekunden. Diese Innovation bringt neue Fortschritte auf dem Gebiet der Beinroboter.
Im Bereich der Hochgeschwindigkeitsroboterbewegung war es schon immer eine große Herausforderung, Geschwindigkeit und Sicherheit gleichzeitig aufrechtzuerhalten. Doch einem Forschungsteam der Carnegie Mellon University (CMU) und der ETH Zürich (ETH) ist kürzlich ein Durchbruch gelungen. Der von ihnen entwickelte neue Vierbeiner-Roboteralgorithmus kann sich nicht nur schnell in komplexen Umgebungen bewegen, sondern auch Hindernissen geschickt ausweichen und so das Ziel „Agilität und Sicherheit“ wirklich erreichen. Die Innovation dieses Algorithmus liegt in seiner Fähigkeit, die Umgebung schnell zu identifizieren und zu analysieren und auf der Grundlage von Echtzeitdaten intelligente Entscheidungen zu treffen. Durch den Einsatz fortschrittlicher Sensoren und leistungsstarker Rechenleistung ist der Roboter in der Lage, Hindernisse in seiner Umgebung genau zu erkennen und ihnen auszuweichen, indem er seinen Gang und seine Flugbahn anpasst. Die erfolgreiche Anwendung dieser Technologie wird die Entwicklung von Hochgeschwindigkeitsrobotern erheblich vorantreiben.

Papieradresse: https://arxiv.org/pdf/2401.17583.pdf In verschiedenen Szenarien haben alle erstaunliche Fähigkeiten zur Vermeidung von Hindernissen bei hoher Geschwindigkeit bewiesen:
Enge Korridore voller Hindernisse:
 Unordentliche Innenszenen:
Unordentliche Innenszenen:
 Ob Gras oder draußen, statische oder dynamische Hindernisse, der Roboter Hund kann gelassen damit umgehen:
Ob Gras oder draußen, statische oder dynamische Hindernisse, der Roboter Hund kann gelassen damit umgehen:
 Bei der Begegnung mit einem Kinderwagen weicht der Roboterhund geschickt aus:
Bei der Begegnung mit einem Kinderwagen weicht der Roboterhund geschickt aus:
 Auch Warnschilder, Kisten und Stühle sind kein Problem:
Auch Warnschilder, Kisten und Stühle sind kein Problem:
 Er kommt auch problemlos damit zurecht mit dem plötzlichen Auftauchen von Matten und menschlichen Füßen Bypass:
Er kommt auch problemlos damit zurecht mit dem plötzlichen Auftauchen von Matten und menschlichen Füßen Bypass:
 Der Roboterhund kann sogar Adler spielen und Hühner fangen:
Der Roboterhund kann sogar Adler spielen und Hühner fangen:

RL+ Lernmodellfreier Reach-Avoid-Wert
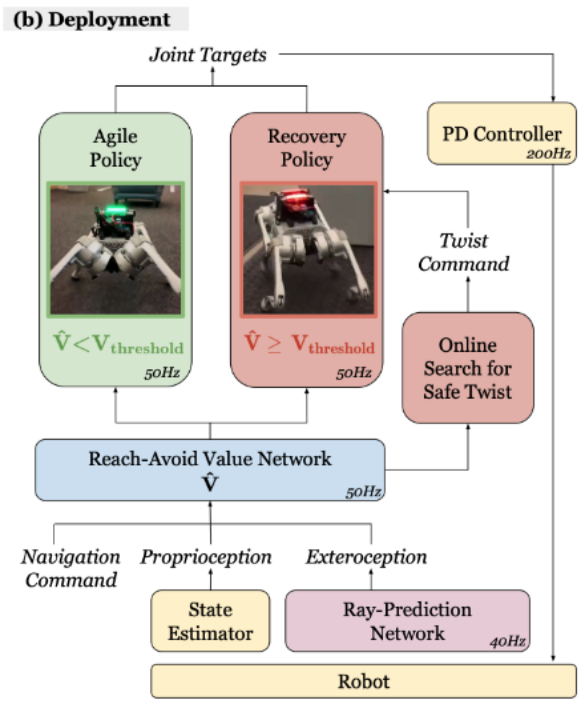
ABS verwendet eine duale Richtlinieneinstellung, einschließlich einer „Agile Policy“ und einer „Recovery Policy“. Agilitätsstrategien ermöglichen es dem Roboter, sich schnell durch Hindernisse zu bewegen, während Wiederherstellungsstrategien eingreifen, um die Sicherheit des Roboters zu gewährleisten, sobald die Reach-Avoid-Value-Schätzung potenzielle Gefahren erkennt (z. B. das plötzliche Auftauchen eines Kinderwagens).

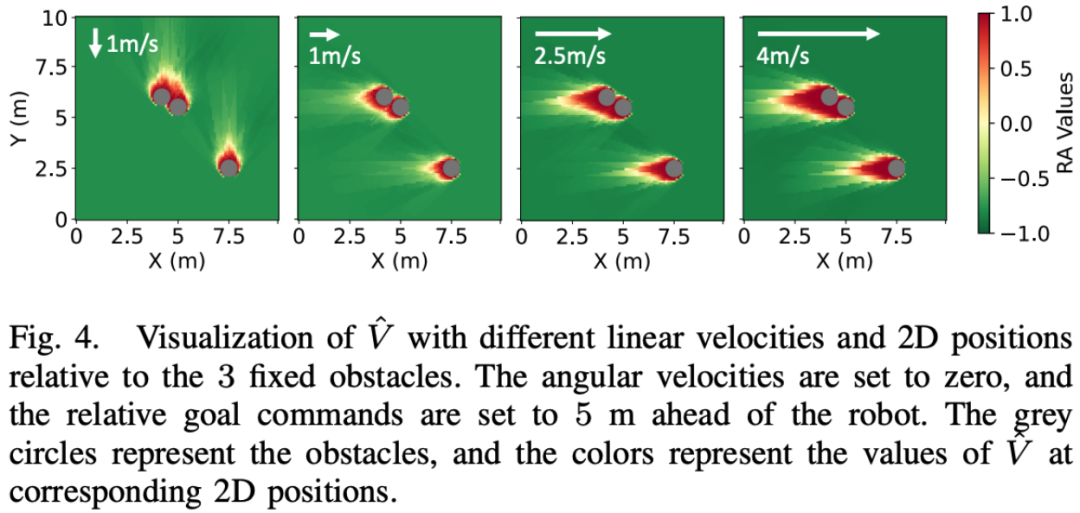
Die Abbildung unten zeigt den erlernten RA-Wert (Reach Defense) für einen bestimmten Satz von Hindernissen. Wenn sich die Robotergeschwindigkeit ändert, ändert sich die Verteilungslandschaft der RA-Werte entsprechend. Das Vorzeichen des RA-Wertes ist ein sinnvoller Hinweis auf die Sicherheit der agilen Strategie. Mit anderen Worten: Diese Grafik zeigt das Sicherheitsrisiko des Roboters, wenn er bestimmten Hindernissen mit unterschiedlichen Geschwindigkeiten durch unterschiedliche RA-Werte gegenübersteht. Die hohen und niedrigen Änderungen des RA-Werts spiegeln die Sicherheitsrisiken wider, denen der Roboter bei der Ausführung agiler Strategien in verschiedenen Zuständen ausgesetzt sein kann.
Die Innovation der Wiederherstellungsstrategie besteht darin, dass sie es dem vierbeinigen Roboter ermöglicht, als Backup schnell lineare Geschwindigkeits- und Winkelgeschwindigkeitsanweisungen zu verfolgen Erhaltungsstrategien. Im Gegensatz zur agilen Strategie konzentriert sich der Beobachtungsraum der Wiederherstellungsstrategie auf die Verfolgung von Lineargeschwindigkeits- und Winkelgeschwindigkeitsbefehlen und erfordert keine externen sensorischen Informationen. Die Missionsbelohnungen der Wiederherstellungsstrategie konzentrieren sich auf die Verfolgung der linearen Geschwindigkeit, die Verfolgung der Winkelgeschwindigkeit, das Überleben und die Aufrechterhaltung der Körperhaltung, um einen reibungslosen Wechsel zurück zur Beweglichkeitsstrategie zu ermöglichen. Das Training dieser Strategie wird ebenfalls in einer Simulationsumgebung durchgeführt, jedoch mit spezifischer Domänen-Randomisierung und Kurseinstellungen, um sich besser an die Bedingungen anzupassen, die die Wiederherstellungsstrategie auslösen können. Dieser Ansatz bietet vierbeinigen Robotern die Möglichkeit, schnell auf mögliche Ausfälle bei Hochgeschwindigkeitsbewegungen zu reagieren.
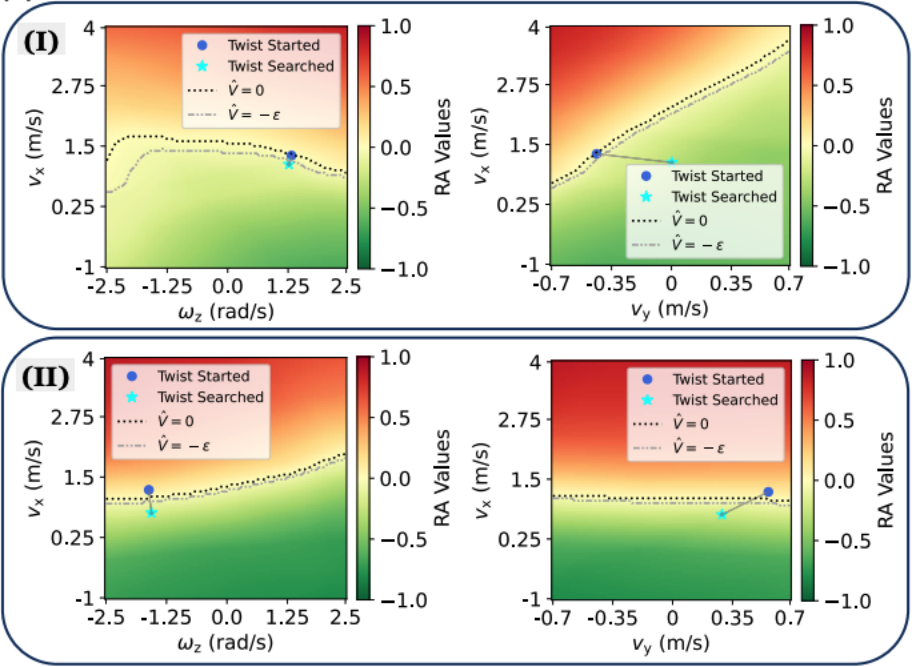
Die folgende Abbildung zeigt eine visuelle Darstellung der RA-Wertelandschaft (Rare Defense), wenn die Wiederherstellungsstrategie in zwei spezifischen Situationen (I und II) ausgelöst wird. Diese Visualisierungen werden in den Ebenen vx (Geschwindigkeit entlang der x-Achse) versus ωz (Winkelgeschwindigkeit um die z-Achse) und vx versus vy (Geschwindigkeit entlang der y-Achse) durchgeführt. Die Abbildung zeigt den anfänglichen Rotationszustand vor der Suche (d. h. den aktuellen Rotationszustand der Roboterbasis) und die durch die Suche erhaltenen Befehle. Vereinfacht ausgedrückt zeigen diese Diagramme die optimalen Bewegungsanweisungen, die durch die Wiederherstellungsstrategiesuche unter bestimmten Bedingungen erhalten wurden, und wie sich diese Anweisungen auf den RA-Wert auswirken und somit die Sicherheit des Roboters in verschiedenen Bewegungszuständen widerspiegeln.


Das obige ist der detaillierte Inhalt vonCMUÐ gelingt ein Durchbruch: Der Roboterhund verfügt über einen vollen Beweglichkeitswert und kann Hindernisse mit extrem hoher Geschwindigkeit überwinden, wodurch Geschwindigkeit und Sicherheit kombiniert werden!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die Industriekette der künstlichen Intelligenz umfasst
- Stärken Sie die Modebranche mit Technologie und unterstützen Sie den Bezirk Futian beim Aufbau eines „Bay Area Fashion Headquarters Center'.
- Was ist die nächste Grenze in der künstlichen Intelligenz und Robotik?
- Tesla plant die Errichtung einer Elektrofahrzeugfabrik in Indien, um die indische Elektrofahrzeugindustrie anzukurbeln
- Web3 und KI konzentrieren sich auf Veränderung und Beständigkeit und gestalten den Gipfeldialog der Filmindustrie neu