
Heim >System-Tutorial >LINUX >Erkundung des Kontextwechsels auf Linux-CPUs
Erkundung des Kontextwechsels auf Linux-CPUs

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-02-05 13:06:10721Durchsuche
Wie wir alle wissen, ist Linux ein Betriebssystem, das Multitasking unterstützt. Die Anzahl der Aufgaben, die es gleichzeitig ausführen kann, übersteigt die Anzahl der CPUs bei weitem. Natürlich werden diese Aufgaben nicht tatsächlich gleichzeitig ausgeführt (für eine einzelne CPU), sondern weil das System die CPU nacheinander für einen kurzen Zeitraum diesen Aufgaben zuweist, entsteht die Illusion, dass mehrere Aufgaben gleichzeitig ausgeführt werden .
CPU-Kontext
Bevor jede Aufgabe ausgeführt wird, muss die CPU wissen, wo sie diese Aufgabe laden und starten soll. Das bedeutet, dass das System die Register und den Programmzähler der CPU im Voraus einstellen muss.
CPU-Register sind kleine, aber sehr schnelle Speicher, die in die CPU integriert sind. Der Programmzähler wird verwendet, um den Speicherort des aktuell von der CPU ausgeführten Befehls oder den Speicherort des nächsten auszuführenden Befehls zu speichern.
Beide sind die notwendige Umgebung für die CPU, bevor sie eine Aufgabe ausführen kann, daher wird sie „CPU-Kontext“ genannt. Bitte beachten Sie das Bild unten:
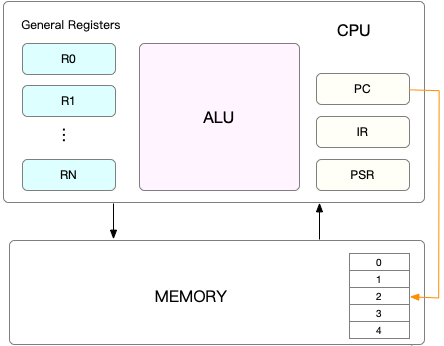
Da Sie nun wissen, was ein CPU-Kontext ist, wird es Ihnen meiner Meinung nach leicht fallen, die CPU-Kontextumschaltung zu verstehen. „CPU-Kontextwechsel“ bezieht sich auf das Speichern des CPU-Kontexts (CPU-Register und Programmzähler) der vorherigen Aufgabe, das anschließende Laden des Kontexts der neuen Aufgabe in diese Register und den Programmzähler und schließlich das Springen zum Programmzähler.
Diese gespeicherten Kontexte werden im Systemkernel gespeichert und wieder geladen, wenn die Aufgabenausführung neu geplant wird. Dadurch wird sichergestellt, dass der ursprüngliche Status der Aufgabe nicht beeinträchtigt wird und die Aufgabe scheinbar kontinuierlich ausgeführt wird.
Arten der CPU-Kontextumschaltung
Man könnte sagen, dass der CPU-Kontextwechsel nichts anderes ist als die Aktualisierung von CPU-Registern und Programmzählerwerten, und diese Register sind darauf ausgelegt, Aufgaben schnell auszuführen. Warum wirkt sich das also auf die CPU-Leistung aus?
Haben Sie vor der Beantwortung dieser Frage jemals darüber nachgedacht, was diese „Aufgaben“ sind? Man könnte sagen, dass eine Aufgabe ein Prozess oder ein Thread ist. Ja, Prozesse und Threads sind die häufigsten Aufgaben, aber es gibt darüber hinaus noch andere Arten von Aufgaben.
Nicht vergessenHardware-Interrupt ist ebenfalls eine häufige Aufgabe. Das Hardware-Triggersignal führt dazu, dass der Interrupt-Handler aufgerufen wird.
Daher gibt es mindestens drei verschiedene Arten von CPU-Kontextwechseln:
- Prozesskontextwechsel
- Thread-Kontextwechsel
- Kontextwechsel unterbrechen
Lassen Sie uns einen nach dem anderen ansehen.
Prozesskontextwechsel
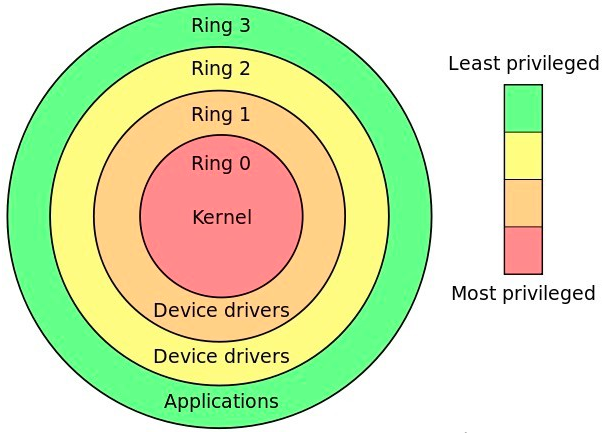
Linux unterteilt den laufenden Bereich des Prozesses entsprechend der Berechtigungsebene in Kernelbereich und Benutzerbereich, was der CPU-Berechtigungsebene von Ring 0 和 Ring 3 in der folgenden Abbildung entspricht.
-
Kernelraum(
Ring 0) verfügt über die höchsten Berechtigungen und kann direkt auf alle Ressourcen zugreifen -
Benutzerbereich (
Ring 3) kann nur auf eingeschränkte Ressourcen zugreifen und nicht direkt auf Hardwaregeräte wie Speicher zugreifen. Es muss über Systemaufrufeim Kernel „eingeschlossen“ werden, um auf diese privilegierten Ressourcen zugreifen zu können.
 Benutzerbereich
Benutzerbereich ausgeführt wird, wird er als Benutzerstatus des Prozesses bezeichnet. Wenn er in den Kernelbereich fällt, wird er als Kernelstatus des Prozesses bezeichnet. Die Konvertierung vom Benutzermodus in den Kernelmodus muss über einen Systemaufruf abgeschlossen werden. Wenn wir beispielsweise den Inhalt einer Datei anzeigen, benötigen wir den folgenden Systemaufruf: Wird also während des oben genannten Systemaufrufs ein CPU-Kontextwechsel stattfinden? Natürlich. Dazu muss zunächst der Speicherort der ursprünglichen Benutzermodusanweisung im CPU-Register gespeichert werden. Um Kernel-Modus-Code auszuführen, müssen als Nächstes die CPU-Register auf den neuen Speicherort der Kernel-Modus-Anweisungen aktualisiert werden. Springen Sie abschließend zum Kernel-Status, um die Kernel-Aufgabe auszuführen. Nachdem der Systemaufruf beendet ist, müssen die CPU-Register den ursprünglich gespeicherten Benutzerstatus wiederherstellenund dann in den Benutzerbereich wechseln, um den Prozess fortzusetzen. Während eines Systemaufrufs gibt es also tatsächlich zwei CPU-Kontextwechsel. Aber es sollte darauf hingewiesen werden, dass der Systemaufrufprozess weder einen Prozesswechsel noch einen Wechsel von Systemressourcen wie dem virtuellen Speicher beinhaltet. Dies unterscheidet sich von dem, was wir normalerweise als „Prozesskontextwechsel“ bezeichnen. Unter Prozesskontextwechsel versteht man den Wechsel von einem Prozess zu einem anderen, während während des Systemaufrufs immer derselbe Prozess ausgeführt wird Der Systemaufrufprozess wird oft als Berechtigungsmoduswechsel und nicht als Kontextwechsel bezeichnet. Tatsächlich ist jedoch während des Systemaufrufprozesses auch ein Wechsel des CPU-Kontexts unvermeidlich. Was ist also der Unterschied zwischen Prozesskontextwechsel und Systemaufrufen? Erstens werden Prozesse vom Kernel verwaltet und Prozesswechsel können nur im Kernelmodus erfolgen. Daher umfasst der Prozesskontext nicht nur Benutzerraumressourcen wie „virtueller Speicher“, „Stapel“ und „globale Variablen“, sondern auch Kernelraumzustände wie „Kernelstapel“ und „Register“.
Der Prozesskontextwechsel hat also einen Schritt mehr als der Systemaufruf:
Bevor Sie den Kernel-Status und die CPU-Register des aktuellen Prozesses speichern, müssen Sie den virtuellen Speicher, den Stapel usw. des Prozesses speichern und den Kernel-Status des nächsten Prozesses laden.
Laut Tsunas Testbericht benötigt jeder Kontextwechsel mehrere zehn Nanosekunden bis Mikrosekunden CPU-Zeit. Diese Zeit ist beträchtlich, insbesondere bei einer großen Anzahl von Prozesskontextwechseln, was leicht dazu führen kann, dass die CPU viel Zeit damit verbringt, Ressourcen wie Register, Kernel-Stacks und virtuellen Speicher zu speichern und wiederherzustellen. Genau darüber haben wir im letzten Artikel gesprochen, ein wesentlicher Faktor, der dazu führt, dass die durchschnittliche Auslastung steigt.
Wann wird der Prozess so geplant/umgeschaltet, dass er auf der CPU ausgeführt wird? Tatsächlich gibt es viele Szenarien, ich möchte sie im Folgenden für Sie zusammenfassen: sind, während Prozesse die Grundeinheit der
Wenn ein Prozess nur einen Thread hat, kann davon ausgegangen werden, dass ein Prozess einem Thread entspricht
Wenn ein Prozess über mehrere Threads verfügt, teilen sich diese Threads dieselben Ressourcen, z. B. virtuellen Speicher und globale Variablen.
. Beim Unterbrechen anderer Prozesse muss der aktuelle Zustand des Prozesses gespeichert werden, damit der Prozess nach der Unterbrechung immer noch aus dem ursprünglichen Zustand wiederhergestellt werden kann.
Im Gegensatz zum Prozesskontext bezieht sich die Unterbrechungskontextumschaltung nicht auf den Benutzerstatus des Prozesses. Selbst wenn der Interrupt-Prozess den Prozess im Benutzermodus unterbricht, besteht daher keine Notwendigkeit, Ressourcen im Benutzermodus wie virtuellen Speicher und globale Variablen des Prozesses zu speichern und wiederherzustellen. Darüber hinaus verbraucht der Interrupt-Kontextwechsel ebenso wie der Prozesskontextwechsel CPU. Übermäßige Umschaltzeiten verbrauchen viele CPU-Ressourcen und beeinträchtigen sogar die Gesamtleistung des Systems erheblich. Wenn Sie also feststellen, dass zu viele Interrupts vorhanden sind, müssen Sie darauf achten, ob dies zu ernsthaften Leistungsproblemen für Ihr System führt.
Zusammenfassend lässt sich sagen, dass Sie unabhängig davon, welches Szenario zu einem Kontextwechsel führt, Folgendes wissen sollten: CPU-Kontextwechsel ist eine der Kernfunktionen zur Gewährleistung des normalen Betriebs des Linux-Systems und erfordert im Allgemeinen keine besondere Aufmerksamkeit.
open(): Datei öffnen read(): Lesen Sie den Inhalt der Dateiwrite(): Schreiben Sie den Inhalt der Datei in die Ausgabedatei (einschließlich Standardausgabe) close(): Datei schließen
Prozesskontextwechsel vs. Systemaufruf
Aufgabenplanungsleep
Wenn ein Prozess mit einer höheren Priorität ausgeführt wird, wird der aktuelle Prozess durch den Prozess mit hoher Priorität angehalten, um die Ausführung des Prozesses mit hoher Priorität sicherzustellen.
sind.
Um es ganz klar auszudrücken: Das sogenannte Task-Scheduling im Kernel plant tatsächlich Threads; und Prozesse stellen nur Ressourcen wie virtuellen Speicher und globale Variablen für Threads bereit. Für Threads und Prozesse können wir es also so verstehen:
Offensichtlich verbraucht der Thread-Wechsel innerhalb desselben Prozesses weniger Ressourcen als der Wechsel mehrerer Prozesse. Dies ist auch der Vorteil von Multithreading gegenüber Multiprozess.
InterruptUm schnell auf Ereignisse reagieren zu können, unterbrechen Hardware-Interrupts den normalen Planungs- und Ausführungsprozess und rufen dann den Interrupt-Handler auf.
Allerdings verbraucht ein übermäßiger Kontextwechsel CPU-Zeit zum Speichern und Wiederherstellen von Daten wie Registern, Kernel-Stacks, virtuellem Speicher usw., wodurch die tatsächliche Laufzeit des Prozesses verkürzt und die Gesamtsystemleistung erheblich verringert wird.
Das obige ist der detaillierte Inhalt vonErkundung des Kontextwechsels auf Linux-CPUs. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!