
Heim >Technologie-Peripheriegeräte >KI >Ein 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor
Ein 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor

- PHPznach vorne
- 2024-02-01 14:24:261380Durchsuche
HuggingFace ist die beliebteste Open-Source-Community für maschinelles Lernen mit 300.000 verschiedenen Modellen für maschinelles Lernen und 100.000 verfügbaren Anwendungen.
Wenn diese 300.000 Modelle auf HuggingFace frei kombiniert werden könnten, um gemeinsam neue Lernaufgaben zu erledigen, wie würde es aussehen?
Tatsächlich schlug Professor Zhou Zhihua von der Universität Nanjing im Jahr 2016, als HuggingFace herauskam, das Konzept der „Learnware“ vor und zeichnete einen solchen Entwurf.
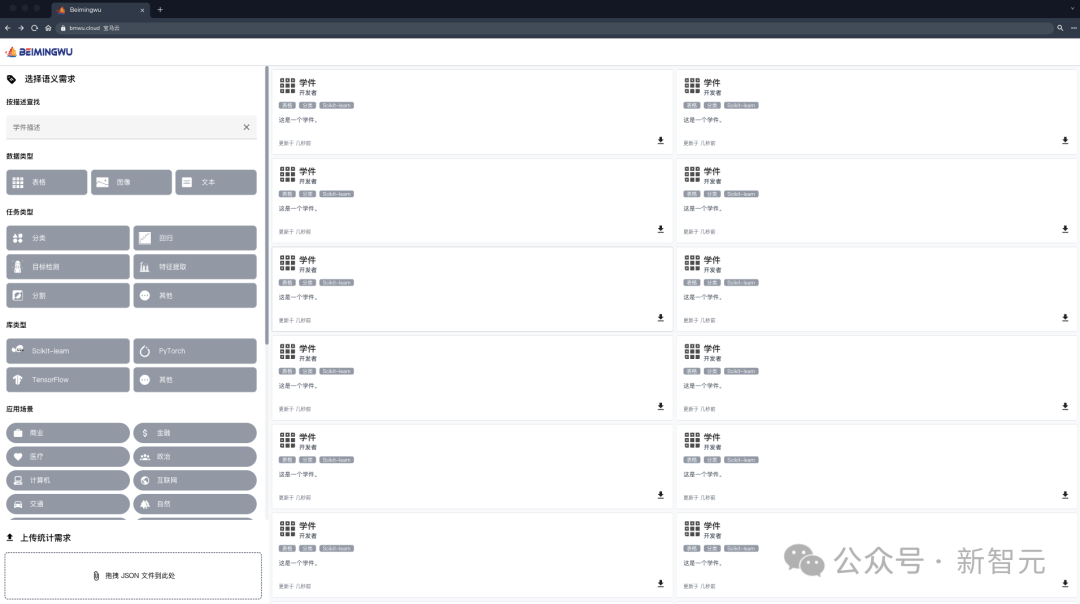
Kürzlich hat das Team von Professor Zhou Zhihua von der Universität Nanjing eine solche Plattform ins Leben gerufen – Beimingwu.
Adresse: https://bmwu.cloud/
Beimingwu bietet Forschern und Benutzern nicht nur die Möglichkeit, ihre eigenen Modelle hochzuladen, sondern führt auch Modellabgleich und Kollaborationsfusion entsprechend den Benutzeranforderungen durch, um das Lernen effizient abzuwickeln Aufgaben .

Papieradresse: https://arxiv.org/abs/2401.14427
Beimingwu Systemlager: https://www.gitlink.org.cn/beimingwu/beimingwu
Wissenschaftliche Forschung Toolkit-Lager: https://www.gitlink.org.cn/beimingwu/learnware
Das größte Merkmal dieser Plattform ist die Einführung des Learnware-Systems, wodurch ein Durchbruch bei der Realisierung von Modellen basierend auf Benutzerbedürfnissen erzielt wird. Adaptives Matching und Möglichkeiten zur Zusammenarbeit.
Learningware besteht aus einem Modell für maschinelles Lernen und einer Spezifikation, die das Modell beschreibt, also „Learningware = Modell + Spezifikation“.
Die Spezifikation der Lernsoftware besteht aus zwei Teilen: „semantische Spezifikation“ und „statistische Spezifikation“:
- semantische Spezifikation beschreibt die Art und Funktion des Modells durch Text;
- statistische Spezifikation nutzt verschiedene maschinelles Lernen Technologien, die die im Modell enthaltenen statistischen Informationen darstellen.
Die Spezifikation der Lernware beschreibt die Fähigkeiten des Modells, sodass das Modell in Zukunft vollständig erkannt und wiederverwendet werden kann, ohne dass der Benutzer im Voraus etwas über die Lernware weiß, um die Benutzeranforderungen zu erfüllen.
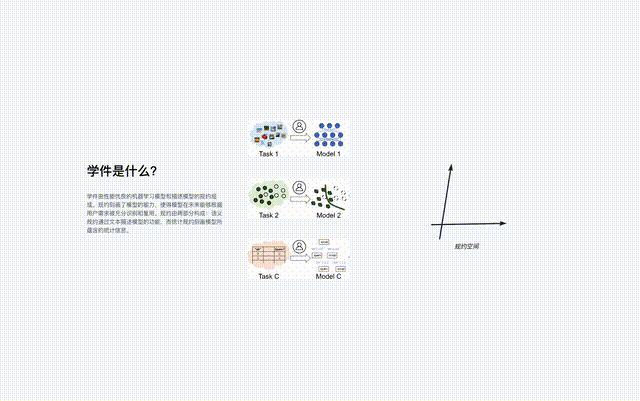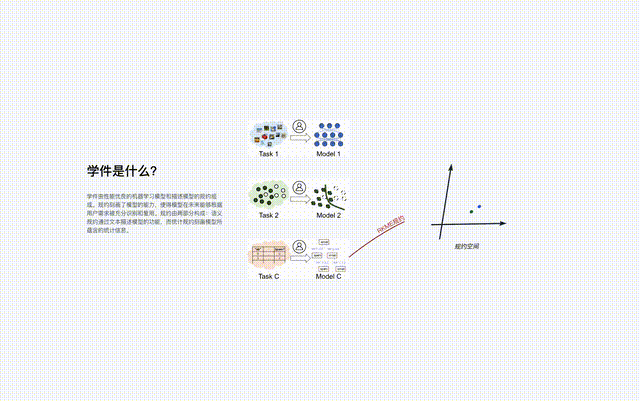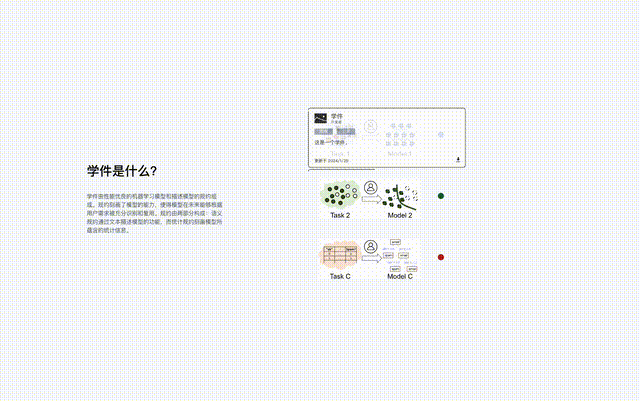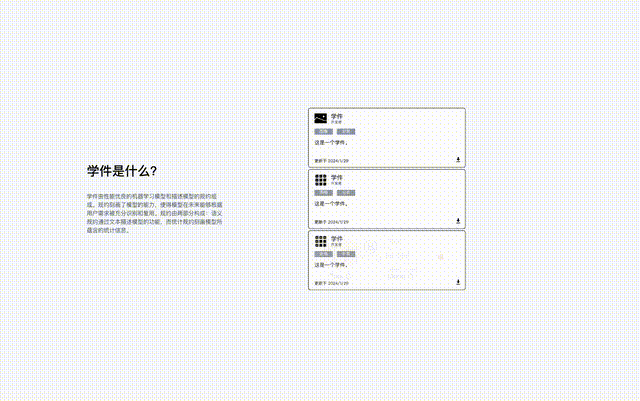
Das Protokoll ist die Kernkomponente des Learningware-Basissystems, das alle Learningware-Prozesse im System verbindet, einschließlich Hochladen, Organisation, Suche, Bereitstellung und Wiederverwendung von Learningware.
So wie Yanziwu in „Dragon“ aus vielen kleinen Inseln besteht, sind auch die Vorschriften in Beimingwu wie kleine Inseln.
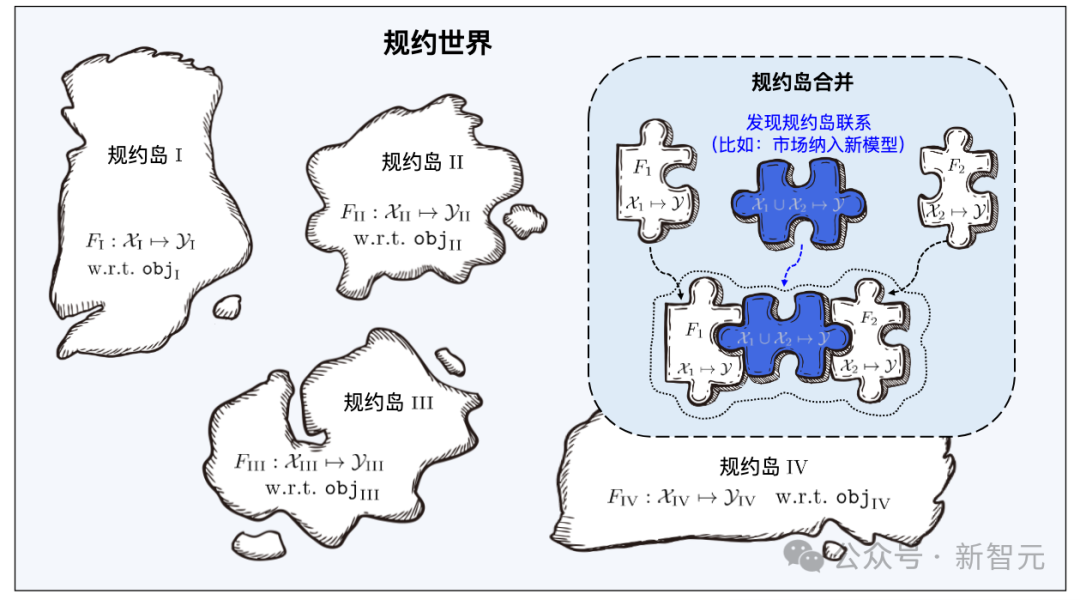
Learningware aus verschiedenen Feature-/Markerräumen bilden zahlreiche Protokollinseln, und alle Protokollinseln zusammen bilden die Protokollwelt im Learningware-Basissystem. Wenn in der Protokollwelt die Verbindungen zwischen verschiedenen Inseln entdeckt und hergestellt werden können, können die entsprechenden Protokollinseln zusammengeführt werden.
Unter dem Learningware-Paradigma können Entwickler auf der ganzen Welt Modelle für das Learningware-Basissystem freigeben. Das System hilft Benutzern, maschinelle Lernaufgaben effizient zu lösen, indem es Learningware effektiv durchsucht und wiederverwendet, ohne maschinelles Lernen von Grund auf neu erstellen zu müssen.
Beimingwu ist die erste systematische Open-Source-Implementierung akademischer Software und bietet eine vorläufige wissenschaftliche Forschungsplattform für akademische softwarebezogene Forschung.
Entwickler, die bereit sind, Modelle zu teilen, können das Learning Warehouse bei der Generierung von Spezifikationen zur Bildung von Lernsoftware unterstützen und diese im Learning Warehouse speichern. In diesem Prozess müssen Entwickler ihre Ausbildung nicht offenlegen Daten an das Learning Warehouse.
Zukünftige Benutzer können ihre Anforderungen an das Learning Warehouse übermitteln und mit Hilfe des Learning Warehouse nach wiederverwendeten Lernmaterialien suchen, um ihre maschinellen Lernaufgaben abzuschließen, und Benutzer müssen ihre eigenen Daten nicht an das Learning Warehouse weitergeben.
Und in Zukunft, wenn das Lerndock über Millionen von Lernstücken verfügt, wird es wahrscheinlich zu „emergentem“ Verhalten kommen: Aufgaben des maschinellen Lernens, für die es in der Vergangenheit keine speziell entwickelten Modelle gab, können durch die Wiederverwendung mehrerer vorhandener Lernstücke wiederverwendet werden. Und lösen.
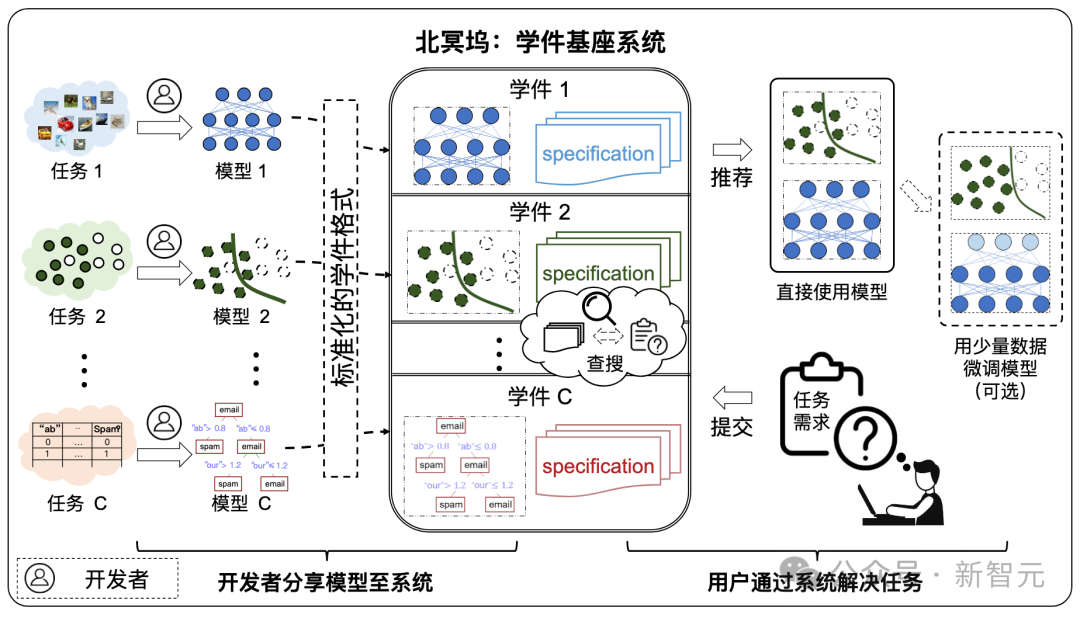
Learningware-Basissystem
Maschinelles Lernen hat in vielen Bereichen große Erfolge erzielt, ist jedoch immer noch mit vielen Problemen konfrontiert, z. B. dem Bedarf an großen Mengen an Trainingsdaten und hervorragenden Trainingsfähigkeiten, der Schwierigkeit des kontinuierlichen Lernens und katastrophalen Folgen Vergessen. Risiken und Verlust von Datenschutz/Eigentum usw.
Obwohl es für jedes der oben genannten Probleme entsprechende Untersuchungen gibt, kann die Lösung eines der Probleme dazu führen, dass andere Probleme schwerwiegender werden, da die Probleme miteinander verknüpft sind.
Das Lernbasissystem hofft, durch einen Gesamtrahmen viele der oben genannten Probleme gleichzeitig zu lösen:
- Mangel an Trainingsdaten/Fähigkeiten: Auch für normale Benutzer, denen es an Trainingsfähigkeiten mangelt oder die nur über geringe Trainingsfähigkeiten verfügen Daten können sie leistungsstarke Modelle für maschinelles Lernen erhalten, da Benutzer leistungsstarke Lernware aus einem Lernware-Basissystem übernehmen und diese weiter optimieren oder verbessern können, anstatt das Modell selbst von Grund auf zu erstellen.
- Kontinuierliches Lernen: Da kontinuierlich Lernsoftware mit hervorragender Leistung für verschiedene Aufgaben eingereicht wird, wird das Wissen im Basissystem der Lernsoftware weiter bereichert, wodurch auf natürliche Weise kontinuierliches und lebenslanges Lernen realisiert wird.
- Katastrophales Vergessen: Sobald ein Lernstück empfangen wurde, wird es immer im Lernstück-Basissystem untergebracht, es sei denn, alle Aspekte seiner Funktionen können durch andere Lernstücke ersetzt werden. Daher bleibt altes Wissen im Lernbasissystem immer erhalten und wird nie vergessen.
- Datenschutz/Eigentum: Entwickler reichen nur Modelle ein, ohne private Daten weiterzugeben, sodass Datenschutz/Eigentum gut geschützt werden können. Obwohl die Möglichkeit eines Reverse Engineering des Modells nicht vollständig ausgeschlossen werden kann, ist das Risiko eines Datenschutzverlusts beim Lernbasissystem im Vergleich zu vielen anderen Datenschutzsystemen sehr gering.
Die Zusammensetzung des Learningware-Basissystems
Wie in der folgenden Abbildung dargestellt, ist der Systemworkflow in die folgenden zwei Phasen unterteilt:
- Übermittlungsphase: Entwickler senden spontan verschiedene Learningware an ein Basissystem für Lernstücke, die Qualitätsprüfungen und weitere Organisation durchführen.
- Bereitstellungsphase: Wenn der Benutzer Aufgabenanforderungen übermittelt, empfiehlt das Learningware-Basissystem Lernware, die gemäß der Learningware-Spezifikation für die Aufgabe des Benutzers hilfreich ist, und leitet den Benutzer bei der Bereitstellung und Wiederverwendung an.
Protokollwelt
Protokoll ist die Kernkomponente des Learningware-Basissystems, das alle Learningware-Prozesse im System verbindet, einschließlich Hochladen, Organisieren, Suchen, Bereitstellen und Wiederverwenden von Learningware.
Learningware aus verschiedenen Feature-/Markerräumen bilden zahlreiche Protokollinseln, und alle Protokollinseln zusammen bilden die Protokollwelt im Learningware-Basissystem. Wenn in der Protokollwelt die Verbindungen zwischen verschiedenen Inseln entdeckt und hergestellt werden können, können die entsprechenden Protokollinseln zusammengeführt werden.
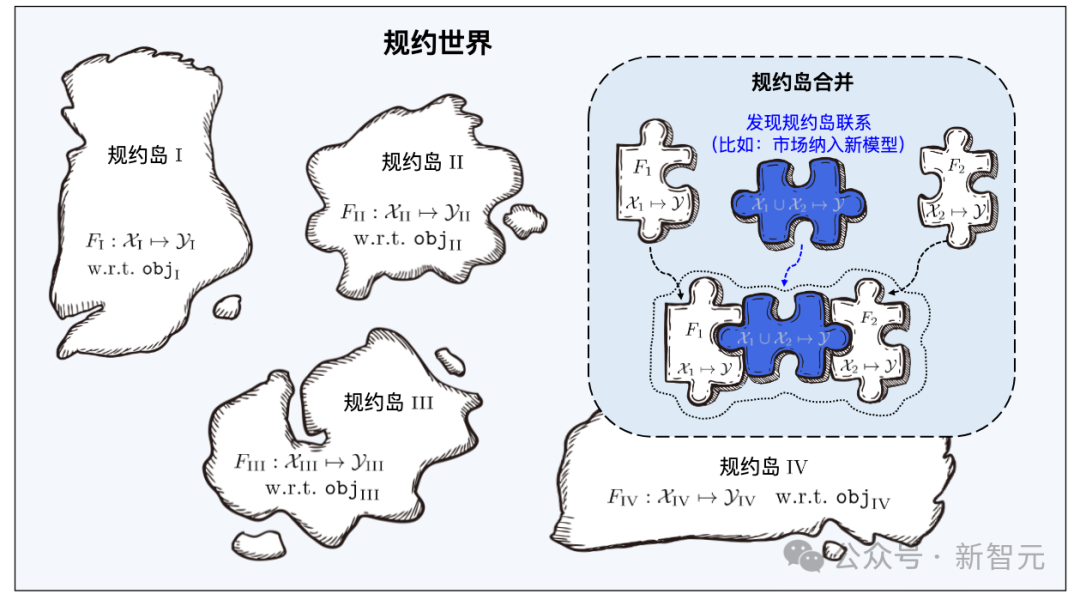
Bei der Suche lokalisiert das Lernbasissystem zunächst die spezifische Protokollinsel anhand der semantischen Spezifikationen in den Benutzeranforderungen und identifiziert dann die Lernmaterialien auf der Protokollinsel anhand der statistischen Spezifikationen in den Benutzeranforderungen genau. Durch die Zusammenführung verschiedener Protokollinseln kann die entsprechende Lernsoftware für Aufgaben in unterschiedlichen Feature-/Marker-Räumen eingesetzt werden, also für Aufgaben über ihren ursprünglichen Zweck hinaus wiederverwendet werden.
Das Learningware-Paradigma schafft einen einheitlichen Spezifikationsraum, indem es die Fähigkeiten der von der Community gemeinsam genutzten Modelle für maschinelles Lernen voll ausnutzt und maschinelle Lernaufgaben für neue Benutzer auf einheitliche Weise effizient löst. Mit zunehmender Anzahl von Lernstücken wird durch eine effektive Organisation der Lernstückstruktur die Gesamtfähigkeit des Lernstück-Basissystems zur Lösung von Aufgaben erheblich verbessert.
Die Architektur von Beimingwu
Wie in der folgenden Abbildung dargestellt, umfasst die Systemarchitektur von Beimingwu vier Ebenen, von der Learningware-Speicherschicht bis zur Benutzerinteraktionsschicht. Es ist das erste Mal, dass Learningware systematisch implementiert wird das Bottom-up-Paradigma. Die spezifischen Funktionen der vier Ebenen sind wie folgt:
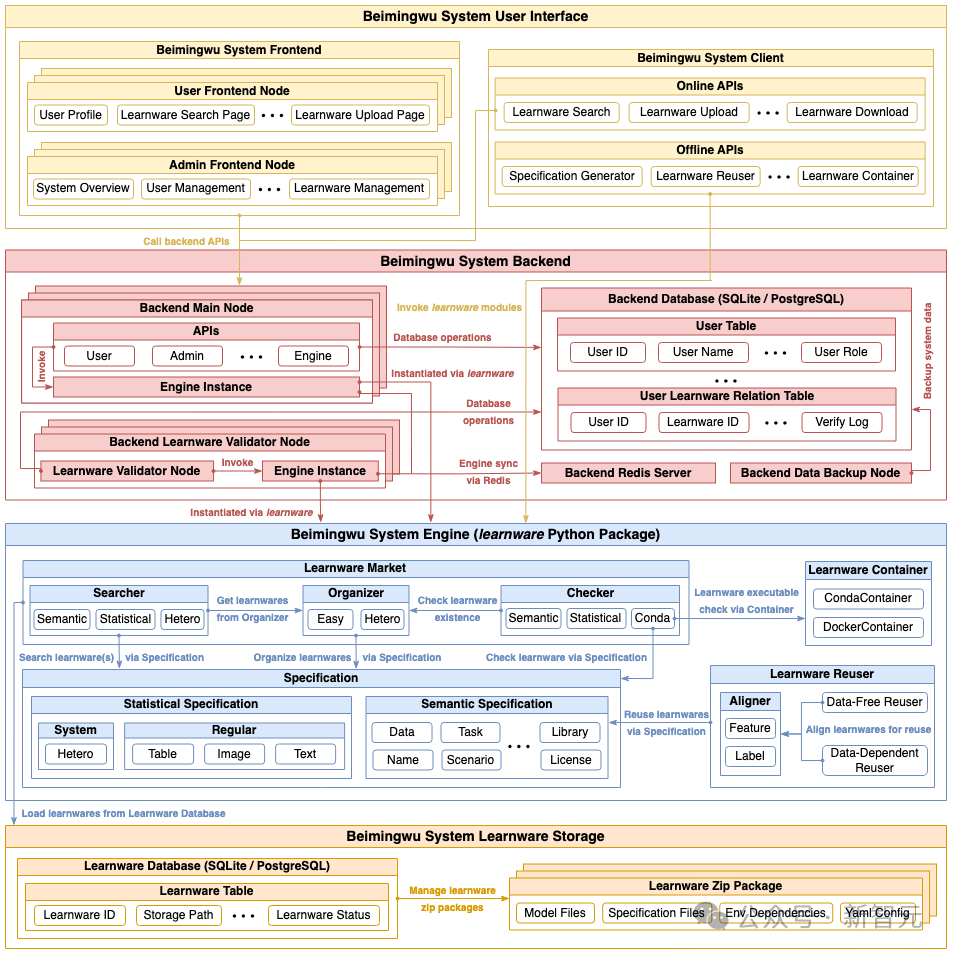
- Learningware-Speicherschicht: verwaltet im ZIP-Paketformat gespeicherte Lernware und bietet Zugriff auf relevante Informationen über die Learningware-Datenbank.
- System-Engine-Schicht: umfasst alle Prozesse im Learningware-Paradigma, einschließlich Hochladen, Erkennen, Organisieren, Suchen und Bereitstellen von Lernware und wiederverwenden und unabhängig vom Back-End und Front-End in Form eines Learnware-Python-Pakets ausführen, das eine umfangreiche Algorithmusschnittstelle für Learnware-bezogene Aufgaben und wissenschaftliche Forschungserkundung bietet.
- System-Back-End-Schicht: Implementierung Mit dem Durch die Bereitstellung von Beimingwu in Industriequalität werden stabile Online-Systemdienste bereitgestellt und die Benutzerinteraktion zwischen dem Front-End und dem Client durch die Bereitstellung einer umfangreichen Back-End-API unterstützt.
- Benutzerinteraktionsebene: Implementiert webbasiertes Front-End und Befehle zeilenbasiert Der Client bietet umfangreiche und bequeme Möglichkeiten für die Benutzerinteraktion.
Experimentelle Auswertung
In der Arbeit konstruierte das Forschungsteam auch verschiedene Arten grundlegender experimenteller Szenarien, um Benchmark-Algorithmen für die Protokollgenerierung, Lernartefakterkennung und Wiederverwendung in Tabellen, Bildern und Textdaten zu evaluieren.
Tabular Data Experiment
An verschiedenen tabellarischen Datensätzen bewertete das Team zunächst die Leistung der Identifizierung und Wiederverwendung von Learningware aus dem Learningware-System, das über denselben Funktionsraum wie die Benutzeraufgabe verfügt.
Da Formularaufgaben in der Regel aus unterschiedlichen Merkmalsräumen stammen, bewertete das Forschungsteam darüber hinaus auch die Identifizierung und Wiederverwendung von Lernstücken aus unterschiedlichen Merkmalsräumen.
Homogener Fall
Im homogenen Fall fungieren die 53 Filialen im PFS-Datensatz als 53 unabhängige Benutzer.
Jeder Store nutzt seine eigenen Testdaten als Benutzeraufgabendaten und verfolgt einen einheitlichen Feature-Engineering-Ansatz. Diese Benutzer können dann das Basissystem nach homogenen Lernelementen durchsuchen, die denselben Funktionsraum wie ihre Aufgaben haben.
Wenn der Benutzer keine gekennzeichneten Daten hat oder die Menge der gekennzeichneten Daten begrenzt ist, hat das Team verschiedene Benchmark-Algorithmen verglichen und der durchschnittliche Verlust für alle Benutzer ist in der folgenden Abbildung dargestellt. Die linke Tabelle zeigt, dass der datenfreie Ansatz viel besser ist als die zufällige Auswahl und Bereitstellung einer Lernware vom Markt. Das rechte Diagramm zeigt, dass die Identifizierung und Wiederverwendung einzelner oder mehrerer Lernware besser ist als die vom Benutzer trainierte Modelle. Bessere Leistung.
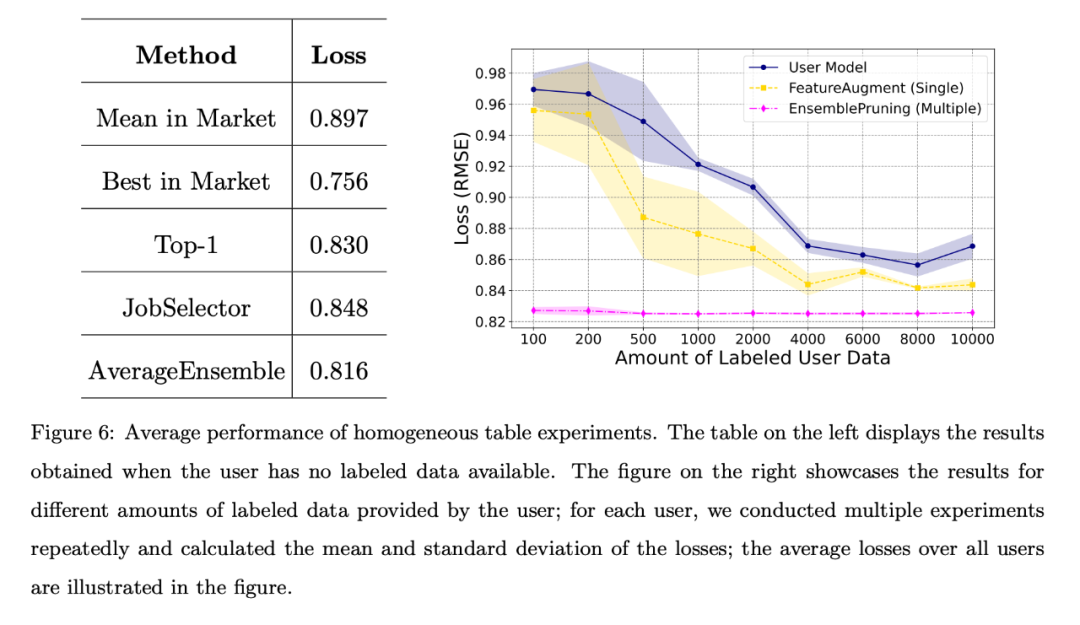
Die linke Tabelle zeigt, dass die datenfreie Methode viel besser ist als die zufällige Auswahl und Bereitstellung eines Lernstücks vom Markt. Die rechte Abbildung zeigt, dass bei begrenzten Trainingsdaten des Benutzers die Identifizierung und Wiederverwendung einzelner bzw Mehrfaches Lernen Die Software bietet eine bessere Leistung als das vom Benutzer trainierte Modell.
Heterogene Fälle
Basierend auf der Ähnlichkeit zwischen Marktsoftware und Benutzeraufgaben können heterogene Fälle weiter in unterschiedliche Feature-Engineering- und unterschiedliche Aufgabenszenarien unterteilt werden.
Verschiedene Feature-Engineering-Szenarien:
Die links in der Abbildung unten gezeigten Ergebnisse zeigen, dass die Lernsoftware im System auch dann eine starke Leistung zeigen kann, wenn dem Benutzer keine Annotationsdaten vorliegen, insbesondere wenn mehrere Lernsoftware vorhanden ist wird die AverageEnsemble-Methode wiederverwendet.
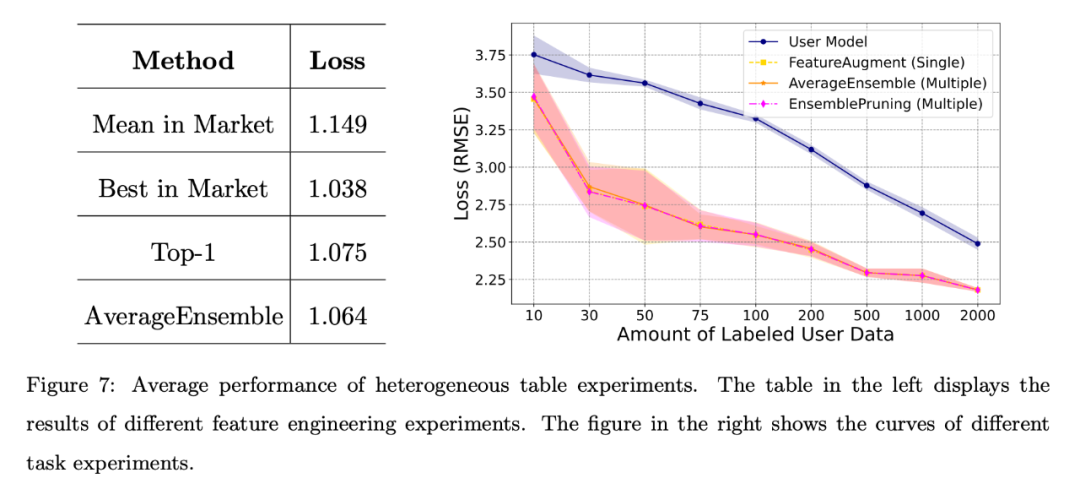
Verschiedene Aufgabenszenarien:
Die rechte Seite der Abbildung oben zeigt die Verlustkurven des Benutzer-Selbsttrainingsmodells und verschiedener Wiederverwendungsmethoden für Lernware.
Offensichtlich ist die experimentelle Überprüfung heterogener Lernkomponenten von Vorteil, wenn die Menge der vom Benutzer annotierten Daten begrenzt ist, und hilft dabei, sich besser an den Funktionsraum des Benutzers anzupassen.
Bild- und Textdatenexperimente
Darüber hinaus führte das Forschungsteam eine grundlegende Bewertung des Systems anhand von Bilddatensätzen durch.
Die folgende Abbildung zeigt, dass die Nutzung eines Lernbasissystems zu einer guten Leistung führen kann, wenn Benutzer mit einem Mangel an annotierten Daten konfrontiert sind oder nur über eine begrenzte Datenmenge (weniger als 2000 Instanzen) verfügen.
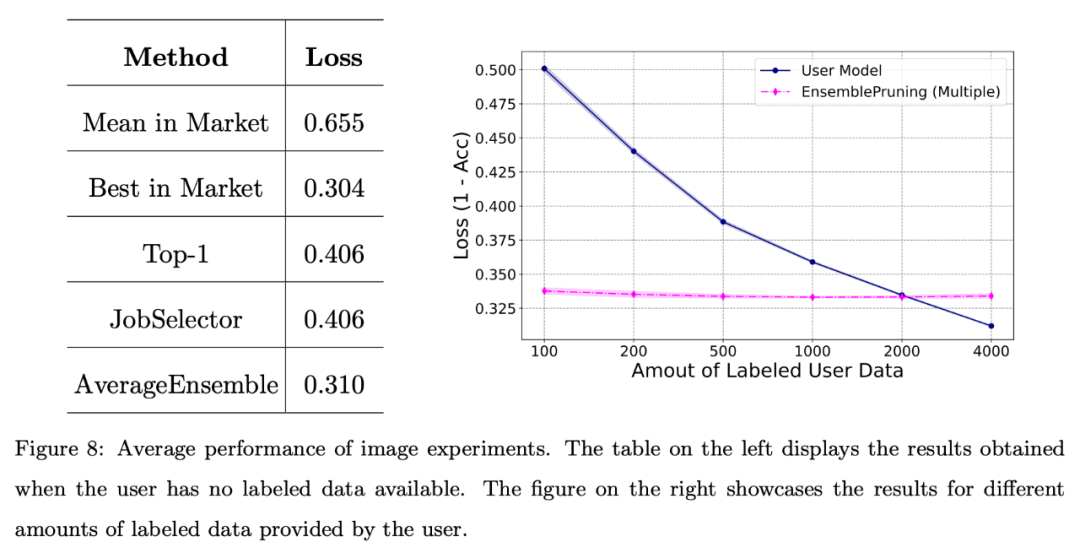
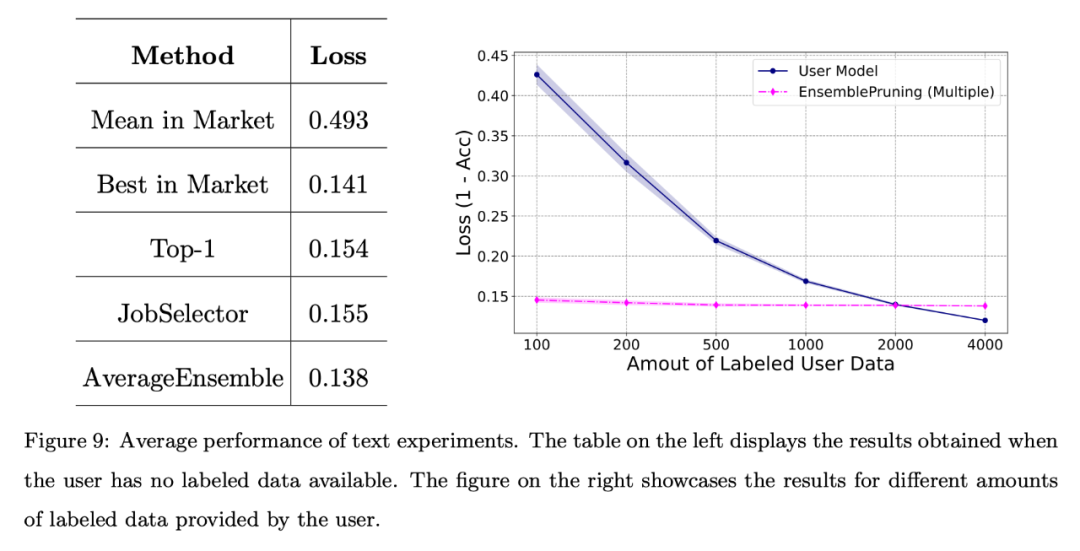
Das Team führte außerdem eine grundlegende Bewertung des Systems anhand eines Benchmark-Textdatensatzes durch. Feature-Space-Ausrichtung über einen einheitlichen Feature-Extraktor.
Wie in der folgenden Abbildung dargestellt, ist die durch die Identifizierung und Wiederverwendung von Lernware erzielte Leistung selbst dann, wenn keine Anmerkungsdaten bereitgestellt werden, mit der der besten Lernware im System vergleichbar.
Darüber hinaus können im Vergleich zum Training des Modells von Grund auf durch die Verwendung des Lernbasissystems etwa 2000 Proben eingespart werden.
Das obige ist der detaillierte Inhalt vonEin 8-jähriges Meisterwerk des Teams von NTU Zhou Zhihua! Das „Learningware'-System löst das Problem der Wiederverwendung maschinellen Lernens und die „Modellfusion' bringt ein neues Paradigma der wissenschaftlichen Forschung hervor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in den Entscheidungsbaum für maschinelles Lernen in Python
- Was bedeutet, dass der Start des Windows-Bootmanagers fehlgeschlagen ist?
- Was soll ich tun, wenn der Win10-Bluescreen mit dem Fehlercode Fehler bei der Kernel-Sicherheitsüberprüfung angezeigt wird?
- Verwenden Sie Tsinghua Source, um das Herunterladen von Python-Paketen und Pip-Einstellungen für Windows-Betriebssysteme zu beschleunigen
- Erfahren Sie mehr über die Funktionsweise von Pip: Interpretieren Sie den Download- und Installationsprozess von Python-Paketen