

 Technologie-PeripheriegeräteKIKeine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an
Technologie-PeripheriegeräteKIKeine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an
Texteinbettung (Worteinbettung) ist eine grundlegende Technologie im Bereich der Verarbeitung natürlicher Sprache (NLP). Sie kann Text dem semantischen Raum zuordnen und ihn in eine dichte Vektordarstellung umwandeln. Diese Methode wird häufig in verschiedenen NLP-Aufgaben eingesetzt, darunter Informationsabruf (IR), Beantwortung von Fragen, Berechnung der Textähnlichkeit und Empfehlungssysteme. Durch die Texteinbettung können wir die Bedeutung und Beziehung von Texten besser verstehen und dadurch die Effektivität von NLP-Aufgaben verbessern.
Im Bereich des Information Retrieval (IR) werden in der ersten Stufe des Retrievals üblicherweise Texteinbettungen zur Ähnlichkeitsberechnung verwendet. Es funktioniert, indem es einen kleinen Satz Kandidatendokumente in einem großen Korpus abruft und dann feinkörnige Berechnungen durchführt. Einbettungsbasierter Abruf ist auch ein wichtiger Bestandteil der Retrieval-Augmented Generation (RAG). Es ermöglicht großen Sprachmodellen (LLMs), auf dynamisches externes Wissen zuzugreifen, ohne Modellparameter zu ändern. Auf diese Weise kann das IR-System Texteinbettungen und externes Wissen besser nutzen, um die Abrufergebnisse zu verbessern.
Obwohl frühe Lernmethoden zur Texteinbettung wie word2vec und GloVe weit verbreitet sind, schränken ihre statischen Eigenschaften die Fähigkeit ein, umfangreiche Kontextinformationen in natürlicher Sprache zu erfassen. Mit dem Aufkommen vorab trainierter Sprachmodelle haben jedoch einige neue Methoden wie Sentence-BERT und SimCSE erhebliche Fortschritte bei NLI-Datensätzen (Natural Language Inference) erzielt, indem BERT so optimiert wurde, dass es Texteinbettungen lernt. Diese Methoden nutzen die kontextbewussten Fähigkeiten von BERT, um die Semantik und den Kontext von Text besser zu verstehen und dadurch die Qualität und Ausdruckskraft von Texteinbettungen zu verbessern. Durch die Kombination von Vortraining und Feinabstimmung können diese Methoden umfangreichere semantische Informationen aus großen Korpora für die Verarbeitung natürlicher Sprache lernen Schulung genutzt wurde. Sie werden zunächst anhand von Milliarden schwach überwachter Textpaare vorab trainiert und dann anhand mehrerer annotierter Datensätze verfeinert. Diese Strategie kann die Leistung der Texteinbettung effektiv verbessern.
Bestehende mehrstufige Methoden weisen noch zwei Mängel auf:
1 Der Aufbau einer komplexen mehrstufigen Trainingspipeline erfordert viel technische Arbeit, um eine große Anzahl von Korrelationspaaren zu verwalten.
2. Die Feinabstimmung basiert auf manuell erfassten Datensätzen, die häufig durch die Aufgabenvielfalt und die Sprachabdeckung eingeschränkt sind.
Die meisten Methoden verwenden Encoder im BERT-Stil und ignorieren den Trainingsfortschritt besserer LLM und verwandter Techniken.
Das Forschungsteam von Microsoft hat kürzlich eine einfache und effiziente Trainingsmethode zur Texteinbettung vorgeschlagen, um einige der Mängel früherer Methoden zu überwinden. Dieser Ansatz erfordert keine komplexen Pipeline-Designs oder manuell erstellten Datensätze, sondern nutzt LLM, um verschiedene Textdaten zu synthetisieren. Mit diesem Ansatz konnten sie hochwertige Texteinbettungen für Hunderttausende Texteinbettungsaufgaben in fast 100 Sprachen generieren, während der gesamte Trainingsprozess weniger als 1.000 Schritte umfasste.
 Link zum Papier: https://arxiv.org/abs/2401.00368
Link zum Papier: https://arxiv.org/abs/2401.00368
Konkret verwendeten die Forscher eine zweistufige Aufforderungsstrategie, indem sie zuerst den LLM-Brainstorming-Kandidaten-Aufgabenpool aufforderten und dann Aufforderung LLM generiert Daten für eine bestimmte Aufgabe aus dem Pool.
Um verschiedene Anwendungsszenarien abzudecken, entwarfen die Forscher mehrere Eingabeaufforderungsvorlagen für jeden Aufgabentyp und kombinierten die von verschiedenen Vorlagen generierten Daten, um die Vielfalt zu erhöhen.
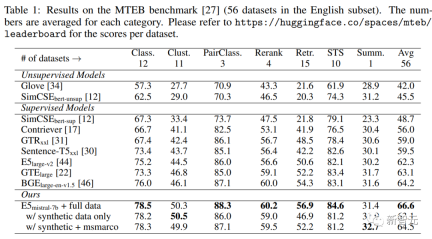
Experimentelle Ergebnisse belegen, dass Mistral-7B bei der Feinabstimmung „nur synthetischer Daten“ eine sehr wettbewerbsfähige Leistung bei den BEIR- und MTEB-Benchmarks erzielt; wenn die Feinabstimmung sowohl synthetischer als auch annotierter Daten hinzugefügt wird, wird eine Sota-Leistung erreicht.
Verwenden Sie große Modelle, um die Texteinbettung zu verbessern
1. Generierung synthetischer DatenDie Verwendung modernster großer Sprachmodelle (LLM) wie GPT-4 zur Synthese von Daten gewinnt immer mehr an Bedeutung , was das Modell hinsichtlich Multitasking und Mehrsprachenfähigkeitsvielfalt verbessern kann, wodurch robustere Texteinbettungen trainiert werden können, die bei verschiedenen nachgelagerten Aufgaben (z. B. semantischer Abruf, Textähnlichkeitsberechnung, Clustering) eine gute Leistung erbringen.
Um vielfältige synthetische Daten zu generieren, schlugen die Forscher eine einfache Taxonomie vor, die zunächst Einbettungsaufgaben klassifiziert und dann für jeden Aufgabentyp unterschiedliche Eingabeaufforderungsvorlagen verwendet.
Asymmetrische Aufgaben
Umfasst Aufgaben, bei denen die Abfrage und das Dokument semantisch miteinander verbunden sind, sich aber nicht gegenseitig umschreiben. Basierend auf der Länge der Abfrage und des Dokuments unterteilten die Forscher die asymmetrischen Aufgaben weiter in vier Unterkategorien: Short-Long-Matching (kurze Abfrage und langes Dokument, ein typisches Szenario in kommerziellen Suchmaschinen), Long-Short-Matching, kurz – Kurzes Spiel und langes langes Spiel. Für jede Unterkategorie entwarfen die Forscher eine zweistufige Eingabeaufforderungsvorlage, bei der sie LLM zunächst dazu aufforderten, eine Aufgabenliste zu erstellen, und dann ein spezifisches Beispiel für die aufgabendefinierten Bedingungen generierten. Die Ausgabe von GPT-4 war größtenteils kohärent. Die Qualität ist sehr hoch. In Vorversuchen versuchten die Forscher auch, mit einer einzigen Eingabeaufforderung Aufgabendefinitions- und Abfragedokumentpaare zu generieren, aber die Datenvielfalt war nicht so gut wie bei der oben erwähnten zweistufigen Methode. Symmetrieaufgaben umfassen hauptsächlich Abfragen und Dokumente mit ähnlicher Semantik, aber unterschiedlichen Oberflächenformen. In diesem Artikel werden zwei Anwendungsszenarien untersucht: monolinguale semantische Textähnlichkeit (STS) und Bi-Text-Retrieval. Für jedes Szenario werden zwei verschiedene Eingabeaufforderungsvorlagen entworfen, die seit der Definition der Aufgabe an ihre spezifischen Ziele angepasst werden relativ einfach ist, kann der Brainstorming-Schritt weggelassen werden. Um die Vielfalt der Eingabeaufforderungswörter weiter zu erhöhen und die Vielfalt der synthetischen Daten zu verbessern, haben die Forscher zu jeder Eingabeaufforderungstafel mehrere Platzhalter hinzugefügt und diese zur Laufzeit zufällig abgetastet. Beispielsweise steht „{query_length}“ für „Sampled from“. die Menge „{weniger als 5 Wörter, 5-10 Wörter, mindestens 10 Wörter}“. Um mehrsprachige Daten zu generieren, haben Forscher den Wert von „{Sprache}“ aus der Sprachliste von XLM-R entnommen und dabei allen generierten Daten, die nicht dem vordefinierten JSON entsprechen, mehr Gewicht gegeben Das Format wird beim Parsen verworfen; Duplikate werden auch basierend auf der genauen Zeichenfolgenübereinstimmung entfernt. Verwenden Sie bei einem gegebenen Abfrage-Dokument-Paar zunächst die ursprüngliche Abfrage q+, um eine neue Anweisung q_inst zu generieren, wobei „{task_definition}“ ein Platzhalter zum Einbetten einer einsatzigen Beschreibung ist Aufgabensymbol. Für die generierten synthetischen Daten wird die Ausgabe des Brainstorming-Schritts verwendet; für andere Datensätze, wie z. B. MS-MARCO, erstellen Forscher manuell Aufgabendefinitionen und wenden sie auf alle Abfragen im Datensatz an, ohne die Dateien zu ändern Beliebiges Befehlspräfix am Ende. Auf diese Weise ist der Dokumentenindex vorgefertigt und die auszuführenden Aufgaben können angepasst werden, indem nur die Abfrageseite geändert wird. Hängen Sie bei einem vorab trainierten LLM ein [EOS]-Token an das Ende der Abfrage und des Dokuments an und geben Sie es dann in das LLM ein, um die Abfrage- und Dokumenteinbettungen zu erhalten, indem Sie den [EOS]-Vektor der letzten Ebene abrufen. Dann verwenden Sie den Standard-InfoNCE-Verlust, um den Verlust für Intra-Batch-Negative und Hard-Negative zu berechnen. wobei ℕ die Menge aller Negative darstellt, Die Forscher nutzten den Azure OpenAI-Dienst, um 500.000 Beispiele mit 150.000 eindeutigen Anweisungen zu generieren, von denen 25 % von GPT-3.5-Turbo und der Rest von GPT-4 generiert wurden , die insgesamt 180 Millionen Token verbrauchte. Die Hauptsprache ist Englisch und deckt insgesamt 93 Sprachen ab. Für 75 ressourcenarme Sprachen gibt es durchschnittlich etwa 1.000 Beispiele pro Sprache. In Bezug auf die Datenqualität stellten die Forscher fest, dass einige der Ergebnisse von GPT-3.5-Turbo nicht strikt den in der Eingabeaufforderungsvorlage angegebenen Richtlinien entsprachen, die Gesamtqualität jedoch dennoch akzeptabel und vorläufig war Experimente haben auch gezeigt, dass die Verwendung dieser Teilmenge von Daten Vorteile bietet. Modellfeinabstimmung und -bewertung Die Forscher nutzten den oben genannten Verlust, um den vorab trainierten Mistral-7B für eine Epoche zu optimieren, folgten der Trainingsmethode von RankLLaMA und verwendeten LoRA mit Rang 16 . Um den GPU-Speicherbedarf weiter zu reduzieren, kommen Technologien wie Gradient Checkpointing, Mixed Precision Training und DeepSpeed ZeRO-3 zum Einsatz. In Bezug auf Trainingsdaten wurden sowohl generierte synthetische Daten als auch 13 öffentliche Datensätze verwendet, was nach der Stichprobe zu etwa 1,8 Millionen Beispielen führte. Für einen fairen Vergleich mit einigen früheren Arbeiten berichten die Forscher auch über Ergebnisse, wenn die einzige Annotationsüberwachung der MS-MARCO-Kapitelranking-Datensatz ist, und bewerten das Modell auch anhand des MTEB-Benchmarks. Wie Sie in der Tabelle unten sehen können, erreichte das im Artikel erhaltene Modell „E5mistral-7B + vollständige Daten“ die höchste durchschnittliche Punktzahl im MTEB-Benchmark, die 2,4 höher ist als das vorherige fortschrittlichstes Modell. In der Einstellung „nur mit synthetischen Daten“ werden keine annotierten Daten für das Training verwendet, aber die Leistung ist immer noch sehr konkurrenzfähig. Die Forscher verglichen auch mehrere kommerzielle Texteinbettungsmodelle, aber die mangelnde Transparenz und Dokumentation dieser Modelle verhinderte einen fairen Vergleich. Aus den Ergebnissen des Abrufleistungsvergleichs auf dem BEIR-Benchmark geht jedoch hervor, dass das trainierte Modell dem aktuellen kommerziellen Modell weit überlegen ist. Mehrsprachiger Abruf Um die Mehrsprachigkeit des Modells zu bewerten, führten die Forscher eine Auswertung des MIRACL-Datensatzes durch, der von Menschen kommentierte Abfragen und Relevanzbeurteilungen in 18 Sprachen enthält. Die Ergebnisse zeigen, dass das Modell mE5-large in ressourcenreichen Sprachen, insbesondere in Englisch, übertrifft und seine Leistung besser ist. Für ressourcenarme Sprachen ist das Modell jedoch immer noch nicht ideal im Vergleich zu mE5-base. Die Forscher führen dies darauf zurück, dass Mistral-7B vorab hauptsächlich anhand englischer Daten trainiert wurde, eine Methode, mit der prädiktive mehrsprachige Modelle diese Lücke schließen können. 
2. Training

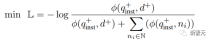
 zur Berechnung des Matching-Scores zwischen der Abfrage und dem Dokument verwendet wird, t ein Temperatur-Hyperparameter ist, der im Experiment auf 0,02 festgelegt wurde
zur Berechnung des Matching-Scores zwischen der Abfrage und dem Dokument verwendet wird, t ein Temperatur-Hyperparameter ist, der im Experiment auf 0,02 festgelegt wurde
Experimentergebnisse
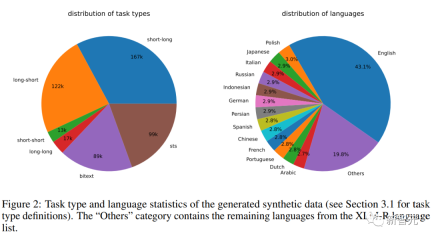
Synthetische Datenstatistik
Hauptergebnisse
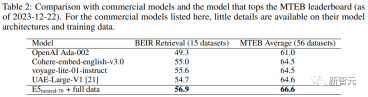
Das obige ist der detaillierte Inhalt vonKeine manuelle Anmerkung erforderlich! LLM unterstützt das Lernen der Texteinbettung: Unterstützt problemlos 100 Sprachen und passt sich Hunderttausenden nachgelagerten Aufgaben an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Sie müssen KI am Arbeitsplatz hinter einem Schleier der Unwissenheit bauenApr 29, 2025 am 11:15 AM
Sie müssen KI am Arbeitsplatz hinter einem Schleier der Unwissenheit bauenApr 29, 2025 am 11:15 AMIn John Rawls 'wegweisendem Buch von 1971 schlug er ein Gedankenexperiment vor, das wir als Kern des heutigen KI-Designs und der Entscheidungsfindung verwenden sollten: den Schleier der Unwissenheit. Diese Philosophie bietet ein einfaches Instrument zum Verständnis von Eigenkapital und bietet auch eine Entwurf für Führungskräfte, um dieses Verständnis zu nutzen, um KI auf gerechte Weise zu entwerfen und umzusetzen. Stellen Sie sich vor, Sie treffen Regeln für eine neue Gesellschaft. Aber es gibt eine Prämisse: Sie wissen nicht im Voraus, welche Rolle Sie in dieser Gesellschaft spielen werden. Möglicherweise sind Sie reich oder arm, gesund oder behindert, gehören einer Mehrheit oder einer marginalen Minderheit. Der Betrieb unter diesem "Schleier der Unwissenheit" verhindert, dass Regelmacher Entscheidungen treffen, die selbst zugute kommen. Im Gegenteil, die Menschen werden motivierter sein, die Öffentlichkeit zu formulieren
 Entscheidungen, Entscheidungen… nächste Schritte für die praktische angewandte KIApr 29, 2025 am 11:14 AM
Entscheidungen, Entscheidungen… nächste Schritte für die praktische angewandte KIApr 29, 2025 am 11:14 AMZahlreiche Unternehmen sind auf Roboterprozessautomatisierung (RPA) spezialisiert und bieten Bots, um sich wiederholende Aufgaben zu automatisieren - Uipath, Automatisierung überall, blaues Prisma und andere. In der Zwischenzeit verarbeiten Sie Mining, Orchestrierung und intelligente Dokumentenverarbeitung Speciali
 Die Agenten kommen - mehr darüber, was wir neben AI -Partnern tun werdenApr 29, 2025 am 11:13 AM
Die Agenten kommen - mehr darüber, was wir neben AI -Partnern tun werdenApr 29, 2025 am 11:13 AMDie Zukunft der KI bewegt sich über die einfache Wortvorhersage und die Konversationsimulation hinaus. KI -Agenten sind aufgetaucht, in der Lage, unabhängige Handlungen und Aufgabenabschluss zu erledigen. Diese Verschiebung zeigt sich bereits in Tools wie dem Claude von Anthropic. KI -Agenten: Forschung a
 Warum Empathie wichtiger ist als die Kontrolle für Führungskräfte in einer KI-gesteuerten ZukunftApr 29, 2025 am 11:12 AM
Warum Empathie wichtiger ist als die Kontrolle für Führungskräfte in einer KI-gesteuerten ZukunftApr 29, 2025 am 11:12 AMSchnelle technologische Fortschritte erfordern eine zukunftsweisende Perspektive auf die Zukunft der Arbeit. Was passiert, wenn die KI nur die Produktivitätsverstärkung überschreitet und unsere gesellschaftlichen Strukturen prägt? Topher McDougals bevorstehendes Buch Gaia Wakes:
 KI für die Produktklassifizierung: Können Maschinen das Steuergesetz meistern?Apr 29, 2025 am 11:11 AM
KI für die Produktklassifizierung: Können Maschinen das Steuergesetz meistern?Apr 29, 2025 am 11:11 AMDie Produktklassifizierung, die häufig komplexe Codes wie "HS 8471.30" aus Systemen wie dem harmonisierten System (HS) umfasst, ist für den internationalen Handel und den Inlandsumsatz von entscheidender Bedeutung. Diese Codes gewährleisten den korrekten Steuerantrag und wirken sich auf jeden Inv aus
 Könnte die Nachfrage des Rechenzentrums einen Klima -Tech -Rebound auslösen?Apr 29, 2025 am 11:10 AM
Könnte die Nachfrage des Rechenzentrums einen Klima -Tech -Rebound auslösen?Apr 29, 2025 am 11:10 AMDie Zukunft des Energieverbrauchs in Rechenzentren und Klimaschutzinvestitionen In diesem Artikel wird der Anstieg des Energieverbrauchs in Rechenzentren untersucht, die von KI und ihren Auswirkungen auf den Klimawandel angetrieben werden, und analysiert innovative Lösungen und politische Empfehlungen, um diese Herausforderung zu befriedigen. Herausforderungen des Energiebedarfs: Zentren im großen und ultra-großen Maßstab verbrauchen enorme Macht, vergleichbar mit der Summe von Hunderttausenden gewöhnlicher nordamerikanischer Familien und aufstrebende AI-Zentren im Bereich Ultra-Large-Scale-Zentren verbrauchen Dutzende von Zeiten mehr mehr Macht als diese. In den ersten acht Monaten des 2024 haben Microsoft, Meta, Google und Amazon rund 125 Milliarden US -Dollar in den Bau und den Betrieb von AI -Rechenzentren investiert (JP Morgan, 2024) (Tabelle 1). Der wachsende Energiebedarf ist sowohl eine Herausforderung als auch eine Chance. Laut Kanarischen Medien der drohende Elektrizität
 AI und Hollywoods nächstes goldenes ZeitalterApr 29, 2025 am 11:09 AM
AI und Hollywoods nächstes goldenes ZeitalterApr 29, 2025 am 11:09 AMGenerative AI revolutioniert die Film- und Fernsehproduktion. Das Ray 2-Modell von Luma sowie das Gen-4 von Runway, Openai von Sora, Google's VEO und andere neue Modelle verbessern die Qualität der generierten Videos mit beispielloser Geschwindigkeit. Diese Modelle können problemlos komplexe Spezialeffekte und realistische Szenen erzeugen, selbst kurze Videoclips und Kameraser-Bewegungseffekte wurden erreicht. Während die Manipulation und Konsistenz dieser Tools noch verbessert werden müssen, ist die Geschwindigkeit des Fortschritts erstaunlich. Generatives Video wird zu einem unabhängigen Medium. Einige Modelle sind gut in der Animationsproduktion, andere sind gut in Live-Action-Bildern. Es ist erwähnenswert, dass Adobe's Firefly und Moonvalleys MA
 Wird Chatgpt langsam AIs größtes Ja-Mann?Apr 29, 2025 am 11:08 AM
Wird Chatgpt langsam AIs größtes Ja-Mann?Apr 29, 2025 am 11:08 AMChatGPT -Benutzererfahrung lehnt ab: Ist es ein Modellverschlechterungs- oder Benutzererwartungen? In jüngster Zeit haben sich eine große Anzahl von ChatGPT bezahlten Nutzern über ihre Leistungsverschlechterung beschwert, die weit verbreitete Aufmerksamkeit erregt hat. Die Benutzer berichteten über langsamere Antworten auf Modelle, kürzere Antworten, mangelnde Hilfe und noch mehr Halluzinationen. Einige Benutzer äußerten Unzufriedenheit in den sozialen Medien und wiesen darauf hin, dass ChatGPT zu „zu schmeichelhaft“ geworden ist, und neigt dazu, Benutzeransichten zu überprüfen, anstatt ein kritisches Feedback zu geben. Dies wirkt sich nicht nur auf die Benutzererfahrung aus, sondern verleiht Unternehmenskunden auch tatsächliche Verluste, wie z. B. reduzierte Produktivität und Rechenressourcenverschwendung. Nachweis der Leistungsverschlechterung Viele Benutzer haben einen signifikanten Verschlechterung der Chatgpt-Leistung gemeldet, insbesondere in älteren Modellen wie GPT-4 (die Ende dieses Monats bald vom Service abgebrochen werden). Das


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

