
Heim >Technologie-Peripheriegeräte >KI >Netizens enthüllten die Einbettungstechnologie, die im neuen Modell von OpenAI verwendet wird
Netizens enthüllten die Einbettungstechnologie, die im neuen Modell von OpenAI verwendet wird

- 王林nach vorne
- 2024-01-29 09:03:29785Durchsuche
Vor ein paar Tagen kam OpenAI mit einer Welle wichtiger Updates und kündigte gleich fünf neue Modelle an, darunter zwei neue Texteinbettungsmodelle.
Einbettung ist die Verwendung numerischer Sequenzen zur Darstellung von Konzepten in natürlicher Sprache, Code usw. Sie helfen Modellen des maschinellen Lernens und anderen Algorithmen, die Beziehungen zwischen Inhalten besser zu verstehen und erleichtern die Durchführung von Aufgaben wie Clustering oder Abruf.
Im Allgemeinen verbraucht die Verwendung größerer Einbettungsmodelle (z. B. zum Abrufen im Vektorspeicher gespeichert) mehr Kosten, Rechenleistung, Speicher und Speicherressourcen. Allerdings bieten die beiden von OpenAI eingeführten Texteinbettungsmodelle unterschiedliche Optionen. Erstens ist das Text-Embedding-3-Small-Modell ein kleineres, aber effizientes Modell. Es kann in Umgebungen mit begrenzten Ressourcen verwendet werden und eignet sich gut für Texteinbettungsaufgaben. Andererseits ist das Text-Embedding-3-Large-Modell größer und leistungsfähiger. Dieses Modell kann komplexere Texteinbettungsaufgaben bewältigen und genauere und detailliertere Einbettungsdarstellungen bereitstellen. Die Verwendung dieses Modells erfordert jedoch mehr Rechenressourcen und Speicherplatz. Daher kann abhängig von den spezifischen Anforderungen und Ressourcenbeschränkungen ein geeignetes Modell ausgewählt werden, um das Verhältnis zwischen Kosten und Leistung auszugleichen.
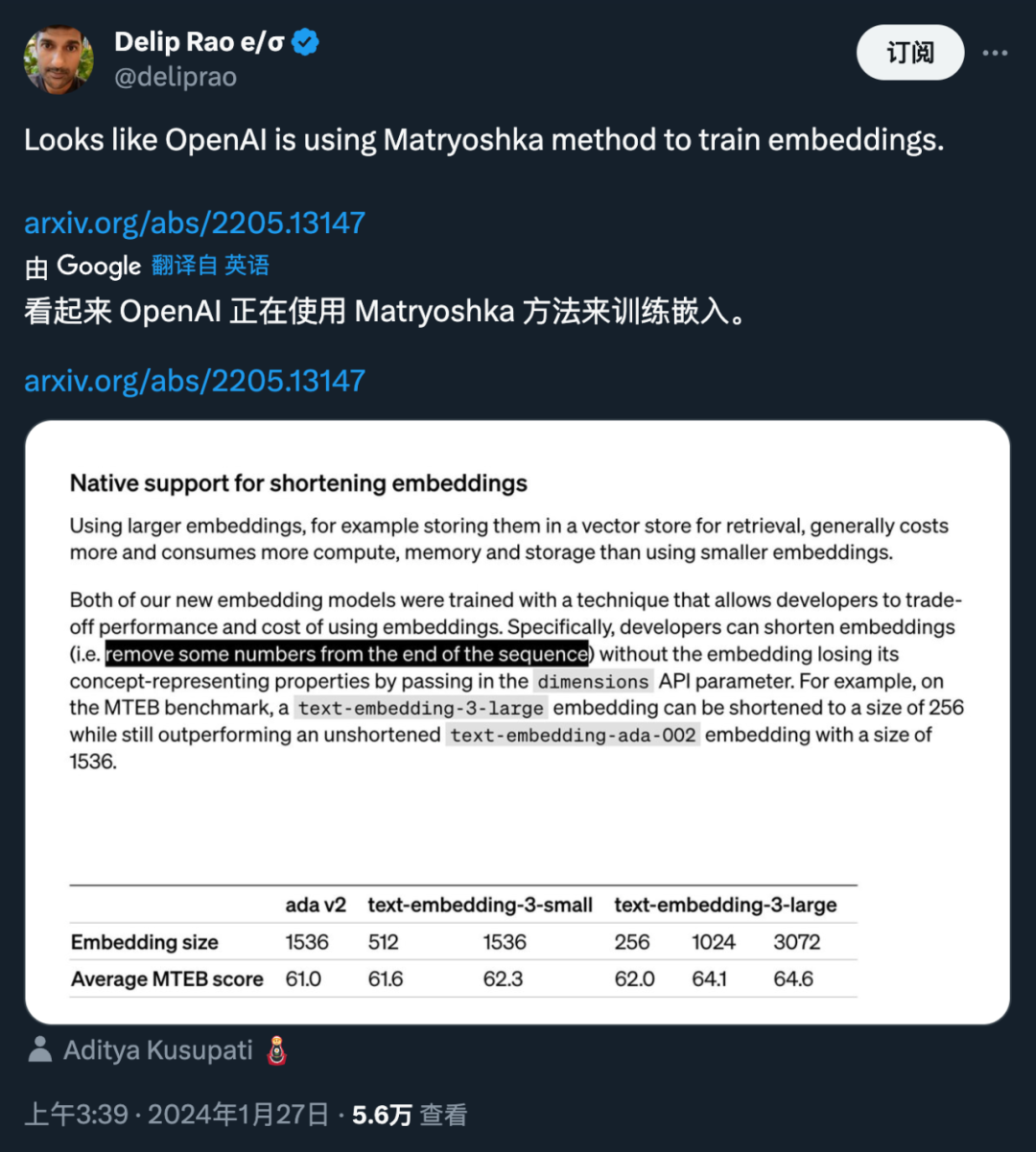
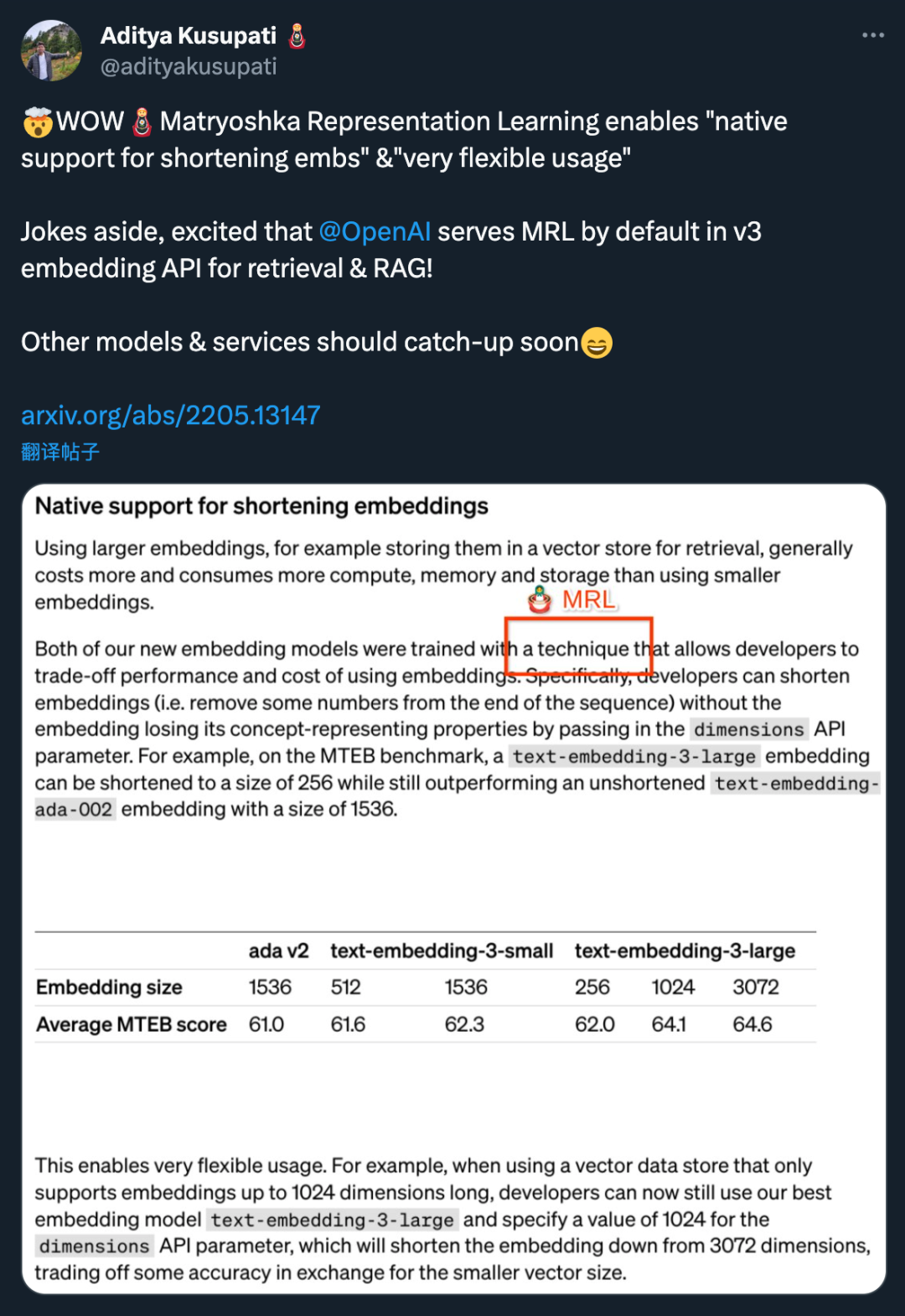
Beide neuen Einbettungsmodelle werden mit einer Trainingstechnik durchgeführt, die es Entwicklern ermöglicht, einen Kompromiss zwischen Leistung und Kosten der Einbettung zu finden. Insbesondere können Entwickler die Größe der Einbettung verkürzen, ohne ihre konzeptionellen Darstellungseigenschaften zu verlieren, indem sie die Einbettung im Dimensions-API-Parameter übergeben. Beispielsweise kann beim MTEB-Benchmark „text-embedding-3-large“ auf eine Größe von 256 gekürzt werden, übertrifft aber immer noch die ungekürzte Einbettung „text-embedding-ada-002“ (der Größe 1536). Auf diese Weise können Entwickler basierend auf spezifischen Anforderungen ein geeignetes Einbettungsmodell auswählen, das nicht nur die Leistungsanforderungen erfüllt, sondern auch die Kosten kontrolliert.

Der Einsatz dieser Technologie ist sehr flexibel. Wenn beispielsweise ein Vektordatenspeicher verwendet wird, der nur Einbettungen mit bis zu 1024 Dimensionen unterstützt, kann ein Entwickler das beste Einbettungsmodell text-embedding-3-large auswählen und die Einbettungsdimensionen von 3072 ändern, indem er für die Dimensions-API einen Wert von 1024 angibt Parameter gekürzt auf 1024. Obwohl dies zu Einbußen bei der Genauigkeit führen kann, können kleinere Vektorgrößen erzielt werden.
Die von OpenAI verwendete Methode der „verkürzten Einbettung“ erregte in der Folge große Aufmerksamkeit bei Forschern.
Es wurde festgestellt, dass diese Methode mit der „Matryoshka Representation Learning“-Methode identisch ist, die in einem Artikel im Mai 2022 vorgeschlagen wurde.
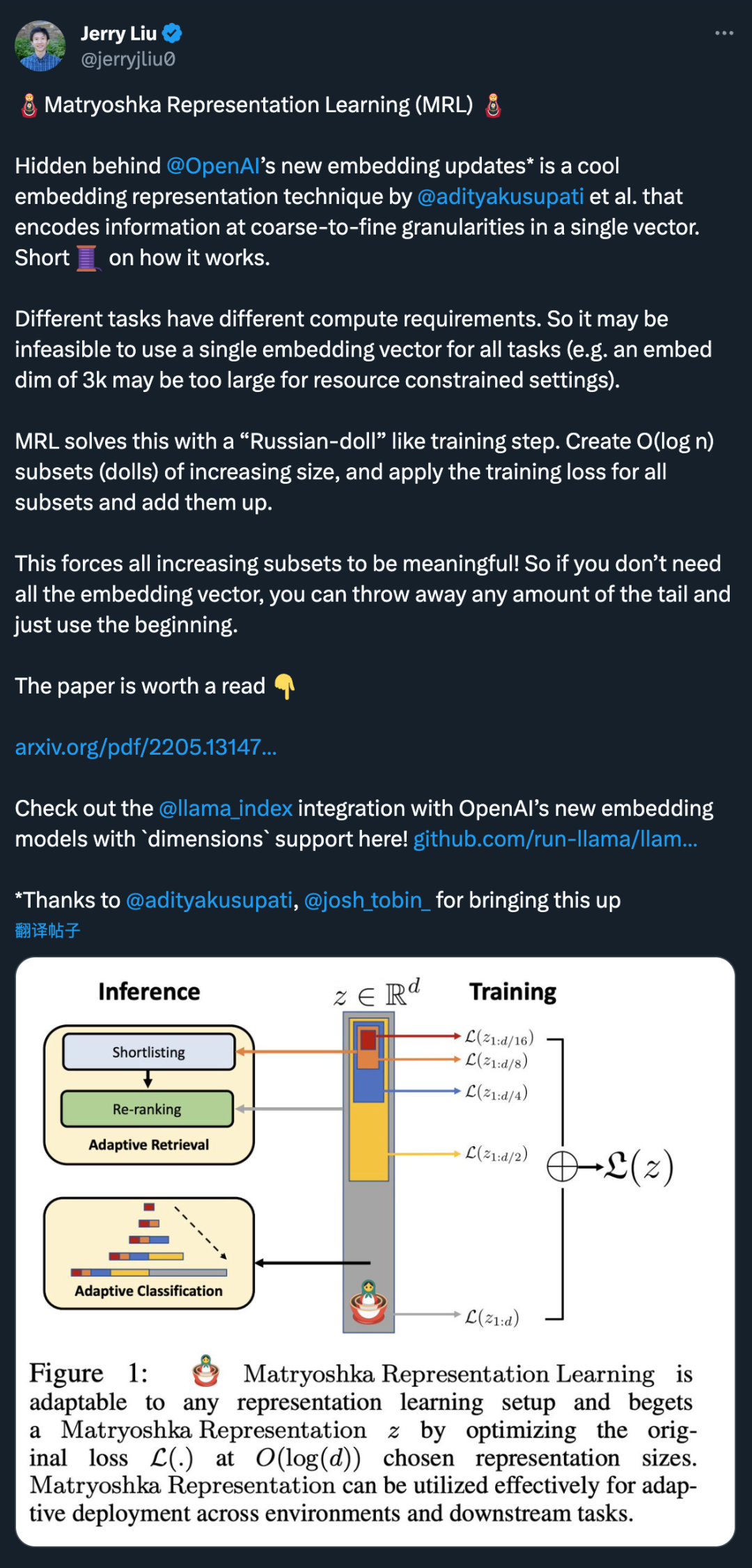
Hinter dem neuen Einbettungsmodell-Update von OpenAI verbirgt sich eine coole Einbettungsdarstellungstechnik, die von @adityakusupati et al. vorgeschlagen wurde.
Und Aditya Kusupati, einer der Autoren von MRL, sagte auch: „OpenAI verwendet standardmäßig MRL in der eingebetteten API der Version 3 für den Abruf und RAG! Andere Modelle und Dienste sollten bald aufholen.“ Was ist dann MRL genau? Wie ist die Wirkung? Das alles finden Sie unten in der Veröffentlichung von 2022.
Papiertitel: Matryoshka Representation Learning
- Papierlink: https://arxiv.org/pdf/2205.13147.pdf
- Die von den Forschern gestellte Frage lautet: Kann eine flexible Darstellungsmethode so gestaltet werden, dass sie sich an mehrere nachgelagerte Aufgaben mit unterschiedlichen Rechenressourcen anpasst?
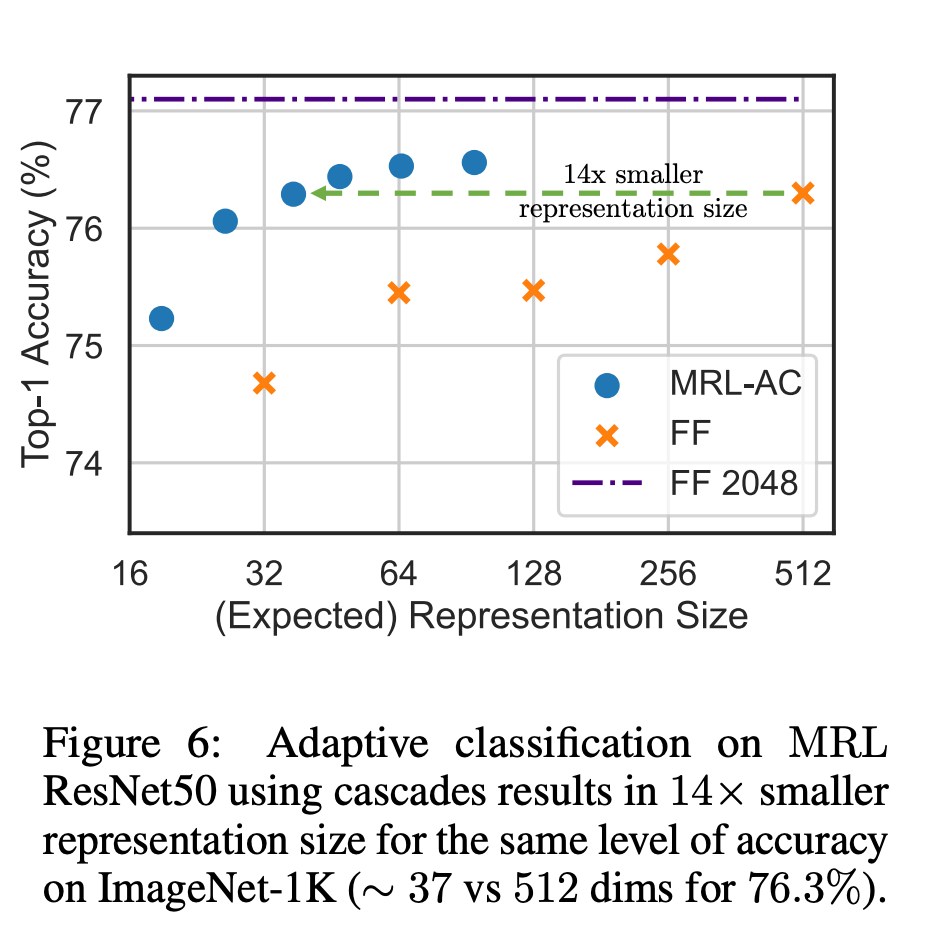
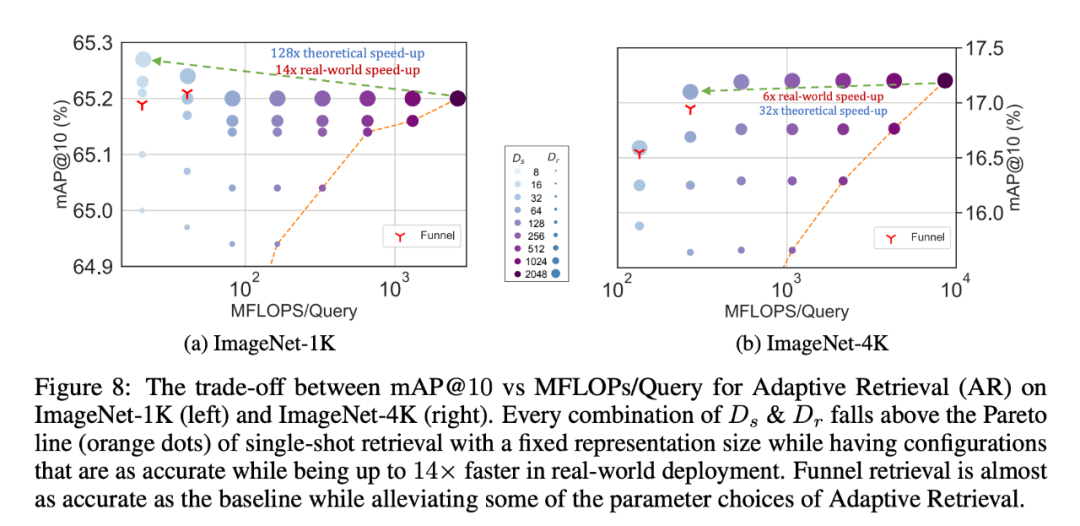
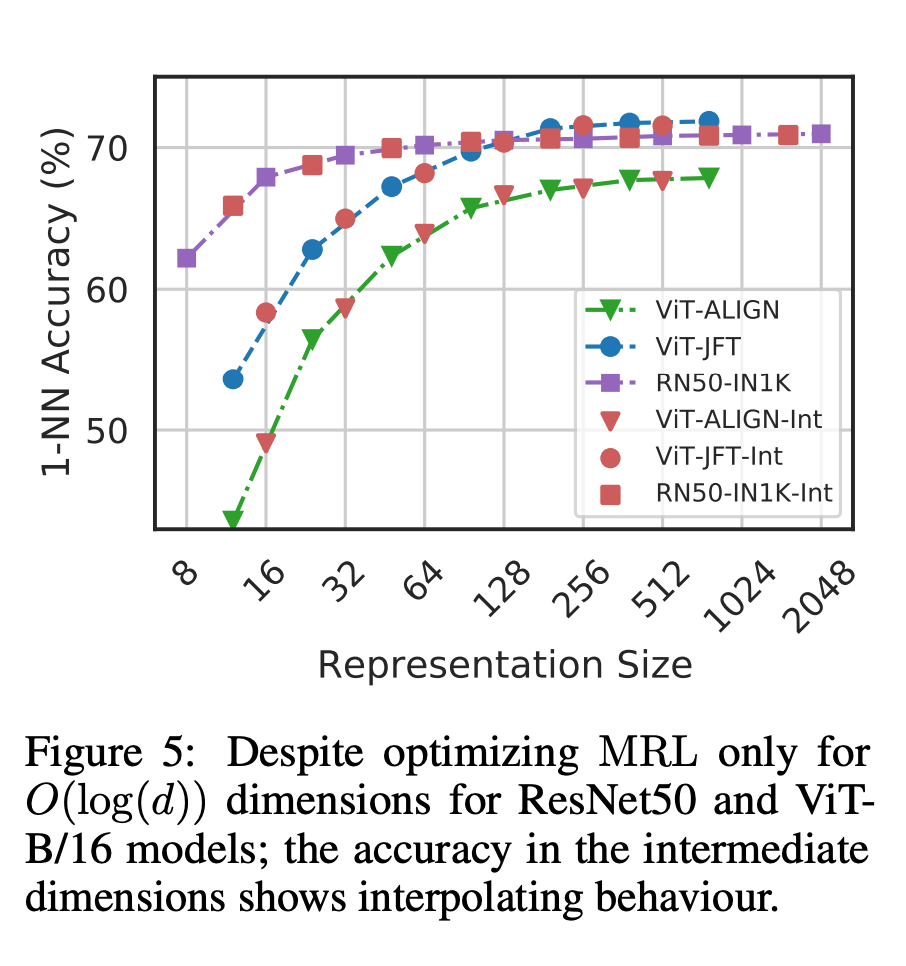
Abbildung 1 zeigt die Kernidee von MRL und die adaptive Einsatzeinstellung der erlernten Matroschka-Darstellung: Die ersten m-Dimensionen (m∈[d]) der Matroschka-Darstellung sind eine Informations- Reichhaltiger niedrigdimensionaler Vektor, keine zusätzlichen Trainingskosten erforderlich, und seine Genauigkeit ist nicht geringer als die der unabhängig trainierten m-dimensionalen Darstellungsmethode. Der Informationsgehalt von Matroschka-Darstellungen nimmt mit zunehmender Dimensionalität zu und bildet eine Grob-zu-Fein-Darstellung, ohne dass umfangreiches Training oder zusätzlicher Bereitstellungsaufwand erforderlich sind. MRL bietet die erforderliche Flexibilität und Multitreue zur Charakterisierung von Vektoren und sorgt so für einen nahezu optimalen Kompromiss zwischen Genauigkeit und Rechenaufwand. Mit diesen Vorteilen kann MRL basierend auf Genauigkeit und rechnerischen Einschränkungen adaptiv eingesetzt werden. In dieser Arbeit konzentrieren sich die Forscher auf zwei Schlüsselbausteine realer ML-Systeme: Klassifizierung und Abruf im großen Maßstab. Zur Klassifizierung verwendeten die Forscher adaptive Kaskaden und Darstellungen variabler Größe, die von durch MRL trainierten Modellen erstellt wurden, wodurch die durchschnittliche eingebettete Dimensionalität, die zum Erreichen einer bestimmten Genauigkeit erforderlich ist, erheblich reduziert wurde. Bei ImageNet-1K beispielsweise führt die adaptive MRL-Klassifizierung zu einer Reduzierung der Darstellungsgröße um das bis zu 14-fache bei derselben Genauigkeit wie die Basislinie. Ähnlich haben Forscher MRL auch in adaptiven Retrieval-Systemen verwendet. Bei einer gegebenen Abfrage werden die ersten paar Dimensionen der Abfrageeinbettung verwendet, um die Abrufkandidaten zu filtern, und dann werden nach und nach weitere Dimensionen verwendet, um den Abrufsatz neu zu ordnen. Eine einfache Implementierung dieses Ansatzes erreicht die 128-fache theoretische Geschwindigkeit (in FLOPS) und die 14-fache Wall-Clock-Zeit im Vergleich zu einem einzelnen Abrufsystem mit Standard-Einbettungsvektoren. Es ist wichtig zu beachten, dass die Abrufgenauigkeit von MRL vergleichbar ist das einer Einzelsuche (Abschnitt 4.3.1). Da MRL schließlich Darstellungsvektoren von grob bis fein intuitiv lernt, sollte es mehr semantische Informationen über verschiedene Dimensionen hinweg teilen (Abbildung 5). Dies spiegelt sich in einer kontinuierlichen Long-Tail-Lerneinstellung wider, die die Genauigkeit um bis zu 2 % verbessert und gleichzeitig genauso robust ist wie die ursprünglichen Einbettungen. Aufgrund der grobkörnigen bis feinkörnigen Natur der MRL kann sie außerdem als Methode zur Analyse der Einfachheit der Instanzklassifizierung und von Informationsengpässen verwendet werden. Weitere Forschungsdetails finden Sie im Originaltext des Papiers. 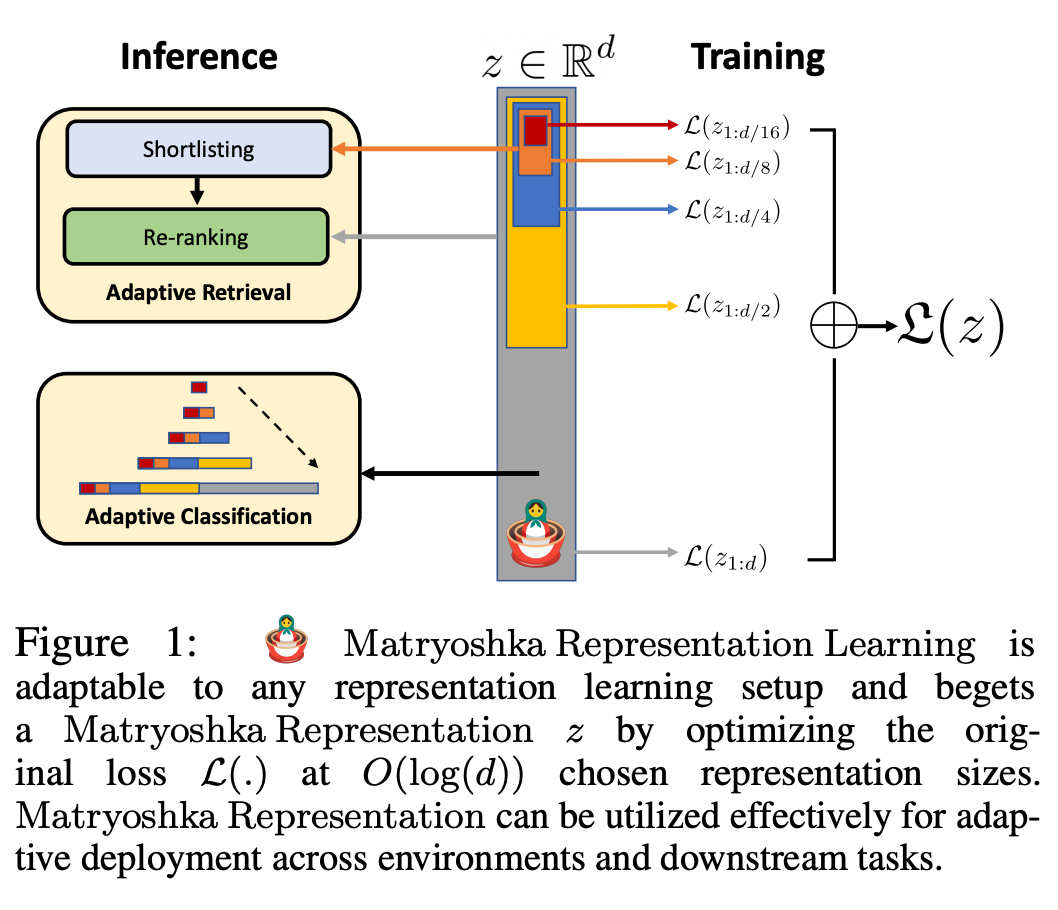
Das obige ist der detaillierte Inhalt vonNetizens enthüllten die Einbettungstechnologie, die im neuen Modell von OpenAI verwendet wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!