
Heim >Technologie-Peripheriegeräte >KI >OK-Robot entwickelt von Meta und der New York University: Teeausgießer-Roboter ist entstanden
OK-Robot entwickelt von Meta und der New York University: Teeausgießer-Roboter ist entstanden

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-24 20:15:04867Durchsuche
Im familiären Umfeld werden Familienmitglieder oft gebeten, die Fernbedienung am Fernsehschrank in die Hand zu nehmen. Manchmal sind sogar Haushunde nicht immun. Aber es gibt immer wieder Situationen, in denen Menschen nicht in der Lage sind, andere zu kontrollieren. Und Hunde sind möglicherweise nicht in der Lage, die Anweisungen zu verstehen. Die Erwartung der Menschen an Roboter besteht darin, bei der Erledigung dieser Aufgaben zu helfen. Dies ist unser ultimativer Traum für Roboter.
Kürzlich haben die New York University und Meta zusammengearbeitet, um einen Roboter mit der Fähigkeit zum autonomen Handeln zu entwickeln. Wenn Sie ihm sagen: „Legen Sie die Cornflakes bitte auf den Tisch auf dem Nachttisch“, erledigt es die Aufgabe erfolgreich, indem es selbständig nach den Cornflakes sucht und die beste Route und entsprechende Aktionen plant. Darüber hinaus verfügt der Roboter auch über die Fähigkeit, Gegenstände zu organisieren und mit Müll umzugehen, um Ihnen Komfort zu bieten.



Dieser Roboter heißt OK-Robot und wurde von Forschern der New York University und Meta gebaut. Sie integrierten die Grundmodule des visuellen Sprachmodells, der Navigation und des Greifens in ein offenes, wissensbasiertes Framework, um eine Lösung für effiziente Pick-and-Place-Operationen von Robotern bereitzustellen. Das bedeutet, dass die Anschaffung eines Roboters, der uns beim Servieren von Tee und Wasser unterstützt, mit zunehmendem Alter Realität werden kann.
OK-Robots Positionierung als „offenes Wissen“ bezieht sich auf sein Lernmodell, das auf großen öffentlichen Datensätzen trainiert wird. Wenn OK-Robot in einer neuen häuslichen Umgebung platziert wird, ruft es die Scanergebnisse vom iPhone ab. Basierend auf diesen Scans berechnet es mithilfe von LangSam und CLIP dichte visuelle Sprachdarstellungen und speichert sie im semantischen Speicher. Wenn dann eine sprachliche Anfrage nach einem aufzunehmenden Objekt gestellt wird, wird die sprachliche Darstellung der Anfrage mit dem semantischen Gedächtnis abgeglichen. Als nächstes wendet OK-Robot nach und nach die Navigations- und Kommissionierungsmodule an, bewegt sich zum gewünschten Objekt und nimmt es auf. Ein ähnlicher Prozess kann zum Verwerfen von Objekten verwendet werden.
Um OK-Robot zu untersuchen, haben Forscher es in 10 realen häuslichen Umgebungen getestet. Durch Experimente fanden sie heraus, dass in einer unsichtbaren natürlichen häuslichen Umgebung die Erfolgsquote des Systems bei der Zero-Sample-Bereitstellung durchschnittlich 58,5 % betrug. Allerdings hängt diese Erfolgsquote stark von der „Natürlichkeit“ der Umgebung ab. Sie fanden außerdem heraus, dass diese Erfolgsquote auf etwa 82,4 % gesteigert werden konnte, indem die Abfrage verbessert, der Raum aufgeräumt und offensichtlich störende Objekte (z. B. zu groß, zu durchscheinend oder zu rutschig) ausgeschlossen wurden.
OK-Robot hat 171 Aufnahmeaufgaben in 10 häuslichen Umgebungen in New York City versucht.
Zusammenfassend kamen sie durch Experimente zu folgenden Schlussfolgerungen:
- Vorab trainierte visuelle Sprachmodelle sind sehr effektiv für die Navigation im offenen Vokabular: Aktuelle visuelle Sprachmodelle im offenen Vokabular – wie CLIP oder OWL-ViT – — Hervorragend geeignet, beliebige Objekte in der realen Welt zu identifizieren und sie ohne Schüsse zu navigieren und zu finden.
- Vorab trainierte Greifmodelle können direkt auf die mobile Manipulation angewendet werden: Ähnlich wie bei VLM können spezialisierte Robotermodelle, die auf großen Datenmengen vorab trainiert wurden, direkt auf das Greifen mit offenem Vokabular zu Hause angewendet werden. Diese Robotermodelle erfordern keine zusätzliche Schulung oder Feinabstimmung.
- Wie Komponenten kombiniert werden, ist entscheidend: Forscher fanden heraus, dass sie mit einem vorab trainierten Modell mithilfe eines einfachen Zustandsmaschinenmodells ohne Training kombiniert werden können. Sie fanden auch heraus, dass der Einsatz von Heuristiken zum Ausgleich der physischen Einschränkungen des Roboters in der realen Welt zu höheren Erfolgsraten führte.
- Es gibt noch einige Herausforderungen: Angesichts der großen Herausforderung des Zero-Sample-Betriebs in jedem Haushalt hat OK-Robot auf der Grundlage früherer Arbeiten Verbesserungen vorgenommen: Durch die Analyse der Fehlermodi stellten sie fest, dass Roboter in visuellen Sprachmodellen von Bedeutung sind Es können Verbesserungen in der Modell- und Robotermorphologie vorgenommen werden, die die Leistung offener Wissensmanipulationsagenten direkt verbessern.
Um die Arbeit anderer Forscher im Bereich der Open-Knowledge-Robotik zu fördern und zu unterstützen, erklärte der Autor, dass er den Code und die Module von OK-Robot teilen werde. Weitere Informationen finden Sie unter: https://ok-robot.github.io.
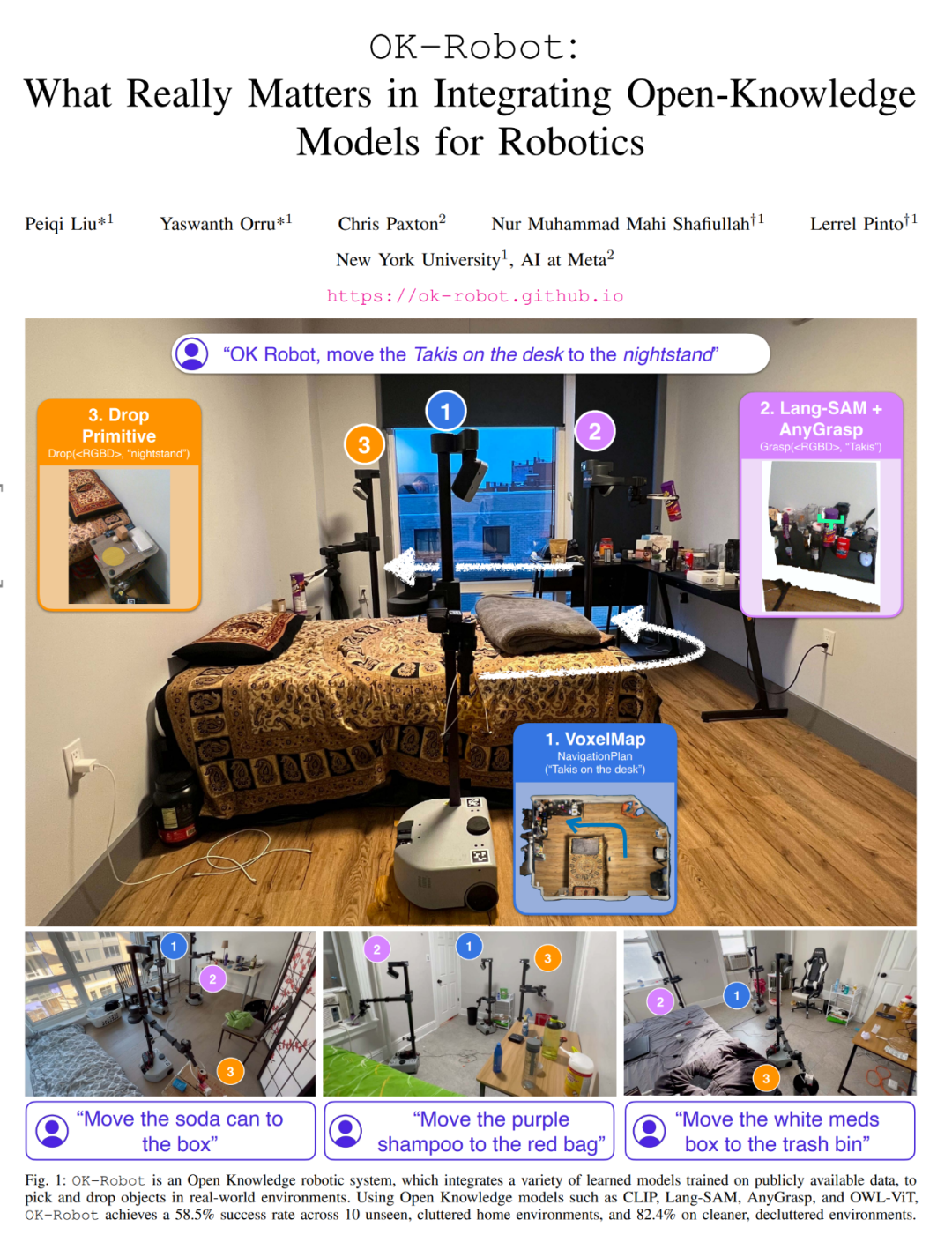
- Papiertitel: OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics
- Papierlink: https://arxiv.org/pdf/2401.12202.pdf
Technische Komponenten und Methoden
Diese Forschung löst hauptsächlich dieses Problem: Nehmen Sie A von B auf und legen Sie es auf C, wobei A ein Objekt ist und B und C sich irgendwo in der realen Umgebung befinden. Um dies zu erreichen, muss das vorgeschlagene System die folgenden Module umfassen: ein Objektnavigationsmodul mit offenem Vokabular, ein RGB-D-Grabbing-Modul mit offenem Vokabular und ein heuristisches Modul zum Freigeben oder Platzieren von Objekten (Dropheuristik).
Öffnen Sie die Vokabular-Objektnavigation
Scannen Sie zunächst den Raum. Open Vocabulary Object Navigation folgt dem CLIP-Fields-Ansatz und geht von einer Pre-Mapping-Phase des manuellen Scannens der häuslichen Umgebung mit einem iPhone aus. Bei diesem manuellen Scan wird einfach ein Heimvideo mit der Record3D-App auf einem iPhone aufgenommen, wodurch eine Reihe von RGB-D-Bildern mit Standorten erstellt werden.
Das Scannen jedes Raums dauert weniger als eine Minute. Sobald die Informationen gesammelt sind, wird das RGB-D-Bild zusammen mit der Kameraposition und -position zur Kartenerstellung in die Projektbibliothek exportiert. Die Aufnahme muss die Bodenoberfläche sowie Objekte und Behälter in der Umgebung erfassen.
Der nächste Schritt ist die Objekterkennung. Bei jedem gescannten Bild verarbeitet ein Objektdetektor mit offenem Vokabular den gescannten Inhalt. In diesem Artikel wird der OWL-ViT-Objektdetektor ausgewählt, da diese Methode bei vorläufigen Abfragen eine bessere Leistung erbringt. Wir wenden den Detektor auf jeden Frame an, extrahieren jeden Objektbegrenzungsrahmen, jede CLIP-Einbettung und jedes Detektorvertrauen und übergeben sie an das Objektspeichermodul des Navigationsmoduls.
Führen Sie dann eine objektzentrierte semantische Speicherung durch. In diesem Artikel wird VoxelMap verwendet, um diesen Schritt auszuführen. Insbesondere werden die von der Kamera erfassten Tiefenbilder und Posen verwendet, um die Objektmaske in reale Koordinaten zu projizieren. Auf diese Weise kann eine Punktwolke bereitgestellt werden, in der jeder Punkt eine Assoziation aufweist semantische Vektoren aus CLIP.
Gefolgt vom Abfragespeichermodul: Bei einer Sprachabfrage verwendet dieser Artikel den CLIP-Sprachencoder, um sie in semantische Vektoren umzuwandeln. Da jedes Voxel einem realen Ort im Haus zugeordnet ist, kann der Ort gefunden werden, an dem das Abfrageobjekt am wahrscheinlichsten gefunden wird, ähnlich wie in Abbildung 2 (a).
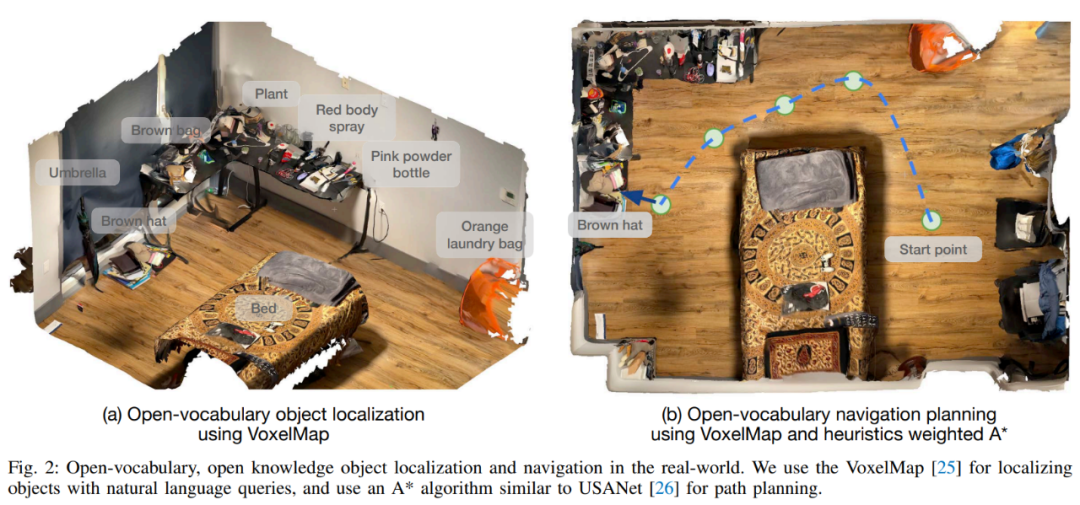
Bei Bedarf wird in diesem Artikel „A auf B“ als „A schließt B“ implementiert. Dazu wählt Abfrage A die ersten 10 Punkte aus und Abfrage B wählt die ersten 50 Punkte aus. Berechnen Sie dann den paarweisen euklidischen Abstand von 10 × 50 und wählen Sie den Punkt A aus, der dem kürzesten Abstand (A, B) zugeordnet ist.
Nach Abschluss des obigen Vorgangs besteht der nächste Schritt darin, zum Objekt in der realen Welt zu navigieren: Sobald die 3D-Positionskoordinaten in der realen Welt ermittelt wurden, können sie als Navigationsziel des Roboters zur Initialisierung verwendet werden Betriebsphase. Das Navigationsmodul muss den Roboter in Reichweite bringen, damit der Roboter dann das Zielobjekt manipulieren kann.
Greifen von Objekten aus der realen Welt durch Roboter
Im Gegensatz zur Navigation mit offenem Vokabular muss der Algorithmus zur Erfüllung der Greifaufgabe physisch mit beliebigen Objekten in der realen Welt interagieren, was diesen Teil noch mehr macht Schwierigkeit. Daher wird in diesem Artikel ein vorab trainiertes Greifmodell verwendet, um Greifgesten in der realen Welt zu generieren und VLM zum Filtern von Sprachbedingungen zu verwenden.
Das in diesem Artikel verwendete Modul zur Grifferzeugung ist AnyGrasp, das kollisionsfreie Griffe mithilfe paralleler Backengreifer in einer Szene anhand eines einzelnen RGB-Bilds und einer Punktwolke generiert.
AnyGrasp stellt die möglichen Griffe in der Szene bereit (Abbildung 3, Spalte 2), einschließlich Griffpunkt, Breite, Höhe, Tiefe und Griffwert, der das unkalibrierte Modellvertrauen in jedem Griff darstellt.

Griffe mithilfe linguistischer Abfragen filtern: Für von AnyGrasp erhaltene Griffvorschläge verwendet dieser Artikel LangSam zum Filtern von Griffen. Dieser Artikel projiziert alle vorgeschlagenen Griffpunkte auf das Bild und findet die Griffpunkte, die in die Objektmaske fallen (Abbildung 3, Spalte 4).
Griffausführung. Sobald der optimale Griff bestimmt ist (Abbildung 3, Spalte 5), kann eine einfache Pre-Greif-Methode verwendet werden, um das Zielobjekt zu greifen.
Heuristisches Modul zum Loslassen oder Platzieren von Objekten
Nach dem Greifen des Objekts geht es im nächsten Schritt darum, wo das Objekt platziert werden soll. Im Gegensatz zur Basisimplementierung von HomeRobot, bei der davon ausgegangen wird, dass der Ort, an dem das Objekt fallen gelassen wird, eine ebene Fläche ist, erweitert dieses Papier dies, um auch konkave Objekte wie Waschbecken, Behälter, Kisten und Taschen abzudecken.
Nachdem Navigation, Greifen und Platzierung alle vorhanden sind, geht es nur noch darum, sie zusammenzustellen. Die Methode kann direkt auf jedes neue Zuhause angewendet werden. Bei neuen Wohnumgebungen kann die Studie einen Raum in weniger als einer Minute scannen. Die Verarbeitung zu einer VoxelMap dauert dann weniger als fünf Minuten. Nach Fertigstellung kann der Roboter sofort am gewünschten Standort platziert und in Betrieb genommen werden. Von der Ankunft in einer neuen Umgebung bis zum Beginn des autonomen Betriebs darin benötigt das System durchschnittlich weniger als 10 Minuten, um seine erste Pick-and-Place-Aufgabe abzuschließen.
Experimente
In mehr als 10 Heimexperimenten erreichte OK-Robot eine Erfolgsquote von 58,5 % bei Pick-and-Place-Aufgaben.
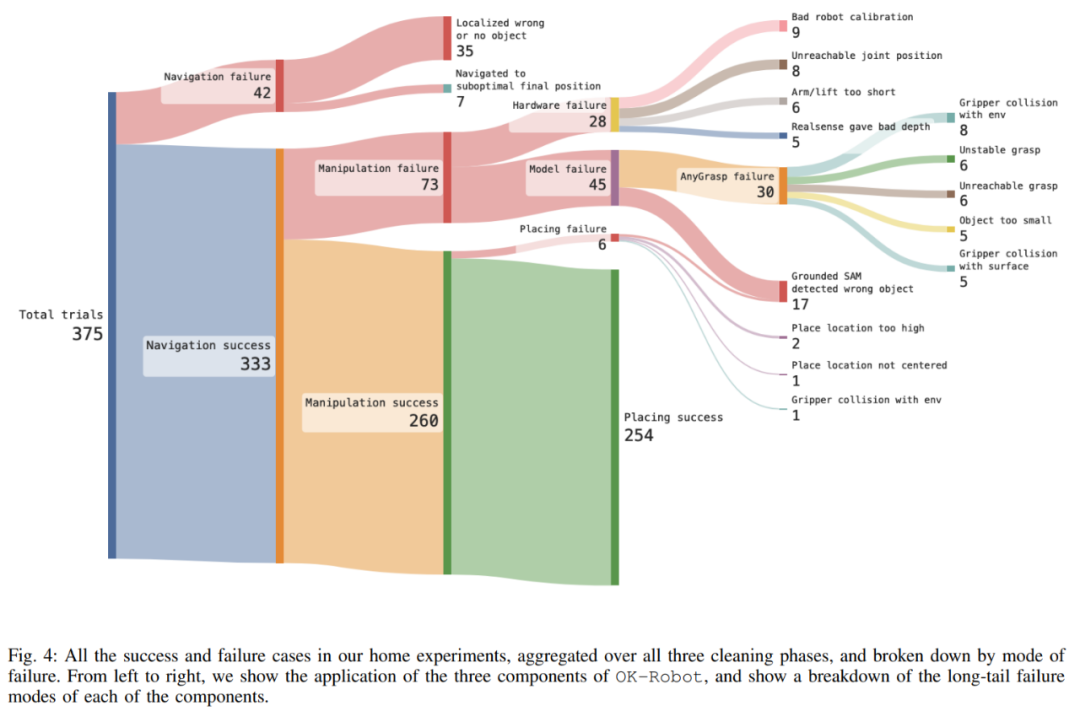
Die Studie führte auch eine eingehende Untersuchung von OK-Robot durch, um seine Fehlermodi besser zu verstehen. Die Studie ergab, dass die Hauptursache für das Versagen ein Betriebsversagen war. Nach sorgfältiger Beobachtung wurde jedoch festgestellt, dass die Ursache des Versagens durch das lange Heck verursacht wurde. Zu den drei Hauptursachen für das Versagen gehörte das Versagen beim Einholen Aus dem semantischen Gedächtnis geht hervor, dass der Ort, zu dem das richtige Objekt navigiert werden soll (9,3 %), die vom Manipulationsmodul erhaltene Pose schwierig zu vervollständigen ist (8,0 %), und Hardwaregründe (7,5 %).
Aus Abbildung 5 ist ersichtlich, dass die in OK-Robot verwendete VoxelMap etwas besser ist als andere semantische Speichermodule. Was das Scraping-Modul betrifft, übertrifft AnyGrasp andere Scraping-Methoden deutlich und übertrifft den besten Kandidaten (Top-Down-Scraping) relativ gesehen um fast 50 %. Die Tatsache, dass das auf Heuristiken basierende Top-Down-Crawling von HomeRobot die Open-Source-AnyGrasp-Basislinie und Contact-GraspNet übertrifft, zeigt jedoch, dass der Aufbau eines wirklich universellen Crawling-Modells weiterhin schwierig ist.
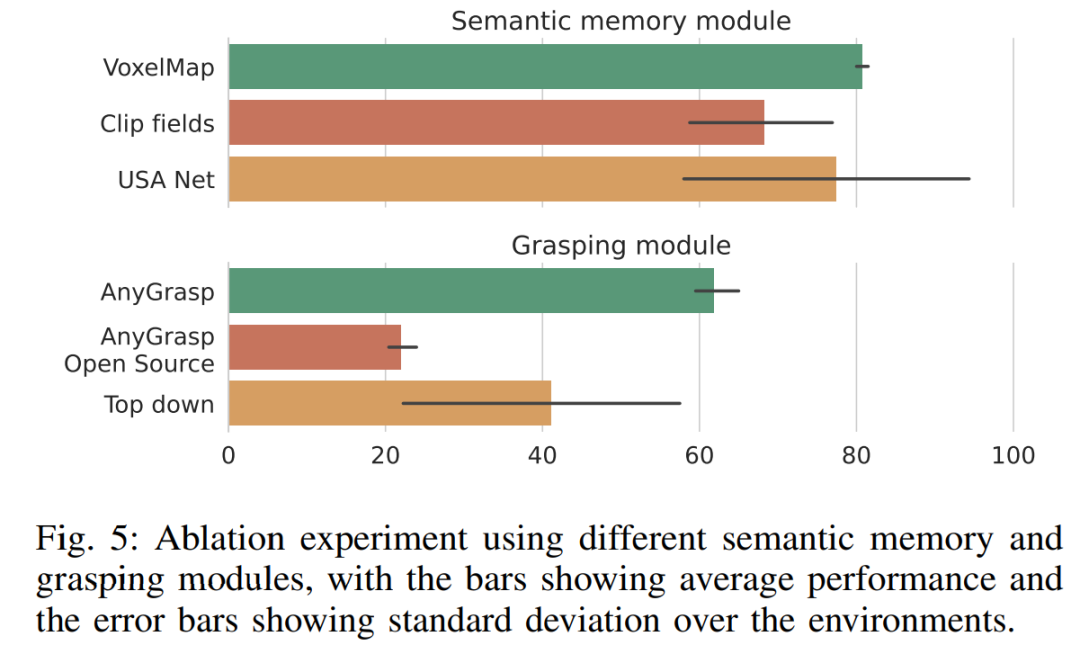
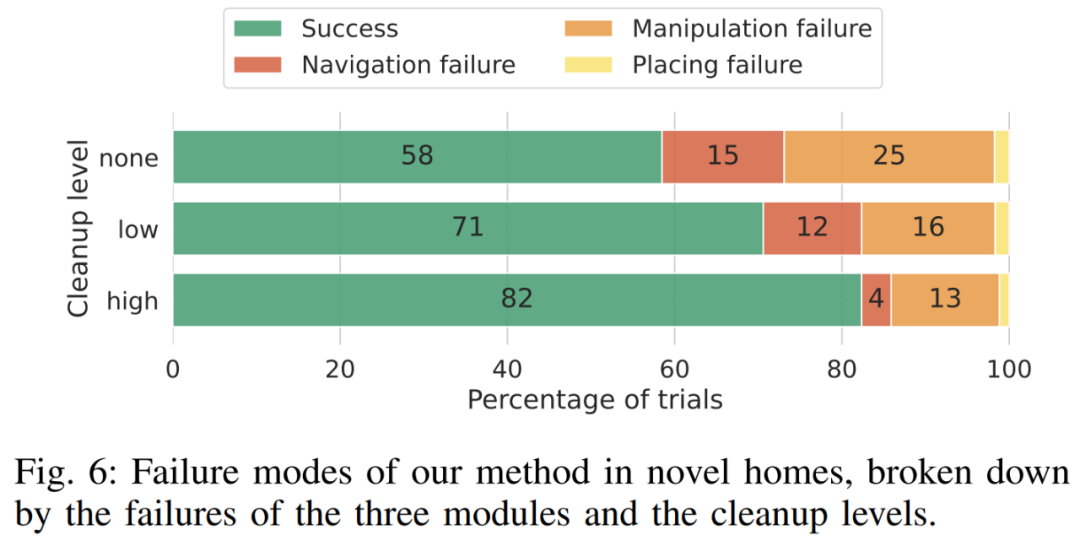
Abbildung 6 zeigt die vollständige Analyse des Versagens von OK-Robot in verschiedenen Phasen. Der Analyse zufolge erhöht sich die Navigationsgenauigkeit, wenn die Forscher die Umgebung bereinigen und verschwommene Objekte löschen, und die Gesamtfehlerrate sinkt von 15 % auf 12 % und sinkt schließlich auf 4 %. Ebenso verbesserte sich die Genauigkeit, als die Forscher die Umgebung von Unordnung befreiten, wobei die Fehlerquote von 25 Prozent auf 16 Prozent und schließlich auf 13 Prozent sank.
Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonOK-Robot entwickelt von Meta und der New York University: Teeausgießer-Roboter ist entstanden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!