
Heim >Technologie-Peripheriegeräte >KI >Pika, ein neues Open-Source-Framework der Universität Peking und Stanford, nutzt LLM zur Verbesserung des Verständnisses und bietet ein tieferes Verständnis des Diffusionsmodells komplexer Aufforderungswörter.
Pika, ein neues Open-Source-Framework der Universität Peking und Stanford, nutzt LLM zur Verbesserung des Verständnisses und bietet ein tieferes Verständnis des Diffusionsmodells komplexer Aufforderungswörter.

- 王林nach vorne
- 2024-01-24 18:33:18680Durchsuche
Pika Peking University und Stanford arbeiten zusammen, um Open Sourcedas neueste Text-Bild-Generierungs-/Bearbeitungs-Framework zu entwickeln!
Ohne zusätzliches Training kann das Diffusionsmodell über bessere Fähigkeiten zum schnellen Verstehen von Wörtern verfügen.
Bei langen und komplexen Aufforderungswörtern ist die Genauigkeit höher, die Details werden besser kontrolliert und die erzeugten Bilder sind natürlicher.
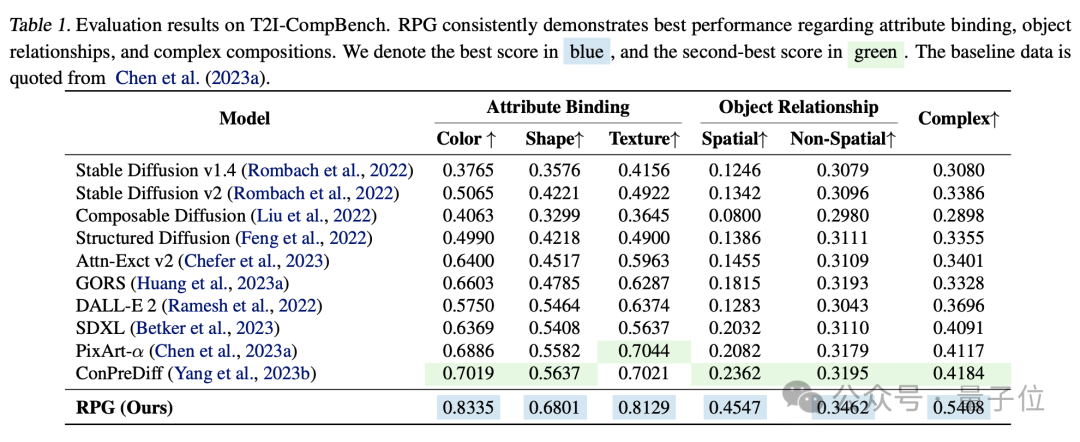
Der Effekt übertrifft die Modelle Dall·E 3 und SDXL mit der stärksten Bilderzeugung.
Zum Beispiel muss das Bild links und rechts zwei Schichten aus Eis und Feuer aufweisen, links Eisberge und rechts Vulkane.
SDXL erfüllte die Prompt-Word-Anforderungen überhaupt nicht und Dall·E 3 generierte keine Details des Vulkans.

Sie können auch sekundäre Bearbeitungen von Bildern durch schnelle Wortpaare generieren.
Dies ist das Text-Bild-Generierungs-/Bearbeitungs-Framework RPG (Recaption, Plan and Generate), das im Internet für hitzige Diskussionen gesorgt hat.

Es wurde gemeinsam von der Peking University, Stanford und Pika entwickelt. Zu den Autoren gehören Professor Cui Bin von der Fakultät für Informatik der Universität Peking, Chenlin Meng, Mitbegründer und CTO von Pika usw.
Der aktuelle Framework-Code ist Open Source und mit verschiedenen multimodalen Großmodellen (wie MiniGPT-4) und Diffusionsmodell-Backbone-Netzwerken (wie ControlNet) kompatibel.
Verwenden Sie multimodale große Modelle zur Verbesserung
Lange Zeit waren Diffusionsmodelle beim Verständnis komplexer Aufforderungswörter relativ schwach.
Einige bestehende Verbesserungsmethoden erzielen am Ende entweder keine ausreichenden Ergebnisse oder erfordern zusätzliche Schulungen.
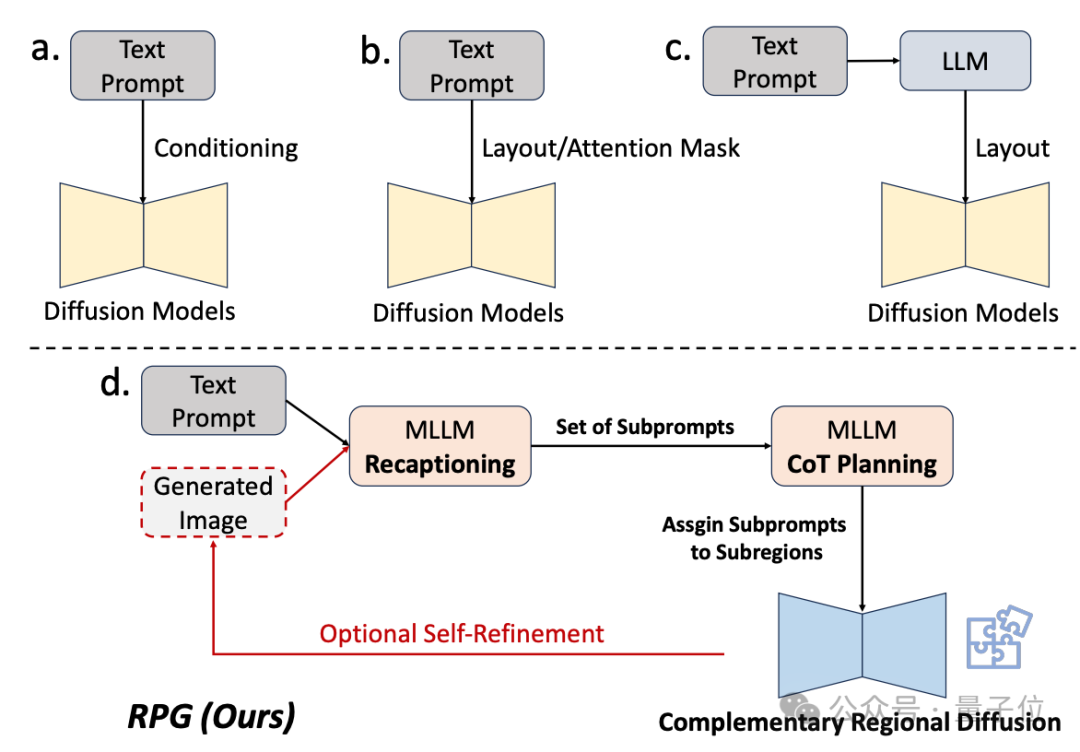
Daher nutzt das Forschungsteam die Verständnisfähigkeit multimodaler Großmodelle, um die Kombination und Steuerbarkeit des Diffusionsmodells zu verbessern.
Wie aus dem Namen des Frameworks hervorgeht, ermöglicht es dem Modell, „neu zu beschreiben, zu planen und zu generieren“.
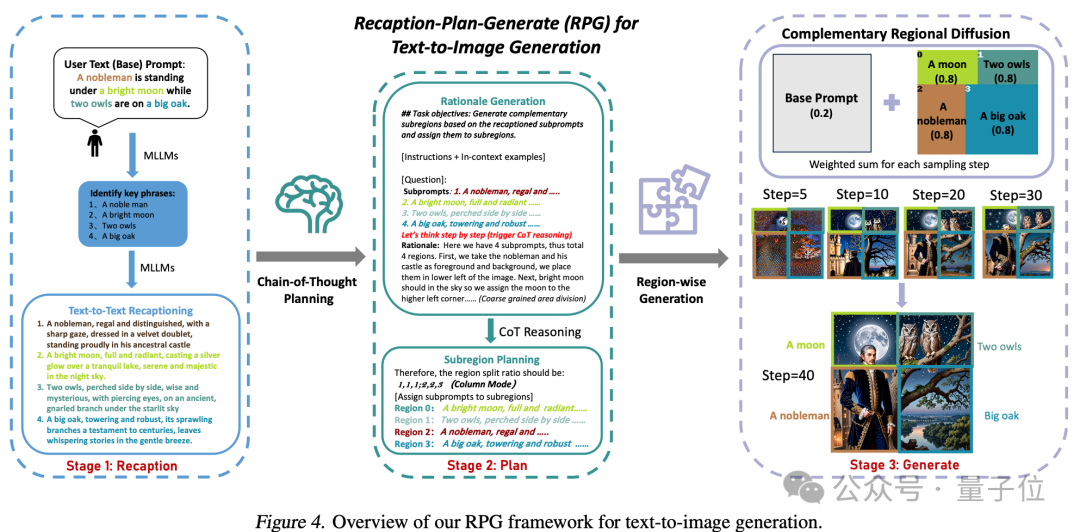
Die Kernstrategie dieser Methode besteht aus drei Aspekten:
1. Multimodale Zusammenfassung: Verwenden Sie ein großes Modell, um komplexe Texteingabeaufforderungen in mehrere Untereingabeaufforderungen zu zerlegen und jede Untereingabeaufforderung zur Verbesserung detailliert zu aktualisieren die Fähigkeit des Diffusionsmodells, Aufforderungswörter zu verstehen.
2. Chain-of-Thought-Planung (Chain-of-Thought-Planung): Nutzen Sie die Chain-of-Thought-Planung multimodaler großer Modelle, um den Bildraum in komplementäre Unterbereiche zu unterteilen und verschiedene Unterbereiche abzugleichen -Eingabeaufforderungen für jede Unterregion, komplexe Generierungsaufgaben in mehrere einfachere Generierungsaufgaben zerlegen.

3. Komplementäre regionale Verbreitung: Nach der Aufteilung des Raums generieren nicht überlappende Bereiche Bilder basierend auf Unteraufforderungen und fügen sie dann zusammen.
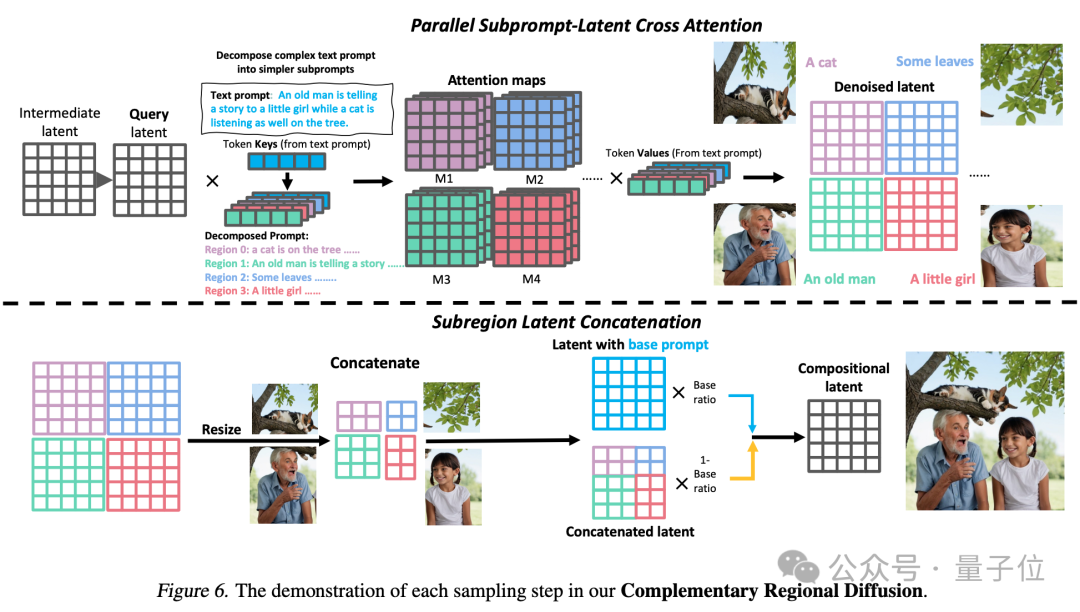 Abschließend wird ein Bild generiert, das den Anforderungen an prompte Wörter besser entspricht.
Abschließend wird ein Bild generiert, das den Anforderungen an prompte Wörter besser entspricht.
 Das RPG-Framework kann auch Haltung, Tiefe und andere Informationen zur Bildgenerierung nutzen.
Das RPG-Framework kann auch Haltung, Tiefe und andere Informationen zur Bildgenerierung nutzen.
Im Vergleich zu ControlNet kann RPG die Eingabeaufforderungswörter weiter aufteilen.
Benutzereingabe: In einem hellen Raum stand mit geschlossenen Augen ein wunderschönes schwarzhaariges Mädchen, das ein champagnerfarbenes, langärmliges Abendkleid trug. Auf der linken Seite des Raumes stand eine zarte blaue Vase mit rosa Rosen und auf der rechten einige leuchtend weiße Rosen.
Einfache Aufforderungsworte: Ein schönes Mädchen steht in ihrem hellen Zimmer.
Bereich 0: Eine zarte blaue Vase gefüllt mit rosa Rosen
Bereich 1: Ein wunderschönes brünettes Mädchen, das mit geschlossenen Augen ein langärmliges Champagnerkleid trägt.
Bereich 2: Einige leuchtend weiße Rosen.
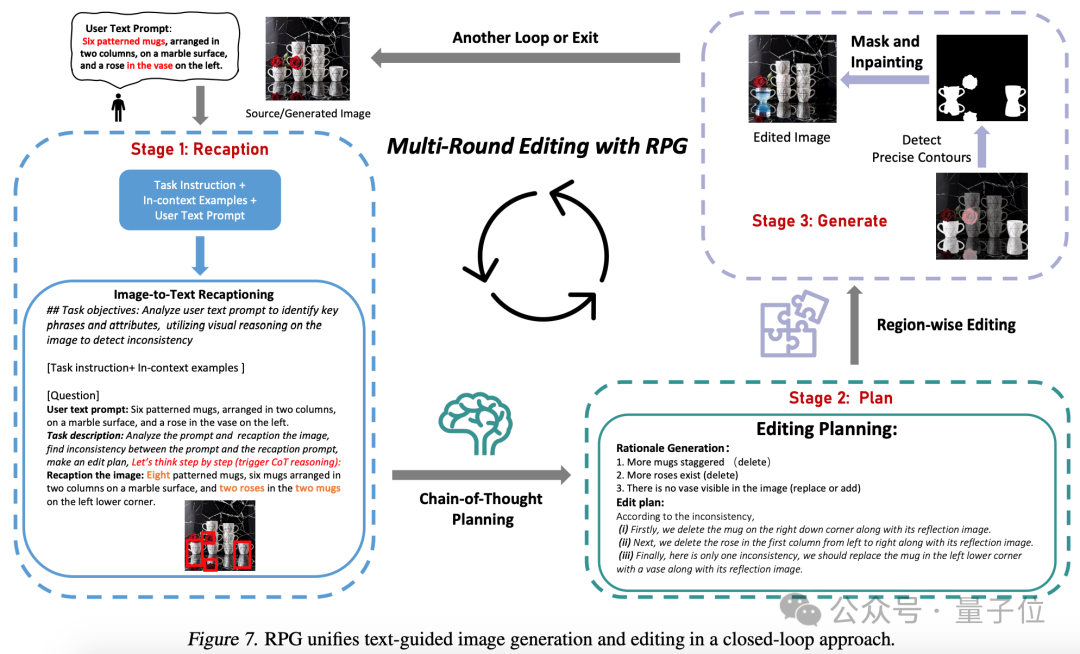
 kann auch eine Bilderzeugung und -bearbeitung im geschlossenen Regelkreis erreichen.
kann auch eine Bilderzeugung und -bearbeitung im geschlossenen Regelkreis erreichen.
Aus dem experimentellen Vergleich übertrifft RPG andere Bilderzeugungsmodelle in Dimensionen wie Farbe, Form, Raum und Textgenauigkeit.
Forschungsteam
Diese Studie hat zwei Co-Autoren, Ling Yang und Zhaochen Yu, beide von der Universität Peking.
Zu den teilnehmenden Autoren gehört Chenlin Meng, Mitbegründer und CTO des KI-Startups Pika.
Sie hat einen Doktortitel in Informatik von Stanford und verfügt über umfangreiche akademische Erfahrung in den Bereichen Computer Vision und 3D-Vision. Sie hat am Denoising Diffusion Implicit Model (DDIM)-Artikel mitgewirkt, der inzwischen mehr als 1.700 Zitate in einem einzigen Artikel enthält. Eine Reihe von Forschungsartikeln zum Thema generative KI wurden auf Top-Konferenzen wie ICLR, NeurIPS, CVPR und ICML veröffentlicht und viele von ihnen wurden in Oral aufgenommen.
Letztes Jahr wurde Pika mit seinem KI-Videogenerierungsprodukt Pika 1.0 sofort ein Hit. Der Hintergrund seiner Gründung durch zwei chinesische Doktorandinnen aus Stanford machte es noch auffälliger.

△Links ist Guo Wenjing (Pika-CEO), rechts Chenlin Meng
An der Forschung beteiligt ist auch Professor Cui Bin, stellvertretender Dekan der Fakultät für Informatik der Universität Peking außerdem Direktor des Institute of Data Science and Engineering.

Papieradresse: https://arxiv.org/abs/2401.11708
Codeadresse: https://github.com/YangLing0818/RPG-DiffusionMaster
Das obige ist der detaillierte Inhalt vonPika, ein neues Open-Source-Framework der Universität Peking und Stanford, nutzt LLM zur Verbesserung des Verständnisses und bietet ein tieferes Verständnis des Diffusionsmodells komplexer Aufforderungswörter.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Gründe, warum KI nicht in Echtzeit färben kann
- Wie kann das Problem gelöst werden, dass die Attributleiste oben in der KI fehlt?
- Was sind die wichtigsten technischen Indikatoren von LCD-Monitoren, die nicht im Lieferumfang enthalten sind?
- Was ist einer der wichtigsten technischen Indikatoren eines Monitors?
- Welche Etappen hat die Datenmanagement-Technologie bisher durchlaufen?