Artificial Intelligence Feedback (AIF) wird RLHF ersetzen?
Im Bereich großer Modelle ist die Feinabstimmung ein wichtiger Schritt zur Verbesserung der Modellleistung. Da die Anzahl der großen Open-Source-Modelle allmählich zunimmt, haben die Menschen viele Methoden zur Feinabstimmung zusammengefasst, von denen einige gute Ergebnisse erzielt haben. Kürzlich nutzten Forscher von Meta und der New York University die „Selbstbelohnungsmethode“, um großen Modellen die Generierung ihrer eigenen Feinabstimmungsdaten zu ermöglichen, was für die Menschen einen neuen Schock auslöste. Mit der neuen Methode hat der Autor Llama 2 70B in drei Iterationen verfeinert, und das generierte Modell übertraf eine Reihe bestehender wichtiger großer Modelle in der AlpacaEval 2.0-Rangliste, darunter Claude 2, Gemini Pro und GPT -4 . So erregte das Papier bereits wenige Stunden nach seiner Veröffentlichung auf arXiv die Aufmerksamkeit der Menschen. Obwohl die Methode noch nicht Open Source ist, wird davon ausgegangen, dass die in der Arbeit verwendete Methode klar beschrieben ist und nicht schwer zu reproduzieren sein sollte. 
Es ist bekannt, dass die Optimierung großer Sprachmodelle (LLM) mithilfe menschlicher Präferenzdaten die Befehlsverfolgungsleistung vorab trainierter Modelle erheblich verbessern kann. In der GPT-Reihe schlug OpenAI eine Standardmethode für Human Feedback Reinforcement Learning (RLHF) vor, die es großen Modellen ermöglicht, Belohnungsmodelle aus menschlichen Vorlieben zu lernen und die Belohnungsmodelle dann einzufrieren und zum Trainieren von LLM mithilfe von Reinforcement Learning zu verwenden Methode hat einen großen Erfolg erzielt. Eine neue Idee, die kürzlich aufgetaucht ist, besteht darin, das Training von Belohnungsmodellen vollständig zu vermeiden und menschliche Präferenzen direkt zum Training von LLM zu nutzen, wie beispielsweise die direkte Präferenzoptimierung (DPO). In beiden oben genannten Fällen wird die Abstimmung durch die Größe und Qualität der menschlichen Präferenzdaten beeinträchtigt, und im Fall von RLHF wird die Qualität der Abstimmung auch durch die Qualität der daraus trainierten eingefrorenen Belohnungsmodelle beeinträchtigt. In einer neuen Arbeit in Meta schlagen die Autoren vor, ein sich selbst verbesserndes Belohnungsmodell zu trainieren, das nicht eingefroren, sondern während der LLM-Optimierung kontinuierlich aktualisiert wird, um diesen Engpass zu vermeiden. Der Schlüssel zu diesem Ansatz besteht darin, einen Agenten mit allen Fähigkeiten zu entwickeln, die während des Trainings erforderlich sind (anstatt in Belohnungsmodelle und Sprachmodelle aufzuteilen), was ein Vortraining von Aufgaben zur Befolgung von Anweisungen und ein Training mit mehreren Aufgaben ermöglicht Trainieren Sie gleichzeitig mehrere Aufgaben, um eine Aufgabenmigration zu erreichen. Also stellen die Autoren ein selbstbelohnendes Sprachmodell vor, dessen Agenten sowohl die Anweisungen des Modells befolgen und Antworten auf gegebene Eingabeaufforderungen generieren als auch neue Anweisungen basierend auf Beispielen generieren und bewerten können, um sie ihren eigenen hinzuzufügen Trainingssets. Die neue Methode verwendet ein Framework ähnlich dem iterativen DPO, um diese Modelle zu trainieren. Ausgehend von einem Seed-Modell, wie in Abbildung 1 dargestellt, gibt es in jeder Iteration einen Prozess zur Erstellung von Selbstanweisungen, bei dem das Modell Kandidatenantworten für die neu erstellten Eingabeaufforderungen generiert und Belohnungen dann von demselben Modell zugewiesen werden. Letzteres wird durch die Aufforderung durch LLM-as-a-A-Judge erreicht, die auch als Aufgabe zur Befolgung von Anweisungen angesehen werden kann. Aus den generierten Daten wird ein Präferenzdatensatz erstellt und die nächste Iteration des Modells über DPO trainiert.
Selbstbelohnendes SprachmodellDer vom Autor vorgeschlagene Ansatz geht zunächst davon aus, dass auf ein grundlegendes vorab trainiertes Sprachmodell und eine kleine Menge menschlich kommentierter Startdaten zugegriffen werden kann, und erstellt dann ein Modell zielt darauf ab, beide Fähigkeiten zu besitzen: 1. Befolgen Sie die Anweisungen: Geben Sie Eingabeaufforderungen, die die Anfrage des Benutzers beschreiben, und generieren Sie qualitativ hochwertige, hilfreiche (und harmlose) Antworten. 2. Erstellung von Selbstanweisungen: Möglichkeit, anhand von Beispielen neue Anweisungen zu generieren und auszuwerten, um sie Ihrem eigenen Trainingssatz hinzuzufügen. Diese Fähigkeiten werden verwendet, um dem Modell die Selbstausrichtung zu ermöglichen, d. h. sie sind die Komponenten, die verwendet werden, um sich mithilfe von Artificial Intelligence Feedback (AIF) iterativ selbst zu trainieren. Bei der Erstellung von Selbstanweisungen geht es darum, Kandidatenantworten zu generieren und dann das Modell selbst seine Qualität beurteilen zu lassen, d. h. es fungiert als sein eigenes Belohnungsmodell und ersetzt so die Notwendigkeit eines externen Modells. Dies wird durch den LLM-as-a-Judge-Mechanismus erreicht [Zheng et al., 2023b], d. h. durch die Formulierung der Antwortbewertung als eine Anweisung folgende Aufgabe. Als Trainingssatz wurden diese selbst erstellten AIF-Präferenzdaten verwendet. Beim Feinabstimmungsprozess wird also für beide Rollen das gleiche Modell verwendet: als „Lernender“ und als „Richter“. Basierend auf der neuen Rolle des Richters kann das Modell die Leistung durch kontextbezogene Feinabstimmung weiter verbessern. Der gesamte Selbstausrichtungsprozess ist ein iterativer Prozess, der durch die Erstellung einer Reihe von Modellen erfolgt, von denen jedes eine Verbesserung gegenüber dem vorherigen darstellt. Wichtig hierbei ist, dass das Modell sowohl seine generativen Fähigkeiten verbessern als auch denselben generativen Mechanismus wie sein eigenes Belohnungsmodell verwenden kann. Dies bedeutet, dass sich das Belohnungsmodell selbst durch diese Iterationen verbessern kann, was mit den inhärenten Kriterien von Belohnungsmodellen übereinstimmt. Es gibt Unterschiede in der Herangehensweise. Forscher glauben, dass dieser Ansatz das Potenzial dieser Lernmodelle erhöhen kann, sich in Zukunft zu verbessern und restriktive Engpässe zu beseitigen. Abbildung 1 zeigt einen Überblick über die Methode.
In dem Experiment verwendete der Forscher Llama 2 70B als grundlegendes Vortrainingsmodell. Sie fanden heraus, dass die LLM-Ausrichtung mit Selbstbelohnung nicht nur die Leistung beim Befolgen von Anweisungen verbesserte, sondern auch die Fähigkeiten zur Belohnungsmodellierung im Vergleich zum Basis-Seed-Modell verbesserte. Das bedeutet, dass das Modell beim iterativen Training in der Lage ist, sich in einer bestimmten Iteration einen Präferenzdatensatz von besserer Qualität zu liefern als in der vorherigen Iteration. Während dieser Effekt in der realen Welt tendenziell gesättigt ist, bietet er die interessante Möglichkeit, dass das resultierende Belohnungsmodell (und damit das LLM) besser ist als ein Modell, das ausschließlich auf von Menschen geschriebenen Rohdaten trainiert wird. In Bezug auf die Fähigkeit, Anweisungen zu befolgen, sind die experimentellen Ergebnisse in Abbildung 3 dargestellt: Die Forscher bewerteten das Selbstbelohnungsmodell auf der AlpacaEval 2-Rangliste und die Ergebnisse sind in Tabelle 1 aufgeführt. Sie kamen zu derselben Schlussfolgerung wie bei der Vergleichsbewertung, das heißt, die Erfolgsquote der Trainingsiterationen war höher als die von GPT4-Turbo, von 9,94 % in Iteration 1 über 15,38 % in Iteration 2 bis hin zu 20,44 % Iteration 3. Mittlerweile übertrifft das Modell Iteration 3 viele bestehende Modelle, darunter Claude 2, Gemini Pro und GPT4 0613.
Die Ergebnisse der Belohnungsmodellierung sind in Tabelle 2 aufgeführt. Die Schlussfolgerungen umfassen:
EFT hat sich gegenüber der SFT-Basislinie verbessert. Im Vergleich zur alleinigen Verwendung von IFT haben sich alle fünf Messindikatoren verbessert. Beispielsweise stieg die paarweise Genauigkeitsübereinstimmung mit Menschen von 65,1 % auf 78,7 %.
Verbessern Sie die Fähigkeiten zur Belohnungsmodellierung durch Selbsttraining. Nach einer Runde Selbstbelohnungstraining wird die Fähigkeit des Modells, Selbstbelohnungen für die nächste Iteration bereitzustellen, verbessert und seine Fähigkeit, Anweisungen zu befolgen, wird ebenfalls verbessert.
Die Bedeutung von LLMas-a-Judge-Tipps. Die Forscher verwendeten verschiedene Eingabeaufforderungsformate und stellten fest, dass LLMas-a-Judge-Eingabeaufforderungen bei Verwendung der SFT-Basislinie eine höhere paarweise Genauigkeit aufwiesen.
Der Autor glaubt, dass die Selbstbelohnungstrainingsmethode nicht nur die Fähigkeit des Modells zur Befehlsverfolgung verbessert, sondern auch die Fähigkeit des Modells zur Belohnungsmodellierung in Iterationen. Obwohl dies nur eine vorläufige Studie ist, scheint es sich um eine spannende Forschungsrichtung zu handeln. Solche Modelle können Belohnungen in zukünftigen Iterationen besser zuweisen, um die Einhaltung von Anweisungen zu verbessern und einen harmlosen Zyklus zu erreichen. Diese Methode eröffnet auch gewisse Möglichkeiten für komplexere Beurteilungsmethoden. Beispielsweise können große Modelle die Genauigkeit ihrer Antworten überprüfen, indem sie eine Datenbank durchsuchen, was zu einer genaueren und zuverlässigeren Ausgabe führt. Referenzinhalt: https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_lingual_models_meta_2024/Das obige ist der detaillierte Inhalt vonGroße Modelle unter Selbstbelohnung: Llama2 optimiert sich selbst durch Meta-Lernen und übertrifft die Leistung von GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!







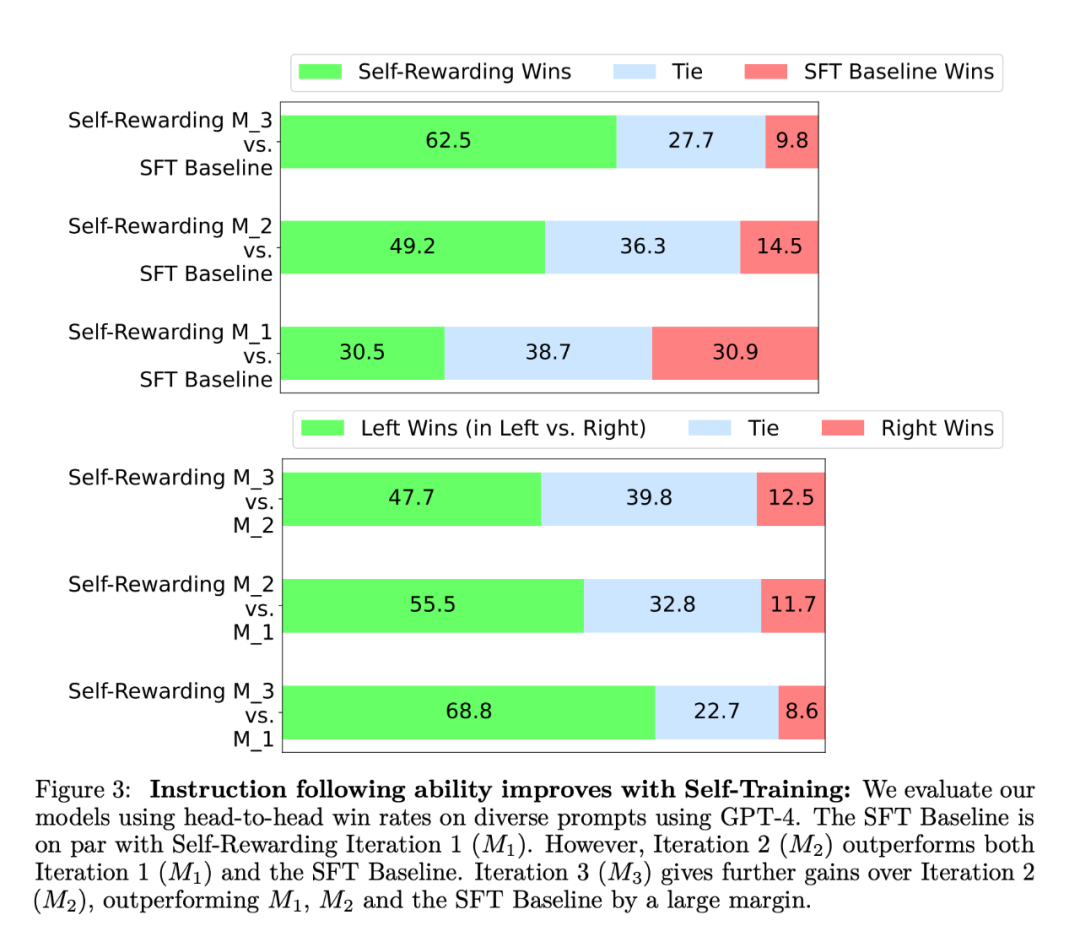 Die Forscher bewerteten das Selbstbelohnungsmodell auf der AlpacaEval 2-Rangliste und die Ergebnisse sind in Tabelle 1 aufgeführt. Sie kamen zu derselben Schlussfolgerung wie bei der Vergleichsbewertung, das heißt, die Erfolgsquote der Trainingsiterationen war höher als die von GPT4-Turbo, von 9,94 % in Iteration 1 über 15,38 % in Iteration 2 bis hin zu 20,44 % Iteration 3. Mittlerweile übertrifft das Modell Iteration 3 viele bestehende Modelle, darunter Claude 2, Gemini Pro und GPT4 0613.
Die Forscher bewerteten das Selbstbelohnungsmodell auf der AlpacaEval 2-Rangliste und die Ergebnisse sind in Tabelle 1 aufgeführt. Sie kamen zu derselben Schlussfolgerung wie bei der Vergleichsbewertung, das heißt, die Erfolgsquote der Trainingsiterationen war höher als die von GPT4-Turbo, von 9,94 % in Iteration 1 über 15,38 % in Iteration 2 bis hin zu 20,44 % Iteration 3. Mittlerweile übertrifft das Modell Iteration 3 viele bestehende Modelle, darunter Claude 2, Gemini Pro und GPT4 0613. 