
 Backend-EntwicklungPython-TutorialWie man mit Python die KI trainiert, das Snake-Spiel zu spielen
Backend-EntwicklungPython-TutorialWie man mit Python die KI trainiert, das Snake-Spiel zu spielen
Dies ist eine einfache Anleitung, wie man mithilfe von Reinforcement Learning einer KI beibringt, das Snake-Spiel zu spielen. Der Artikel zeigt Schritt für Schritt, wie man eine benutzerdefinierte Spielumgebung einrichtet und die in Python standardisierte Stable-Baselines3-Algorithmusbibliothek verwendet, um die KI für das Spielen von Snake zu trainieren.
In diesem Projekt verwenden wir Stable-Baselines3, eine standardisierte Bibliothek, die eine benutzerfreundliche PyTorch-basierte Implementierung von Reinforcement Learning (RL)-Algorithmen ermöglicht.
Zunächst richten Sie die Umgebung ein. Es gibt viele integrierte Spielumgebungen in der Stable-Baselines-Bibliothek. Hier verwenden wir eine modifizierte Version des klassischen Snake, mit zusätzlichen kreuz und quer verlaufenden Wänden in der Mitte.
Ein besserer Belohnungsplan wäre, nur Schritte zu belohnen, die dem Essen näher kommen. Hier ist Vorsicht geboten, denn die Schlange kann immer noch nur lernen, im Kreis zu laufen, sich bei der Annäherung an Futter eine Belohnung zu holen, sich dann umzudrehen und zurückzukommen. Um dies zu vermeiden, müssen wir auch eine gleichwertige Strafe für den Verzicht auf Nahrungsmittel verhängen, das heißt, wir müssen sicherstellen, dass der Nettogewinn im geschlossenen Kreislauf Null ist. Wir müssen auch eine Strafe für das Auftreffen auf Wände einführen, da sich eine Schlange in manchen Fällen dafür entscheidet, gegen eine Wand zu schlagen, um näher an ihr Futter heranzukommen.
Die meisten Algorithmen für maschinelles Lernen sind recht komplex und schwer zu implementieren. Glücklicherweise implementiert Stable-Baselines3 bereits mehrere hochmoderne Algorithmen, die uns zur Verfügung stehen. Im Beispiel verwenden wir Proximal Policy Optimization (PPO). Wir müssen zwar nicht im Detail wissen, wie der Algorithmus funktioniert (sehen Sie sich dieses Erklärvideo an, wenn Sie interessiert sind), aber wir müssen ein grundlegendes Verständnis davon haben, was seine Hyperparameter sind und was sie tun. Glücklicherweise gibt es bei PPO nur wenige davon und wir werden Folgendes verwenden:
learning_rate: Legt fest, wie groß die Schritte für Richtlinienaktualisierungen sind, genau wie bei anderen maschinellen Lernszenarien. Wenn Sie den Wert zu hoch einstellen, kann der Algorithmus daran gehindert werden, die richtige Lösung zu finden, oder ihn sogar in eine Richtung drängen, von der er sich nie wieder erholen kann. Wenn Sie den Wert zu niedrig einstellen, dauert das Training länger. Ein gängiger Trick besteht darin, eine Zeitplanerfunktion zu verwenden, um es während des Trainings anzupassen.
Gamma: Rabattfaktor für zukünftige Belohnungen, zwischen 0 (nur unmittelbare Belohnungen sind wichtig) und 1 (zukünftige Belohnungen haben den gleichen Wert wie unmittelbare Belohnungen). Um den Trainingseffekt aufrechtzuerhalten, ist es am besten, ihn über 0,9 zu halten.
clip_range1+-clip_range: Eine wichtige Funktion von PPO, die dafür sorgt, dass sich das Modell während des Trainings nicht wesentlich ändert. Die Reduzierung hilft bei der Feinabstimmung des Modells in späteren Trainingsphasen.
ent_coef: Je höher sein Wert, desto mehr wird der Algorithmus dazu ermutigt, verschiedene nicht optimale Aktionen zu untersuchen, was dem Schema helfen kann, lokale Belohnungsmaxima zu umgehen.
Im Allgemeinen beginnen Sie einfach mit den Standard-Hyperparametern.
Die nächsten Schritte bestehen darin, einige vorgegebene Schritte zu trainieren, dann selbst zu sehen, wie der Algorithmus funktioniert, und dann mit den neuen möglichen Parametern, die die beste Leistung erbringen, von vorne zu beginnen. Hier zeichnen wir die Belohnungen für verschiedene Trainingszeiten auf.
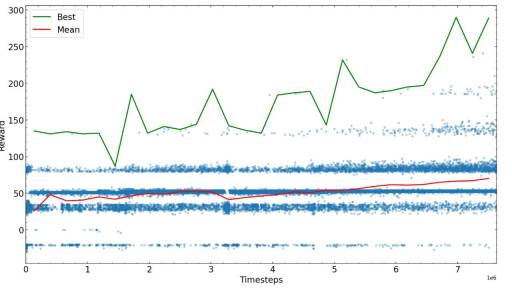
Nach genügend Schritten konvergiert der Schlangentrainingsalgorithmus zu einem bestimmten Belohnungswert. Sie können das Training abschließen oder versuchen, die Parameter zu verfeinern und mit dem Training fortzufahren.
Die zum Erreichen der maximal möglichen Belohnung erforderlichen Trainingsschritte hängen stark vom Problem, dem Belohnungsschema und den Hyperparametern ab. Daher wird empfohlen, vor dem Training des Algorithmus eine Optimierung durchzuführen. Am Ende des Beispiels zum Trainieren der KI für das Schlangenspiel stellten wir fest, dass die KI in der Lage war, Nahrung im Labyrinth zu finden und eine Kollision mit dem Schwanz zu vermeiden.
Das obige ist der detaillierte Inhalt vonWie man mit Python die KI trainiert, das Snake-Spiel zu spielen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python lernen: Ist 2 Stunden tägliches Studium ausreichend?Apr 18, 2025 am 12:22 AM
Python lernen: Ist 2 Stunden tägliches Studium ausreichend?Apr 18, 2025 am 12:22 AMIst es genug, um Python für zwei Stunden am Tag zu lernen? Es hängt von Ihren Zielen und Lernmethoden ab. 1) Entwickeln Sie einen klaren Lernplan, 2) Wählen Sie geeignete Lernressourcen und -methoden aus, 3) praktizieren und prüfen und konsolidieren Sie praktische Praxis und Überprüfung und konsolidieren Sie und Sie können die Grundkenntnisse und die erweiterten Funktionen von Python während dieser Zeit nach und nach beherrschen.
 Python für die Webentwicklung: SchlüsselanwendungenApr 18, 2025 am 12:20 AM
Python für die Webentwicklung: SchlüsselanwendungenApr 18, 2025 am 12:20 AMZu den wichtigsten Anwendungen von Python in der Webentwicklung gehören die Verwendung von Django- und Flask -Frameworks, API -Entwicklung, Datenanalyse und Visualisierung, maschinelles Lernen und KI sowie Leistungsoptimierung. 1. Django und Flask Framework: Django eignet sich für die schnelle Entwicklung komplexer Anwendungen, und Flask eignet sich für kleine oder hochmobile Projekte. 2. API -Entwicklung: Verwenden Sie Flask oder Djangorestframework, um RESTFUFFUPI zu erstellen. 3. Datenanalyse und Visualisierung: Verwenden Sie Python, um Daten zu verarbeiten und über die Webschnittstelle anzuzeigen. 4. Maschinelles Lernen und KI: Python wird verwendet, um intelligente Webanwendungen zu erstellen. 5. Leistungsoptimierung: optimiert durch asynchrones Programmieren, Caching und Code
 Python vs. C: Erforschung von Leistung und Effizienz erforschenApr 18, 2025 am 12:20 AM
Python vs. C: Erforschung von Leistung und Effizienz erforschenApr 18, 2025 am 12:20 AMPython ist in der Entwicklungseffizienz besser als C, aber C ist in der Ausführungsleistung höher. 1. Pythons prägnante Syntax und reiche Bibliotheken verbessern die Entwicklungseffizienz. 2. Die Kompilierungsmerkmale von Compilation und die Hardwarekontrolle verbessern die Ausführungsleistung. Bei einer Auswahl müssen Sie die Entwicklungsgeschwindigkeit und die Ausführungseffizienz basierend auf den Projektanforderungen abwägen.
 Python in Aktion: Beispiele in realer WeltApr 18, 2025 am 12:18 AM
Python in Aktion: Beispiele in realer WeltApr 18, 2025 am 12:18 AMZu den realen Anwendungen von Python gehören Datenanalysen, Webentwicklung, künstliche Intelligenz und Automatisierung. 1) In der Datenanalyse verwendet Python Pandas und Matplotlib, um Daten zu verarbeiten und zu visualisieren. 2) In der Webentwicklung vereinfachen Django und Flask Frameworks die Erstellung von Webanwendungen. 3) Auf dem Gebiet der künstlichen Intelligenz werden Tensorflow und Pytorch verwendet, um Modelle zu bauen und zu trainieren. 4) In Bezug auf die Automatisierung können Python -Skripte für Aufgaben wie das Kopieren von Dateien verwendet werden.
 Pythons Hauptnutzung: ein umfassender ÜberblickApr 18, 2025 am 12:18 AM
Pythons Hauptnutzung: ein umfassender ÜberblickApr 18, 2025 am 12:18 AMPython wird häufig in den Bereichen Data Science, Web Development und Automation Scripting verwendet. 1) In der Datenwissenschaft vereinfacht Python die Datenverarbeitung und -analyse durch Bibliotheken wie Numpy und Pandas. 2) In der Webentwicklung ermöglichen die Django- und Flask -Frameworks Entwicklern, Anwendungen schnell zu erstellen. 3) In automatisierten Skripten machen Pythons Einfachheit und Standardbibliothek es ideal.
 Der Hauptzweck von Python: Flexibilität und BenutzerfreundlichkeitApr 17, 2025 am 12:14 AM
Der Hauptzweck von Python: Flexibilität und BenutzerfreundlichkeitApr 17, 2025 am 12:14 AMDie Flexibilität von Python spiegelt sich in Multi-Paradigm-Unterstützung und dynamischen Typsystemen wider, während eine einfache Syntax und eine reichhaltige Standardbibliothek stammt. 1. Flexibilität: Unterstützt objektorientierte, funktionale und prozedurale Programmierung und dynamische Typsysteme verbessern die Entwicklungseffizienz. 2. Benutzerfreundlichkeit: Die Grammatik liegt nahe an der natürlichen Sprache, die Standardbibliothek deckt eine breite Palette von Funktionen ab und vereinfacht den Entwicklungsprozess.
 Python: Die Kraft der vielseitigen ProgrammierungApr 17, 2025 am 12:09 AM
Python: Die Kraft der vielseitigen ProgrammierungApr 17, 2025 am 12:09 AMPython ist für seine Einfachheit und Kraft sehr beliebt, geeignet für alle Anforderungen von Anfängern bis hin zu fortgeschrittenen Entwicklern. Seine Vielseitigkeit spiegelt sich in: 1) leicht zu erlernen und benutzten, einfachen Syntax; 2) Reiche Bibliotheken und Frameworks wie Numpy, Pandas usw.; 3) plattformübergreifende Unterstützung, die auf einer Vielzahl von Betriebssystemen betrieben werden kann; 4) Geeignet für Skript- und Automatisierungsaufgaben zur Verbesserung der Arbeitseffizienz.
 Python in 2 Stunden am Tag lernen: Ein praktischer LeitfadenApr 17, 2025 am 12:05 AM
Python in 2 Stunden am Tag lernen: Ein praktischer LeitfadenApr 17, 2025 am 12:05 AMJa, lernen Sie Python in zwei Stunden am Tag. 1. Entwickeln Sie einen angemessenen Studienplan, 2. Wählen Sie die richtigen Lernressourcen aus, 3. Konsolidieren Sie das durch die Praxis erlernte Wissen. Diese Schritte können Ihnen helfen, Python in kurzer Zeit zu meistern.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

Dreamweaver CS6
Visuelle Webentwicklungstools

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

