

 Technologie-PeripheriegeräteKIWie wichtig es ist, die Datenqualität beim maschinellen Lernen sicherzustellen und wie man sie bestätigt
Technologie-PeripheriegeräteKIWie wichtig es ist, die Datenqualität beim maschinellen Lernen sicherzustellen und wie man sie bestätigtWie wichtig es ist, die Datenqualität beim maschinellen Lernen sicherzustellen und wie man sie bestätigt


Maschinelles Lernen ist in Organisationen jeder Größe zu einem wichtigen Werkzeug geworden, um Erkenntnisse zu gewinnen und datengesteuerte Entscheidungen zu treffen. Der Erfolg eines Machine-Learning-Projekts hängt jedoch stark von der Qualität der Daten ab. Eine schlechte Datenqualität führt zu ungenauen Vorhersagen und einer schlechten Modellleistung. Daher ist es von entscheidender Bedeutung, die Bedeutung der Datenqualität beim maschinellen Lernen zu verstehen und verschiedene Techniken einzusetzen, um qualitativ hochwertige Daten sicherzustellen.
Daten sind eine unverzichtbare und wichtige Ressource für maschinelles Lernen. Verschiedene Arten von Daten spielen ihre jeweilige Rolle bei der Modellkonstruktion. Verschiedene Datentypen wie kategoriale Daten, numerische Daten, Zeitreihendaten und Textdaten werden häufig verwendet. Die Verfügbarkeit qualitativ hochwertiger Daten ist ein Schlüsselfaktor für die Genauigkeit und Zuverlässigkeit von Modellen.
Wie stellt man die Datenqualität sicher?
Im Allgemeinen gibt es vier Schritte: Datenerfassung, Dateninjektion, Datenvorverarbeitung und Feature-Arbeit. Konkret:
Daten sammeln
Die Datenvorbereitung für maschinelles Lernen wird oft als ETL-Pipeline zum Extrahieren, Transformieren und Laden bezeichnet.
Extraktion: Erhalten Sie Daten aus verschiedenen Quellen, einschließlich Datenbanken, APIs oder gängigen Dateien wie CSV oder Excel. Daten können strukturiert oder unstrukturiert sein.
Transformation ist der Prozess der Anpassung von Daten an ein maschinelles Lernmodell. Dazu gehört die Bereinigung der Daten, um Fehler oder Inkonsistenzen zu beseitigen, die Standardisierung der Daten und deren Konvertierung in ein für das Modell akzeptables Format. Darüber hinaus ist auch Feature-Engineering erforderlich, um die Rohdaten in eine Reihe von Features als Eingabe für das Modell umzuwandeln.
Laden: Der letzte Schritt besteht darin, die konvertierten Daten an ein Ziel wie eine Datenbank, einen Datenspeicher oder ein Dateisystem hochzuladen oder zu laden. Die generierten Daten können zum Trainieren oder Testen von Modellen für maschinelles Lernen verwendet werden.
Nach dem Sammeln der Daten müssen Sie die Daten einfügen.
Dateninjektion
Um die Leistung des maschinellen Lernmodells zu verbessern, müssen wir neue Daten zum vorhandenen Datenserver hinzufügen, um die Datenbank zu aktualisieren und weitere unterschiedliche Daten hinzuzufügen. Dieser Prozess wird häufig mithilfe praktischer Tools automatisiert.
Zum Beispiel:
Batch-Einfügung: Daten stapelweise einfügen, normalerweise zu einem festen Zeitpunkt.
Echtzeitinjektion: Injizieren Sie Daten sofort nach der Generierung.
Stream-Injection: Daten werden in Form eines kontinuierlichen Streams injiziert. Es wird häufig in Echtzeit verwendet.
Die dritte Stufe der Datenpipeline ist die Datenvorverarbeitung.
Datenvorverarbeitung
Die Datenverarbeitung bereitet die Daten für die Verwendung in Modellen des maschinellen Lernens vor. Dies ist ein wichtiger Schritt beim maschinellen Lernen, da dadurch sichergestellt wird, dass die Daten in einem Format vorliegen, das das Modell verwenden kann, und dass etwaige Fehler oder Inkonsistenzen behoben werden .
Die Datenverarbeitung umfasst normalerweise eine Kombination aus Datenbereinigung, Datentransformation und Datenstandardisierung. Die genauen Schritte zur Datenverarbeitung hängen von der Art der Daten und dem von Ihnen verwendeten maschinellen Lernmodell ab.
Allgemeiner Ablauf der Datenverarbeitung:
Allgemeine Schritte:
1. Datenbereinigung: Entfernen Sie Fehler, Inkonsistenzen und Ausreißer aus der Datenbank.
2. Datenkonvertierung: Daten werden in eine Form konvertiert, die von Modellen des maschinellen Lernens verwendet werden kann, z. B. zur Konvertierung kategorialer Variablen in numerische Variablen.
3. Datennormalisierung: Skalierung von Daten innerhalb eines bestimmten Bereichs zwischen 0 und 1, was zur Verbesserung der Leistung einiger Modelle für maschinelles Lernen beiträgt.
4. Daten hinzufügen: Fügen Sie Änderungen oder Aktionen zu vorhandenen Datenpunkten hinzu, um neue Datenpunkte zu erstellen.
5. Merkmalsauswahl oder -extraktion: Identifizieren und wählen Sie grundlegende Merkmale aus den Daten aus, die als Eingabe für das maschinelle Lernmodell verwendet werden sollen.
6. Ausreißererkennung: Identifizieren und entfernen Sie Datenpunkte, die erheblich von großen Datenmengen abweichen. Ausreißer können Analyseergebnisse verändern und die Leistung von Modellen für maschinelles Lernen beeinträchtigen.
7. Duplikate erkennen: Identifizieren und entfernen Sie doppelte Datenpunkte. Doppelte Daten können zu ungenauen oder unzuverlässigen Ergebnissen führen und die Größe des Datensatzes erhöhen, was die Verarbeitung und Analyse erschwert.
8. Identifizieren Sie Trends: Finden Sie Muster und Trends in Ihren Daten, die Sie nutzen können, um zukünftige Vorhersagen zu treffen oder die Natur Ihrer Daten besser zu verstehen.
Die Datenverarbeitung ist beim maschinellen Lernen von entscheidender Bedeutung, da sie sicherstellt, dass die Daten in einer Form vorliegen, die das Modell verwenden kann, und Fehler oder Inkonsistenzen beseitigt. Dies verbessert die Modellleistung und Vorhersagegenauigkeit.
Die letzte Phase der Datenpipeline ist das Feature Engineering.
Feature Engineering
Feature Engineering wandelt Rohdaten in Features um, die als Eingabe für Modelle für maschinelles Lernen verwendet werden können. Dabei geht es darum, die kritischsten Daten aus dem Rohmaterial zu identifizieren, zu extrahieren und in ein Format umzuwandeln, das das Modell verwenden kann. Feature Engineering ist beim maschinellen Lernen von entscheidender Bedeutung, da es die Modellleistung erheblich beeinflussen kann.
Feature Engineering umfasst:
Feature-Extraktion: Extrahieren relevanter Informationen aus Rohdaten. Identifizieren Sie beispielsweise die wichtigsten Funktionen oder kombinieren Sie vorhandene Funktionen, um neue zu erstellen.
Attributänderung: Ändern Sie den Attributtyp, indem Sie beispielsweise eine kategoriale Variable in eine numerische Variable ändern oder die Daten so skalieren, dass sie in einen bestimmten Bereich passen.
Funktionsauswahl: Bestimmen Sie die grundlegenden Funktionen der Daten, die als Eingabe für das maschinelle Lernmodell verwendet werden sollen.
Dimensionalitätsreduzierung: Reduzieren Sie die Anzahl der Features in der Datenbank, indem Sie redundante oder irrelevante Features entfernen.
Daten hinzufügen: Fügen Sie Änderungen oder Aktionen zu vorhandenen Datenpunkten hinzu, um neue zu erstellen.
Feature Engineering erfordert ein gutes Verständnis der Daten, des zu lösenden Problems und des zu verwendenden maschinellen Lernalgorithmus. Dieser Prozess ist iterativ und experimentell und erfordert möglicherweise mehrere Iterationen, um den optimalen Funktionssatz zu finden, der die Modellleistung verbessert.
Das obige ist der detaillierte Inhalt vonWie wichtig es ist, die Datenqualität beim maschinellen Lernen sicherzustellen und wie man sie bestätigt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

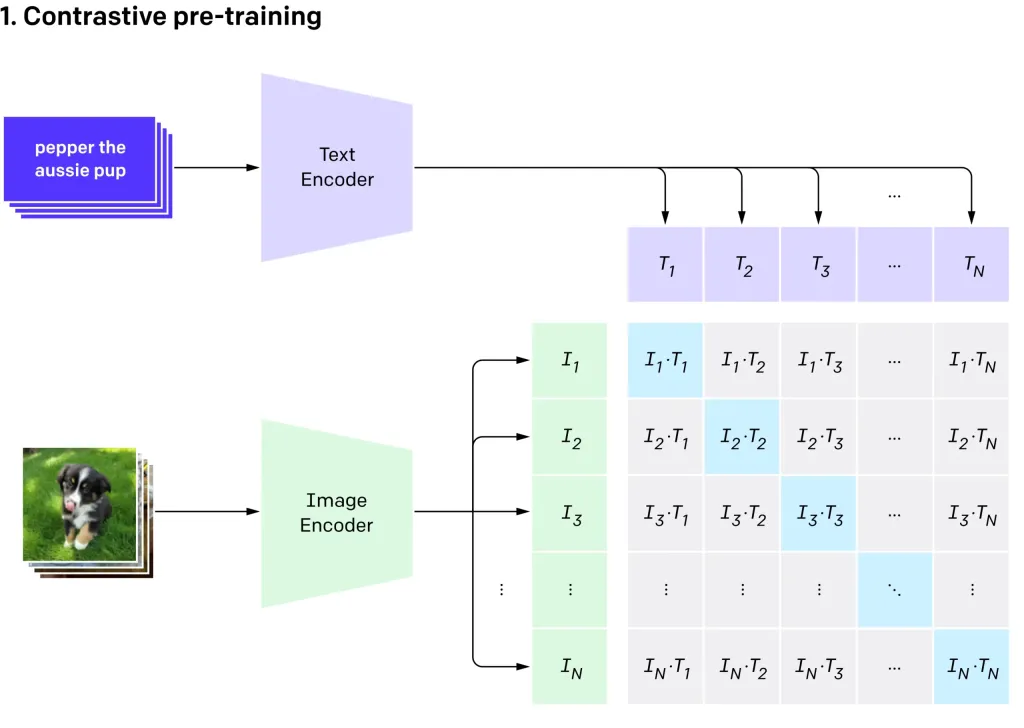 Null-Shot-Bildklassifizierung mit OpenAIs Clip Vit-L14Apr 11, 2025 am 10:04 AM
Null-Shot-Bildklassifizierung mit OpenAIs Clip Vit-L14Apr 11, 2025 am 10:04 AMOpenAIs Clip-Modell (kontrastive Sprache-Image-Vor-Training), insbesondere die Clip Vit-L14-Variante, stellt einen signifikanten Fortschritt beim multimodalen Lernen und der Verarbeitung natürlicher Sprache dar. Dieses leistungsstarke Computer -Vision -System zeichnet sich bei Represe aus
 7 Schritte zum Erstellen eines AI -Agenten ohne Code - Analytics VidhyaApr 11, 2025 am 10:03 AM
7 Schritte zum Erstellen eines AI -Agenten ohne Code - Analytics VidhyaApr 11, 2025 am 10:03 AMNutzen Sie die Kraft von KI-Agenten mit Wordware: eine Plattform ohne Code für mühelose KI-Agentenerstellung. KI-Agenten revolutionieren, wie wir mit Computern interagieren, Aufgaben automatisieren und die Entscheidungsfindung rationalisieren. Dieser Blog zeigt, wie man baut
 LLMs über Mobilgeräte: Gegenwart und zukünftige Möglichkeiten - Analytics VidhyaApr 11, 2025 am 09:58 AM
LLMs über Mobilgeräte: Gegenwart und zukünftige Möglichkeiten - Analytics VidhyaApr 11, 2025 am 09:58 AMGenerative KI: Das nächste Smartphone -Schlachtfeld Die Smartphone -Branche ist in einem heftigen Wettbewerb gesperrt: das Rennen um die Integration fortschrittlicher Generative KI. Von der Verbesserung der Benutzerinteraktion bis zur Steigerung der Produktivität sind die Einsätze hoch. Apples iPhone 16
 Top 10 generative AI -Subreddits im Jahr 2025 - Analytics VidhyaApr 11, 2025 am 09:51 AM
Top 10 generative AI -Subreddits im Jahr 2025 - Analytics VidhyaApr 11, 2025 am 09:51 AMGenerative KI: Ihr Leitfaden für 10 essentielle Reddit -Gemeinschaften Generative KI entwickelt sich schnell weiter, wobei ständig neue Modelle auftauchen. Auf dem Laufenden zu bleiben ist von entscheidender Bedeutung, und Reddit bietet lebendige Gemeinden, die diesem Gebiet gewidmet sind. Dieser Artikel zeigt t
 Wichtige Herausforderungen und Einschränkungen in KI -Modellen - Analytics VidhyaApr 11, 2025 am 09:44 AM
Wichtige Herausforderungen und Einschränkungen in KI -Modellen - Analytics VidhyaApr 11, 2025 am 09:44 AMEinführung Künstliche Intelligenz (KI) hat sich schnell in verschiedene Arbeitsplätze integriert, die durch erhebliche Investitionen in die KI -Forschung und -entwicklung angetrieben werden. Die Anwendungen von AI umfassen einen weiten Bereich, von unkomplizierten Aufgaben wie virtuellen Assistenten bis hin zu COM
 Umgang mit Nullwerten in SQLApr 11, 2025 am 09:37 AM
Umgang mit Nullwerten in SQLApr 11, 2025 am 09:37 AMEinführung Im Bereich der Datenbanken stellen Nullwerte häufig einzigartige Herausforderungen. In Bezug auf fehlende, undefinierte oder unbekannte Daten können sie das Datenmanagement und die Analyse komplizieren. Betrachten Sie eine Verkaufsdatenbank mit einem fehlenden Kundenfeedback oder -bestand
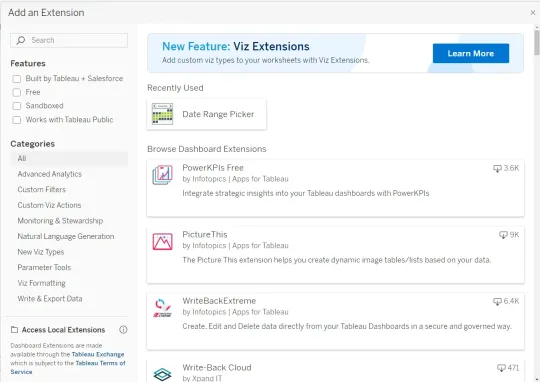 Wie integriere ich Google Gemini in Tableau Dashboards?Apr 11, 2025 am 09:27 AM
Wie integriere ich Google Gemini in Tableau Dashboards?Apr 11, 2025 am 09:27 AMNutzung der Leistung von Google Gemini in Tableau Dashboards: Eine KI-betriebene Verbesserung Tableaus robuste Visualisierungsfunktionen, Spanning Data Prepation (Tableau Prep Builder), Data Storytelling (Tableau Desktop) und Collaborative Sharing (Table
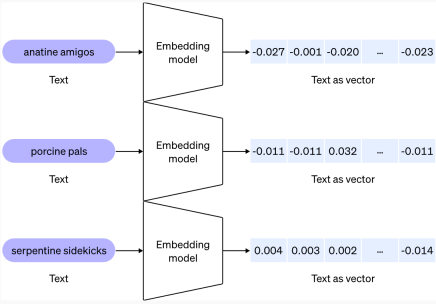 Was sind Vektor -Einbettungen? Typen und AnwendungsfälleApr 11, 2025 am 09:18 AM
Was sind Vektor -Einbettungen? Typen und AnwendungsfälleApr 11, 2025 am 09:18 AMErschöpfen der Kraft der Vektor -Einbettungen: Ein Leitfaden zur generativen KI Stellen Sie sich vor, Sie erklären jemandem, der Ihre Sprache nicht spricht - eine entmutigende Aufgabe, oder? Betrachten Sie nun Maschinen, die auch Schwierigkeiten haben, "unter" unter


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Dreamweaver Mac
Visuelle Webentwicklungstools

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

