
Heim >Technologie-Peripheriegeräte >KI >Das große Yi-VL-Modell ist Open Source und steht bei MMMU und CMMMU an erster Stelle
Das große Yi-VL-Modell ist Open Source und steht bei MMMU und CMMMU an erster Stelle

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-22 21:30:21578Durchsuche
https://huggingface.co/01-ai https://www.modelscope.cn/organization/01ai



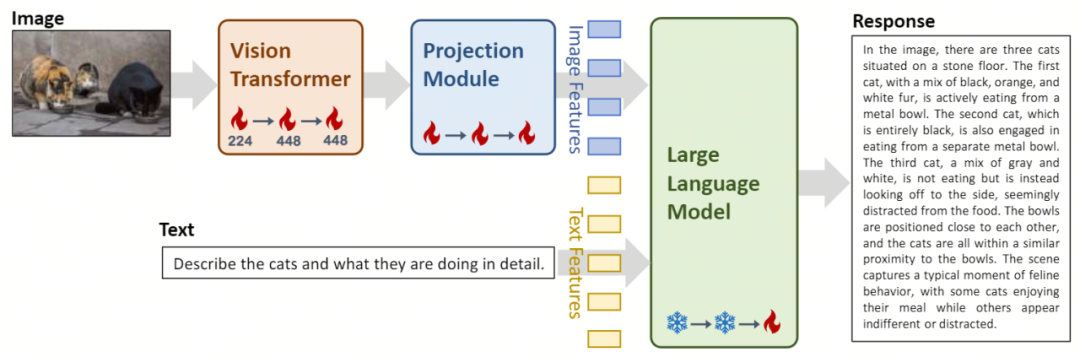
Vision Transformer (kurz ViT) kommt zum Einsatz Für die Bildkodierung initialisiert das Open-Source-Modell OpenClip ViT-H/14 trainierbare Parameter und lernt, Merkmale aus großen „Bild-Text“-Paaren zu extrahieren, wodurch das Modell in die Lage versetzt wird, Bilder zu verarbeiten und zu verstehen. Das Projektionsmodul bietet die Möglichkeit, Bildmerkmale räumlich an Textmerkmalen im Modell auszurichten. Dieses Modul besteht aus einem Multilayer Perceptron (MLP), das Schichtnormalisierungen enthält. Dieses Design ermöglicht es dem Modell, visuelle und Textinformationen effektiver zu verschmelzen und zu verarbeiten, wodurch die Genauigkeit des multimodalen Verständnisses und der multimodalen Generierung verbessert wird. Die Einführung der großen Sprachmodelle Yi-34B-Chat und Yi-6B-Chat bietet Yi-VL leistungsstarke Sprachverständnis- und Generierungsfunktionen. Dieser Teil des Modells nutzt fortschrittliche Technologie zur Verarbeitung natürlicher Sprache, um Yi-VL dabei zu helfen, komplexe Sprachstrukturen tiefgreifend zu verstehen und kohärente und relevante Textausgaben zu generieren.
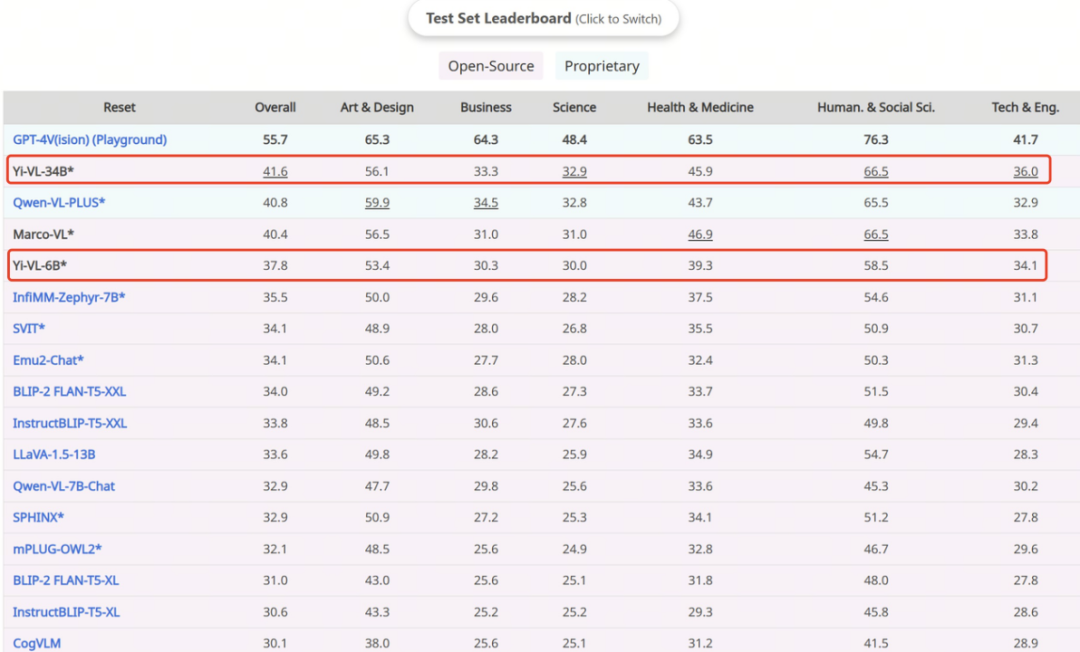
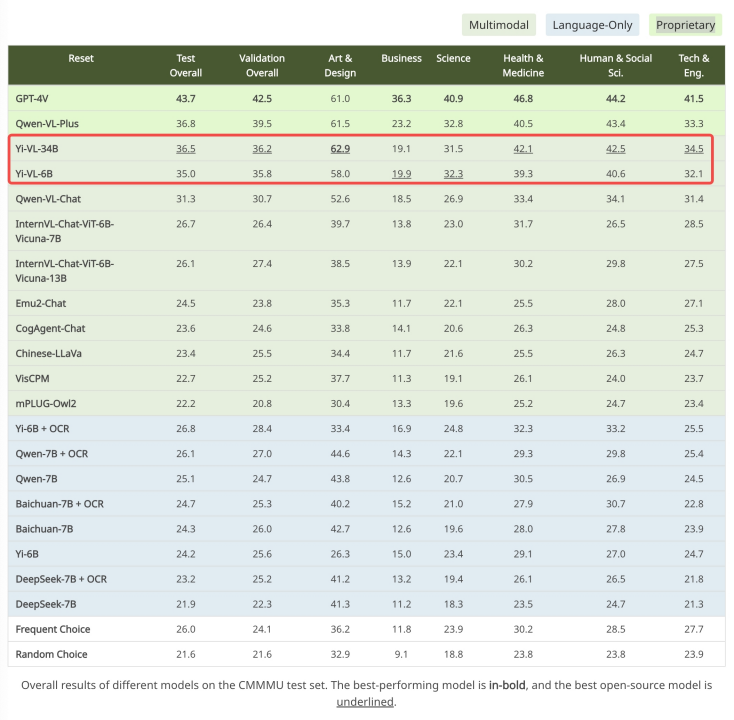
Die erste Stufe: Zero One Wanwu verwendet 100 Millionen gepaarte „Bild-Text“-Datensätze, um ViT- und Projektionsmodule zu trainieren. Zu diesem Zeitpunkt ist die Bildauflösung auf 224 x 224 eingestellt, um die Wissenserfassungsfähigkeiten von ViT in bestimmten Architekturen zu verbessern und gleichzeitig eine effiziente Ausrichtung auf große Sprachmodelle zu ermöglichen. Die zweite Stufe: Zero One Thing erhöht die Bildauflösung von ViT auf 448 x 448. Durch diese Verbesserung kann das Modell komplexe visuelle Details besser erkennen. In dieser Phase werden etwa 25 Millionen Bild-Text-Paare verwendet. Die dritte Stufe: Zero One Wish öffnet die Parameter des gesamten Modells für das Training, mit dem Ziel, die Leistung des Modells in der multimodalen Chat-Interaktion zu verbessern. Die Trainingsdaten decken eine Vielzahl von Datenquellen mit insgesamt etwa 1 Million „Bild-Text“-Paaren ab, wodurch die Breite und Ausgewogenheit der Daten gewährleistet ist.
Das obige ist der detaillierte Inhalt vonDas große Yi-VL-Modell ist Open Source und steht bei MMMU und CMMMU an erster Stelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:jiqizhixin.com. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen
Vorheriger Artikel:So organisieren Sie maschinelle Lernprojekte: Anwendung von Crisp-DMNächster Artikel:So organisieren Sie maschinelle Lernprojekte: Anwendung von Crisp-DM
In Verbindung stehende Artikel
Mehr sehen- Um die Entwicklung der 5G-Technologie zu beschleunigen, wurde die weltweit erste 5G-RedCap-Industrieallianz gegründet
- Ein langer Artikel mit 10.000 Wörtern: Dekonstruktion der Kette, Lösungen und unternehmerischen Möglichkeiten der KI-Sicherheitsbranche
- Audi-Chef: Der Halbleitermangel hat dazu geführt, dass die deutsche Automobilindustrie in eine mehrjährige Engpassphase geraten wird
- Wie können kollaborative Roboter die intelligente Fertigung und Modernisierung der täglichen chemischen Industrie unterstützen? Hören Sie, was die Experten sagen
- Kai-fu Lees KI-Unternehmen „Zero One Everything' Open-Source-Yi-Großmodell wurde des Plagiats LLaMA beschuldigt