
Heim >Technologie-Peripheriegeräte >KI >Testwettbewerb für das KI-Videogenerierungs-Framework: Pika, Gen-2, ModelScope, SEINE, wer kann gewinnen?
Testwettbewerb für das KI-Videogenerierungs-Framework: Pika, Gen-2, ModelScope, SEINE, wer kann gewinnen?

- 王林nach vorne
- 2024-01-22 13:06:121102Durchsuche
KI-Videogenerierung ist in letzter Zeit eines der heißesten Gebiete. Verschiedene Universitätslabore, der Internetgigant AI Labs und Start-up-Unternehmen haben sich dem Weg zur KI-Videogenerierung angeschlossen. Noch auffälliger ist die Veröffentlichung von Videogenerationsmodellen wie Pika, Gen-2, Show-1, VideoCrafter, ModelScope, SEINE, LaVie und VideoLDM. v⁽ⁱ⁾
Sie sind bestimmt neugierig auf die folgenden Fragen:
- Welches Videogenerierungsmodell ist das beste?
- Was sind die Besonderheiten der einzelnen Modelle?
- Welche Probleme verdienen Aufmerksamkeit und müssen im Bereich der KI-Videogenerierung gelöst werden?
Zu diesem Zweck haben wir VBench ins Leben gerufen, ein umfassendes „Bewertungsframework für Videogenerierungsmodelle“, das Benutzern Informationen über die Vor- und Nachteile und Eigenschaften verschiedener Videomodelle liefern soll. Durch VBench können Benutzer die Stärken und Vorteile verschiedener Videomodelle verstehen.

- Papier: https://arxiv.org/abs/2311.17982
- Code: https://github.com/Vchitect/VBench
- Webseite: https ://vchitect.github.io/VBench-project/
- Papiertitel: VBench: Comprehensive Benchmark Suite for Video Generative Models
VBench kann den Videogenerierungseffekt nicht nur umfassend und sorgfältig bewerten, sondern auch bereitstellen konsistente Bewertung der Sinneserfahrungen von Menschen, wodurch Zeit und Energie gespart werden.
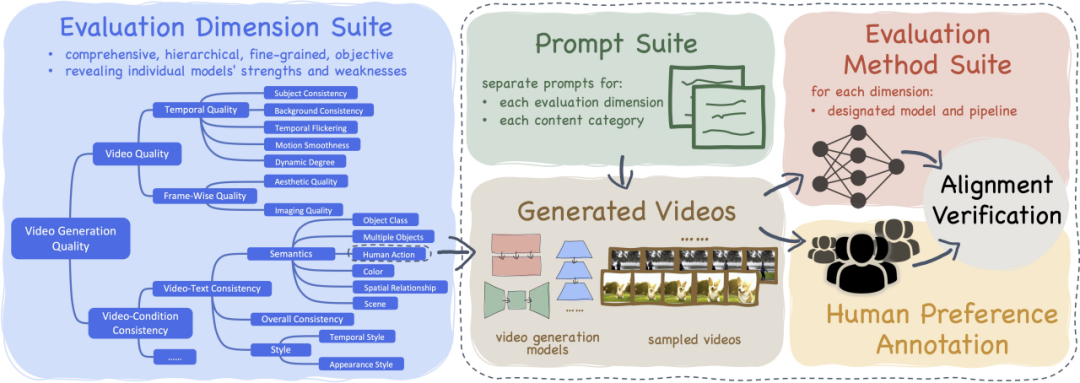
- VBench enthält 16 geschichtete und entkoppelte Bewertungsdimensionen.
- VBench hat das Prompt-List-System für die Bewertung der Vincent-Videogenerierung als Open Source bereitgestellt Bewertung
- VBench bietet multiperspektivische Einblicke, um die zukünftige Erforschung der KI-Videogenerierung zu unterstützen

KI-Videogenerierungsmodell - Bewertungsergebnisse
Open-Source-KI-Videogenerierungsmodell
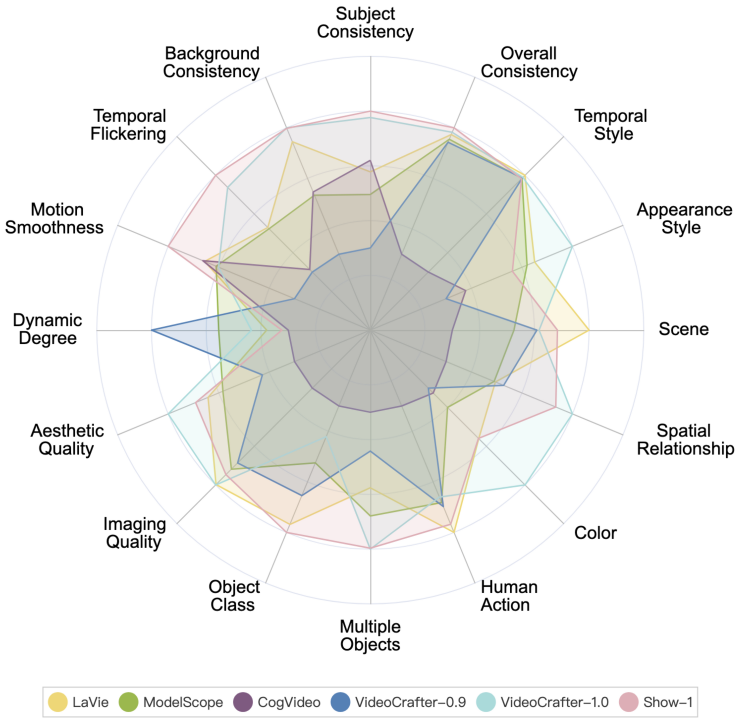
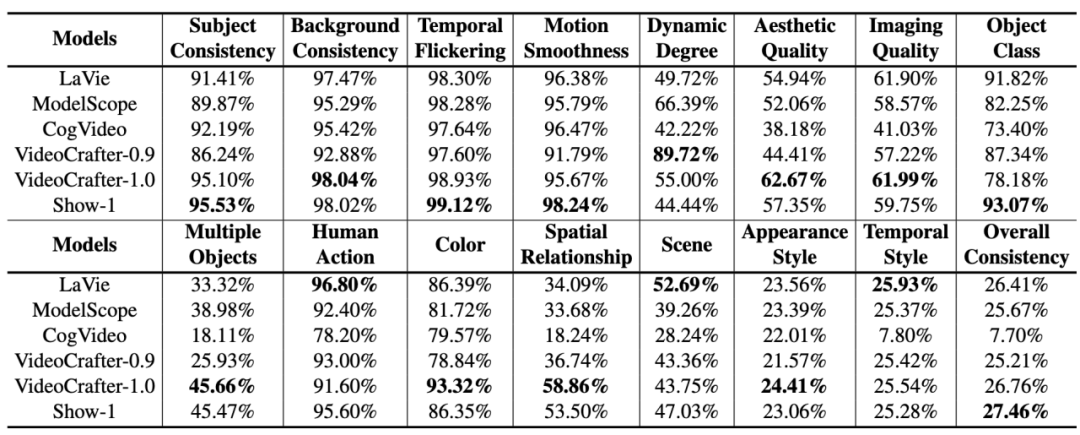
Die Leistung jedes Open-Source-KI-Videogenerierungsmodells auf VBench ist wie folgt.
Die Leistung verschiedener Open-Source-KI-Videogenerierungsmodelle auf VBench. Im Radardiagramm haben wir die Ergebnisse für jede Dimension auf einen Wert zwischen 0,3 und 0,8 normalisiert, um den Vergleich klarer darzustellen.
Video-Generierungsmodelle von Startups
VBench liefert derzeit Bewertungsergebnisse von zwei Startup-Modellen, Gen-2 und Pika.
Leistung von Gen-2 und Pika auf VBench. Um den Vergleich klarer darzustellen, haben wir im Radardiagramm VideoCrafter-1.0 und Show-1 als Referenzen hinzugefügt und die Bewertungsergebnisse jeder Dimension auf einen Wert zwischen 0,3 und 0,8 normalisiert. 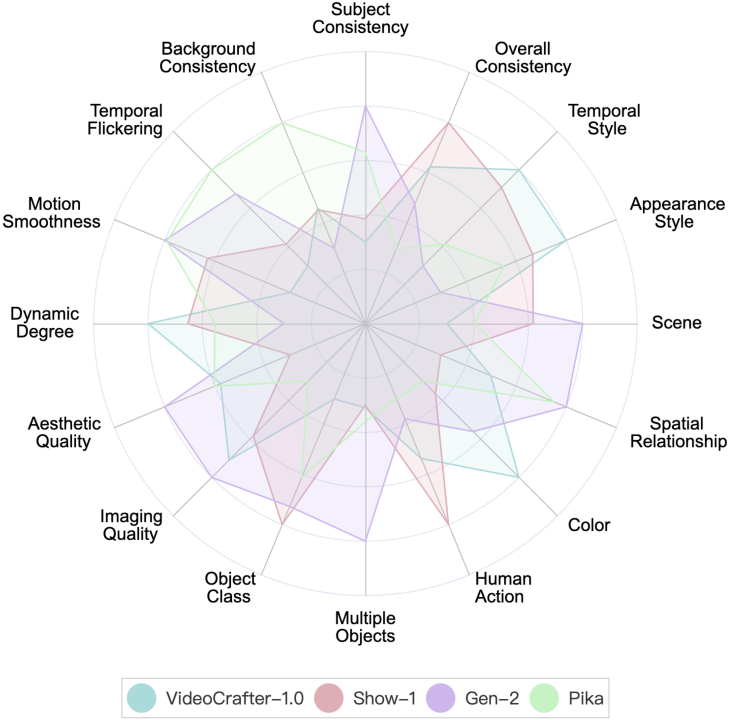
Leistung von Gen-2 und Pika auf VBench. Als Referenz beziehen wir die numerischen Ergebnisse von VideoCrafter-1.0 und Show-1 ein.
Es ist ersichtlich, dass Gen-2 und Pika offensichtliche Vorteile in Bezug auf die Videoqualität (Videoqualität) haben, wie z. B. zeitliche Konsistenz (zeitliche Konsistenz) und Einzelbildqualität (ästhetische Qualität und Bildqualität). Im Hinblick auf die semantische Konsistenz mit Benutzereingabeaufforderungen (z. B. menschliches Handeln und Erscheinungsstil) sind teildimensionale Open-Source-Modelle besser.
Videogenerierungsmodell VS Bildgenerierungsmodell
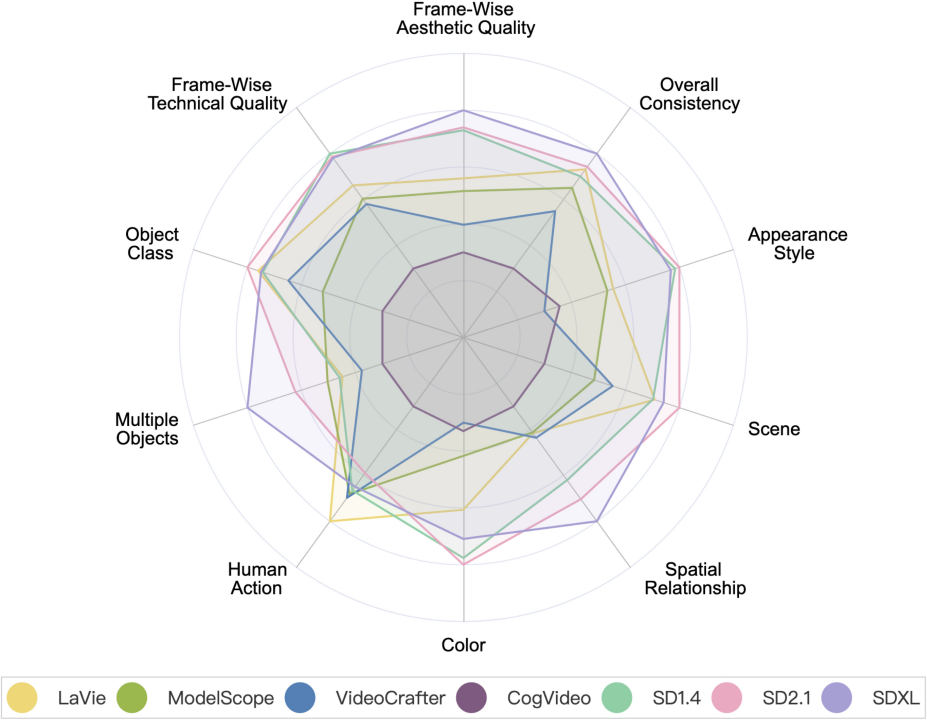
Videogenerierungsmodell VS Bildgenerierungsmodell. Darunter sind SD1.4, SD2.1 und SDXL Bilderzeugungsmodelle.
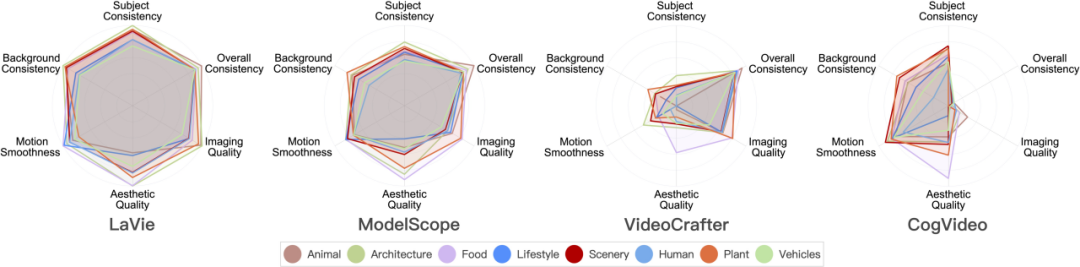
Leistung des Videogenerierungsmodells in 8 Hauptszenenkategorien
Im Folgenden sind die Bewertungsergebnisse verschiedener Modelle in 8 verschiedenen Kategorien aufgeführt.
VBench ist jetzt Open Source und kann mit einem Klick installiert werden
Derzeit ist VBench vollständig Open Source und unterstützt die Installation mit einem Klick. Jeder ist willkommen, mitzuspielen, die Modelle zu testen, an denen er interessiert ist, und zusammenzuarbeiten, um die Entwicklung der Video-Generierungs-Community voranzutreiben.



Open-Source-Adresse: https://github.com/Vchitect/VBench
Wir haben auch eine Reihe von Prompt als Open Source bereitgestellt Listen: https://github.com/Vchitect/VBench/tree/master/prompts, enthält Benchmarks für die Bewertung in verschiedenen Fähigkeitsdimensionen sowie Bewertungsbenchmarks für verschiedene Szenarioinhalte.
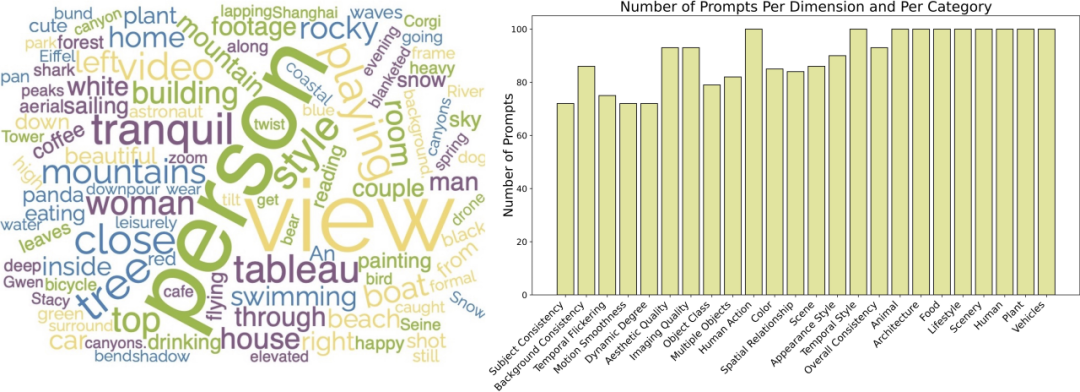
Die Wortwolke links zeigt die Verteilung hochfrequenter Wörter in unseren Prompt Suites und das Bild rechts zeigt die Statistik der Anzahl der Prompts in verschiedenen Dimensionen und Kategorien.
Ist VBench genau?
Für jede Dimension haben wir die Korrelation zwischen den VBench-Bewertungsergebnissen und den manuellen Bewertungsergebnissen berechnet, um die Konsistenz unserer Methode mit der menschlichen Wahrnehmung zu überprüfen. In der folgenden Abbildung stellt die horizontale Achse die Ergebnisse der manuellen Bewertung in verschiedenen Dimensionen dar, und die vertikale Achse zeigt die Ergebnisse der automatischen Bewertung der VBench-Methode. Es ist ersichtlich, dass unsere Methode in allen Dimensionen stark an der menschlichen Wahrnehmung ausgerichtet ist. „VBench bringt Denken in die KI-Videogenerierung“ der Videogenerierung liefert wertvolle Erkenntnisse.
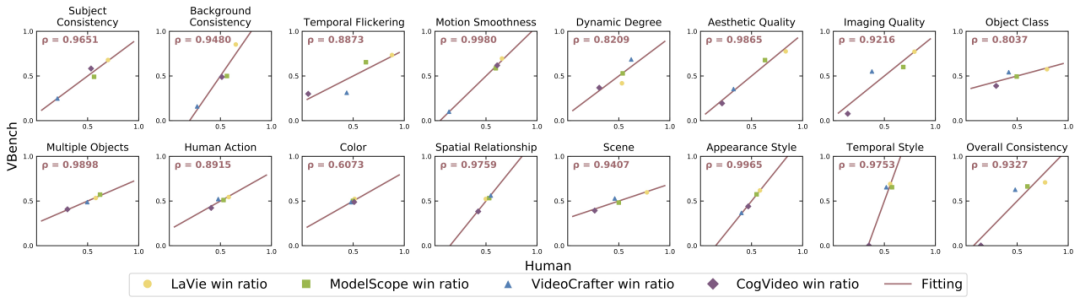
Wir haben festgestellt, dass zeitliche Konsistenz (wie Subjektkonsistenz, Hintergrundkonsistenz, Bewegungsglätte) und Video Es gibt eine gewisse Kompromissbeziehung zwischen der Bewegungsamplitude (Dynamikgrad). Beispielsweise schnitten Show-1 und VideoCrafter-1.0 in Bezug auf die Konsistenz des Hintergrunds und die Geschmeidigkeit der Aktion sehr gut ab, erzielten jedoch schlechtere Ergebnisse in Bezug auf die Dynamik. Dies kann daran liegen, dass die Erzeugung „nicht bewegter“ Bilder eher „im Timing“ erscheint. Sehr stimmig.“ VideoCrafter-0.9 hingegen ist in der Dimension der Timing-Konsistenz schwächer, schneidet aber beim dynamischen Grad gut ab.
Dies zeigt, dass es in Zukunft tatsächlich schwierig ist, gleichzeitig „zeitliche Kohärenz“ und „höhere Dynamik“ zu erreichen. Wir sollten uns nicht nur auf die Verbesserung eines Aspekts konzentrieren, sondern auch auf die Verbesserung von „zeitlicher Kohärenz“ und „Video“. Qualität" gleichzeitig. Dynamischer Grad" diese beiden Aspekte, das ist sinnvoll.
Bewerten Sie den Inhalt der Szene, um das Potenzial jedes Modells zu erkunden.
Einige Modelle weisen große Leistungsunterschiede in verschiedenen Kategorien auf. In Bezug auf die ästhetische Qualität (Ästhetische Qualität) befindet sich CogVideo beispielsweise in „Essen“. Die Kategorie „“ schnitt gut ab, schnitt jedoch in der Kategorie „LifeStyle“ schlechter ab. Kann die ästhetische Qualität von CogVideo in den „LifeStyle“-Kategorien verbessert werden, wenn die Trainingsdaten angepasst werden, und dadurch die gesamte Videoästhetikqualität des Modells verbessert werden?
Dies zeigt uns auch, dass wir bei der Bewertung eines Videogenerierungsmodells die Leistung des Modells in verschiedenen Kategorien oder Themen berücksichtigen, die Obergrenze des Modells in einer bestimmten Fähigkeitsdimension erkunden und dann gezielt verbessern müssen. hinterherhinkenden“ Szenenkategorien.
Kategorien mit komplexer Bewegung: schlechte räumlich-zeitliche Leistung
Kategorien mit hoher räumlicher Komplexität weisen niedrige Werte in der ästhetischen Qualitätsdimension auf. Beispielsweise stellt die Kategorie „LifeStyle“ relativ hohe Anforderungen an die Anordnung komplexer Elemente im Raum und die Kategorie „Mensch“ stellt aufgrund der Generierung von Scharnierstrukturen Herausforderungen.
Für Kategorien mit komplexem Timing, wie zum Beispiel die Kategorie „Mensch“, die normalerweise komplexe Aktionen beinhaltet, und die Kategorie „Fahrzeug“, die sich oft schneller bewegt, sind ihre Werte in allen getesteten Dimensionen relativ niedrig. Dies zeigt, dass das aktuelle Modell immer noch gewisse Mängel bei der Verarbeitung der zeitlichen Modellierung aufweist. Die zeitlichen Modellierungsbeschränkungen können zu räumlicher Unschärfe und Verzerrung führen, was zu einer sowohl zeitlich als auch räumlich unbefriedigenden Videoqualität führt.
Schwierig zu generierende Kategorien: Die Erhöhung der Datenmenge bringt kaum Vorteile
Wir haben Statistiken zum häufig verwendeten Videodatensatz WebVid-10M durchgeführt und festgestellt, dass etwa 26 % der Daten damit zusammenhängen „Menschlich“. Der höchste Anteil unter den acht Kategorien, die wir gezählt haben. In den Bewertungsergebnissen schnitt die Kategorie „Mensch“ jedoch unter den acht Kategorien am schlechtesten ab.
Das zeigt, dass bei einer komplexen Kategorie wie „Mensch“ eine einfache Erhöhung der Datenmenge möglicherweise keine wesentlichen Leistungsverbesserungen mit sich bringt. Eine mögliche Methode besteht darin, das Erlernen des Modells durch die Einführung „menschlicher“ Vorkenntnisse oder Kontrollen wie Skelette usw. zu steuern.
... Punktzahl. Daher haben wir die ästhetische Qualitätsleistung verschiedener Inhaltskategorien im WebVid-10M-Datensatz weiter analysiert und festgestellt, dass die Kategorie „Lebensmittel“ auch die höchste ästhetische Bewertung in WebVid-10M aufweist.Das bedeutet, dass basierend auf Millionen von Daten das Filtern/Verbessern der Datenqualität hilfreicher ist als das Erhöhen der Datenmenge.
Verbesserungsmöglichkeit: Mehrere Objekte und die Beziehung zwischen Objekten genau generieren
Das aktuelle Videogenerierungsmodell befindet sich in „Mehrere Objekte“ und „räumliche Beziehung“. In Bezug auf die Leistung kann es immer noch nicht aufholen mit Bilderzeugungsmodellen (insbesondere SDXL), was die Bedeutung der Verbesserung der Kombinationsmöglichkeiten unterstreicht. Die sogenannte Kombinationsfähigkeit bezieht sich darauf, ob das Modell mehrere Objekte bei der Videogenerierung sowie die räumlichen und interaktiven Beziehungen zwischen ihnen genau anzeigen kann.
Mögliche Methoden zur Lösung dieses Problems können sein:
Datenkennzeichnung: Erstellen Sie einen Videodatensatz, um klare Beschreibungen mehrerer Objekte im Video sowie Beschreibungen der räumlichen Positionsbeziehungen und Interaktionsbeziehungen zwischen ihnen bereitzustellen Objekte.
Fügen Sie während des Videogenerierungsprozesses Zwischenmodi/Module hinzu, um die Steuerung der Kombination und räumlichen Position von Objekten zu unterstützen.
- Die Verwendung eines besseren Text-Encoders (Text-Encoder) hat auch einen größeren Einfluss auf die kombinierte Generierungsfähigkeit des Modells.
- Kurve zur Rettung des Landes: Übergeben Sie das Problem der „Objektkombination“, das T2V nicht gut lösen kann, an T2I und generieren Sie Videos über T2I + I2V. Dieser Ansatz kann auch für viele andere Probleme bei der Videogenerierung wirksam sein.
Das obige ist der detaillierte Inhalt vonTestwettbewerb für das KI-Videogenerierungs-Framework: Pika, Gen-2, ModelScope, SEINE, wer kann gewinnen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Originalvideo der PHP-chinesischen Website: Kurszusammenfassung der PHP-Schulungsreihe „Dragon Babu' für öffentliche Wohlfahrt!
- Welche Software ist KI?
- Was bedeutet, dass der Start des Windows-Bootmanagers fehlgeschlagen ist?
- Welcher Ordner ist BaiduNetDisk?
- So legen Sie den Ein- und Ausblendeffekt für Videos in Premiere fest