Lightning Attention-2 ist ein neuer linearer Aufmerksamkeitsmechanismus, der die Trainings- und Inferenzkosten langer Sequenzen mit denen einer Sequenzlänge von 1K in Einklang bringt.
Die Begrenzung der Sequenzlänge großer Sprachmodelle hat ihre Anwendung im Bereich der künstlichen Intelligenz, wie z. B. Multi-Turn-Dialog, Langtextverständnis, multimodale Datenverarbeitung und -generierung usw., stark eingeschränkt. Der Hauptgrund für diese Einschränkung besteht darin, dass die in aktuellen großen Sprachmodellen verwendete Transformer-Architektur eine quadratische Rechenkomplexität im Verhältnis zur Sequenzlänge aufweist. Das bedeutet, dass mit zunehmender Sequenzlänge die benötigten Rechenressourcen exponentiell ansteigen. Die effiziente Verarbeitung langer Sequenzen war schon immer eine der Herausforderungen großer Sprachmodelle. Frühere Methoden konzentrierten sich in der Regel auf die Anpassung großer Sprachmodelle an längere Sequenzen in der Inferenzphase. Beispielsweise können Alibi oder ähnliche relative Positionscodierungsmethoden verwendet werden, um dem Modell die Anpassung an unterschiedliche Eingabesequenzlängen zu ermöglichen, oder ähnliche relative Positionscodierungsmethoden wie RoPE können verwendet werden, um Unterschiede vorzunehmen, und es kann weiteres Training am Modell durchgeführt werden Das hat das Training abgeschlossen. Kurzfristige Feinabstimmung, um den Zweck der Verstärkung der Sequenzlänge zu erreichen. Diese Methoden ermöglichen nur großen Modellen bestimmte Funktionen zur Modellierung langer Sequenzen, der tatsächliche Trainings- und Inferenzaufwand wurde jedoch nicht verringert. Das OpenNLPLab-Team versucht, das Problem der langen Sequenz großer Sprachmodelle ein für alle Mal zu lösen. Sie schlugen Lightning Attention-2 vor und stellten es als Open-Source-Lösung zur Verfügung, einen neuen linearen Aufmerksamkeitsmechanismus, der die Trainings- und Inferenzkosten langer Sequenzen mit denen einer 1K-Sequenzlänge in Einklang bringt. Bevor ein Speicherengpass auftritt, hat eine unbegrenzte Erhöhung der Sequenzlänge keine negativen Auswirkungen auf die Trainingsgeschwindigkeit des Modells. Dadurch ist ein Vortraining in unbegrenzter Länge möglich. Gleichzeitig entsprechen die Inferenzkosten sehr langer Texte den Kosten von 1K-Token oder liegen sogar darunter, was die Inferenzkosten aktueller großer Sprachmodelle erheblich reduzieren wird. Wie in der Abbildung unten gezeigt, beginnt bei den Modellgrößen 400M, 1B und 3B mit zunehmender Sequenzlänge die Trainingsgeschwindigkeit von LLaMA, die von FlashAttention2 unterstützt wird, rapide zu sinken, die Geschwindigkeit von TansNormerLLM, das von Lightning Attention-2 unterstützt wird, jedoch schon fast keine Veränderung.  Bild 1
Bild 1
- Paper: Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
- Paper-Adresse: https://arxiv.org/pdf/2401.04658.pdf
- Open-Source-Adresse: https://github.com/OpenNLPLab/lightning-attention
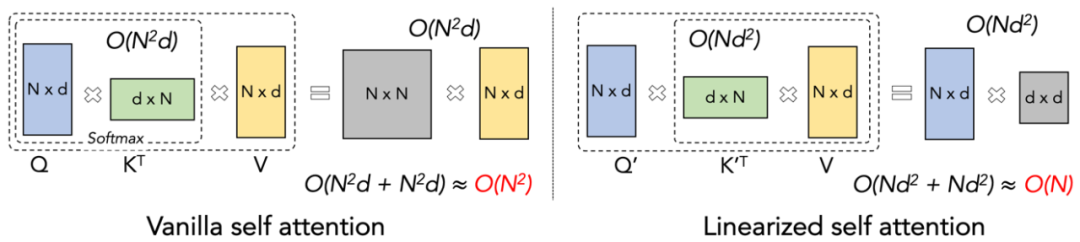
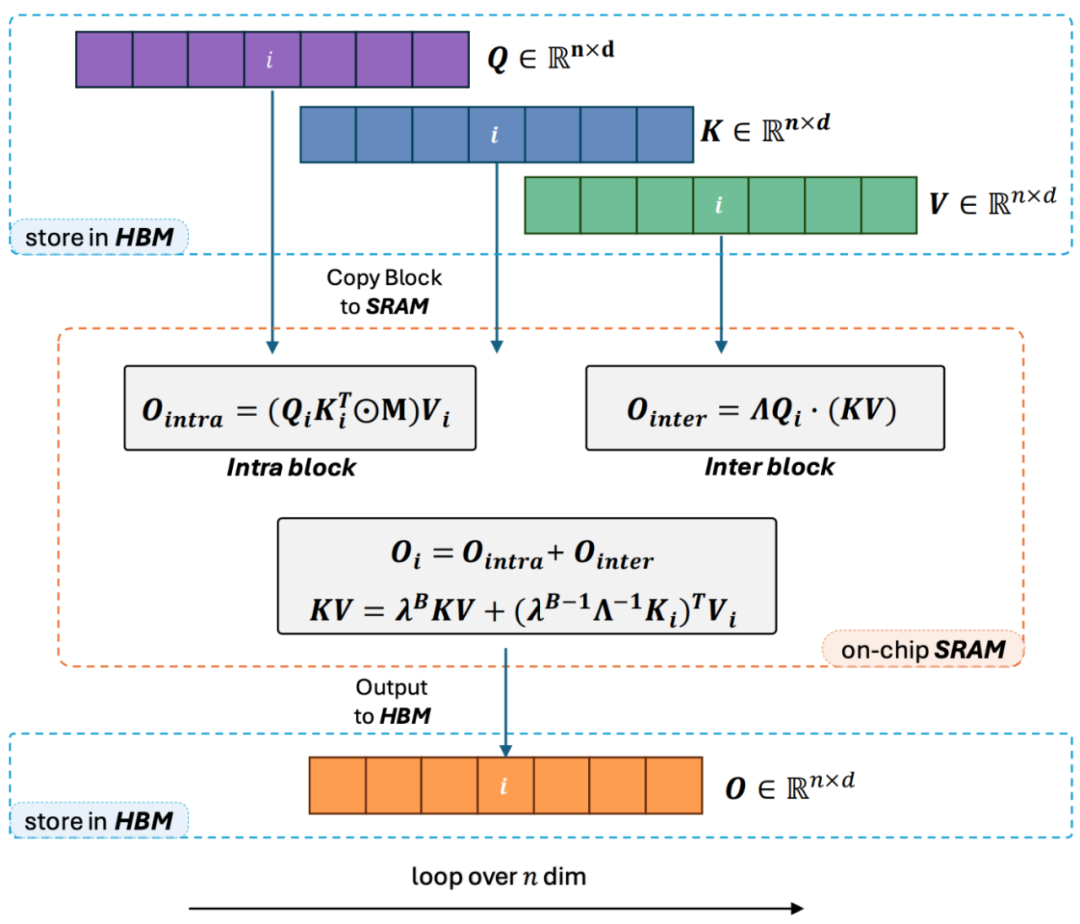
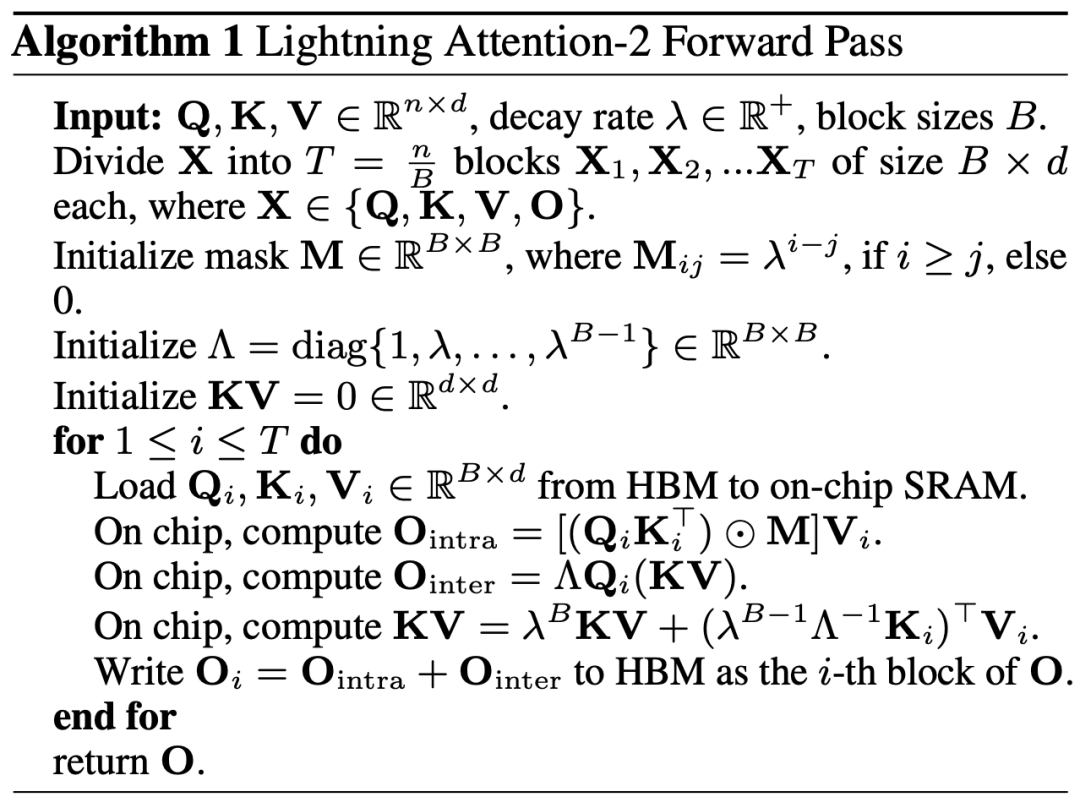
Lightning Attention-2 Einführung Hält die Geschwindigkeit vor dem Training großer Modelle über verschiedene Sequenzlängen hinweg konstant, was genau das ist es klingt wie eine unmögliche Mission. Tatsächlich kann dies erreicht werden, wenn die rechnerische Komplexität eines Aufmerksamkeitsmechanismus in Bezug auf die Sequenzlänge linear bleibt. Seit dem Aufkommen der linearen Aufmerksamkeit [https://arxiv.org/abs/2006.16236] im Jahr 2020 haben Forscher hart daran gearbeitet, die tatsächliche Effizienz der linearen Aufmerksamkeit mit ihrer theoretischen linearen Rechenkomplexität in Einklang zu bringen. Vor 2023 konzentrierten sich die meisten Arbeiten zur linearen Aufmerksamkeit darauf, ihre Genauigkeit an Transformers anzupassen. Mitte 2023 kann schließlich der verbesserte lineare Aufmerksamkeitsmechanismus [https://arxiv.org/abs/2307.14995] hinsichtlich der Genauigkeit an die hochmoderne Transformer-Architektur angepasst werden. Allerdings ist der kritischste Berechnungstrick „Links-zu-Rechts-Multiplikation“ (siehe Abbildung unten), der die Rechenkomplexität bei linearer Aufmerksamkeit in linear ändert (wie in der Abbildung unten gezeigt), in Wirklichkeit viel langsamer als der direkte Linksmultiplikationsalgorithmus Implementierung. Der Grund dafür ist, dass die Implementierung der rechten Multiplikation die Verwendung einer kumulativen Summierung (Cumsum) erfordert, die eine große Anzahl von Schleifenoperationen enthält. Aufgrund der großen Anzahl von E/A-Operationen ist die Effizienz der rechten Multiplikation viel geringer als die der linken Multiplikation. Um die Idee von Lightning Attention-2 besser zu verstehen, überprüfen wir zunächst die Berechnungsformel der traditionellen Softmax-Aufmerksamkeit: O=softmax ((QK^ T)⊙ M_) V, wobei Q, K, V, M, O jeweils Abfrage, Schlüssel, Wert, Maske und Ausgabematrix sind. M ist hier eine untere dreieckige All-1-Matrix in Einwegaufgaben (wie GPT). . In zwei Richtungen Es kann in Aufgaben (wie Bert) ignoriert werden, das heißt, es gibt keine Maskenmatrix für bidirektionale Aufgaben. Der Autor fasst die Gesamtidee von Lightning Attention-2 zur Erläuterung in die folgenden drei Punkte zusammen: 1 Eine der Kernideen von Linear Attention besteht darin, den rechenintensiven Softmax-Operator zu entfernen. Achtung: Die Berechnungsformel kann als O=((QK^T)⊙M_) V geschrieben werden. Aufgrund der Existenz der Maskenmatrix M in der Einwegaufgabe kann diese Form jedoch immer noch nur Linksmultiplikationsberechnungen durchführen, sodass die Komplexität von O (N) nicht erhalten werden kann. Da es jedoch für bidirektionale Aufgaben keine Maskenmatrix gibt, kann die Berechnungsformel der linearen Aufmerksamkeit weiter auf O = (QK ^ T) V vereinfacht werden. Die Feinheit der linearen Aufmerksamkeit besteht darin, dass ihre Berechnungsformel durch einfache Verwendung des assoziativen Gesetzes der Matrixmultiplikation weiter umgewandelt werden kann in: O=Q (K^T V). Diese Berechnungsform wird als rechte Multiplikation bezeichnet, und die entsprechende erstere lautet links. Aus Abbildung 2 können wir intuitiv verstehen, dass lineare Aufmerksamkeit bei bidirektionalen Aufgaben eine attraktive O(N)-Komplexität erreichen kann! 2. Da das reine Decoder-GPT-Modell jedoch allmählich zum De-facto-Standard für LLM wird, ist die Verwendung der richtigen Multiplikationsfunktion von Linear Attention zur Beschleunigung von Einwegaufgaben zu einem dringenden Problem geworden, das gelöst werden muss. Um dieses Problem zu lösen, schlug der Autor dieses Artikels vor, die Idee des „Teilens und Eroberns“ zu verwenden, um die Berechnung der Aufmerksamkeitsmatrix in zwei Formen zu unterteilen: Diagonalmatrix und nichtdiagonale Matrix, und unterschiedliche zu verwenden Möglichkeiten, sie zu berechnen. Wie in Abbildung 3 dargestellt, verwendet Linear Attention-2 die im Computerbereich häufig verwendete Tiling-Idee, um die Q-, K- und V-Matrizen in die gleiche Anzahl von Blöcken zu unterteilen. Unter diesen behält die Berechnung des Blocks selbst (intra-block) aufgrund der Existenz der Maskenmatrix immer noch die Berechnungsmethode der linken Multiplikation mit einer Komplexität von O (N^2) bei, während die Berechnung des Blocks (inter-block) immer noch die Berechnungsmethode der linken Multiplikation beibehält. Block) keine Maskenmatrix hat, können Sie die richtige Multiplikationsberechnungsmethode verwenden, um die Komplexität von O (N) zu genießen. Nachdem beide separat berechnet wurden, können sie direkt addiert werden, um die lineare Aufmerksamkeitsausgabe Oi zu erhalten, die dem i-ten Block entspricht. Gleichzeitig wird der Zustand von KV durch Cumsum akkumuliert, um bei der Berechnung des nächsten Blocks verwendet zu werden. Auf diese Weise beträgt die Algorithmuskomplexität des gesamten Lightning Attention-2 O (N^2) für Intra-Block und O (N) für Inter-Block-Kompromiss. Wie ein besserer Kompromiss erzielt werden kann, hängt von der Blockgröße von Tiling ab. 3. Aufmerksame Leser werden feststellen, dass der obige Prozess nur der Algorithmusteil von Lightning Attention-2 ist. Der Grund für den Namen Lightning liegt darin, dass der Autor die Effizienz des Algorithmusprozesses bei der GPU-Hardwareausführung vollständig berücksichtigt hat Verfahren. Inspiriert durch die FlashAttention-Arbeitsreihe hat der Autor bei der tatsächlichen Durchführung von Berechnungen auf der GPU die geteilten Q_i-, K_i- und V_i-Tensoren vom langsameren HBM mit größerer Kapazität innerhalb der GPU auf den schnelleren SRAM mit geringerer Kapazität verschoben System, wodurch ein großer Teil des Speicher-IO-Overheads reduziert wird.Nachdem der Block die Berechnung der linearen Aufmerksamkeit abgeschlossen hat, wird sein Ausgabeergebnis O_i zurück an HBM verschoben. Wiederholen Sie diesen Vorgang, bis alle Blöcke verarbeitet wurden. Leser, die mehr Details erfahren möchten, können die Algorithmen 1 und 2 in diesem Artikel sowie den detaillierten Ableitungsprozess im Artikel sorgfältig lesen. Sowohl der Algorithmus als auch der Ableitungsprozess unterscheiden zwischen den Vorwärts- und Rückwärtsprozessen von Lightning Attention-2, was den Lesern zu einem tieferen Verständnis verhelfen kann.
Figure 3
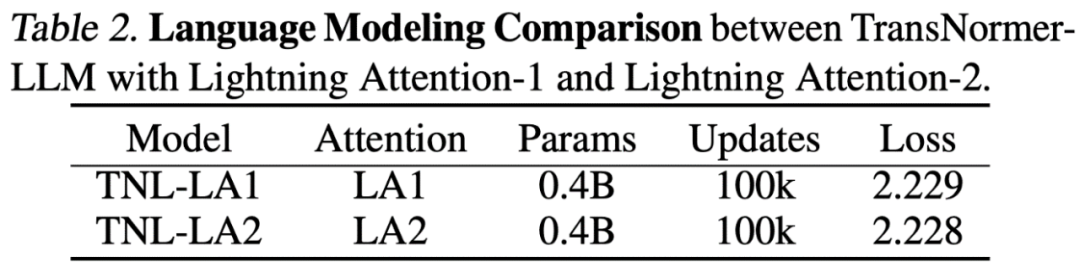
Lightning Achtung-2-Genauigkeitsvergleich Die Forscher verglichen zuerst die Aufmerksamkeit der Blitze auf einem Parametermodell (400 m) mit Blitz mit Blitz Der Genauigkeitsunterschied von Attention-1 ist, wie in der folgenden Abbildung dargestellt, nahezu gleich.
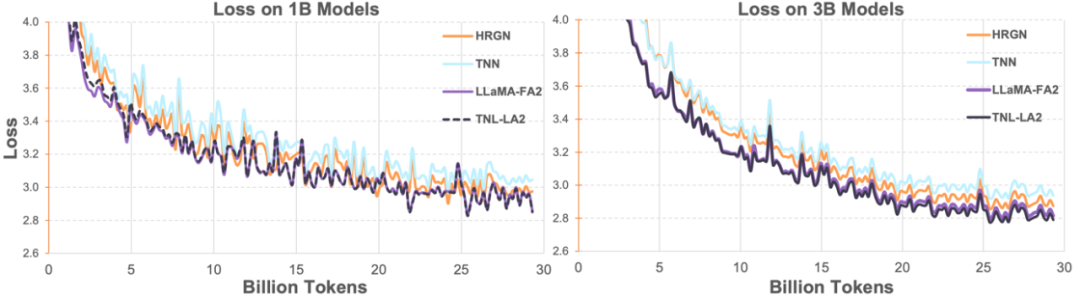
Dann verglichen die Forscher TransNormerLLM (TNL-LA2), das von Lightning Attention-2 unterstützt wird, mit anderen fortschrittlichen Nicht-Transformer-Architekturnetzwerken und LLaMA, das von FlashAttention2 unterstützt wird, auf 1B und 3B unter demselben Korpus. Wie in der folgenden Abbildung dargestellt, behalten TNL-LA2 und LLaMA einen ähnlichen Trend bei und die Verlustleistung ist besser. Dieses Experiment zeigt, dass Lightning Attention-2 eine Genauigkeitsleistung aufweist, die der hochmodernen Transformer-Architektur bei der Sprachmodellierung nicht nachsteht.
In der Aufgabe zum großen Sprachmodell verglichen die Forscher die Ergebnisse von TNL-LA2 15B und Pythia anhand gemeinsamer Benchmarks für große Modelle ähnlicher Größe. Wie in der folgenden Tabelle gezeigt, ist TNL-LA2 unter der Bedingung, dass dieselben Token gegessen werden, etwas höher als das Pythia-Modell, basierend auf der Aufmerksamkeit von Softmax beim gesunden Menschenverstand und den umfassenden Multiple-Choice-Fähigkeiten.
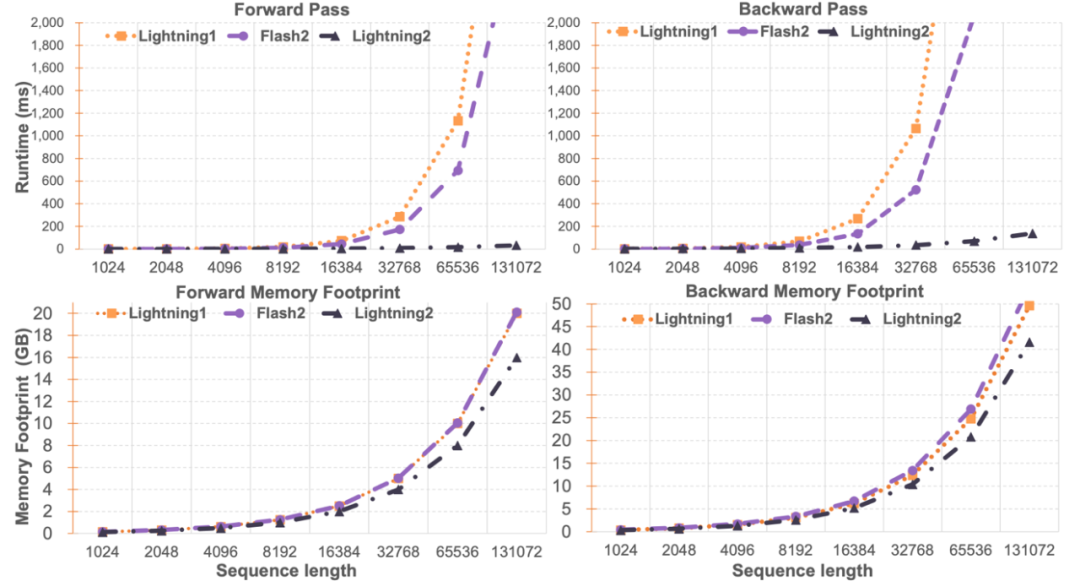
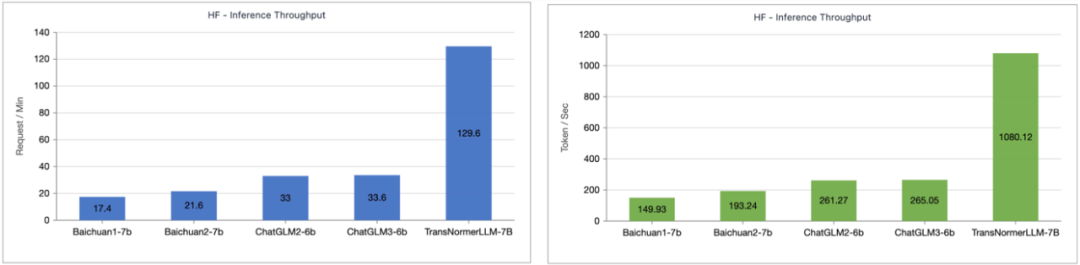
Lightning Attention-2 GeschwindigkeitsvergleichDie Forscher verglichen die Einzelmodulgeschwindigkeit und Speichernutzung von Lightning Attention-2 und FlashAttention2. Wie in der folgenden Abbildung dargestellt, zeigt Lightning Attention-2 im Vergleich zu Lightning Attention-1 und FlashAttention2 einen streng linearen Anstieg der Geschwindigkeit im Vergleich zur Sequenzlänge. Hinsichtlich der Speichernutzung zeigen alle drei ähnliche Trends, Lightning Attention-2 weist jedoch einen geringeren Speicherbedarf auf. Der Grund dafür ist, dass die Speichernutzung von FlashAttention2 und Lightning Attention-1 ebenfalls annähernd linear ist. Der Autor bemerkte, dass sich dieser Artikel hauptsächlich auf die Lösung der Trainingsgeschwindigkeit des linearen Aufmerksamkeitsnetzwerks konzentriert und für lange Sequenzen beliebiger Länge eine Trainingsgeschwindigkeit erreicht, die der von 1K-Sequenzen ähnelt. In Bezug auf die Inferenzgeschwindigkeit gibt es nicht viel Einführung. Dies liegt daran, dass die lineare Aufmerksamkeit während des Denkens verlustfrei in den RNN-Modus umgewandelt werden kann, wodurch ein ähnlicher Effekt erzielt wird, dh die Geschwindigkeit des Denkens für ein einzelnes Token ist konstant. Bei Transformer hängt die Inferenzgeschwindigkeit des aktuellen Tokens von der Anzahl der Token davor ab. Der Autor testete den Vergleich der Inferenzgeschwindigkeit zwischen dem von Lightning Attention-1 unterstützten TransNormerLLM-7B und dem gängigen 7B-Modell. Wie in der folgenden Abbildung dargestellt, beträgt die Durchsatzgeschwindigkeit von Lightning Attention-1 unter der ungefähren Parametergröße das Vierfache der von Baichuan und mehr als das 3,5-fache der von ChatGLM, was einen hervorragenden Vorteil bei der Inferenzgeschwindigkeit darstellt.
Lightning Attention-2 stellt einen großen Fortschritt im linearen Aufmerksamkeitsmechanismus dar und macht es zu einem perfekten Ersatz für die traditionelle Softmax-Aufmerksamkeit in Bezug auf Genauigkeit und Geschwindigkeit und bietet Unterstützung für immer größere Modelle in der Zukunft bietet die Möglichkeit einer nachhaltigen Skalierung und bietet einen Weg, unendlich lange Sequenzen effizienter zu verarbeiten. Das OpenNLPLab-Team wird in Zukunft sequentielle parallele Algorithmen basierend auf linearen Aufmerksamkeitsmechanismen untersuchen, um das derzeit auftretende Problem der Speicherbarriere zu lösen. Das obige ist der detaillierte Inhalt vonLightning Attention-2: Eine neue Generation von Aufmerksamkeitsmechanismen, die eine unendliche Sequenzlänge, konstante Kosten für die Rechenleistung und eine höhere Modellierungsgenauigkeit erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!


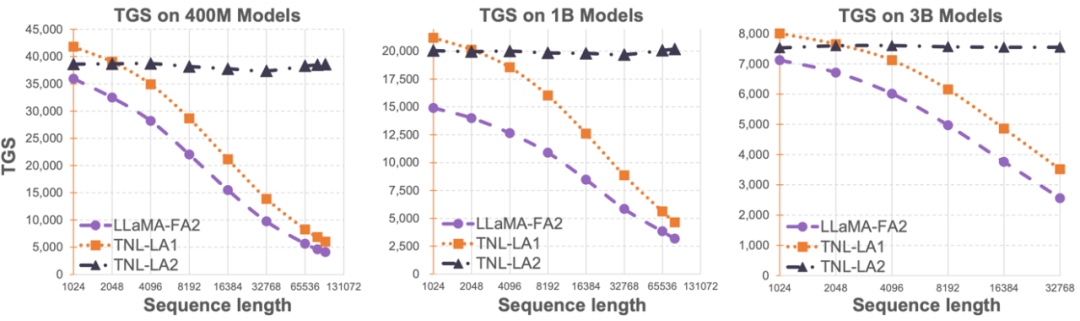 Bild 1
Bild 1