
Heim >Technologie-Peripheriegeräte >KI >Das Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt
Das Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt

- PHPznach vorne
- 2024-01-17 14:12:24957Durchsuche
In den letzten Jahren hat sich die Forschung an großen Modellen beschleunigt und es wurden nach und nach multimodales Verständnis sowie Fähigkeiten zum zeitlichen und räumlichen Denken bei verschiedenen Aufgaben nachgewiesen. Verschiedene verkörperte Betriebsaufgaben von Robotern stellen natürlich hohe Anforderungen an das Sprachbefehlsverständnis, die Szenenwahrnehmung und die räumlich-zeitliche Planung. Dies führt natürlich zu der Frage: Können die Fähigkeiten großer Modelle vollständig genutzt und auf den Bereich der Robotik übertragen werden? die zugrunde liegende Handlungssequenz direkt planen?
ByteDance Research verwendet das Open-Source-Multimodal-Language-Vision-Großmodell OpenFlamingo, um ein benutzerfreundliches RoboFlamingo-Roboterbetriebsmodell zu entwickeln, das nur das Training einer einzelnen Maschine erfordert. VLM kann durch einfache Feinabstimmung in Robotics VLM umgewandelt werden, das für Sprachinteraktionsroboter-Betriebsaufgaben geeignet ist.
Verifiziert durch OpenFlamingo am Roboteroperationsdatensatz CALVIN. Experimentelle Ergebnisse zeigen, dass RoboFlamingo nur 1 % der Daten mit Sprachanmerkungen verwendet und bei einer Reihe von Roboterbetriebsaufgaben SOTA-Leistung erreicht. Mit der Eröffnung des RT-X-Datensatzes wird erwartet, dass RoboFlamingo, das auf Open-Source-Daten vorab trainiert und für verschiedene Roboterplattformen optimiert wurde, zu einem einfachen und effektiven groß angelegten Robotermodellprozess wird. Das Papier testete auch die Feinabstimmungsleistung von VLM mit unterschiedlichen Strategieköpfen, unterschiedlichen Trainingsparadigmen und unterschiedlichen Flamingo-Strukturen bei Roboteraufgaben und kam zu einigen interessanten Schlussfolgerungen.

- Projekthomepage: https://roboflamingo.github.io
- Codeadresse: https://github.com/RoboFlamingo/RoboFlamingo
- Papieradresse: https://arxiv.org/abs/2311.01378
Forschungshintergrund
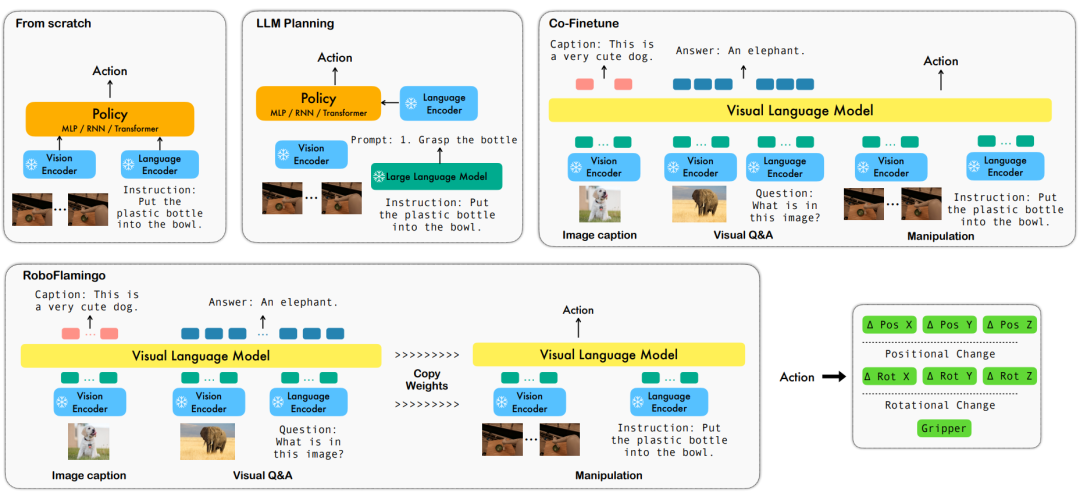
Sprachbasierte Roboterbedienung ist eine wichtige Anwendung im Bereich der verkörperten Intelligenz, die multimodales Datenverständnis umfasst und Verarbeitung, einschließlich Sehen, Sprache und Kontrolle. In den letzten Jahren haben visuelle sprachbasierte Modelle (VLMs) erhebliche Fortschritte in Bereichen wie Bildbeschreibung, visuelle Beantwortung von Fragen und Bildgenerierung gemacht. Die Anwendung dieser Modelle auf Roboteroperationen steht jedoch noch vor Herausforderungen, beispielsweise bei der Integration visueller und sprachlicher Informationen und bei der Bewältigung der zeitlichen Abfolge von Roboteroperationen. Die Lösung dieser Herausforderungen erfordert Verbesserungen in mehreren Aspekten, wie z. B. die Verbesserung der multimodalen Darstellungsfähigkeiten des Modells, die Entwicklung effektiverer Modellfusionsmechanismen und die Einführung von Modellstrukturen und Algorithmen, die sich an die sequentielle Natur von Roboteroperationen anpassen. Darüber hinaus besteht Bedarf an der Entwicklung umfangreicherer Robotik-Datensätze, um diese Modelle zu trainieren und zu bewerten. Durch kontinuierliche Forschung und Innovation wird erwartet, dass sprachbasierte Roboteroperationen eine größere Rolle in praktischen Anwendungen spielen und dem Menschen intelligentere und komfortablere Dienste bieten.
Um diese Probleme zu lösen, hat das Robotik-Forschungsteam von ByteDance Research das bestehende Open-Source-VLM (Visual Language Model) – OpenFlamingo – verfeinert und ein neues visuelles Sprachmanipulations-Framework namens RoboFlamingo entworfen. Das Merkmal dieses Frameworks besteht darin, dass es VLM verwendet, um ein einstufiges visuelles Sprachverständnis zu erreichen, und historische Informationen über ein zusätzliches Richtlinienkopfmodul verarbeitet. Durch einfache Feinabstimmungsmethoden kann RoboFlamingo an sprachbasierte Roboterbedienungsaufgaben angepasst werden. Es wird erwartet, dass die Einführung dieses Frameworks eine Reihe von Problemen lösen wird, die bei aktuellen Roboteroperationen bestehen.
RoboFlamingo wurde anhand des sprachbasierten Roboteroperationsdatensatzes CALVIN verifiziert. Die experimentellen Ergebnisse zeigen, dass RoboFlamingo nur 1 % der sprachannotierten Daten nutzt und bei einer Reihe von Roboteroperationen eine SOTA-Leistung erreicht (mehr als 10 %). Die Erfolgsrate der Aufgabenfolge beim Aufgabenlernen beträgt 66 %, die durchschnittliche Anzahl der Aufgabenerledigungen beträgt 4,09, die durchschnittliche Anzahl der Aufgabenerledigungen beträgt 3,06; %, die durchschnittliche Anzahl der erledigten Aufgaben beträgt 2,48, die Basislinie Die Methode beträgt 1 %, die durchschnittliche Anzahl der erledigten Aufgaben beträgt 0,67) und kann durch Steuerung im offenen Regelkreis eine Echtzeitreaktion erreichen und kann flexibel auf niedrigeren Ebenen eingesetzt werden. Leistungsplattformen. Diese Ergebnisse zeigen, dass RoboFlamingo eine effektive Robotermanipulationsmethode ist und eine nützliche Referenz für zukünftige Roboteranwendungen bieten kann.
Methode
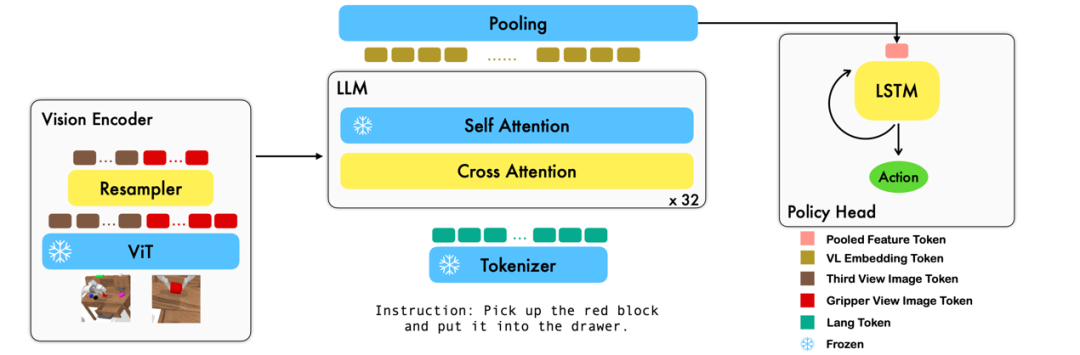
Diese Arbeit nutzt das vorhandene Grundmodell der visuellen Sprache basierend auf Bild-Text-Paaren, um die relativen Aktionen jedes Schritts des Roboters durch durchgängiges Training zu generieren. Das Modell besteht aus drei Hauptmodulen: Vision Encoder, Feature Fusion Decoder und Policy Head. Im Vision-Encoder-Modul wird die aktuelle visuelle Beobachtung zunächst in ViT eingegeben und dann wird der von ViT ausgegebene Token durch den Resampler heruntergesampelt. Dieser Schritt trägt dazu bei, die Eingabedimension des Modells zu reduzieren und dadurch die Trainingseffizienz zu verbessern. Das Feature-Fusion-Decoder-Modul verwendet Text-Tokens als Eingabe und verwendet die Ausgabe des visuellen Encoders als Abfrage über einen Kreuzaufmerksamkeitsmechanismus, wodurch die Fusion von visuellen und sprachlichen Features erreicht wird. In jeder Schicht führt der Feature-Fusion-Decoder zunächst die Queraufmerksamkeitsoperation und dann die Selbstaufmerksamkeitsoperation durch. Diese Operationen helfen dabei, Korrelationen zwischen Sprache und visuellen Merkmalen zu extrahieren, um Roboteraktionen besser zu generieren. Basierend auf den aktuellen und historischen Token-Sequenzen, die vom Feature-Fusion-Decoder ausgegeben werden, gibt der Policy-Kopf direkt die aktuellen 7 DoF-Relativaktionen aus, einschließlich der 6-Dim-Endposition des Roboterarms und des 1-Dim-Greifers Öffnen/Schließen. Führen Sie abschließend ein maximales Pooling für den Feature-Fusion-Decoder durch und senden Sie es an den Policy-Head, um relative Aktionen zu generieren. Auf diese Weise ist unser Modell in der Lage, visuelle und sprachliche Informationen effektiv zu verschmelzen, um präzise Roboterbewegungen zu erzeugen. Dies bietet breite Anwendungsaussichten in Bereichen wie der Robotersteuerung und der autonomen Navigation.
Während des Trainingsprozesses nutzt RoboFlamingo die vorab trainierten Parameter ViT, LLM und Cross Attention und passt nur die Parameter Resampler, Cross Attention und Policy Head fein an. Experimentelle Ergebnisse Im Vergleich zu vorhandenen Datensätzen zu visuell-linguistischen Aufgaben sind die Aufgaben von CALVIN hinsichtlich Sequenzlänge, Aktionsraum und Sprache komplexer und unterstützen eine flexible Spezifikation von Sensoreingaben. CALVIN ist in vier Abschnitte ABCD unterteilt, wobei jeder Abschnitt einem anderen Kontext und Layout entspricht.
Quantitative Analyse:
RoboFlamingo weist in allen Einstellungen und Indikatoren die beste Leistung auf, was zeigt, dass es über eine starke Nachahmungsfähigkeit, visuelle Generalisierungsfähigkeit und Sprachgeneralisierungsfähigkeit verfügt. Full und Lang geben an, ob das Modell mit ungepaarten visuellen Daten trainiert wurde (d. h. visuelle Daten ohne Sprachpaarung); „Enriched“ bezieht sich auf das Einfrieren der Einbettungsschicht des fusionierten Decoders; 
Ablationsexperimente:
Verschiedene Richtlinienköpfe: 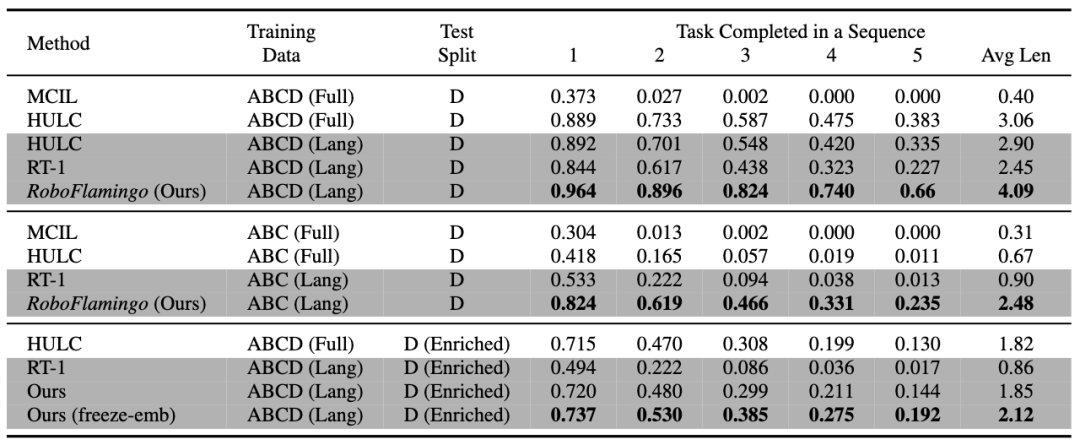
Die Experimente untersuchten vier verschiedene Richtlinienköpfe: MLP ohne Hist, MLP mit Hist, GPT und LSTM. Unter diesen prognostiziert MLP ohne Hist den Verlauf direkt auf der Grundlage aktueller Beobachtungen, und seine Leistung ist am schlechtesten. MLP mit Hist führt historische Beobachtungen am Ende des Vision-Encoders zusammen und sagt Aktionen voraus, und die Leistung wird explizit angegeben An der Spitze der Richtlinie werden implizit historische Informationen verwaltet, und ihre Leistung ist die beste, was die Wirksamkeit der Zusammenführung historischer Informationen durch die Leitung der Richtlinie veranschaulicht.
Die Wirkung des visuellen Sprachvortrainings:
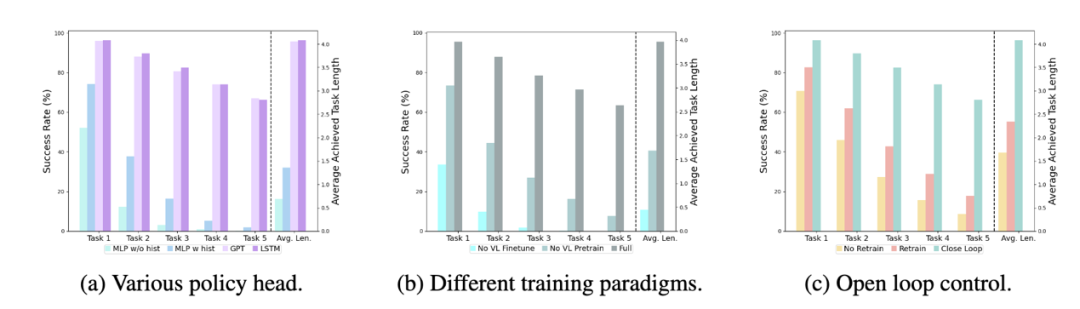 Vortraining spielt eine Schlüsselrolle bei der Verbesserung der Leistung von RoboFlamingo. Experimente zeigen, dass RoboFlamingo bei Roboteraufgaben eine bessere Leistung erbringt, indem es vorab anhand eines großen visuell-linguistischen Datensatzes trainiert.
Vortraining spielt eine Schlüsselrolle bei der Verbesserung der Leistung von RoboFlamingo. Experimente zeigen, dass RoboFlamingo bei Roboteraufgaben eine bessere Leistung erbringt, indem es vorab anhand eines großen visuell-linguistischen Datensatzes trainiert.
Modellgröße und Leistung:
Während im Allgemeinen größere Modelle zu einer besseren Leistung führen, zeigen experimentelle Ergebnisse, dass sogar kleinere Modelle bei einigen Aufgaben mit großen Modellen konkurrieren können.
Auswirkungen der Feinabstimmung von Anweisungen:
Die Feinabstimmung von Anweisungen ist eine leistungsstarke Technik, und experimentelle Ergebnisse zeigen, dass sie die Leistung des Modells weiter verbessern kann.
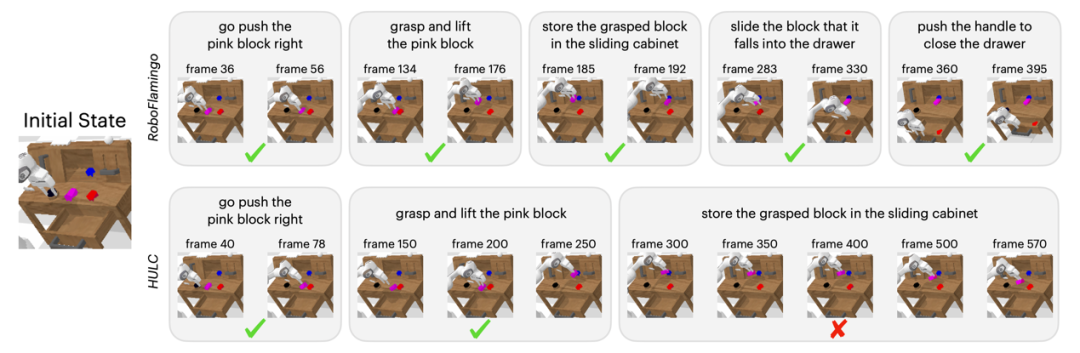
Qualitative Ergebnisse
Im Vergleich zur Baseline-Methode führte RoboFlamingo nicht nur 5 aufeinanderfolgende Teilaufgaben vollständig aus, sondern benötigte auch deutlich weniger Schritte für die ersten beiden Teilaufgaben, die die Baseline-Seite erfolgreich ausführten.
Zusammenfassung
Diese Arbeit stellt ein neuartiges Framework bereit, das auf vorhandenen Open-Source-VLMs für sprachinteraktive Roboterbetriebsstrategien basiert und mit einfacher Feinabstimmung hervorragende Ergebnisse erzielen kann. RoboFlamingo stellt Robotikforschern ein leistungsstarkes Open-Source-Framework zur Verfügung, mit dem sie das Potenzial von Open-Source-VLMs einfacher ausschöpfen können. Die reichhaltigen experimentellen Ergebnisse der Arbeit können wertvolle Erfahrungen und Daten für die praktische Anwendung der Robotik liefern und zur zukünftigen Forschung und Technologieentwicklung beitragen.
Das obige ist der detaillierte Inhalt vonDas Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!