
Heim >Technologie-Peripheriegeräte >KI >ReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert
ReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-17 11:33:281405Durchsuche
Oben geschrieben und das persönliche Verständnis des Autors
Domänenänderungen auf der Sensorebene autonomer Fahrzeuge sind ein sehr häufiges Phänomen, wie z. B. autonome Fahrzeuge in verschiedenen Szenen und Orten, autonome Fahrzeuge unter unterschiedlichen Licht- und Wetterbedingungen, autonome Fahrzeuge, die mit ausgestattet sind Aufgrund der unterschiedlichen Sensorausstattung können die oben genannten als klassische Unterschiede im Bereich des autonomen Fahrens angesehen werden. Dieser Domänenunterschied stellt das autonome Fahren vor Herausforderungen, vor allem weil autonome Fahrmodelle, die auf altem Domänenwissen basieren, ohne zusätzliche Kosten nur schwer direkt in einer neuen, noch nie dagewesenen Domäne implementiert werden können. Daher schlagen wir in diesem Artikel ein Rekonstruktions-Simulations-Bewusstseinsschema (ReSimAD) vor, um eine neue Perspektive und Methode für die Domänenmigration bereitzustellen. Insbesondere verwenden wir die implizite Rekonstruktionstechnologie, um altes Domänenwissen in der Fahrszene zu erhalten. Der Zweck des Rekonstruktionsprozesses besteht darin, zu untersuchen, wie domänenbezogenes Wissen in der alten Domäne in domäneninvariante Darstellungen umgewandelt werden kann Beispielsweise glauben wir, dass 3D-Netzdarstellungen auf Szenenebene (3D-Netzdarstellungen) eine domäneninvariante Darstellung sind. Basierend auf den rekonstruierten Ergebnissen verwenden wir außerdem den Simulator, um eine realistischere Simulationspunktwolke ähnlich der Zieldomäne zu generieren. Dieser Schritt basiert auf den rekonstruierten Hintergrundinformationen und der Sensorlösung der Zieldomäne, wodurch die Erfassungs- und Kennzeichnungszeit verkürzt wird der anschließende Erfassungsprozess.
Wir haben im experimentellen Verifizierungsteil verschiedene domänenübergreifende Einstellungen berücksichtigt, darunter Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE usw. Alle domänenübergreifenden Einstellungen übernehmen experimentelle Zero-Shot-Einstellungen und verlassen sich nur auf das Hintergrundnetz und die simulierten Sensoren der Quelldomäne, um Zieldomänenproben zu simulieren und so die Fähigkeiten zur Modellverallgemeinerung zu verbessern. Die Ergebnisse zeigen, dass ReSimAD die Generalisierungsfähigkeit des Wahrnehmungsmodells auf die Zieldomänenszene erheblich verbessern kann, sogar besser als einige unbeaufsichtigte Domänenanpassungsmethoden.
Papierinformationen

- Papiertitel: ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
- ICLR-2024 akzeptiert
- Publikationseinheit: Shanghai Artificial Intelligence Laboratory, Shanghai Jiao Tong University, Fudan University, Beihang University
- Papieradresse: https://arxiv.org/abs/2309.05527
- Codeadresse: Simulationsdatensatz und Wahrnehmungsteil, https://github.com/PJLab-ADG /3DTrans #resimad; Quelldomänen-Rekonstruktionsteil, https://github.com/pjlab-ADG/neuralsim; Zieldomänen-Simulationsteil, https://github.com/PJLab-ADG/PCSim
Forschungsmotivation
Herausforderung: Obwohl 3D-Modelle selbstfahrenden Autos dabei helfen können, ihre Umgebung zu erkennen, lassen sich bestehende Basismodelle nur schwer auf neue Bereiche übertragen (z. B. unterschiedliche Sensoreinstellungen oder unsichtbare Städte). Die langfristige Vision im Bereich des autonomen Fahrens besteht darin, Modellen eine Domänenmigration zu geringeren Kosten zu ermöglichen, d Es gibt jeweils zwei Domänen mit offensichtlichen Datenverteilungsunterschieden. Beispielsweise ist die Quelldomäne ein 64-Strahl-Sensor und die Zieldomäne ein Regen-Sensor.
Häufig verwendete Lösungsideen: Angesichts der oben genannten Domänenunterschiede besteht die häufigste Lösung darin, Daten für die Zieldomänenszene abzurufen und zu kommentieren. Mit dieser Methode kann die durch Domänenunterschiede verursachte Verschlechterung der Modellleistung bis zu einem gewissen Grad vermieden werden. Problem, aber es gibt enorme 1) Kosten für die Datenerfassung und 2) Kosten für die Datenkennzeichnung. Daher kann, wie in der folgenden Abbildung gezeigt (siehe die beiden Basismethoden (a) und (b)), die Simulations-Engine zum Rendern einiger Simulationen verwendet werden, um die Kosten für die Datenerfassung und Datenanmerkung für eine neue Domäne zu senken Punktwolkenbeispiele Dies sind gängige Lösungsideen für Sim-to-Real-Forschungsarbeiten. Eine weitere Idee ist die unbeaufsichtigte Domänenanpassung (UDA für 3D). Der Zweck dieser Art von Arbeit besteht darin, zu untersuchen, wie eine annähernd vollständig überwachte Feinabstimmung unter der Bedingung erreicht werden kann, dass nur unbeschriftete Zieldomänendaten verfügbar gemacht werden (beachten Sie, dass es sich um echte Daten handelt). ) Wenn dies erreicht werden kann, werden tatsächlich die Kosten für die Kennzeichnung der Zieldomäne eingespart. Die UDA-Methode muss jedoch immer noch eine große Menge realer Zieldomänendaten sammeln, um die Datenverteilung der Zieldomäne zu charakterisieren.
Abbildung 1: Vergleich verschiedener TrainingsparadigmenUnsere Idee: Anders als die Forschungsideen in den beiden oben genannten Kategorien, wie in der Abbildung unten dargestellt (siehe (c) Basisprozess), haben wir uns dem Datensimulations-Wahrnehmungs-Integrationsweg der Kombination von Virtuellem und Realem verschrieben. Darin bezieht sich die Realität auf: Erstellen einer domäneninvarianten Darstellung basierend auf massiven beschrifteten Quelldomänendaten. Diese Annahme ist für viele Szenarien von praktischer Bedeutung, da wir nach einer langfristigen historischen Datenakkumulation immer davon ausgehen können, dass diese kommentierten Quelldomänendaten vorhanden sind ; Andererseits bedeutet Simulation in der Kombination von virtuellen und realen Mitteln: Nachdem wir eine domäneninvariante Darstellung basierend auf den Quelldomänendaten erstellt haben, kann diese Darstellung in die vorhandene Rendering-Pipeline importiert werden, um eine Simulation der Zieldomänendaten durchzuführen. Im Vergleich zu aktuellen Sim-to-Real-Forschungsarbeiten wird unsere Methode durch reale Daten auf Szenenebene unterstützt, einschließlich realer Informationen wie Straßenstruktur, Steigungen und Gefälle usw. Diese Informationen allein durch die Simulations-Engine zu erhalten, ist schwierig selbst. Nachdem wir Daten in der Zieldomäne erhalten haben, integrieren wir die Daten zum Training in das beste aktuelle Wahrnehmungsmodell, wie z. B. PV-RCNN, und überprüfen dann die Genauigkeit des Modells in der Zieldomäne. Den gesamten detaillierten Arbeitsablauf finden Sie in der folgenden Abbildung:
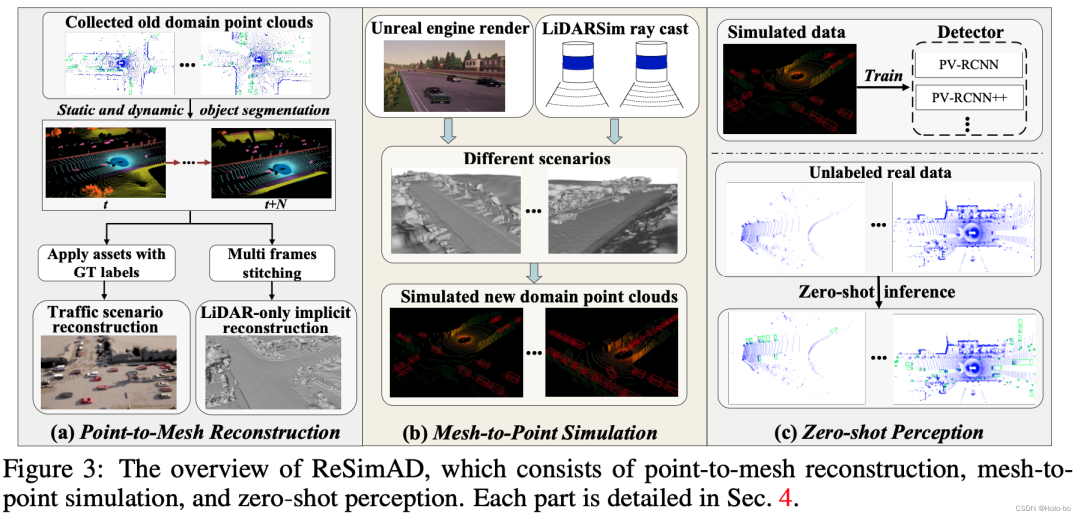 Abbildung 2 ReSimAD-Flussdiagramm
Abbildung 2 ReSimAD-Flussdiagramm
Das Flussdiagramm von ReSimAD ist in Abbildung 2 dargestellt, das hauptsächlich a) impliziten Point-to-Mesh-Rekonstruktionsprozess , umfasst b) Rendering-Prozess der Mesh-to-Point-Simulations-Engine , c) Zero-Sample-Wahrnehmungsprozess .
ReSimAD: Simulations-Rekonstruktions-Wahrnehmungsparadigma
a) Impliziter Point-to-Mesh-Rekonstruktionsprozess: Inspiriert von StreetSurf verwenden wir nur Lidar-Rekonstruktion, um realistische und vielfältige Straßenszenenhintergründe und dynamische Verkehrsflussinformationen zu rekonstruieren. Wir haben zunächst ein reines Punktwolken-SDF-Rekonstruktionsmodul (LiDAR-only Implicit Neural Reconstruction, LINR) entwickelt. Sein Vorteil besteht darin, dass es nicht von einigen Domänenunterschieden beeinflusst wird, die durch die Kameraerfassung verursacht werden, wie z. B. Änderungen der Beleuchtung, Änderungen der Wetterbedingungen. usw. . Das SDF-Rekonstruktionsmodul für reine Punktwolken verwendet LiDAR-Strahlen als Eingabe, sagt dann Tiefeninformationen voraus und erstellt schließlich eine 3D-Netzdarstellung der Szene.
Konkret wenden wir für das Licht 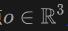 , das vom Ursprung
, das vom Ursprung 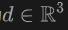 in die Richtung
in die Richtung 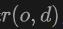 emittiert wird, Volumenrendering auf das Lidar an, um das Signed Distance Field (SDF)-Netzwerk zu trainieren, und die Renderingtiefe D kann wie folgt formuliert werden:
emittiert wird, Volumenrendering auf das Lidar an, um das Signed Distance Field (SDF)-Netzwerk zu trainieren, und die Renderingtiefe D kann wie folgt formuliert werden:
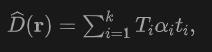
wo ist die Abtasttiefe 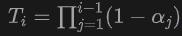 eines Abtastpunkts die akkumulierte Transmission, die durch Verwendung des Nahbereichsmodells in NeuS erhalten wird.
eines Abtastpunkts die akkumulierte Transmission, die durch Verwendung des Nahbereichsmodells in NeuS erhalten wird.
Inspiriert von StreetSurf stammt die Modelleingabe des in diesem Artikel vorgeschlagenen Rekonstruktionsprozesses aus Lidar-Strahlen und die Ausgabe ist die vorhergesagte Tiefe. Auf jeden abgetasteten Lidar-Strahl  wenden wir einen logarithmischen L1-Verlust auf
wenden wir einen logarithmischen L1-Verlust auf 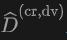 an, d. Aufgrund der inhärenten spärlichen Datenmenge, die von LIDAR erfasst wird, kann ein einzelner LIDAR-Punktwolkenrahmen nur einen Teil der in einem Standard-RGB-Bild enthaltenen Informationen erfassen. Dieser Unterschied verdeutlicht die potenziellen Mängel der Tiefendarstellung bei der Bereitstellung der notwendigen geometrischen Details für ein effektives Training. Dies kann daher zu einer großen Anzahl von Artefakten innerhalb des resultierenden rekonstruierten Netzes führen. Um dieser Herausforderung zu begegnen, schlagen wir vor, alle Frames in einer Waymo-Sequenz zusammenzufügen, um die Dichte der Punktwolke zu erhöhen.
an, d. Aufgrund der inhärenten spärlichen Datenmenge, die von LIDAR erfasst wird, kann ein einzelner LIDAR-Punktwolkenrahmen nur einen Teil der in einem Standard-RGB-Bild enthaltenen Informationen erfassen. Dieser Unterschied verdeutlicht die potenziellen Mängel der Tiefendarstellung bei der Bereitstellung der notwendigen geometrischen Details für ein effektives Training. Dies kann daher zu einer großen Anzahl von Artefakten innerhalb des resultierenden rekonstruierten Netzes führen. Um dieser Herausforderung zu begegnen, schlagen wir vor, alle Frames in einer Waymo-Sequenz zusammenzufügen, um die Dichte der Punktwolke zu erhöhen.
Aufgrund der Einschränkung des vertikalen Sichtfelds des Top LiDAR im Waymo-Datensatz hat die ausschließliche Erfassung von Punktwolken zwischen -17,6° und 2,4° offensichtliche Einschränkungen bei der Rekonstruktion umliegender Hochhäuser. Um dieser Herausforderung zu begegnen, stellen wir eine Lösung vor, die Punktwolken von Side LiDAR in eine Abtastsequenz zur Rekonstruktion integriert. An der Vorder-, Rückseite und an zwei Seiten des autonomen Fahrzeugs sind vier blindfüllende Radare mit einem vertikalen Sichtfeld von [-90°, 30°] installiert, was die Mängel der unzureichenden Sichtfeldreichweite von wirksam ausgleicht das obere Lidar. Aufgrund der unterschiedlichen Punktwolkendichte zwischen seitlichem und oberem LIDAR entscheiden wir uns dafür, dem seitlichen LIDAR ein höheres Stichprobengewicht zuzuweisen, um die Rekonstruktionsqualität von Hochhausszenen zu verbessern.
Bewertung der Rekonstruktionsqualität: Aufgrund der durch dynamische Objekte verursachten Verdeckung und des Einflusses von LIDAR-Rauschen kann eine implizite Darstellung in einer bestimmten Menge an Rauschen für die Rekonstruktion vorhanden sein. Daher haben wir die Rekonstruktionsgenauigkeit bewertet. Da wir umfangreiche annotierte Punktwolkendaten aus der alten Domäne erhalten können, können wir die simulierten Punktwolkendaten der alten Domäne durch erneutes Rendern in der alten Domäne erhalten, um die Genauigkeit des rekonstruierten Netzes zu bewerten. Wir messen die simulierte Punktwolke und die ursprüngliche reale Punktwolke unter Verwendung des quadratischen Mittelfehlers (RMSE) und des Fasenabstands (CD):
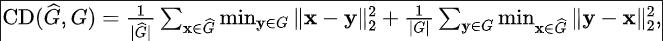
Die Rekonstruktionsbewertung jeder Sequenz und die Beschreibung einiger detaillierter Prozesse finden Sie hier zum Originalanhang.
b) Mesh-to-Point-Simulations-Engine-Rendering-Prozess: Nachdem wir das statische Hintergrundnetz über die obige LINR-Methode erhalten haben, verwenden wir die Blender Python API, um die Netzdaten vom .ply-Format in 3D in .fbx zu konvertieren Modelldateien formatieren und schließlich das Hintergrundnetz als Asset-Bibliothek in den Open-Source-Simulator CARLA laden.
Wir rufen zunächst die Anmerkungsdatei von Waymo ab, um die Begrenzungsrahmenkategorie und die dreidimensionale Objektgröße jedes Verkehrsteilnehmers zu ermitteln. Basierend auf diesen Informationen suchen wir in der digitalen Asset-Bibliothek von CARLA nach den Verkehrsteilnehmern derselben Kategorie mit der größten Größe Assets und importieren Sie dieses digitale Asset als Verkehrsteilnehmermodell. Basierend auf den im CARLA-Simulator verfügbaren Informationen zur Szenenauthentizität haben wir für jedes erkennbare Objekt in der Verkehrsszene ein Erkennungsbox-Extraktionstool entwickelt. Einzelheiten finden Sie unter PCSim Development Tools.
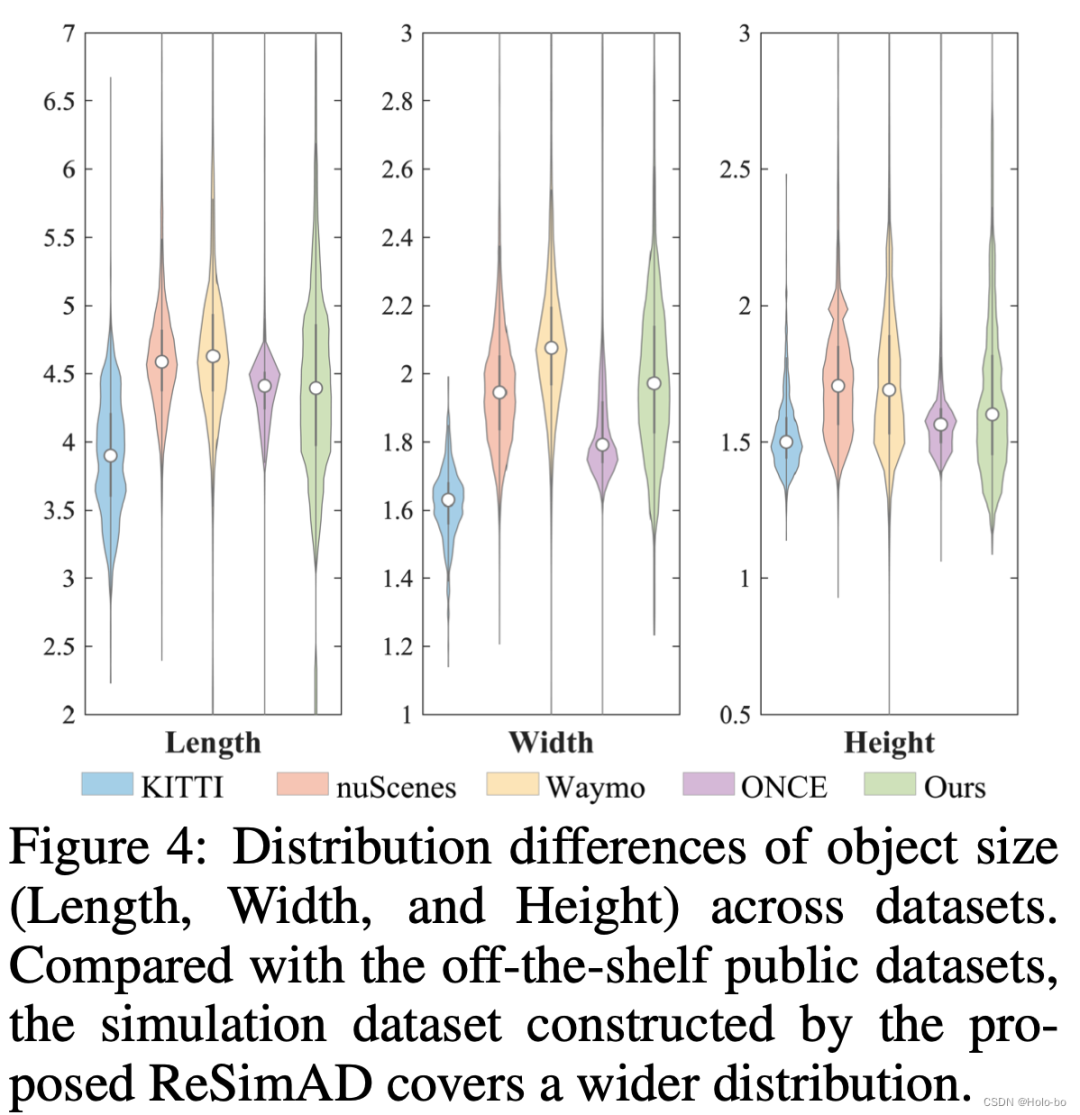 Abbildung 3 Verteilung der Objektgrößen (Länge, Breite, Höhe) von Verkehrsteilnehmern in verschiedenen Datensätzen. Wie aus Abbildung 3 ersichtlich ist, ist die Verteilungsvielfalt der mit dieser Methode simulierten Objektgrößen sehr groß und übertrifft derzeit veröffentlichte Datensätze wie KITTI, nuScenes, Waymo, ONCE usw.
Abbildung 3 Verteilung der Objektgrößen (Länge, Breite, Höhe) von Verkehrsteilnehmern in verschiedenen Datensätzen. Wie aus Abbildung 3 ersichtlich ist, ist die Verteilungsvielfalt der mit dieser Methode simulierten Objektgrößen sehr groß und übertrifft derzeit veröffentlichte Datensätze wie KITTI, nuScenes, Waymo, ONCE usw.
Wir verwenden Waymo als Quelldomänendaten und rekonstruieren sie auf Waymo, um ein realistischeres 3D-Netz zu erhalten. Gleichzeitig verwenden wir KITTI, nuScenes und ONCE als Zieldomänenszenarien und überprüfen die von unserer Methode erzielte Zero-Shot-Leistung in diesen Zieldomänenszenarien.
Wir generieren 3D-Netzdaten auf Szenenebene basierend auf dem Waymo-Datensatz gemäß der Einführung im obigen Kapitel und verwenden die oben genannten Bewertungskriterien, um zu bestimmen, welche 3D-Netze unter der Waymo-Domäne von hoher Qualität sind, und wählen die höchsten 146 aus Netze basierend auf den Ergebnissen. Der anschließende Simulationsprozess der Zieldomäne.
Bewertungsergebnisse
 Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Bewertungsergebnisse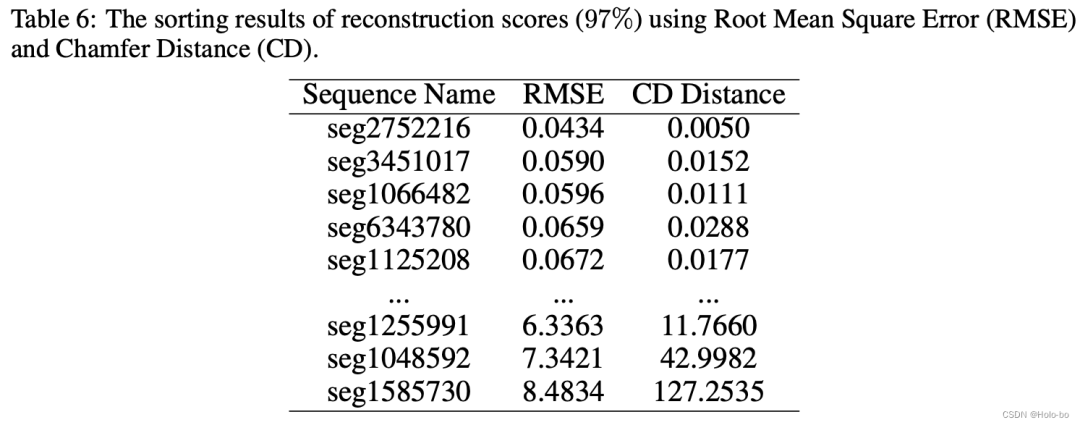 Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt: 
Experimenteller Aufbau
Basisauswahl: Wir vergleichen die vorgeschlagenen ReSim AD mit drei typischen Kreuzen -Domänen-Basislinien werden verglichen: a) eine Basislinie, die die Simulations-Engine direkt für die Datensimulation verwendet; b) eine Basislinie, die eine Datensimulation durchführt, indem die Sensorparametereinstellungen in der Simulations-Engine geändert werden; c) Domänenanpassungs-Baseline (UDA). Metrik: Wir gleichen die aktuellen Bewertungsstandards für die domänenübergreifende 3D-Objekterkennung aus und verwenden BEV-basierte bzw. 3D-basierte AP als Bewertungsmetriken.
- Parametereinstellungen: Einzelheiten finden Sie im Dokument.
- Experimentelle Ergebnisse
Nur die wichtigsten experimentellen Ergebnisse finden Sie in unserem Dokument.
Anpassungsleistung von PV-RCNN/PV-RCNN++-Modellen unter drei domänenübergreifenden Einstellungen
Aus der obigen Tabelle können wir Folgendes beobachten: Der Hauptunterschied zwischen UDA und ReSimAD unter Verwendung der UDA-Technologie (Unsupervised Domain Adaptation) besteht darin, dass erstere Beispiele der Zieldomäne „echte Szenen“ für die Modelldomänenmigration verwendet, während die experimentellen Einstellungen von ReSimAD It erfordert, dass es nicht auf echte Punktwolkendaten in der Zieldomäne zugreifen kann. Wie aus der obigen Tabelle ersichtlich ist, sind die von unserem ReSimAD erzielten domänenübergreifenden Ergebnisse mit denen der UDA-Methode vergleichbar. Dieses Ergebnis zeigt, dass unsere Methode die Kosten für die Datenerfassung erheblich senken und den Umschulungs- und Neuentwicklungszyklus des Modells aufgrund von Domänenunterschieden weiter verkürzen kann, wenn der Lidar-Sensor für kommerzielle Zwecke aufgerüstet werden muss. ReSimAD-Daten werden als Kaltstartdaten der Zieldomäne verwendet, und der Effekt, der auf die Zieldomäne erzielt werden kann
Ein weiterer Vorteil der Verwendung der von ReSimAD generierten Daten besteht darin, dass sie ohne Zugriff verwendet werden können Gleichzeitig kann jede reale Datenverteilung der Zieldomäne erreicht werden. Dieser Prozess ähnelt tatsächlich dem „Kaltstart“-Prozess des autonomen Fahrmodells in neuen Szenarien.
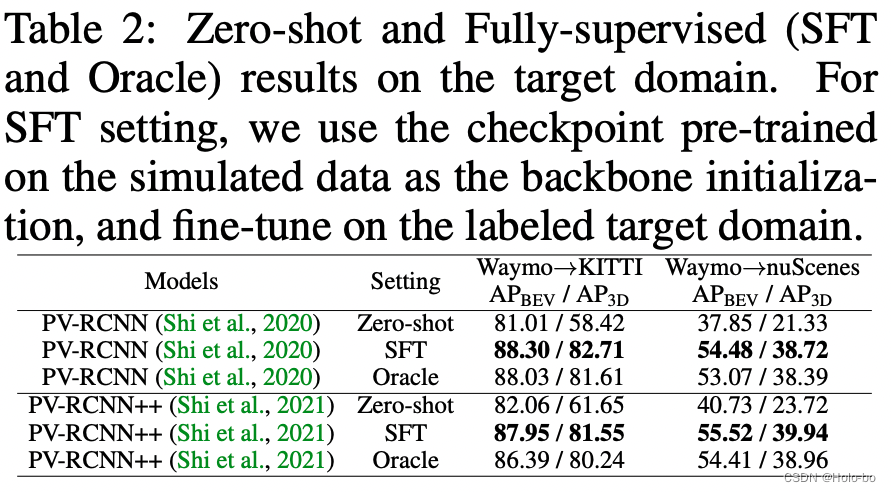 Die obige Tabelle zeigt die experimentellen Ergebnisse unter der vollständig überwachten Zieldomäne. Oracle stellt das Ergebnis des Modelltrainings auf der gesamten Menge der gekennzeichneten Zieldomänendaten dar, während SFT darstellt, dass die Netzwerkinitialisierungsparameter des Basismodells durch die Gewichtungen bereitgestellt werden, die auf den ReSimAD-Simulationsdaten trainiert werden. Die obige experimentelle Tabelle zeigt, dass die mit unserer ReSimAD-Methode simulierte Punktwolke höhere Initialisierungsgewichtungsparameter erhalten kann und ihre Leistung die experimentellen Oracle-Einstellungen übertrifft.
Die obige Tabelle zeigt die experimentellen Ergebnisse unter der vollständig überwachten Zieldomäne. Oracle stellt das Ergebnis des Modelltrainings auf der gesamten Menge der gekennzeichneten Zieldomänendaten dar, während SFT darstellt, dass die Netzwerkinitialisierungsparameter des Basismodells durch die Gewichtungen bereitgestellt werden, die auf den ReSimAD-Simulationsdaten trainiert werden. Die obige experimentelle Tabelle zeigt, dass die mit unserer ReSimAD-Methode simulierte Punktwolke höhere Initialisierungsgewichtungsparameter erhalten kann und ihre Leistung die experimentellen Oracle-Einstellungen übertrifft.
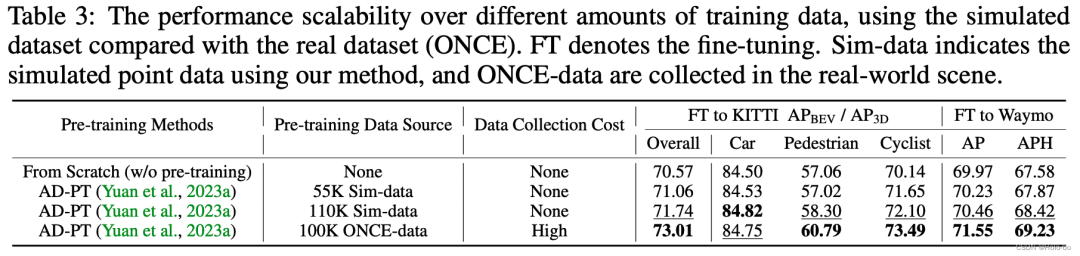
Um zu überprüfen, ob ReSimAD mehr Punktwolkendaten generieren kann, um die 3D-Vorbereitung zu unterstützen -Training, wir entwerfen Die folgenden Experimente wurden durchgeführt: AD-PT (eine kürzlich vorgeschlagene Methode zum Vortraining von Backbone-Netzwerken in autonomen Fahrszenarien) wurde verwendet, um das 3D-Backbone auf der simulierten Punktwolke vorab zu trainieren und dann das Downstream-Real Szenendaten wurden für die Feinabstimmung der vollständigen Parameter verwendet.
- Rekonstruierte Simulation mit ReSimAD vs. visueller Vergleich mit CARLA-Standardsimulation
Visueller Vergleich des Netzes, das wir basierend auf dem Waymo-Datensatz rekonstruiert haben, mit dem mit VDBFusion rekonstruierten Netz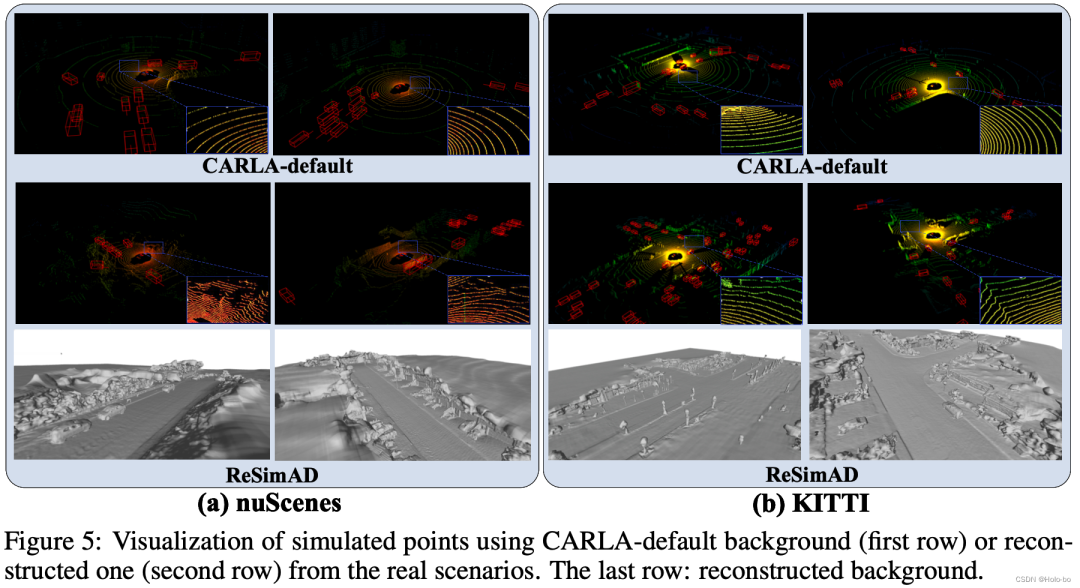
Zusammenfassung 
at In dieser Arbeit konzentrieren wir uns darauf, zu untersuchen, wie man mit Zero-Sample-Zieldomänenmodellübertragungsaufgaben experimentiert. Diese Aufgabe erfordert, dass das Modell das vorab trainierte Modell der Quelldomäne erfolgreich auf das Ziel übertragen kann, ohne dass es irgendwelchen ausgesetzt wird Beispieldateninformationen aus dem Zieldomänenszenario. Im Gegensatz zu früheren Arbeiten haben wir zum ersten Mal eine 3D-Datengenerierungstechnologie untersucht, die auf der impliziten Rekonstruktion der Quelldomäne und der Diversitätssimulation der Zieldomäne basiert, und überprüft, dass diese Technologie ein besseres Modell erzielen kann, ohne der Datenverteilung ausgesetzt zu sein Die Migrationsleistung ist sogar besser als bei einigen unüberwachten Domänenanpassungsmethoden (UDA).
Originallink: https://mp.weixin.qq.com/s/pmHFDvS7nXy-6AQBhvVzSwDas obige ist der detaillierte Inhalt vonReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung der Verwendung des Orbit Controls-Plug-Ins (Orbit Control) durch Three.js zur Steuerung der Modellinteraktion
- Der Unterschied zwischen has und with im Laravel-Assoziationsmodell (ausführliche Einführung)
- Redis-Datentypen und Anwendungsszenarien
- Zu welcher Art von Datenmodell gehört SQL Server?
- So berechnen Sie die Größe des CSS-Box-Modells