
Heim >System-Tutorial >LINUX >Ein Problem, das mich seit einem halben Jahr beschäftigt
Ein Problem, das mich seit einem halben Jahr beschäftigt

- PHPznach vorne
- 2024-01-16 23:33:181479Durchsuche
In diesem Artikel wird ein schwieriger Fehler in einer Virtualisierungsumgebung vorgestellt, der dem Autor seit fast einem halben Jahr Probleme bereitet. Die endgültige Ursache des Fehlers und die Reparaturmethode sind ebenfalls lächerlich. Nicht, weil dieser Prozess kompliziert ist, sondern um einen psychologischen Prozess zu teilen, bei dem darüber nachgedacht wird, wie man bei Fehlern Geschäft und Technologie in Einklang bringt und wie man Suchmaschinen richtig nutzt.
FehlerphänomenWir verfügen über einen Hochleistungs-Proxy-Cluster, der während der internen Testphase stabil lief. Weniger als einen halben Monat nach seiner offiziellen Einführung stürzten jedoch die Hosts, die Proxy-Dienste bereitstellen, plötzlich nacheinander ab, was dazu führte, dass alle Dienste auf den Hosts ausfielen unterbrochen werden.
FehleranalyseWenn ein Fehler auftritt, stürzt der Host direkt ab und kann sich nicht aus der Ferne anmelden. Der Computerraum reagiert auf Tastatureingaben vor Ort. Da das Host-Syslog mit ELK verbunden wurde, haben wir vor und nach dem Absturz verschiedene Syslogs gesammelt.
FehlerprotokollBeim Überprüfen des Syslogs des abgestürzten Hosts habe ich festgestellt, dass der folgende Kernel-Fehler gemeldet wurde, bevor die Maschine abstürzte:
Nov 12 15:06:31 hello-worldkernel: [6373724.634681] BUG: unable to handle kernel NULL pointer dereferenceat 0000000000000078 Nov 12 15:06:31 hello-world kernel: [6373724.634718] IP: []pick_next_task_fair+0x6b8/0x820 Nov 12 15:06:31 hello-world kernel: [6373724.634749] PGD 10561e4067 PUDffdb46067 PMD 0 Nov 12 15:06:31 hello-world kernel: [6373724.634780] Oops: 0000 [#1] SMP
Es zeigt, dass nach dem Zugriff auf den Kernel-Nullzeiger ein Systemfehler ausgelöst wird, der dann eine Reihe von Aufrufstapelfehlern verursacht und schließlich abstürzt.
Um das Fehlerphänomen weiter zu analysieren, müssen Sie zunächst die Architektur dieses Hochleistungs-Proxy-Clusters verstehen.
Einführung in die Architektur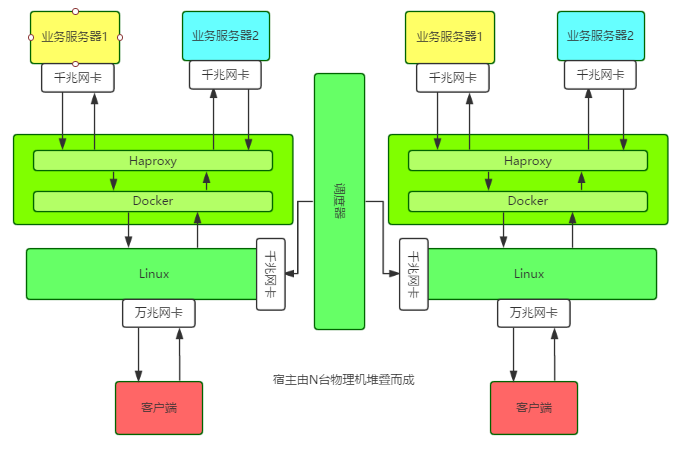
Ein einzelner Knoten führt einen Docker-Container auf einem Host mit einer 10G-Netzwerkkarte aus und führt dann eine Haproxy-Instanz im Container aus. Die Konfigurationsinformationen und Geschäftsinformationen jedes Knotens und jeder Instanz werden auf dem Scheduler gehostet.
Das Besondere ist: Der Host verwendet Linux Bridge, um die IP-Adresse für den Docker-Container direkt zu konfigurieren. Alle externen Service-IPs, einschließlich der eigenen externen Netzwerk-IP, sind an die Linux Bridge gebunden.
AnwendungseinführungDas Betriebssystem, die Hardware und die Docker-Version jedes Hosts sind alle konsistent. Das Betriebssystem und die Docker-Version sind wie folgt:
[操作系统] System : Linux Kernel : 3.16.0-4-amd64 Version : 8.5 Arch : x86_64 [Docker版本] Docker version 1.12.1, build 6b644ecVorläufige Analyse
Die Hostkonfiguration dieses Clusters ist konsistent und die Fehlersymptome sind ebenfalls konsistent. Es gibt drei Zweifel:
1. Die Docker-Version ist nicht mit der Host-Kernel-Version kompatibelDie Umgebungen der drei Hosts sind ursprünglich gleich, aber auf einem Host lief der Dienst zwei Monate lang stabil, bevor er abstürzte, auf einem Host lief der Dienst und stürzte nach einem Monat ab, und auf dem anderen stürzte er ab, nachdem der Dienst eine Woche lang online lief.
Es wurde festgestellt, dass jeder Host zusätzlich zum abnormalen Absturzprotokoll auch über dasselbe Fehlerprotokoll verfügt:
time=”2016-09-07T20:22:19.450573015+08:00″level=warning msg=”Your kernel does not support cgroup memory limit” time=”2016-09-07T20:22:19.450618295+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs period” time=”2016-09-07T20:22:19.450640785+08:00″ level=warningmsg=”Your kernel does not support cgroup cfs quotas” time=”2016-09-07T20:22:19.450769672+08:00″ level=warningmsg=”mountpoint for pids not found”
Den obigen Tipps zufolge sollte die Ursache darin liegen, dass die Kernelversion des Betriebssystems bestimmte Funktionen für diese Docker-Version nicht unterstützt. Die Suche in einer Suchmaschine beeinträchtigt jedoch weder die Funktionalität von Docker noch die Systemstabilität.
Zum Beispiel:
time=”2017-01-19T18:16:30+08:00″level=error msg=”containerd: notify OOM events” error=”openmemory.oom_control: no such file or directory” time=”2017-01-19T18:22:41.368392532+08:00″level=error msg=”Handler for POST /v1.23/containers/338016c68da6/stopreturned error: No such container: 338016c68da6″
Dies ist ein Problem, das seit Docker 1.9 besteht und in 1.12.3 behoben wurde.
Zum Beispiel antwortete jemand auf Github:
“I have been update my docker from 1.11.2 to 1.12.3, This issue is fixed. BTW, this error message can be ignored, it should really just be a warning.”
Aber die hier genannten Probleme sind nur Probleme, die durch Version v1.12.2 behoben werden können. Nachdem wir die Docker-Version aktualisiert hatten, stellten wir fest, dass der Absturz immer noch derselbe war.
So haben wir dann über verschiedene Googles viele Probleme mit dem gleichen Fehlerphänomen wie bei uns bestätigt und zunächst den Zusammenhang zwischen dem Fehler und Docker bestätigt. Basierend auf der offiziellen Ausgabe haben wir auch zunächst bestätigt, dass die Docker-Version nicht mit dem Systemkernel kompatibel ist Version und kann zu Ausfallzeiten führen; dann haben wir durch das offizielle Änderungsprotokoll bestätigt, dass die vom Host verwendete Docker-Version nicht mit der Systemkernel-Version kompatibel ist , aber der Absturz verlief trotzdem ohne Unfälle.
2. Die Verwendung der Linux-Bridge-Methode zum Ändern der Host-Netzwerkkarte kann Fehler auslösenIch habe einen Host gefunden, der nach einer einwöchigen Ausführung des Dienstes abstürzte, Docker nicht mehr ausführte und das Netzwerk nur eine Woche lang stabil lief und keine Auffälligkeiten festgestellt wurden.
3. Die Verwendung von Pipework zum Konfigurieren von IP für Docker-Container kann Fehler auslösenDa wir beim Zuweisen von IPs zu Containern das Open-Source-Pipework-Skript verwendet haben, vermuteten wir, dass es einen Fehler im Funktionsprinzip von Pipework gab, also versuchten wir, IP-Adressen ohne Verwendung von Pipework zuzuweisen, und stellten fest, dass der Host immer noch abstürzte.
Die anfängliche Fehlerbehebung war also problematisch und es war sehr frustrierend, den Host mindestens einmal im Monat abstürzen zu sehen.
故障定位因为还有线上业务在跑,所以没有贸然升级所有宿主内核,而是期望能通过升级Docker或者其它热更新的方式修复问题。但是不断的尝试并没有带来理想中的效果。
直到有一天,在跟一位对Linux内核颇有研究的老司机聊起这个问题时,他三下五除二,Google到了几篇文章,然后提醒我们如果是这个 bug,那是在 Linux 3.18 内核才能修复的。
原因:从sched: Fix race between task_group and sched_task_group的解析来看,就是parent 进程改变了它的task_group,还没调用cgroup_post_fork()去同步给child,然后child还去访问原来的cgroup就会null。
不过这个问题发生在比较低版本的Docker,基本是Docker 1.9以下,而我们用的是Docker1.11.1/1.12.1。所以尽管报错现象比较相似,但我们还是没有100%把握。
但是,这个提醒却给我们打开了思路:去看内核代码,实在不行就下掉所有业务,然后全部升级操作系统内核,保持一个月观察期。
于是,我们开始啃Linux内核代码之路。先查看操作系统本地是否有源码,没有的话需要去Linux kernel官方网站搜索。
下载了源码包后,根据报错syslog的内容进行关键字匹配,发现了以下内容。由于我们的机器是x86_64架构,所以那些avr32/m32r之类的可以跳过不看。结果看下来,完全没有可用信息。
/kernel/linux-3.16.39#grep -nri “unable to handle kernel NULL pointer dereference” * arch/tile/mm/fault.c:530: pr_alert(“Unable to handlekernel NULL pointer dereference/n”); arch/sparc/kernel/unaligned_32.c:221: printk(KERN_ALERT “Unable to handle kernel NULL pointerdereference in mna handler”); arch/sparc/mm/fault_32.c:44: “Unable to handle kernel NULL pointer dereference/n”); arch/m68k/mm/fault.c:47: pr_alert(“Unable tohandle kernel NULL pointer dereference”); arch/ia64/mm/fault.c:292: printk(KERN_ALERT “Unable tohandle kernel NULL pointer dereference (address %016lx)/n”, address); debian/patches/bugfix/all/mpi-fix-null-ptr-dereference-in-mpi_powm-ver-3.patch:20:BUG:unable to handle kernel NULL pointer dereference at (null)
最后,我们还是下线了所有业务,将操作系统内核和Docker版本全部升级到最新版。这个过程有些艰难,当初推广这个系统时拉的广告历历在目,现在下线业务,回炉重造,挺考验勇气和决心的。
故障处理下面是整个故障处理过程中,我们进行的一些操作。
升级操作系统内核对于Docker 1.11.1与内核4.9不兼容的问题,可以删除原有的Docker配置,然后使用官方脚本重新安装最新版本Docker
/proxy/bin#ls /var/lib/dpkg/info/docker-engine. docker-engine.conffiles docker-engine.md5sums docker-engine.postrm docker-engine.prerm docker-engine.list docker-engine.postinst docker-engine.preinst #Getthe latest Docker package. $curl -fsSL https://get.docker.com/ | sh #启动 nohupdocker daemon -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock-s=devicemapper&
这里需要注意的是,Docker安装方式在不同操作系统版本上不尽相同,甚至相同发行版上也有不同,比如原来我们使用以下方式安装Docker:
apt-get install docker-engine
然后在早些时候,还有使用下面的安装方式:
apt-get install lxc-docker
可能是基于原来安装方式的千奇百怪导致问题丛出,所以Docker官方提供了一个脚本用于适配不同系统、不同发行版本Docker安装的问题,这也是一个比较奇怪的地方,所以Docker生态还是蛮乱的。
验证16:44:15 up 28 days, 23:41, 2 users, load average: 0.10, 0.13, 0.15 docker 30320 1 0 Jan11 ? 00:49:56 /usr/bin/docker daemon -p/var/run/docker.pid
Docker内核升级到1.19,Linux内核升级到3.19后,保持运行至今已经2个月多了,都是ok的。
总结这个故障的处理时间跨度很大,都快半年了,想起今年除夕夜收到服务器死机报警的情景,心里像打破五味瓶一样五味杂陈。期间问过不少研究Docker和操作系统内核的同事,往操作系统内核版本等各个方向进行了测试,但总与正确答案背道而驰或差那么一点点。最后发现原来是处理得不够彻底,比如升级不彻底,环境被污染;比如升级的版本不够新,填的坑不够厚。回顾了整个故障处理过程,总结下来大概如下:
回归运维的本质运维要具有预见性、长期规划,而不能仅仅满足于眼前:
- Notfallplan: Fassen Sie die Arten von Fehlern zusammen, die auftreten können, nachdem das System online geht, und stellen Sie einen Notfallplan bereit.
- Den Dienst aufbauen: Priorisieren Sie den Dienst und behandeln Sie dann den Fehler.
- Technische Auswahlprobleme wie die Auswahl der Anwendungsversion: Bei der Bereitstellung der Umgebung und der Auswahl von Anwendungen muss besonders auf verschiedene Versionen geachtet werden. Am besten verwenden Sie Versionen, die in der Community üblich sind oder von anderen getestet oder als machbar verifiziert wurden Studierende im Unternehmen.
- Betriebssystemkernel: Um den Kernel sinnvoll zu aktualisieren, kann die Kernelversion nur gezielt aktualisiert werden, wenn die Probleme in der jeweiligen Version lokalisiert werden, sonst ist alles umsonst.
- In unserem ursprünglichen Design gab es keinen Sperrmechanismus für verschiedene Benutzerplaner, um denselben Container gleichzeitig zu betreiben, und es folgte auch nicht dem Prinzip der Quellenbeurteilung. Es gab auch Migrationsfehler. Bei der Migration wird beurteilt, ob die zu migrierende Zieladresse die lokale Adresse ist. Wenn es sich um eine lokale Adresse handelt, sollte der Vorgang abgelehnt werden. Ich frage mich, ob Ihnen diese Frage bekannt vorkommt. Ich habe festgestellt, dass viele Leute während der Programmentwicklung oft die Eingabequelle oder den Quellstatus des Vorgangs nicht beurteilen, was zu verschiedenen Fehlern führt.
Bei der Behebung dieses Fehlers werden Sie feststellen, dass verschiedene Personen mit Google nach unterschiedlichen Dingen suchen. Warum? Ich denke, dass Suchmaschinen hier voller Mängel oder flexibel sind. Für diesen Fehler habe ich Linux Docker Unable to handle kernel NULL pointer dereferenz für die Suche verwendet, aber die Ergebnisse waren anders als bei anderen, die „Unable to handle kernel NULL pointer dereferenzieren“ verwendet haben. Der Grund dafür ist, dass die Suche nach dem Hinzufügen von „“ präziser wird. Informationen zum richtigen Öffnen von Google.
Das obige ist der detaillierte Inhalt vonEin Problem, das mich seit einem halben Jahr beschäftigt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Eine klassische Algorithmusfrage, die durch einen häufig in Projekten verwendeten Linux-Befehl verursacht wird
- Was ist eine Linux-Zertifizierung?
- So überprüfen Sie die JDK-Version im Linux-System
- So verwenden Sie den Base64-Befehl, um Linux-Befehle zu verschlüsseln und auszuführen
- Wie führt man Protokollaggregation und Statistiken über Linux-Befehlszeilentools durch?