
Heim >System-Tutorial >LINUX >Echtzeitextraktion und protokollbasierte Datensynchronisierungskonsistenz
Echtzeitextraktion und protokollbasierte Datensynchronisierungskonsistenz

- 王林nach vorne
- 2024-01-16 14:36:05733Durchsuche
Autor: Wang Dong
Architekt des CreditEase Technology R&D Center
- Derzeit arbeite ich im CreditEase Technology R&D Center als Architekt und bin verantwortlich für Streaming Computing und Big-Data-Business-Produktlösungen.
- Arbeitete als leitender Ingenieur im China R&D Center von Naver China (dem größten Suchmaschinenunternehmen in Südkorea). Er beschäftigt sich seit vielen Jahren mit der Entwicklung verteilter CUBRID-Datenbankcluster und der CUBRID-Datenbank-Engine http://www.cubrid .org/blog/news/cubrid-cluster-introduction/
Themeneinführung:
- Hintergrundeinführung in DWS
- dbus+Wurmloch-Gesamtarchitektur und technischer Implementierungsplan
- Praktische Anwendungsfälle von DWS
Hallo zusammen, ich bin Wang Dong vom CreditEase Technology R&D Center. Dies ist das erste Mal, dass ich etwas in der Community teile. Bitte korrigieren Sie mich und verzeihen Sie mir.
Das Thema dieses Austauschs ist „Log-basierte DWS-Plattform-Implementierung und -Anwendung“, hauptsächlich um einige der Dinge zu teilen, die wir derzeit bei CreditEase tun. Dieses Thema enthält die Ergebnisse der Bemühungen vieler Brüder und Schwestern der beiden Teams (die Ergebnisse unseres Teams und des Shanwei-Teams). Dieses Mal werde ich es in meinem Namen schreiben und mein Bestes geben, um es Ihnen vorzustellen.
Tatsächlich ist die gesamte Umsetzung im Prinzip relativ einfach und natürlich auch mit viel Technik verbunden. Ich werde versuchen, es so einfach wie möglich auszudrücken, damit jeder das Prinzip und die Bedeutung dieser Angelegenheit versteht. Wenn Sie während des Prozesses Fragen haben, können Sie diese jederzeit stellen und ich werde mein Bestes geben, diese zu beantworten.
DWS ist eine Abkürzung und besteht aus 3 Teilprojekten, die ich später erläutern werde.
1. HintergrundDie Sache beginnt mit den Bedürfnissen des Unternehmens vor einiger Zeit. Jeder weiß, dass sich viele unserer Daten von Standard-Internetunternehmen unterscheiden

In der Vergangenheit gab es mehrere gängige Praktiken:
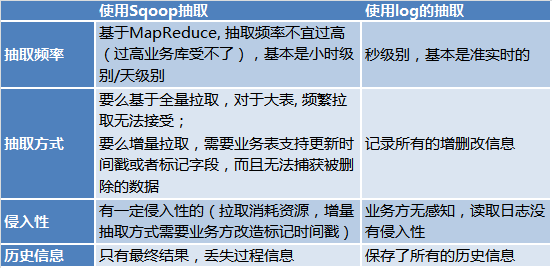
- DBA öffnet die Backup-Datenbank jedes Systems. In Zeiten geringer Geschäftsauslastung (z. B. nachts) können Benutzer die erforderlichen Daten extrahieren. Aufgrund unterschiedlicher Extraktionszeiten, Dateninkonsistenzen zwischen verschiedenen Datenbenutzern, Datenkonflikten und wiederholter Extraktionen haben meiner Meinung nach viele Datenbankadministratoren Kopfschmerzen.
- Die einheitliche Big-Data-Plattform des Unternehmens nutzt Sqoop, um in geschäftsarmen Zeiten einheitlich Daten aus verschiedenen Systemen zu extrahieren, sie in Hive-Tabellen zu speichern und dann Datendienste für andere Datennutzer bereitzustellen. Dieser Ansatz löst das Konsistenzproblem, aber die Aktualität ist schlecht, im Grunde T+1-Aktualität.
- Das Hauptproblem beim Erhalten inkrementeller Änderungen basierend auf Triggern besteht darin, dass die Geschäftsseite sehr aufdringlich ist und Trigger auch Leistungseinbußen verursachen.
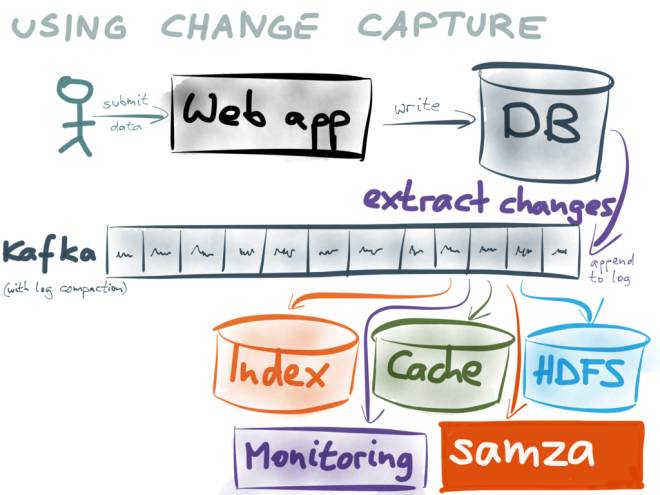
Verwenden Sie inkrementelle Protokolle als Grundlage aller Systeme. Nachfolgende Datenbenutzer verbrauchen Protokolle, indem sie Kafka abonnieren.
Zum Beispiel:
- Benutzer von Big Data können Daten in Hive-Tabellen oder Parquet-Dateien für Hive- oder Spark-Abfragen speichern
- Benutzer, die Suchdienste bereitstellen, können diese in Elasticsearch oder HBase speichern;
- Benutzer, die Caching-Dienste anbieten, können Protokolle in Redis oder Alluxio zwischenspeichern
- Benutzer der Datensynchronisierung können Daten in ihrer eigenen Datenbank speichern;
- Da die Protokolle von Kafka wiederholt genutzt und für einen bestimmten Zeitraum zwischengespeichert werden können, kann jeder Benutzer durch die Nutzung der Protokolle von Kafka die Konsistenz mit der Datenbank aufrechterhalten und die Echtzeitleistung sicherstellen
 Warum nicht Dual Write verwenden? Weitere Informationen finden Sie unter https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
Warum nicht Dual Write verwenden? Weitere Informationen finden Sie unter https://www.confluent.io/blog/using-logs-to-build-a-solid-data-infrastructure-or-why-dual-writes-are-a-bad-idea/
Ich werde hier nicht viel erklären.
So kamen wir auf die Idee, eine Plattform auf Unternehmensebene basierend auf Protokollen aufzubauen.
Im Folgenden wird die DWS-Plattform erläutert. Die DWS-Plattform besteht aus 3 Teilprojekten:
- Dbus (Datenbus): Verantwortlich für das Extrahieren von Daten aus der Quelle in Echtzeit, das Konvertieren in das vereinbarte JSON-Format (UMS-Daten) mit einem eigenen Schema und das Einfügen in Kafka
- Wormhole (Datenaustauschplattform): Verantwortlich für das Lesen von Daten aus Kafka und das Schreiben von Daten auf das Ziel
- Swifts (Echtzeit-Computerplattform): Verantwortlich für das Lesen von Daten aus Kafka, die Berechnung in Echtzeit und das Zurückschreiben von Daten in Kafka.
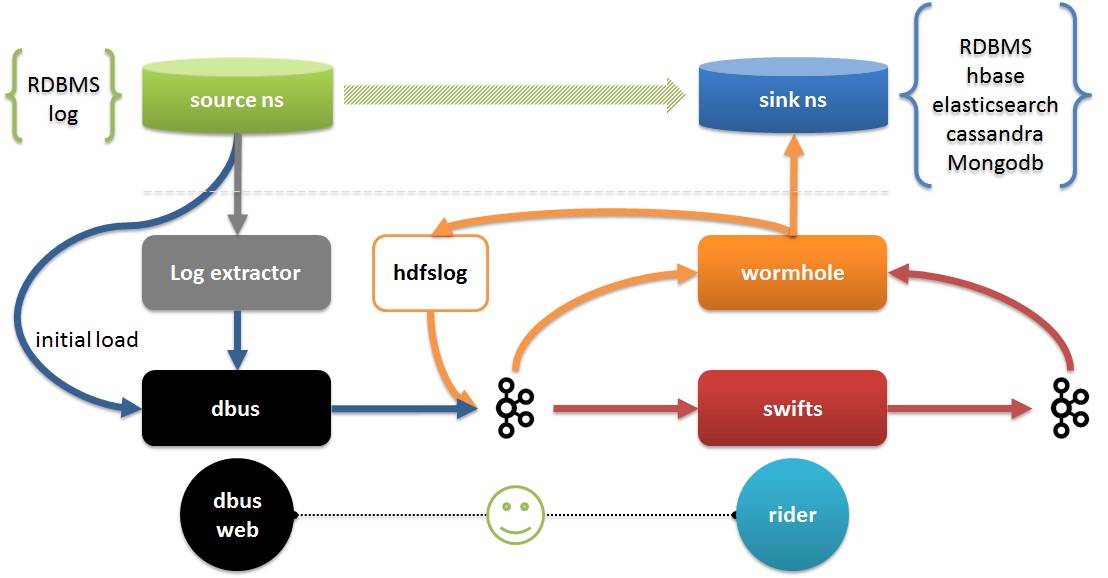
Auf dem Bild:
- Log Extractor und Dbus arbeiten zusammen, um die Datenextraktion und Datenkonvertierung abzuschließen. Die Extraktion umfasst die vollständige und inkrementelle Extraktion.
- Wormhole kann alle Protokolldaten in HDFS speichern; es kann auch Daten in alle Datenbanken implementieren, die JDBC unterstützen, einschließlich HBash, Elasticsearch, Cassandra usw.; Swifts unterstützt Streaming-Berechnungen durch Konfiguration und SQL, einschließlich der Unterstützung von Streaming-Join, Suche, Filter, Fensteraggregation und anderen Funktionen
- Dbus Web ist die Konfigurationsverwaltungsseite von Dbus. Neben der Konfigurationsverwaltung umfasst Rider auch die Laufzeitverwaltung von Wormhole und Swifts, die Überprüfung der Datenqualität usw.
Wir wissen, dass MySQL InnoDB zwar über ein eigenes Protokoll verfügt, die primäre und sekundäre Synchronisierung von MySQL jedoch über binlog erfolgt. Wie unten gezeigt:
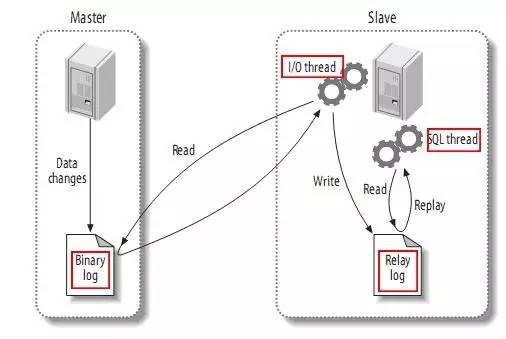
Und Binlog hat drei Modi:
- Zeilenmodus: Die geänderte Form jeder Datenzeile wird im Protokoll aufgezeichnet, und dann werden dieselben Daten auf der Slave-Seite geändert.
- Anweisungsmodus: Jede SQL-Anweisung, die Daten ändert, wird im Bin-Protokoll des Masters aufgezeichnet. Wenn der Slave repliziert, analysiert der SQL-Prozess ihn in denselben SQL-Code, der auf der ursprünglichen Masterseite ausgeführt wurde, und führt ihn erneut aus.
- Gemischter Modus: MySQL unterscheidet die Protokollform, die aufgezeichnet werden soll, basierend auf jeder spezifischen ausgeführten SQL-Anweisung, d. h. es wird zwischen „Anweisung“ und „Zeile“ ausgewählt.

Aufgrund der Unzulänglichkeiten des Anweisungsmodus haben wir während der Kommunikation mit unserem DBA erfahren, dass der Zeilenmodus für die Replikation im eigentlichen Produktionsprozess verwendet wird. Dadurch ist es möglich, das gesamte Protokoll auszulesen.
Normalerweise ist unser MySQL-Layout eine Lösung aus 2 Master-Datenbanken (VIP) + 1 Slave-Datenbank + 1 Backup-Disaster-Recovery-Datenbank. Da die Disaster-Recovery-Datenbank normalerweise für die Remote-Disaster-Recovery verwendet wird, ist die Echtzeitleistung nicht hoch bereitstellen.
Um die Auswirkungen auf die Quellseite zu minimieren, sollten wir natürlich das Binlog-Protokoll aus der Slave-Bibliothek lesen.
Es gibt viele Lösungen zum Lesen von Binlog, und es gibt viele auf Github. Bitte lesen Sie https://github.com/search?utf8=%E2%9C%93&q=binlog. Am Ende haben wir Alibabas Kanal als Protokollextraktionsmethode ausgewählt.
Canal wurde erstmals verwendet, um Alibabas chinesische und amerikanische Computerräume zu synchronisieren. Das Prinzip von Canal ist relativ einfach:
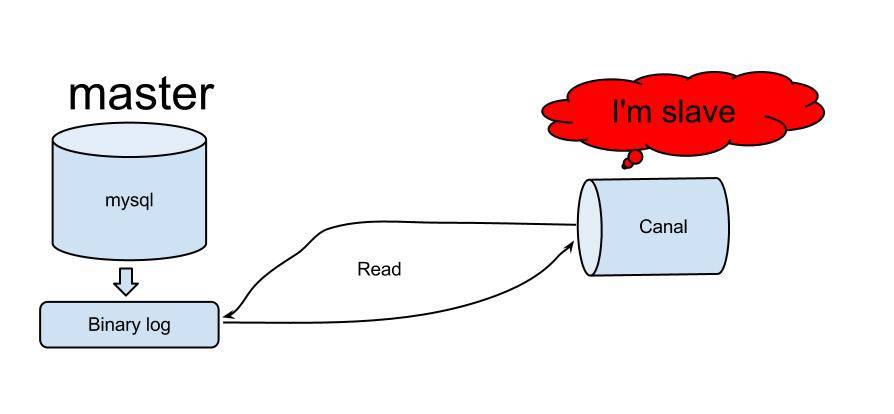
Bild von: https://github.com/alibaba/canal
LösungDie Hauptlösungen für die MySQL-Version von Dbus sind wie folgt:
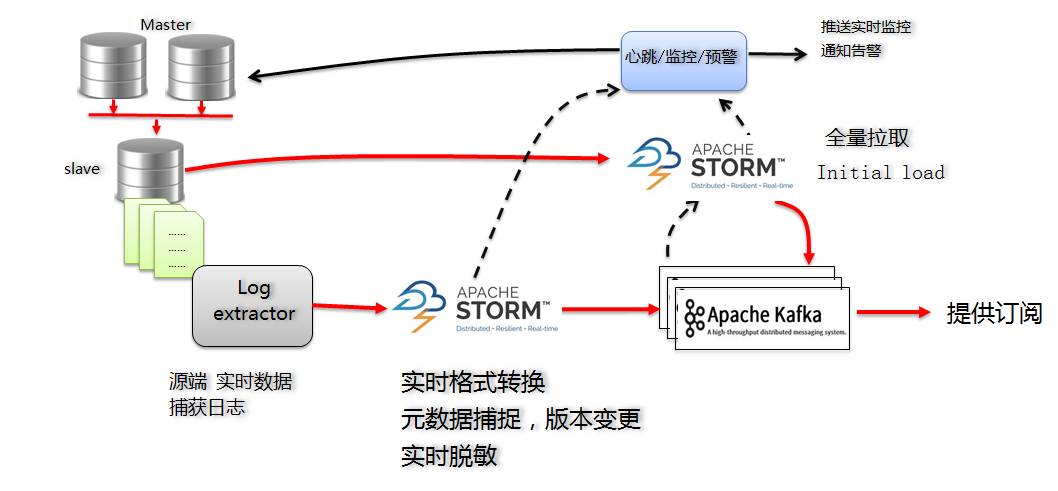
Für inkrementelle Protokolle erhalten wir durch das Abonnieren von Canal Server die inkrementellen Protokolle von MySQL:
- Laut der Ausgabe von Canal liegt das Protokoll im Protobuf-Format vor, um die Daten in Echtzeit in das von uns definierte UMS-Format zu konvertieren (JSON-Format, ich werde es später vorstellen) und in Kafka speichern.
- Das inkrementelle Storm-Programm ist auch für die Erfassung von Schemaänderungen verantwortlich, um die Versionsnummer zu kontrollieren;
- Inkrementelle Storm-Konfigurationsinformationen werden in Zookeeper gespeichert, um Hochverfügbarkeitsanforderungen zu erfüllen.
- Kafka dient sowohl als Ausgabeergebnis als auch als Puffer und Nachrichtendekonstruktionsbereich während der Verarbeitung.
Wenn wir Storm als Lösung in Betracht ziehen, denken wir hauptsächlich, dass Storm die folgenden Vorteile hat:
- Die Technologie ist relativ ausgereift und stabil und kann in Kombination mit Kafka als Standardkombination betrachtet werden;
- Die Echtzeitleistung ist relativ hoch und kann Echtzeitanforderungen erfüllen;
- Erfüllen Sie die Anforderungen an hohe Verfügbarkeit;
- Durch die Konfiguration der Storm-Parallelität können Sie die Möglichkeit aktivieren, die Leistung zu steigern
Für Flusstabellen reicht der inkrementelle Teil aus, aber viele Tabellen müssen die anfänglichen (vorhandenen) Informationen kennen. Zu diesem Zeitpunkt benötigen wir den ersten Ladevorgang (erster Ladevorgang).
Für den ersten Ladevorgang (erster Ladevorgang) haben wir außerdem ein Storm-Programm zur vollständigen Extraktion entwickelt, um über eine JDBC-Verbindung Daten aus der Standby-Datenbank der Quelldatenbank abzurufen. Der anfängliche Ladevorgang besteht darin, alle Daten abzurufen. Wir empfehlen daher, dies während geschäftsschwacher Spitzenzeiten durchzuführen. Glücklicherweise macht man das nur einmal und muss es nicht jeden Tag machen.
Um die volle Menge herauszuholen, greifen wir auf die Ideen von Sqoop zurück. Die vollständige Extraktion von Storm ist in zwei Teile unterteilt:
- Daten Sharing
- Eigentliche Extraktion
Daten-Sharding muss die Sharding-Spalte berücksichtigen, die Daten entsprechend dem Bereich entsprechend der Konfiguration aufteilen, die Spalte automatisch auswählen und die Sharding-Informationen in Kafka speichern.
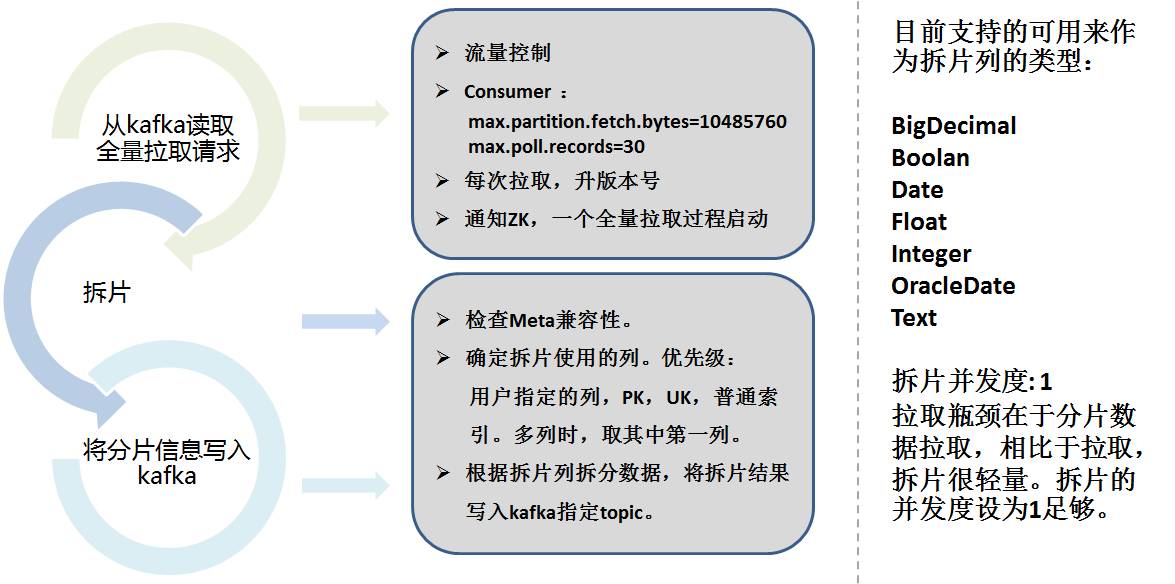
Das Folgende ist die spezifische Sharding-Strategie:
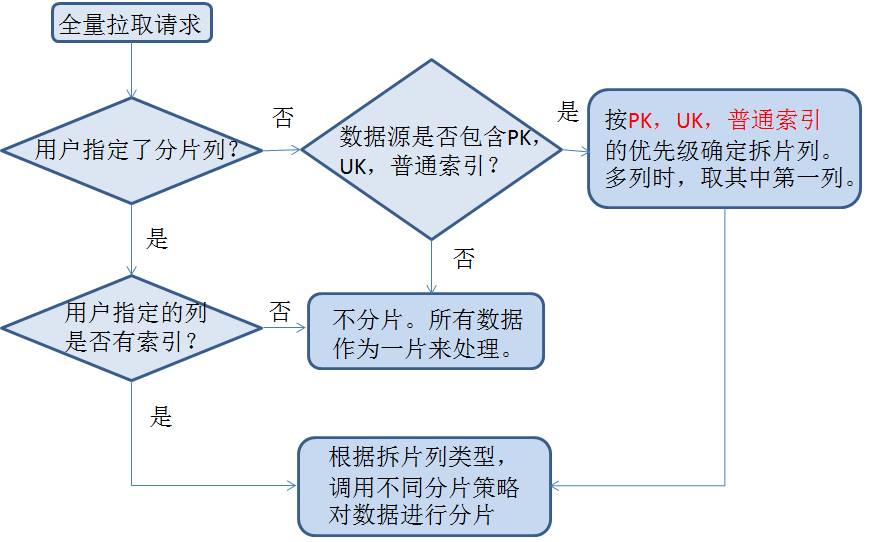
Das Storm-Programm für die vollständige Extraktion liest die Sharding-Informationen von Kafka und verwendet mehrere Parallelitätsebenen, um zum Abrufen parallel eine Verbindung zur Standby-Datenbank herzustellen. Denn die Extraktionszeit kann sehr lang sein. Während des Extraktionsprozesses wird der Echtzeitstatus in Zookeeper geschrieben, um die Überwachung des Heartbeat-Programms zu erleichtern.
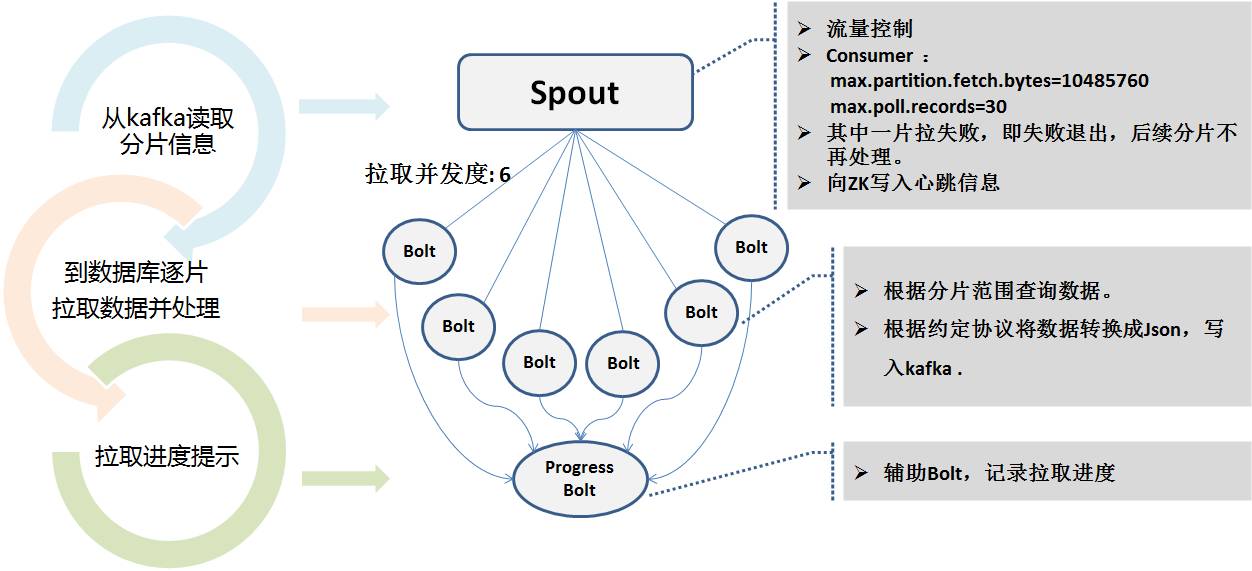
Ob inkrementell oder vollständig, die endgültige Nachrichtenausgabe an Kafka ist ein einheitliches Nachrichtenformat, auf das wir uns geeinigt haben, das sogenannte UMS-Format (Unified Message Schema).
Wie im Bild unten gezeigt:
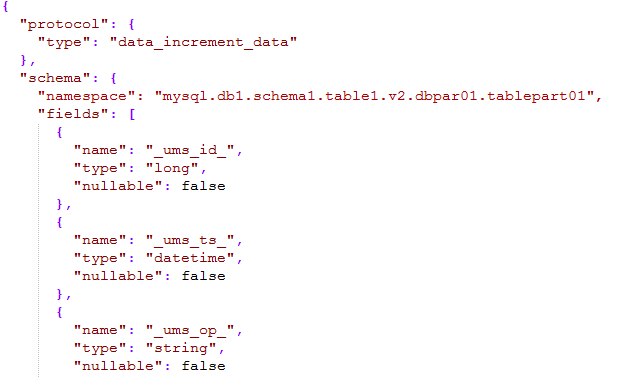

Der Schemateil der Nachricht definiert den Namespace, der aus Typ + Datenquellenname + Schemaname + Tabellenname + Versionsnummer + Unterbibliotheksnummer + Untertabellennummer besteht. Er kann alle Tabellen im gesamten Unternehmen beschreiben kann über einen Namensraum eindeutig lokalisiert werden.
- _ums_op_ gibt an, dass der Datentyp I (einfügen), U (aktualisieren), D (löschen) ist; _ums_ts_ Der Zeitstempel der Hinzufügungs-, Lösch- und Änderungsereignisse wird natürlich aktualisiert
- _ums_id_ Die eindeutige ID der Nachricht, die sicherstellt, dass die Nachricht eindeutig ist, aber hier stellen wir die Reihenfolge der Nachrichten sicher (wird später erklärt);
Die in UMS unterstützten Datentypen beziehen sich auf Hive-Typen und sind vereinfacht und umfassen grundsätzlich alle Datentypen.
Konsistenz von Vollvolumen und inkrementellem Volumen Um die Reihenfolge der Protokollnachrichten so weit wie möglich sicherzustellen, verwendet Kafka bei der gesamten Datenübertragung eine Partitionierungsmethode. Im Allgemeinen ist es grundsätzlich sequentiell und eindeutig.Aber wir wissen, dass das Schreiben von Kafka fehlschlagen wird und Storm möglicherweise auch einen Wiederholungsmechanismus verwendet. Daher garantieren wir nicht unbedingt eine genaue einmalige und vollständige Reihenfolge, aber wir garantieren mindestens einmal.
Daher wird _ums_id_ besonders wichtig.
Für die vollständige Extraktion werden _ums_id_ aus jedem Parallelitätsgrad in zk verwendet, um sicherzustellen, dass die Eingabe negativer Zahlen nicht mit inkrementellen Daten in Konflikt steht und dass diese vor der inkrementellen Menge liegen von Neuigkeiten.
Für die inkrementelle Extraktion verwenden wir die Protokolldateinummer + Protokolloffset von MySQL als eindeutige ID. Id wird als 64 Bit lange Ganzzahl verwendet, die oberen 7 Bits werden für die Protokolldateinummer verwendet und die unteren 12 Bits werden als Protokolloffset verwendet.
Zum Beispiel: 000103000012345678. 103 ist die Protokolldateinummer und 12345678 ist der Protokolloffset.
Auf diese Weise wird die physische Eindeutigkeit ab der Protokollebene sichergestellt (die ID-Nummer ändert sich auch bei einer erneuten Erstellung nicht) und die Reihenfolge wird ebenfalls gewährleistet (das Protokoll kann auch gefunden werden). Durch den Vergleich des _ums_id_-Verbrauchsprotokolls können Sie erkennen, welche Nachricht durch den Vergleich von _ums_id_ aktualisiert wird.
Tatsächlich sind die Absichten von _ums_ts_ und _ums_id_ ähnlich, mit der Ausnahme, dass _ums_ts_ manchmal wiederholt werden kann, d. h. mehrere Vorgänge werden in einer Millisekunde ausgeführt, sodass Sie sich auf den Vergleich von _ums_id_ verlassen müssen.
Herzschlagüberwachung und Frühwarnung Das gesamte System umfasst die Haupt- und Backup-Synchronisation der Datenbank, Canal Server, mehrere gleichzeitige Storm-Prozesse und andere Aspekte.Daher ist die Überwachung und Frühwarnung des Prozesses besonders wichtig.
Über das Heartbeat-Modul wird beispielsweise jede Minute ein Teil der Mentalitätsdaten in jede extrahierte Tabelle eingefügt (konfigurierbar) und die Sendezeit wird ebenfalls gespeichert. Diese Heartbeat-Tabelle wird ebenfalls extrahiert und folgt dem gesamten Prozess, was eigentlich derselbe ist Die synchronisierte Tabellenlogik (da mehrere gleichzeitige Storms unterschiedliche Zweige haben können) kann beim Empfang eines Heartbeat-Pakets nachgewiesen werden, dass die gesamte Verbindung geöffnet ist, auch wenn keine Daten hinzugefügt, gelöscht oder geändert wurden.
Das Storm-Programm und das Heartbeat-Programm senden die Daten an das öffentliche Statistikthema, und das Statistikprogramm speichert sie dann in influxdb. Verwenden Sie Grafana, um sie anzuzeigen, und Sie können den folgenden Effekt sehen:
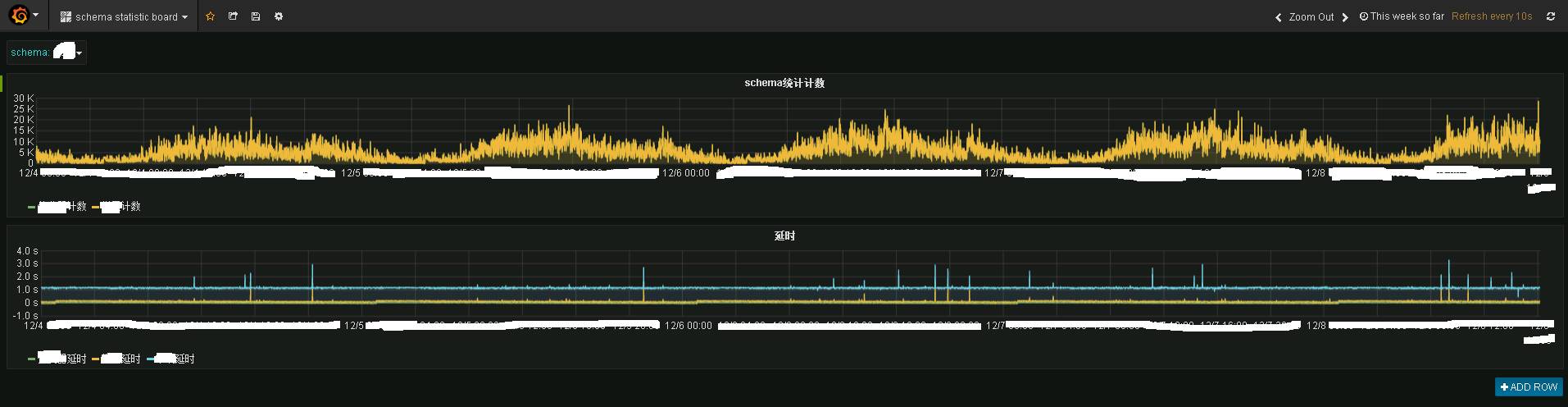 Das Bild zeigt die Echtzeitüberwachungsinformationen eines bestimmten Geschäftssystems. Das Obige ist die Echtzeit-Verkehrssituation und das Folgende ist die Echtzeit-Verzögerungssituation. Es ist zu erkennen, dass die Echtzeitleistung immer noch sehr gut ist. Grundsätzlich wurden die Daten in 1 bis 2 Sekunden an das Terminal Kafka übertragen.
Das Bild zeigt die Echtzeitüberwachungsinformationen eines bestimmten Geschäftssystems. Das Obige ist die Echtzeit-Verkehrssituation und das Folgende ist die Echtzeit-Verzögerungssituation. Es ist zu erkennen, dass die Echtzeitleistung immer noch sehr gut ist. Grundsätzlich wurden die Daten in 1 bis 2 Sekunden an das Terminal Kafka übertragen.
Granfana bietet eine Echtzeitüberwachungsfunktion.
Wenn es zu einer Verzögerung kommt, wird ein E-Mail- oder SMS-Alarm über das Heartbeat-Modul von dbus gesendet.
Desensibilisierung in Echtzeit Unter Berücksichtigung der Datensicherheit bieten die Full-Storm- und Inkremental-Storm-Programme von Dbus auch Echtzeit-Desensibilisierungsfunktionen für Szenarien, in denen eine Desensibilisierung erforderlich ist. Es gibt 3 Möglichkeiten der Desensibilisierung:
 Um es zusammenzufassen: Einfach ausgedrückt exportiert Dbus Daten aus verschiedenen Quellen in Echtzeit und stellt Abonnements in Form von UMS bereit, die Desensibilisierung in Echtzeit, tatsächliche Überwachung und Alarmierung unterstützen.
Um es zusammenzufassen: Einfach ausgedrückt exportiert Dbus Daten aus verschiedenen Quellen in Echtzeit und stellt Abonnements in Form von UMS bereit, die Desensibilisierung in Echtzeit, tatsächliche Überwachung und Alarmierung unterstützen.
Einer der Hauptgründe ist, dass Kafka über natürliche Entkopplungsfunktionen verfügt und das Programm die asynchrone Nachrichtenübermittlung direkt über Kafka durchführen kann. Dbus und Wornhole nutzen Kafka auch intern zur Nachrichtenübermittlung und -entkopplung.
Ein weiterer Grund ist, dass UMS selbstbeschreibend ist. Durch das Abonnieren von Kafka kann jeder fähige Benutzer UMS direkt zur Nutzung nutzen.
Obwohl die Ergebnisse von UMS direkt abonniert werden können, ist noch Entwicklungsarbeit erforderlich. Was Wormhole löst, ist die Bereitstellung einer Ein-Klick-Konfiguration zur Implementierung von Daten in Kafka in verschiedene Systeme, sodass Datenbenutzer ohne Entwicklungsfähigkeiten Daten über Wormhole nutzen können.
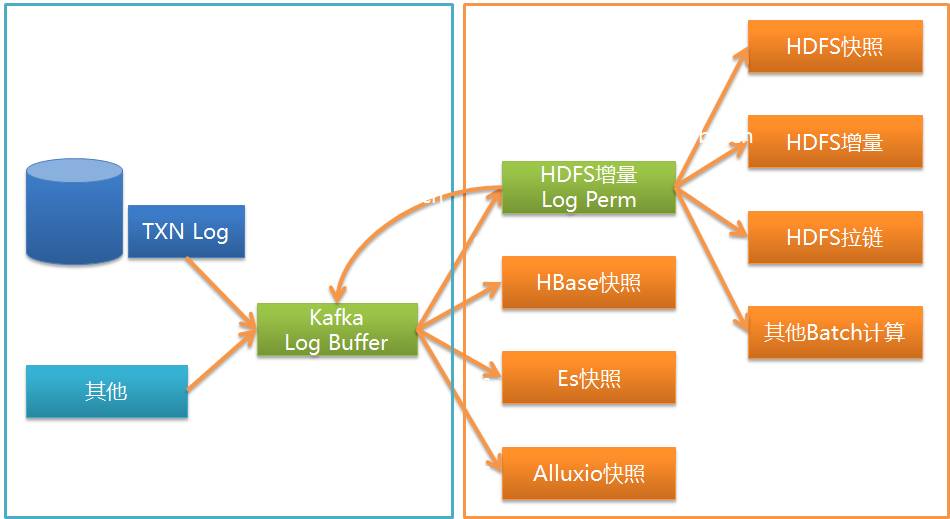
Wie in der Abbildung gezeigt, kann Wormhole UMS in Kafka auf verschiedenen Systemen implementieren. Derzeit werden HDFS, JDBC-Datenbank und HBase am häufigsten verwendet.
In Bezug auf den Technologie-Stack entscheidet sich Wormhole für Spark-Streaming.
In Wormhole bezieht sich ein Fluss von einem Namaspace von der Quelle zum Ziel. Ein Spark-Streaming bedient mehrere Flows.
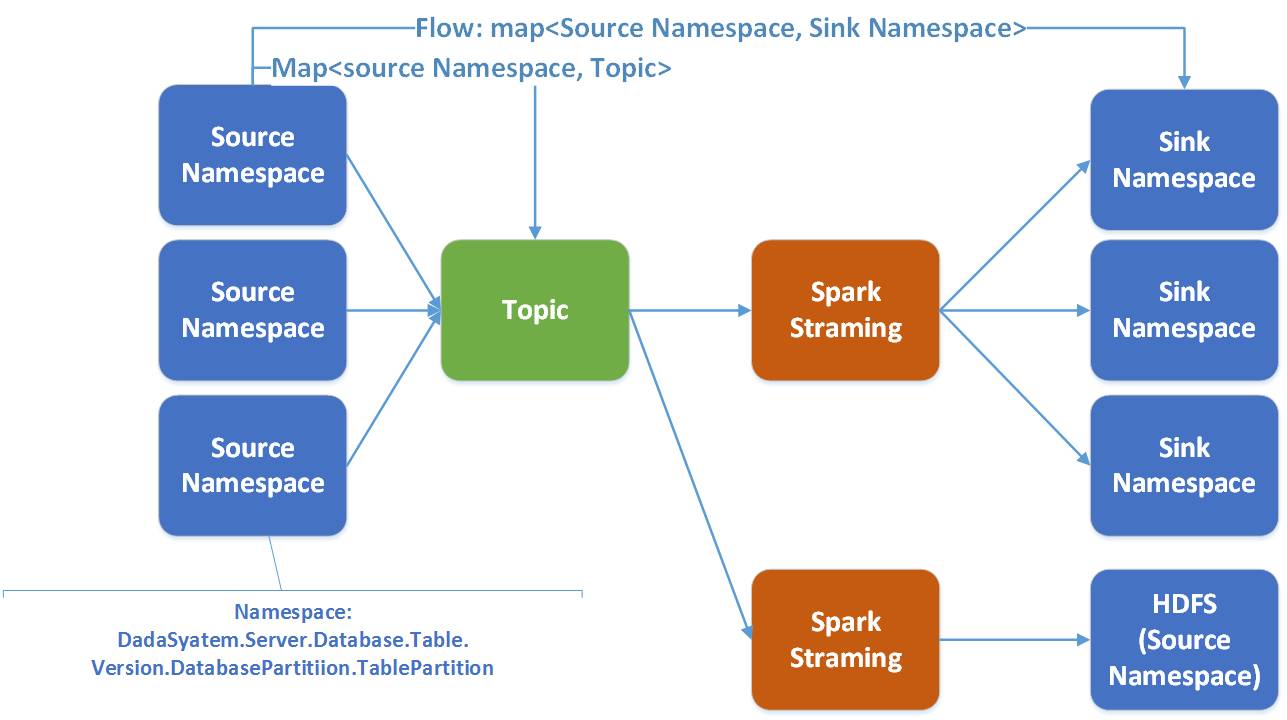
Es gibt gute Gründe, sich für Spark zu entscheiden:
- Spark unterstützt natürlich verschiedene heterogene Speichersysteme
- Obwohl Spark Stream eine etwas schlechtere Latenz als Storm hat, hat Spark einen besseren Durchsatz und eine bessere Rechenleistung
- Spark bietet eine größere Flexibilität bei der Unterstützung paralleler Datenverarbeitung
- Spark bietet einheitliche Funktionen zur Lösung von Sparking Job, Spark Streaming und Spark SQL innerhalb eines Technologie-Stacks, um die spätere Entwicklung zu erleichtern
Hier ist die Funktion von Swifts:
- Die Essenz von Swifts besteht darin, UMS-Daten in Kafka zu lesen, Echtzeitberechnungen durchzuführen und die Ergebnisse in ein anderes Thema in Kafka zu schreiben.
- Echtzeitberechnungen können auf viele Arten durchgeführt werden: z. B. Filter, Projektion (Projektion), Suche, Streaming-Join-Window-Aggregation, wodurch verschiedene Streaming-Echtzeitberechnungen mit Geschäftswert durchgeführt werden können.
Der Vergleich zwischen Wormhole und Swifts ist wie folgt:
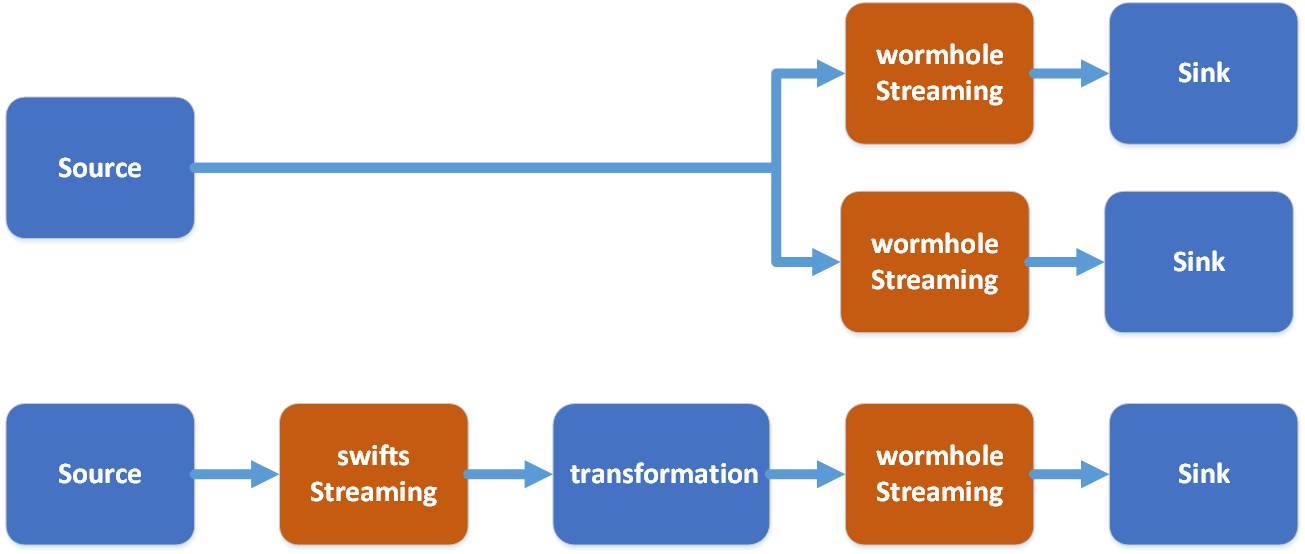
Um Kafkas UMS über das Wormhole Wpark Streaming-Programm zu nutzen, kann zunächst das UMS-Protokoll in HDFS gespeichert werden.
Kafka speichert im Allgemeinen nur einige Tage an Informationen und speichert nicht alle Informationen, während HDFS alle historischen Hinzufügungen, Löschungen und Änderungen speichern kann. Dadurch ist vieles möglich:
- Durch die Wiedergabe von Protokollen in HDFS können wir jederzeit historische Schnappschüsse wiederherstellen.
- Sie können eine Zip-Liste erstellen, um die historischen Informationen jedes Datensatzes für eine einfache Analyse wiederherzustellen Wenn im Programm ein Fehler auftritt, können Sie Backfill verwenden, um die Nachrichten erneut zu verbrauchen und einen neuen Snapshot zu erstellen.
Da Spark Parquet nativ gut unterstützt, kann Spark SQL gute Abfragen für Parquet bereitstellen. Wenn UMS auf HDFS implementiert wird, wird es in einer Parquet-Datei gespeichert. Der Inhalt von Parquet sind die Hinzufügungs-, Lösch- und Änderungsinformationen aller Protokolle sowie _ums_id_ und _ums_ts_.
Wormhole Spark Streaming verteilt und speichert Daten je nach Namespace in verschiedene Verzeichnisse, d. h. unterschiedliche Tabellen und Versionen werden in unterschiedlichen Verzeichnissen abgelegt.
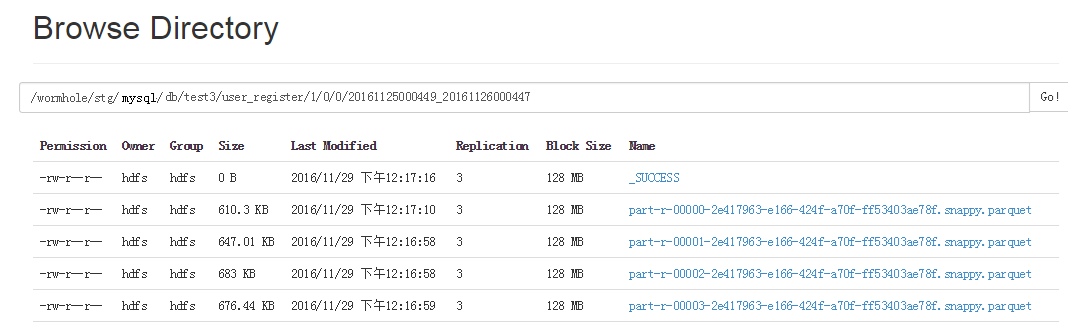
Jedes Parquet-Dateiverzeichnis enthält die Start- und Endzeit der Dateidaten. Auf diese Weise können Sie beim Nachfüllen von Daten entscheiden, welche Parquet-Dateien basierend auf dem ausgewählten Zeitraum gelesen werden müssen, ohne alle Daten lesen zu müssen.
Idempotenz beim Einfügen oder Aktualisieren von Daten Oft besteht die Notwendigkeit, Daten zu verarbeiten und in eine Datenbank oder HBase zu übertragen. Hier stellt sich also die Frage: Welche Art von Daten können aktualisiert werden?
Das wichtigste Prinzip hierbei ist die Idempotenz von Daten.
Egal, ob wir Daten hinzufügen, löschen oder ändern, die Probleme, mit denen wir konfrontiert sind, sind:
- Welche Zeile soll aktualisiert werden
- Was ist die aktualisierte Strategie?
Für die erste Frage müssen Sie tatsächlich einen eindeutigen Schlüssel finden, um die Daten zu finden. Zu den häufigsten gehören:
- Verwenden Sie den Primärschlüssel der Geschäftsbibliothek;
- Die Geschäftspartei gibt mehrere Spalten als gemeinsame eindeutige Indizes an
Bei der zweiten Frage handelt es sich um _ums_id_, da wir sichergestellt haben, dass der große Wert von _ums_id_ aktualisiert wird. Nachdem wir die entsprechende Datenzeile gefunden haben, werden wir sie gemäß diesem Prinzip ersetzen und aktualisieren.
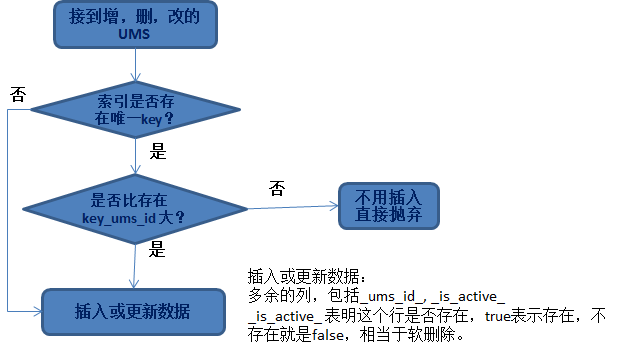
Der Grund, warum wir die Spalte „_ist_aktiv_“ vorläufig löschen und hinzufügen müssen, ist für eine solche Situation:
Wenn die eingefügte _ums_id_ relativ groß ist, handelt es sich um gelöschte Daten (was darauf hinweist, dass die Daten gelöscht wurden). Wenn es sich nicht um eine vorläufige Löschung handelt, fügen Sie zu diesem Zeitpunkt kleine _ums_id_-Daten (alte Daten) ein, die tatsächlich eingefügt werden . .
Dadurch werden alte Daten eingefügt. Nicht mehr idempotent. Daher ist es wichtig, dass die gelöschten Daten weiterhin erhalten bleiben (weiches Löschen) und zur Gewährleistung der Idempotenz der Daten verwendet werden können.
HBase-EinsparungDas Einfügen von Daten in Hbase ist ganz einfach. Der Unterschied besteht darin, dass HBase mehrere Versionen von Daten aufbewahren kann (natürlich können Sie auch nur eine Version aufbewahren).
Beim Einfügen von Daten in HBase müssen folgende Probleme gelöst werden:
- Wählen Sie den entsprechenden Zeilenschlüssel: Das Design des Zeilenschlüssels ist optional. Benutzer können den Primärschlüssel der Quelltabelle oder mehrere Spalten als gemeinsame Primärschlüssel auswählen.
- Wählen Sie die entsprechende Version: Verwenden Sie _ums_id_+ einen größeren Offset (z. B. 10 Milliarden) als Zeilenversion.
Aus Sicht der Leistungsverbesserung können wir die gesamte Spark-Streaming-Dataset-Sammlung ohne Vergleich direkt in HBase einfügen. Lassen Sie HBase basierend auf der Version automatisch für uns ermitteln, welche Daten aufbewahrt werden können und welche nicht.
Daten in JDBC einfügen:
Fügen Sie Daten in die Datenbank ein. Obwohl das Prinzip der Sicherstellung der Idempotenz einfach ist, wird die Implementierung viel komplizierter. Sie können sie nicht einzeln vergleichen und dann einfügen oder aktualisieren.
Wir wissen, dass der RDD/Datensatz von Spark in einer Sammeloperation betrieben wird, um die Leistung zu verbessern. Ebenso müssen wir Idempotenz in einer Sammeloperation erreichen.
Die konkrete Idee ist:
- Fragen Sie zunächst die Zieldatenbank basierend auf dem Primärschlüssel im Satz ab, um einen vorhandenen Datensatz zu erhalten
- Im Vergleich zu den Sammlungen im Datensatz sind sie in zwei Kategorien unterteilt:
B: Vergleichen Sie die vorhandenen Daten mit _ums_id_ und aktualisieren Sie schließlich nur die größeren Zeilen von _ums_id_ in der Zieldatenbank und verwerfen Sie die kleineren Zeilen direkt.
Bei der Betrachtung der Parallelität können sowohl das Einfügen als auch das Aktualisieren fehlschlagen. Daher gibt es auch Strategien, die nach einem Fehler berücksichtigt werden müssen.
Zum Beispiel: Da andere Worker bereits eingefügt haben und das Einfügen aufgrund der Eindeutigkeitsbeschränkung fehlschlägt, müssen Sie es stattdessen aktualisieren und _ums_id_ vergleichen, um zu sehen, ob es aktualisiert werden kann.
Für andere Situationen, in denen das Einfügen nicht möglich ist (z. B. bei Problemen mit dem Zielsystem), verfügt Wormhole auch über einen Wiederholungsmechanismus. Es gibt so viele Details. Hier gibt es nicht viel Einführung.
Einige befinden sich noch in der Entwicklung.
Ich werde nicht näher auf das Einfügen in andere Speicher eingehen. Das allgemeine Prinzip lautet: Entwerfen Sie eine sammlungsbasierte, gleichzeitige Dateneinfügungsimplementierung basierend auf den Eigenschaften jedes Speichers. Dies sind die Leistungsbemühungen von Wormhole, und Benutzer, die Wormhole verwenden, müssen sich darüber keine Sorgen machen.
Nachdem ich so viel gesagt habe: Was sind die praktischen Anwendungen von DWS? Als nächstes werde ich das Echtzeitmarketing vorstellen, das von einem bestimmten System mithilfe von DWS implementiert wird.
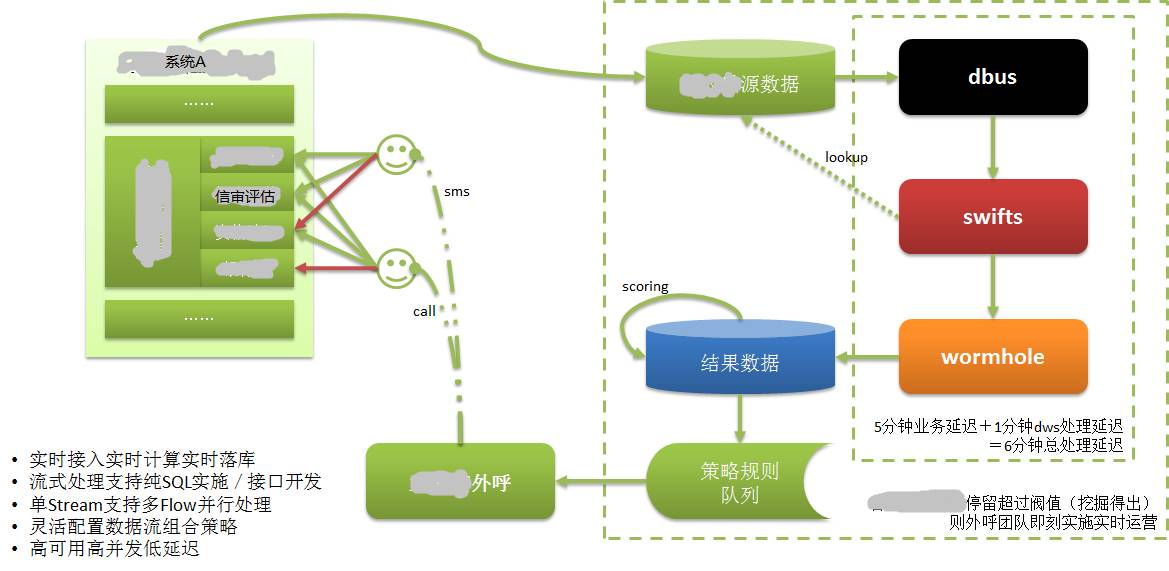
Wie im Bild oben gezeigt:
Die Daten von System A werden in einer eigenen Datenbank gespeichert. Wir wissen, dass CreditEase viele Finanzdienstleistungen anbietet, einschließlich der Kreditaufnahme, und eine sehr wichtige Sache im Kreditaufnahmeprozess ist die Bonitätsprüfung.
Kreditnehmer müssen Informationen vorlegen, die ihre Kreditwürdigkeit belegen, z. B. die Kreditauskunft der Zentralbank, bei der es sich um die Daten mit den stärksten Kreditdaten handelt. Banktransaktionen und Online-Shopping-Transaktionen sind ebenfalls Daten mit starken Bonitätsmerkmalen.
Wenn ein Kreditnehmer über das Web oder die mobile APP Kreditinformationen in System A eingibt, kann er aus irgendeinem Grund möglicherweise nicht fortfahren. Obwohl es sich bei diesem Kreditnehmer möglicherweise um einen hochwertigen potenziellen Kunden handelt, waren diese Informationen in der Vergangenheit nicht verfügbar oder konnte erst seit längerer Zeit bekannt sein, so dass solche Kunden faktisch verloren gehen.
Nach der Anwendung von DWS wurden die vom Kreditnehmer eingegebenen Informationen in der Datenbank erfasst und über DWS in Echtzeit extrahiert, berechnet und in der Zieldatenbank implementiert. Bewerten Sie hochwertige Kunden anhand von Kundenbewertungen. Geben Sie die Kundeninformationen dann sofort an das Kundendienstsystem aus.
Das Kundendienstpersonal kontaktierte den Kreditnehmer (potenziellen Kunden) innerhalb kürzester Zeit (innerhalb weniger Minuten), kümmerte sich um die Kundenbetreuung und verwandelte den potenziellen Kunden in einen echten Kunden. Wir wissen, dass die Kreditaufnahme zeitkritisch ist und keinen Wert hat, wenn sie zu lange dauert.
Ohne die Möglichkeit, in Echtzeit zu extrahieren/berechnen/abzulegen, wäre das alles nicht möglich.
Echtzeit-BerichtssystemEine weitere Echtzeit-Berichtsanwendung ist wie folgt:
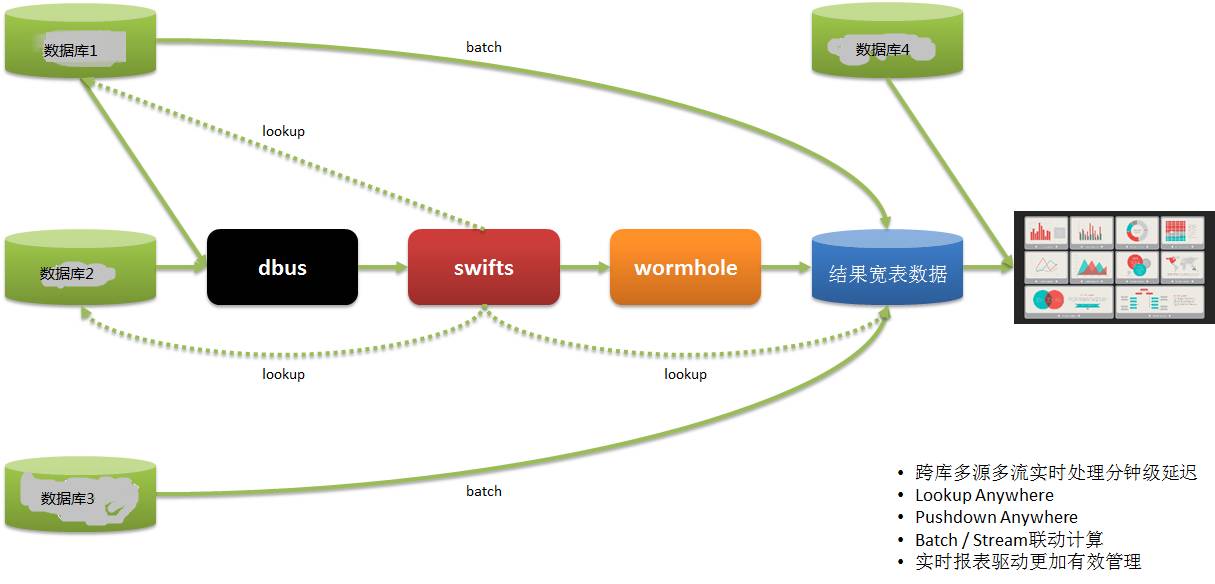
Die Daten unserer Datennutzer stammen aus mehreren Systemen. In der Vergangenheit haben wir T+1 verwendet, um Berichtsinformationen zu erhalten und dann die Abläufe am nächsten Tag zu steuern, was sehr zeitnah war.
Durch DWS werden Daten aus mehreren Systemen in Echtzeit extrahiert, berechnet und umgesetzt sowie Berichte bereitgestellt, sodass der Betrieb rechtzeitig Bereitstellungen und Anpassungen vornehmen und schnell reagieren kann.
Nachdem ich so viel gesagt habe, möchte ich es grob zusammenfassen:
- DWS-Technologie basiert auf dem gängigen Echtzeit-Streaming-Big-Data-Technologie-Framework mit hoher Verfügbarkeit, großem Durchsatz, starker horizontaler Expansion, geringer Latenz und hoher Fehlertoleranz und ist letztendlich konsistent.
- DWS-Funktionen unterstützen heterogene Systeme mit mehreren Quellen und mehreren Zielen, mehrere Datenformate (strukturierte, halbstrukturierte und unstrukturierte Daten) und technische Echtzeitfunktionen.
- DWS kombiniert drei Teilprojekte und startet sie als eine Plattform, wodurch wir Echtzeitfähigkeiten erhalten, um verschiedene Echtzeitszenarioanwendungen voranzutreiben.
Geeignete Szenarien umfassen: Echtzeitsynchronisation/Echtzeitberechnung/Echtzeitüberwachung/Echtzeitberichterstattung/Echtzeitanalyse/Echtzeiteinblick/Echtzeitverwaltung/Echtzeitbetrieb/Echtzeit Entscheidungsfindung
Vielen Dank an alle fürs Zuhören, dieser Austausch endet hier.
F1: Gibt es eine Open-Source-Lösung für den Oracle-Protokollleser?
A1: Es gibt auch viele kommerzielle Lösungen für die Oracle-Branche, wie zum Beispiel: Oracle GoldenGate (ursprüngliches Goldengate), Oracle Xstream, IBM InfoSphere Change Data Capture (ursprünglicher DataMirror), Dell SharePlex (ursprünglicher Quest), inländisches DSG superSync Wait Es gibt nur sehr wenige Open-Source-Lösungen, die einfach zu verwenden sind.
F2: Wie viel Arbeitskraft und materielle Ressourcen wurden in dieses Projekt investiert? Es fühlt sich etwas kompliziert an.
F2: DWS besteht aus drei Teilprojekten mit durchschnittlich 5 bis 7 Personen pro Projekt. Es ist etwas kompliziert, aber es ist tatsächlich ein Versuch, die Big-Data-Technologie zu nutzen, um die Schwierigkeiten zu lösen, mit denen unser Unternehmen derzeit konfrontiert ist.
Weil wir uns mit Big-Data-Technologien beschäftigen, sind alle Brüder und Schwestern im Team sehr glücklich:)
Tatsächlich sind Dbus und Wormhole relativ feste Muster und leicht wiederzuverwenden. Swifts Echtzeit-Computing bezieht sich auf jedes Unternehmen, ist stark anpassbar und relativ mühsam.
F3: Wird das DWS-System von CreditEase Open Source sein?
A3: Wir haben auch darüber nachgedacht, einen Beitrag zur Community zu leisten. Genau wie andere Open-Source-Projekte von Yixin hat das Projekt gerade erst Gestalt angenommen und muss meiner Meinung nach irgendwann in der Zukunft weiterentwickelt werden.
F4: Wie verstehen Sie einen Architekten? Ist er ein Systemingenieur?
A4: Kein Systemingenieur. Wir haben mehrere Architekten bei CreditEase. Sie sollten als technische Manager betrachtet werden, die das Geschäft mit Technologie vorantreiben. Einschließlich Produktdesign, technisches Management usw.
F5: Ist das Replikationsschema OGG?
A5: OGG und andere oben genannte kommerzielle Lösungen sind Optionen.
Quelle des Artikels: DBAplus-Community (dbaplus)
Das obige ist der detaillierte Inhalt vonEchtzeitextraktion und protokollbasierte Datensynchronisierungskonsistenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!