
Heim >Technologie-Peripheriegeräte >KI >Durch die Einführung eines großen inländischen Open-Source-MoE-Modells ist seine Leistung mit Llama 2-7B vergleichbar, während der Rechenaufwand um 60 % reduziert wird
Durch die Einführung eines großen inländischen Open-Source-MoE-Modells ist seine Leistung mit Llama 2-7B vergleichbar, während der Rechenaufwand um 60 % reduziert wird

- PHPznach vorne
- 2024-01-15 21:36:141141Durchsuche
Das Open-Source-MoE-Modell begrüßt endlich seinen ersten inländischen Player!
Seine Leistung ist dem dichten Modell Llama 2-7B nicht unterlegen, aber der Berechnungsbetrag beträgt nur 40 %.
Dieses Modell kann als 19-seitiger Krieger bezeichnet werden, der Lama in Bezug auf seine Mathematik- und Programmierfähigkeiten besonders vernichtet.
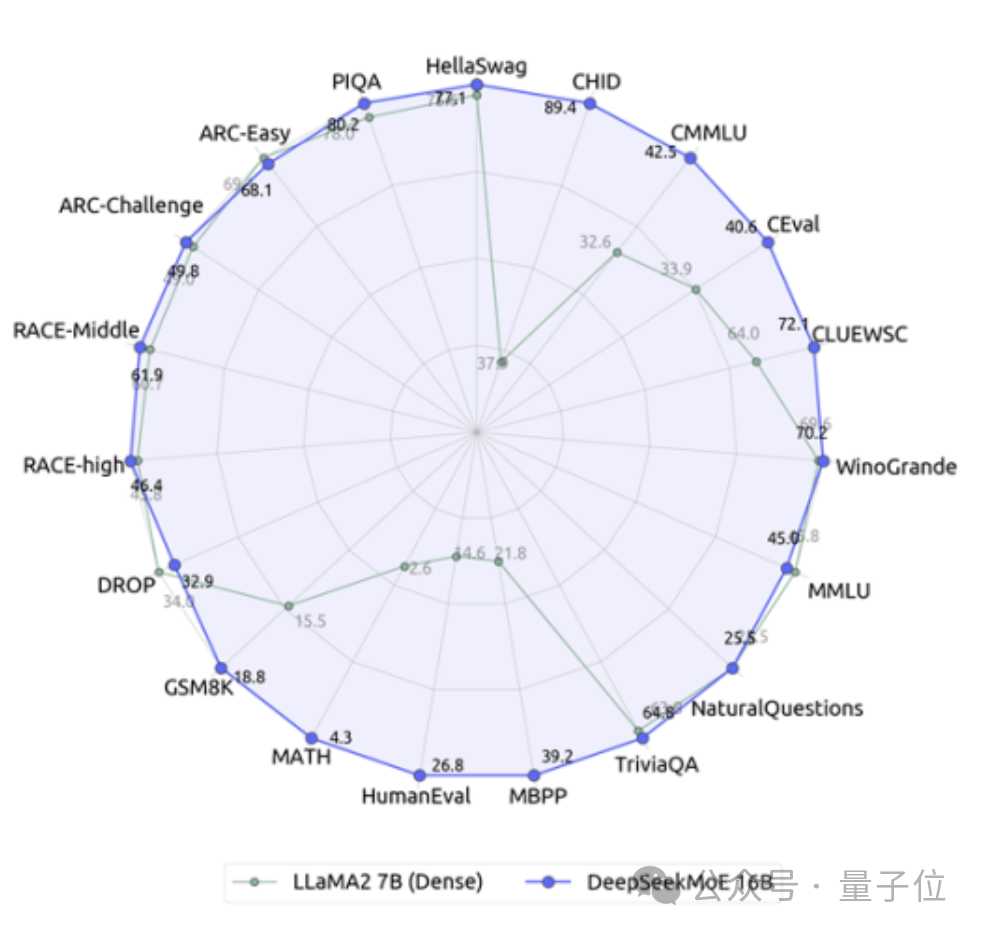
Es ist das neueste Open-Source-Expertenmodell mit 16 Milliarden Parametern, DeepSeek MoE, vom Deep Search-Team.
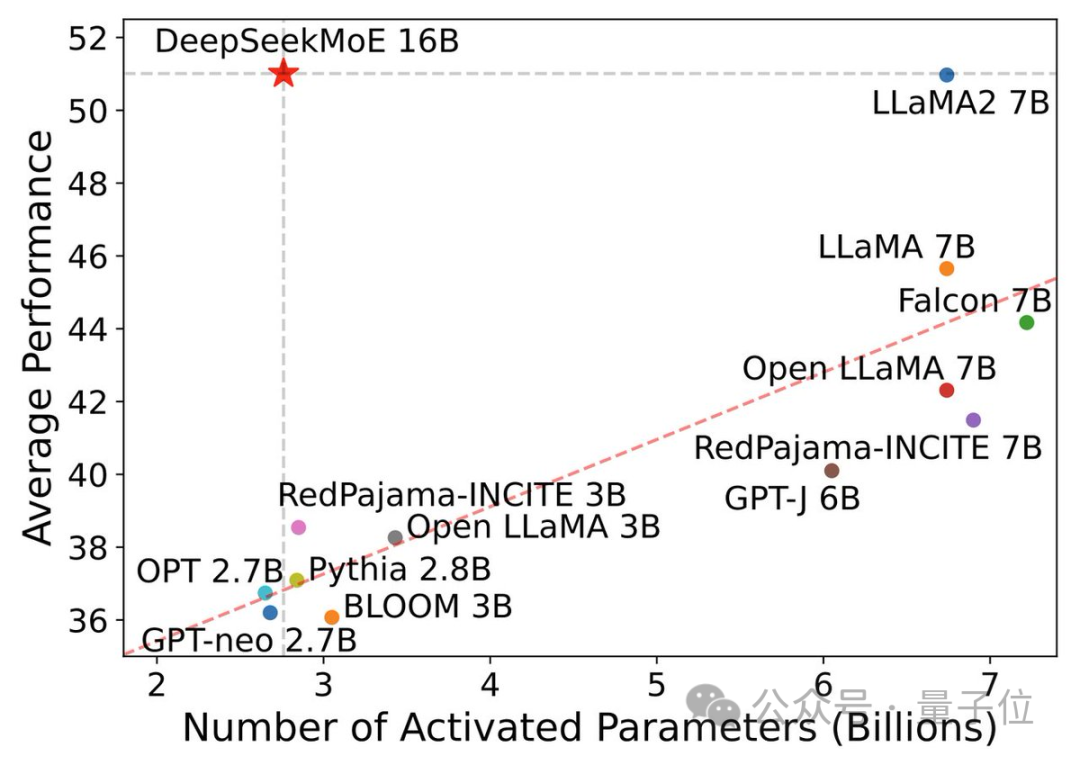
Neben der hervorragenden Leistung liegt das Hauptaugenmerk von DeepSeek MoE auf der Einsparung von Rechenleistung.
In diesem Leistungsaktivierungsparameterdiagramm wird es „hervorgehoben“ und nimmt einen großen leeren Bereich in der oberen linken Ecke ein.
Nur einen Tag nach seiner Veröffentlichung erhielt der Tweet des DeepSeek-Teams auf X eine große Anzahl von Retweets und Aufmerksamkeit.
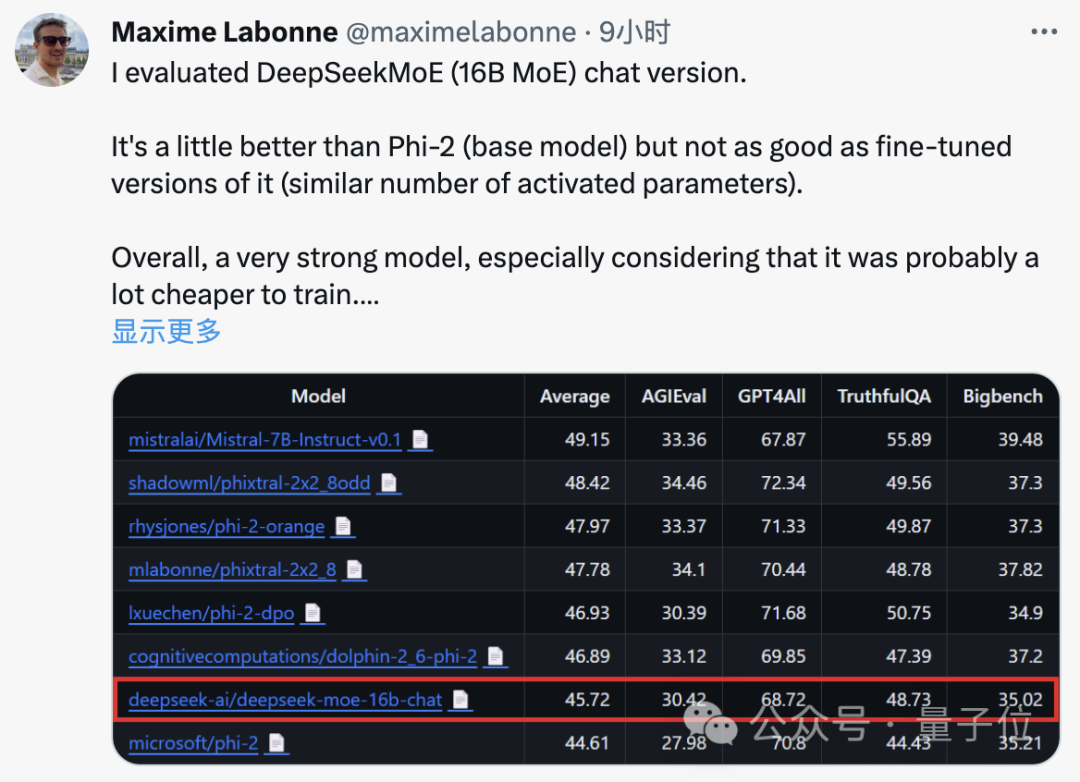
Auch Maxime Labonne, ein Ingenieur für maschinelles Lernen bei JP Morgan, sagte nach dem Testen, dass die Chat-Version von DeepSeek MoE etwas besser abschneidet als Microsofts „kleines Modell“ Phi-2.
Gleichzeitig erhielt DeepSeek MoE auch 300+ Sterne auf GitHub und erschien auf der Homepage der Hugging Face-Textgenerierungsmodell-Rangliste.
Was ist also die spezifische Leistung von DeepSeek MoE?
Der Rechenaufwand wird um 60 % reduziert
Die derzeit eingeführte Version von DeepSeek MoE verfügt über 16 Milliarden Parameter und die tatsächliche Anzahl der aktivierten Parameter beträgt etwa 2,8 Milliarden.
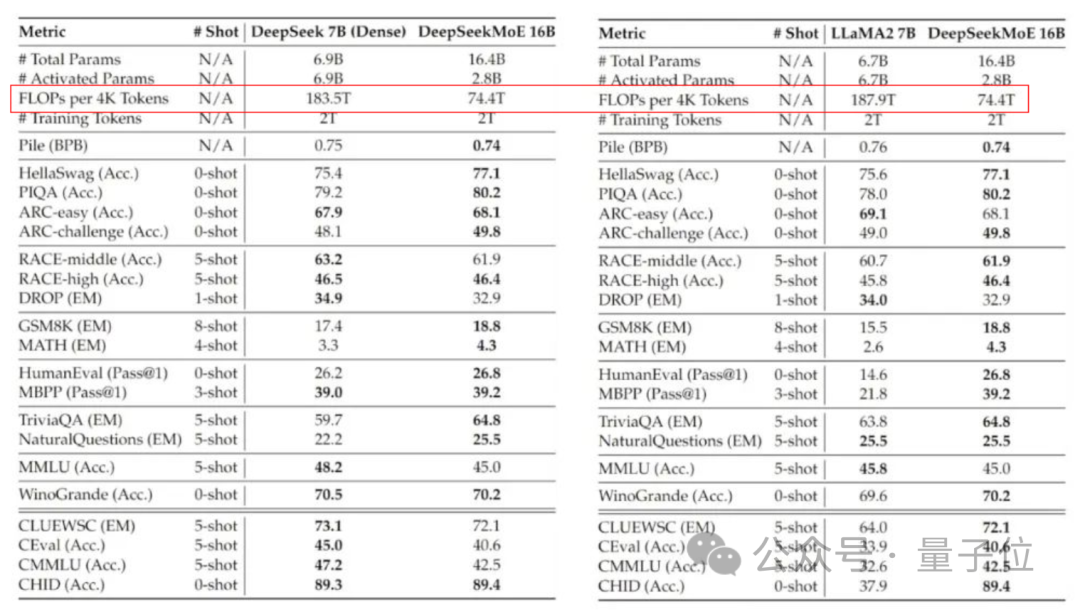
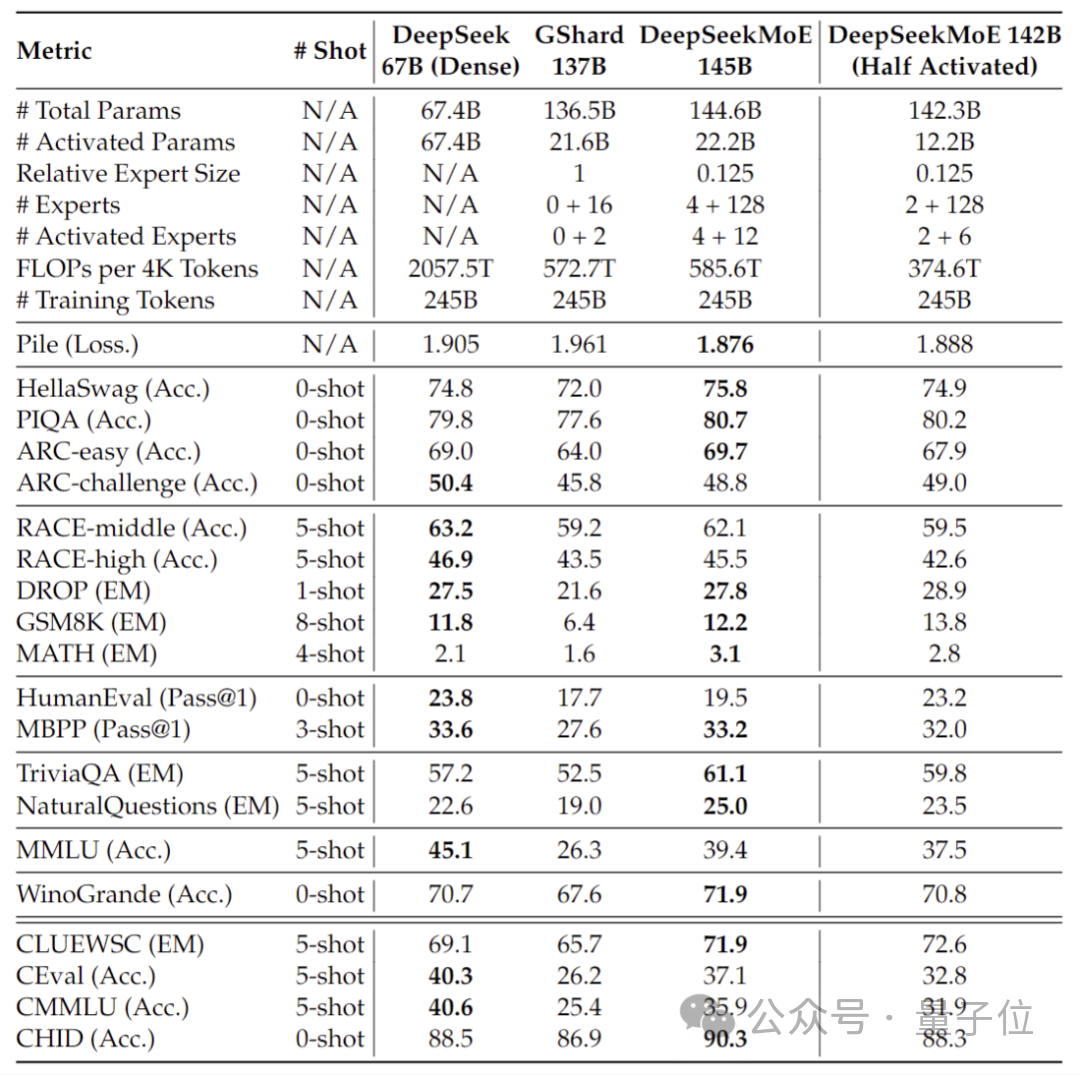
Verglichen mit unserem eigenen 7B-Dichtungsmodell hat die Leistung der beiden bei 19 Datensätzen unterschiedliche Vor- und Nachteile, aber die Gesamtleistung ist relativ ähnlich.
Im Vergleich zu Llama 2-7B, das ebenfalls ein dichtes Modell ist, weist DeepSeek MoE auch offensichtliche Vorteile in Mathematik, Code usw. auf.
Aber die Rechenlast beider dichter Modelle übersteigt 180 TFLOPs pro 4k-Token, während DeepSeek MoE nur 74,4 TFLOPs hat, was nur 40 % der beiden ausmacht.
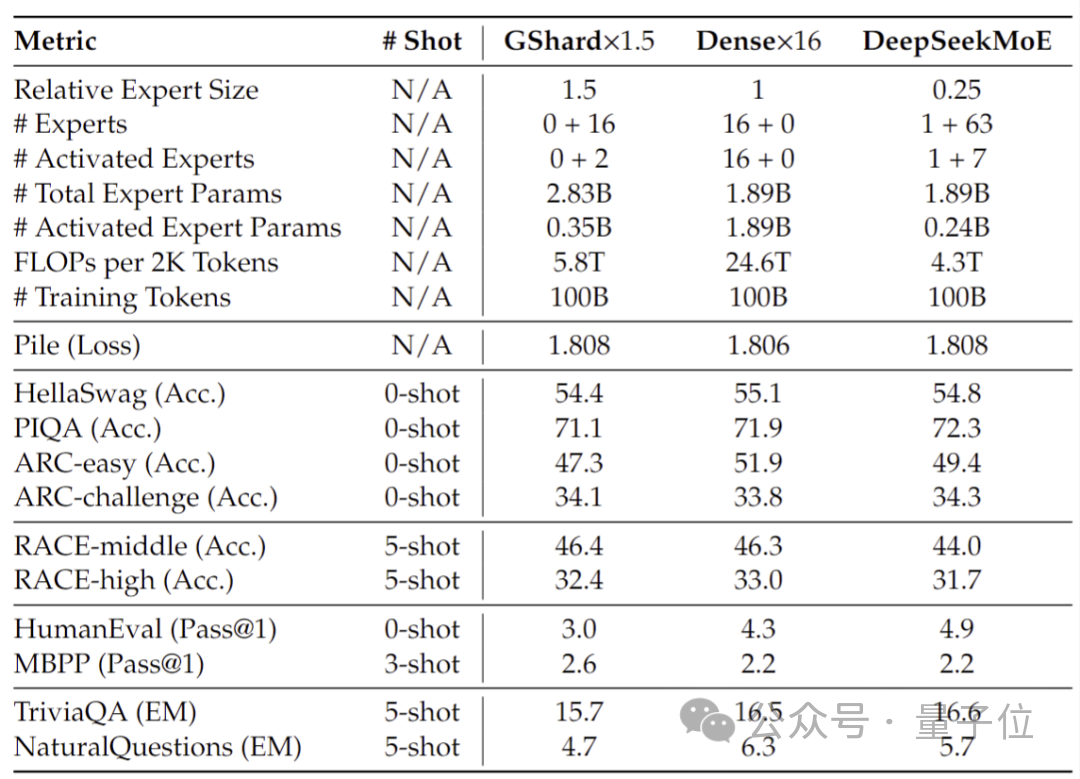
Leistungstests, die mit 2 Milliarden Parametern durchgeführt wurden, zeigen, dass DeepSeek MoE auch gleichwertige oder sogar bessere Ergebnisse erzielen kann als GShard 2.8B, das ebenfalls ein MoE-Modell mit der 1,5-fachen Anzahl von Parametern ist und weniger Berechnungen benötigt.
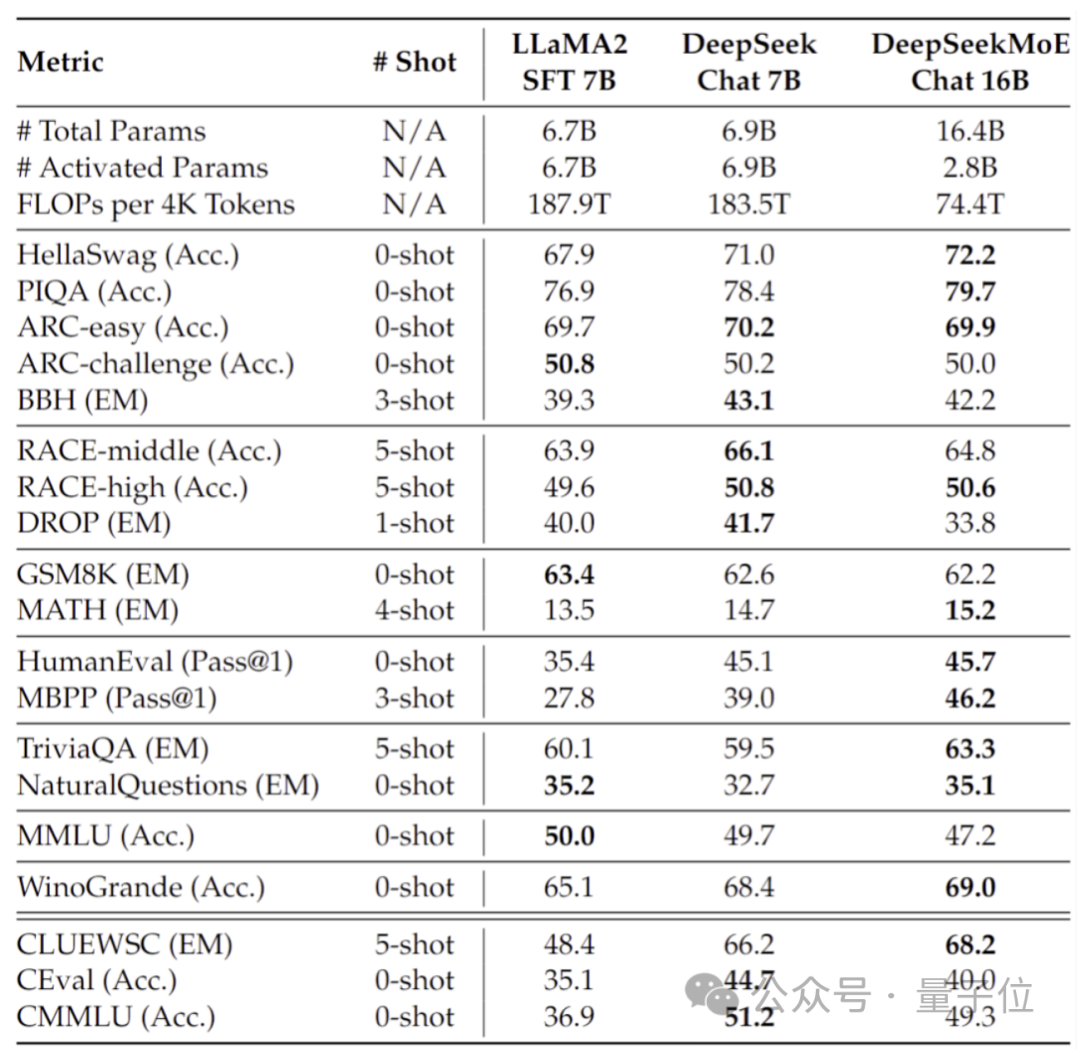
Darüber hinaus hat das Deep Seek-Team auch die Chat-Version von DeepSeek MoE auf Basis von SFT verfeinert, und ihre Leistung kommt auch der eigenen dichten Version und Llama 2-7B nahe.
Darüber hinaus gab das DeepSeek-Team bekannt, dass sich auch eine 145B-Version des DeepSeek-MoE-Modells in der Entwicklung befindet.
Stufenweise vorläufige Tests zeigen, dass das 145B DeepSeek MoE einen großen Vorsprung gegenüber dem GShard 137B hat und mit 28,5 % des Rechenaufwands eine gleichwertige Leistung wie die dichte Version des DeepSeek 67B-Modells erreichen kann.
Nach Abschluss der Forschung und Entwicklung wird das Team auch die 145B-Version als Open Source veröffentlichen.
Hinter der Leistung dieser Modelle steht die neue selbstentwickelte MoE-Architektur von DeepSeek.
Selbst entwickelte neue MoE-Architektur
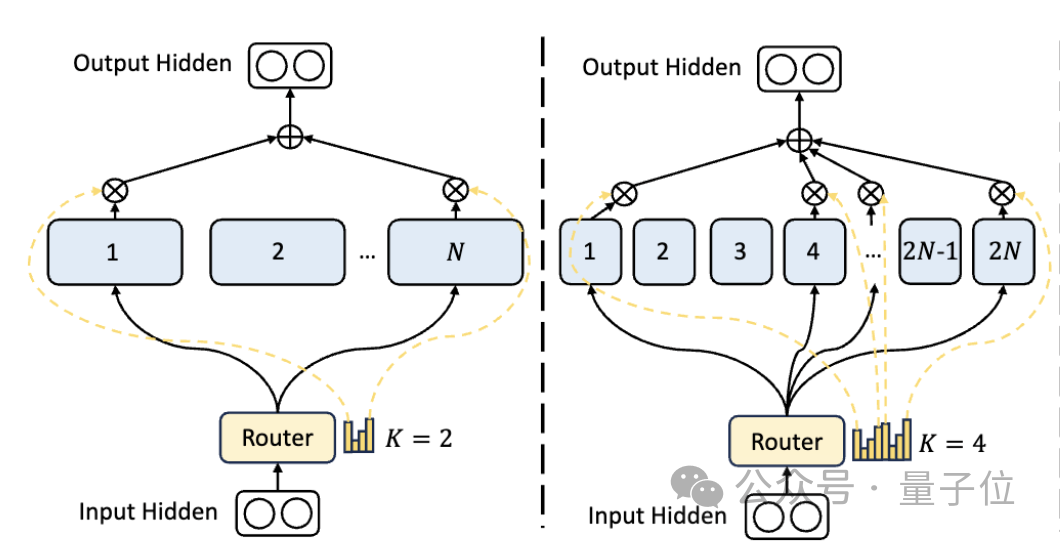
Erstens verfügt DeepSeek im Vergleich zur traditionellen MoE-Architektur über eine feinkörnigere Expertenabteilung.
Wenn die Gesamtzahl der Parameter festgelegt ist, kann das traditionelle Modell N Experten klassifizieren, während DeepSeek 2N Experten klassifizieren kann.
Gleichzeitig ist die Anzahl der Experten, die bei jeder Ausführung einer Aufgabe ausgewählt werden, doppelt so hoch wie beim herkömmlichen Modell, sodass die Gesamtzahl der verwendeten Parameter gleich bleibt, der Grad der Auswahlfreiheit jedoch zunimmt.
Diese Segmentierungsstrategie ermöglicht eine flexiblere und anpassungsfähigere Kombination von Aktivierungsexperten und verbessert dadurch die Genauigkeit des Modells für verschiedene Aufgaben und die Relevanz des Wissenserwerbs.
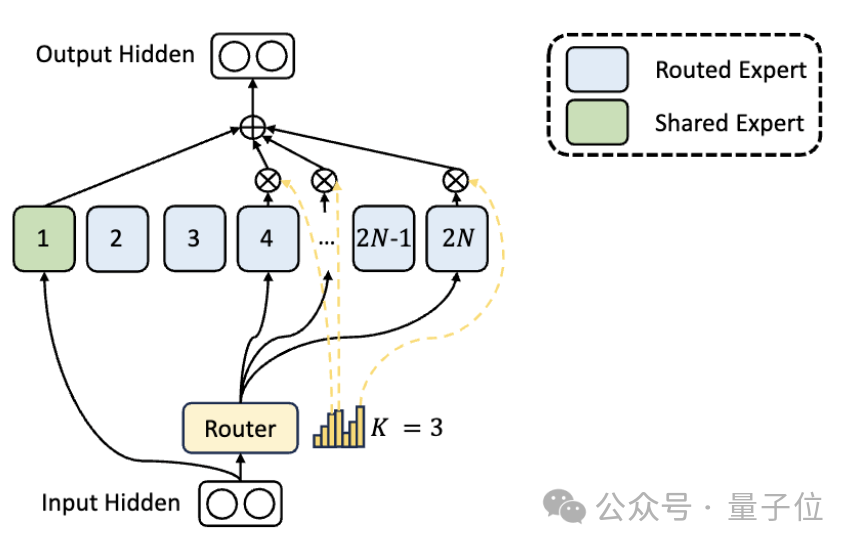
Zusätzlich zu den Unterschieden in der Expertenabteilung führt DeepSeek auch innovativ die Einstellung „gemeinsamer Experte“ ein.
Diese gemeinsamen Experten aktivieren Token für alle Eingaben und sind vom Routing-Modul nicht betroffen. Der Zweck besteht darin, gemeinsames Wissen zu erfassen und zu integrieren, das in verschiedenen Kontexten benötigt wird.
Durch die Komprimierung dieses gemeinsamen Wissens in gemeinsame Experten kann die Parameterredundanz zwischen anderen Experten reduziert und dadurch die Parametereffizienz des Modells verbessert werden.
Die Einstellung gemeinsamer Experten hilft anderen Experten, sich stärker auf ihre individuellen Wissensgebiete zu konzentrieren, wodurch das Gesamtniveau der Expertenspezialisierung erhöht wird.
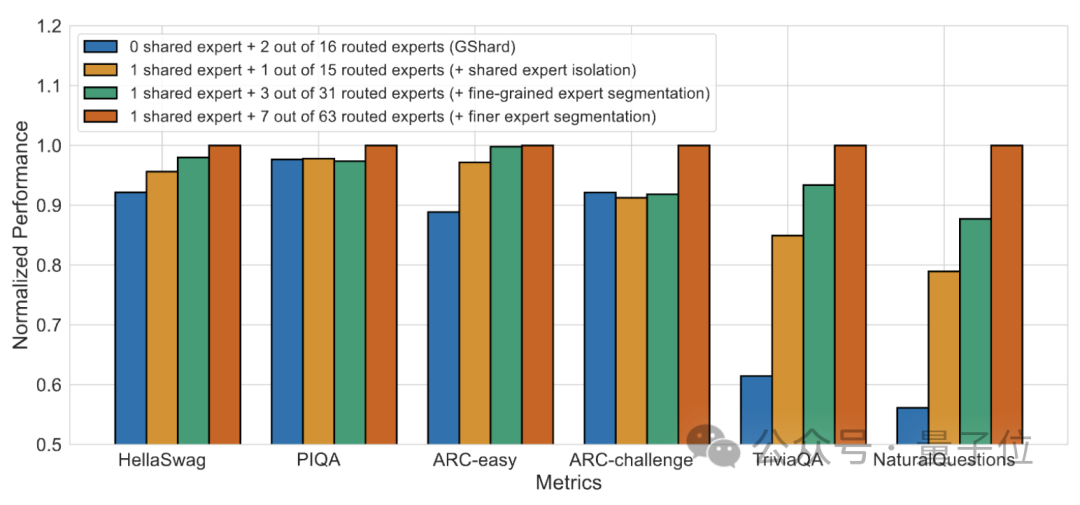
Die Ergebnisse des Ablationsexperiments zeigen, dass beide Lösungen eine wichtige Rolle bei der „Kostensenkung und Effizienzsteigerung“ von DeepSeek MoE spielen.
Papieradresse: https://arxiv.org/abs/2401.06066.
Referenzlink: https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg.
Das obige ist der detaillierte Inhalt vonDurch die Einführung eines großen inländischen Open-Source-MoE-Modells ist seine Leistung mit Llama 2-7B vergleichbar, während der Rechenaufwand um 60 % reduziert wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Biny – ein ultraleichtes Open-Source-PHP-Framework von Tencent
- Was sind die Entwicklungstrends der künstlichen Intelligenz?
- Auf welche Bereiche konzentriert sich Künstliche Intelligenz derzeit?
- Was ist das Grundkonzept der künstlichen Intelligenz?
- Was sind die zehn besten Open-Source-PHP-Blogsysteme im Jahr 2022? 【empfehlen】