
Heim >Technologie-Peripheriegeräte >KI >Lernen Sie multimodale Befehle: Mit der Google-Bildgenerierungs-KI können Sie ganz einfach mitmachen
Lernen Sie multimodale Befehle: Mit der Google-Bildgenerierungs-KI können Sie ganz einfach mitmachen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-15 16:33:051113Durchsuche
Jetzt gibt es ein neues von Google entwickeltes Bildgenerierungsmodell, das die Katze in Abbildung 1 im Stil von Abbildung 2 zeichnen und ihr einen Hut aufsetzen kann. Dieses Modell nutzt die Technologie zur Feinabstimmung von Anweisungen, um neue Bilder basierend auf Textanweisungen und mehreren Referenzbildern präzise zu generieren. Der Effekt ist sehr gut, vergleichbar mit einem PS-Master, der Ihnen persönlich bei der Erstellung eines Bildes hilft.

Bei der Verwendung großer Sprachmodelle (LLM) haben wir erkannt, wie wichtig die Feinabstimmung des Unterrichts ist. Bei entsprechender Feinabstimmung der Anweisungen kann LLM eine Vielzahl von Aufgaben ausführen, wie z. B. das Verfassen von Gedichten, das Schreiben von Code, das Schreiben von Skripten, die Unterstützung bei der wissenschaftlichen Forschung und sogar die Durchführung von Investitionsmanagement.
Ist die Feinabstimmung der Anweisungen jetzt noch effektiv, da große Modelle in das multimodale Zeitalter eingetreten sind? Können wir beispielsweise die Steuerung der Bilderzeugung durch multimodale Anweisungen optimieren? Im Gegensatz zur Sprachgenerierung geht es bei der Bildgenerierung von Anfang an um Multimodalität. Können wir Modelle effektiv in die Lage versetzen, die Komplexität der Multimodalität zu erfassen?
Um dieses Problem zu lösen, haben Google DeepMind und Google Research eine multimodale Anweisungsmethode zur Bildgenerierung vorgeschlagen. Diese Methode verknüpft Informationen aus verschiedenen Modalitäten, um die Bedingungen für die Bilderzeugung auszudrücken (Beispiel im linken Bereich von Abbildung 1).
Multimodale Anweisungen können Sprachanweisungen verbessern. Benutzer können beispielsweise den Stil des Referenzbilds angeben, um ein Modell zum Rendern des Bildes zu generieren. Diese intuitive interaktive Schnittstelle ermöglicht die effiziente Einstellung multimodaler Bedingungen für Bilderzeugungsaufgaben.
Basierend auf dieser Idee erstellte das Team ein multimodales Modell zur Generierung von Instruktionsbildern: Instruct-Imagen.

Papieradresse: https://arxiv.org/abs/2401.01952

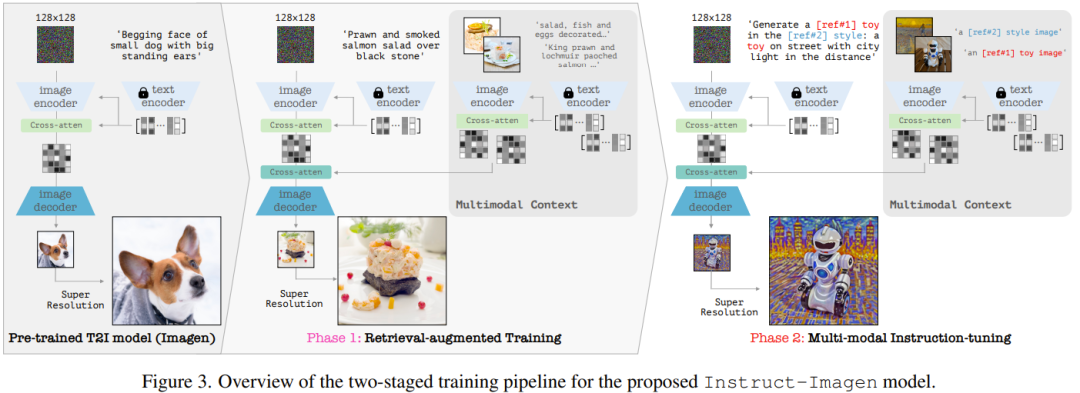
Das Modell verwendet eine zweistufige Trainingsmethode: Verbessern Sie zunächst die Fähigkeit des Modells, mit multimodalen Anweisungen umzugehen, und folgen Sie dann treu Multimodale Benutzerabsicht.
In der ersten Phase übernahm das Team ein vorab trainiertes Text-zu-Bild-Modell mit der Aufgabe, zusätzliche multimodale Eingaben zu verarbeiten und es später so zu verfeinern, dass es genau auf multimodale Anweisungen reagieren konnte. Konkret handelte es sich bei dem vorab trainierten Modell um ein Diffusionsmodell, das um einen ähnlichen (Bild-, Text-)Kontext aus einem Netzwerkkorpus (Bild, Text) erweitert wurde.
In der zweiten Phase verfeinerte das Team das Modell auf eine Vielzahl von Bilderzeugungsaufgaben, die jeweils mit entsprechenden multimodalen Anweisungen gepaart wurden – diese Anweisungen enthielten die Schlüsselelemente der jeweiligen Aufgaben. Nach den oben genannten Schritten kann das resultierende Modell Instruct-Imagen die Fusionseingabe mehrerer Modalitäten (z. B. Skizzen plus visuelle Stile, die mit Textanweisungen beschrieben werden) sehr geschickt verarbeiten, sodass Bilder generiert werden können, die genau zum Kontext passen und hell genug sind.
Wie in Abbildung 1 gezeigt, leistet Instruct-Imagen eine hervorragende Leistung, da es in der Lage ist, komplexe multimodale Anweisungen zu verstehen und Bilder zu erzeugen, die den menschlichen Absichten getreu folgen und sogar Kombinationen von Anweisungen verarbeiten, die noch nie zuvor gesehen wurden.

Menschliches Feedback zeigt, dass Instruct-Imagen in vielen Fällen nicht nur die Leistung aufgabenspezifischer Modelle bei entsprechenden Aufgaben erreicht, sondern diese sogar übertrifft. Darüber hinaus verfügt Instruct-Imagen über starke Generalisierungsfähigkeiten und kann für unbekannte und komplexere Bilderzeugungsaufgaben verwendet werden.
Multimodale Anweisungen zur Generierung
Das vom Team verwendete vorab trainierte Modell ist ein Diffusionsmodell und der Benutzer kann Eingabebedingungen dafür festlegen. Einzelheiten finden Sie im Originalpapier.
Um Vielseitigkeit und Verallgemeinerungsfähigkeit sicherzustellen, schlug das Team für multimodale Anweisungen ein einheitliches multimodales Anweisungenformat vor, in dem die Rolle der Sprache darin besteht, das Ziel der Aufgabe und die multimodalen Bedingungen klar darzulegen dienen als Referenzinformationen.
Dieses neu vorgeschlagene Befehlsformat enthält zwei Schlüsselkomponenten: (1) Nutzlasttextbefehl, dessen Rolle darin besteht, das Aufgabenziel im Detail zu beschreiben und eine Referenzinformationsidentifizierung anzugeben, z. B. [ref#?]. (2) Multimodaler Kontext mit gepaartem (Logo + Text, Bild). Das Modell verwendet dann ein gemeinsames Anweisungsverständnismodell, um Textanweisungen und multimodale Kontexte zu verarbeiten – die spezifische Modalität des Kontexts ist hier nicht eingeschränkt.
Abbildung 2 zeigt anhand von drei Beispielen, wie dieses Format verschiedene Aufgaben der vorherigen Generation darstellen kann. Dies zeigt, dass dieses Format mit Aufgaben der vorherigen Bildgenerierung kompatibel sein kann. Noch wichtiger ist, dass die Sprache flexibel ist, sodass multimodale Anweisungen für neue Aufgaben erweitert werden können, ohne dass ein spezielles Design für Modalität und Aufgaben erforderlich ist.

Instruct-Imagen
Instruct-Imagen basiert auf multimodalen Anweisungen. Auf dieser Grundlage entwarf das Team eine Modellarchitektur, die auf einem vorab trainierten Text-zu-Bild-Diffusionsmodell, nämlich dem kaskadierten Diffusionsmodell, basiert, sodass es die eingegebenen multimodalen Befehlsbedingungen vollständig übernehmen kann.
Konkret verwendeten sie eine Variante von Imagen, siehe den Artikel „Fotorealistische Text-zu-Bild-Diffusionsmodelle mit tiefem Sprachverständnis“, und führten ein Vortraining basierend auf ihren internen Datenquellen durch. Sein vollständiges Modell enthält zwei Unterkomponenten: (1) Text-zu-Bild-Komponente, deren Aufgabe darin besteht, Bilder mit einer Auflösung von 128 x 128 nur unter Verwendung von Texteingabeaufforderungen zu generieren; (2) ein textbedingtes Superauflösungsmodell, das eine Auflösung von 128 konvertieren kann; Bilder in ein Upgrade auf eine Auflösung von 1024 umwandeln.
Zur Codierung multimodaler Anweisungen siehe Abbildung 3 (rechts), die den Datenfluss der Instruct-Imagen-Codierung multimodaler Anweisungen zeigt.
Training von Instruct-Imagen mit einer zweistufigen Methode
Der Trainingsprozess von Instruct-Imagen ist in zwei Phasen unterteilt.
Die erste Stufe ist das durch den Abruf verbesserte Text-zu-Bild-Training, das die erweiterten abgerufenen Nachbarpaare (Bild, Text) verwendet, um das Training der Text-zu-Bild-Generierung fortzusetzen.
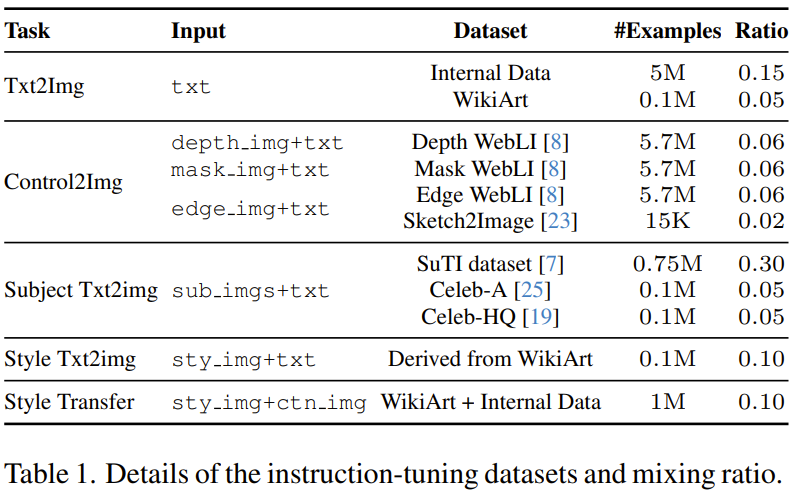
Die zweite Stufe besteht darin, das Ausgabemodell der ersten Stufe zu verfeinern, das eine Mischung verschiedener Bilderzeugungsaufgaben verwendet, von denen jede mit entsprechenden multimodalen Anweisungen gepaart ist. Konkret verwendete das Team 11 Bilder aus 5 Aufgabenkategorien, um den Datensatz zu generieren, siehe Tabelle 1.
In beiden Trainingsstufen wird das Modell durchgängig optimiert.
Experimente
Das Team führte experimentelle Bewertungen der neu vorgeschlagenen Methoden und Modelle durch und führte eine eingehende Analyse des Designs und der Fehlermodi von Instruct-Imagen durch.
Experimentelle Einstellungen
Das Team evaluierte das Modell in zwei Einstellungen, nämlich der domäneninternen Aufgabenbewertung und der Zero-Shot-Aufgabenbewertung, wobei die letztere Einstellung anspruchsvoller ist als die erstere.
Hauptergebnisse
Abbildung 4 vergleicht Instruct-Imagen mit der Basismethode und früheren Methoden. Die Ergebnisse zeigen, dass es mit früheren Methoden bei der Domänenbewertung und der Nullstichprobenbewertung vergleichbar ist.
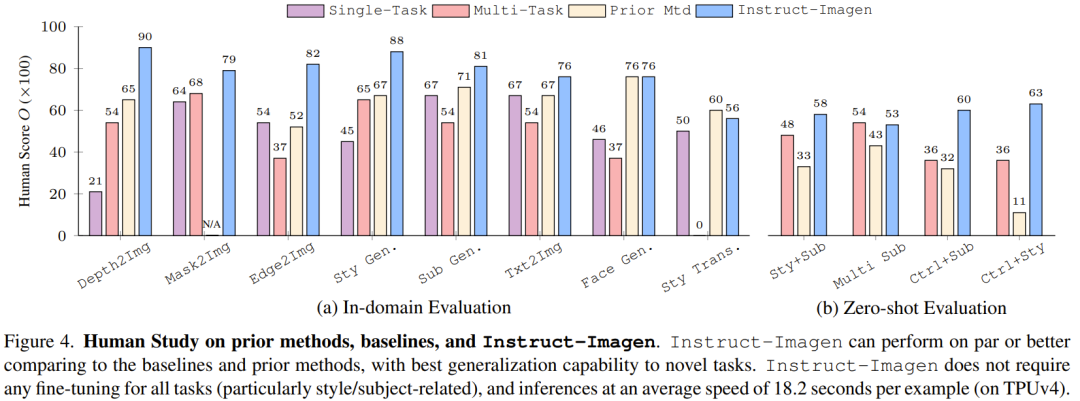
Dies zeigt, dass das Training mit multimodalen Anweisungen die Modellleistung bei Aufgaben mit begrenzten Trainingsdaten (z. B. Stilisierungsgenerierung) verbessern und gleichzeitig die Leistung bei datenreichen Aufgaben (z. B. der Generierung fotoähnlicher Bilder) aufrechterhalten kann. Ohne multimodales Schulungstraining führen Multitasking-Benchmarks tendenziell zu einer schlechten Bildqualität und Textausrichtung.
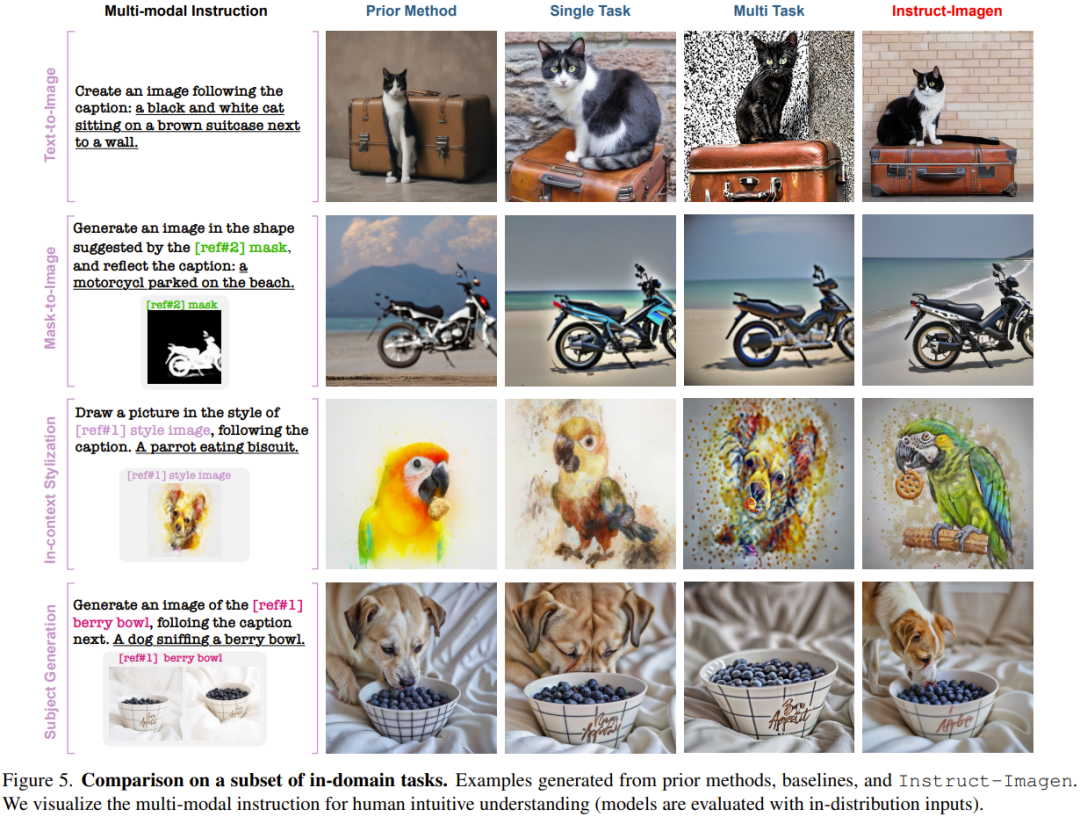
Im kontextbezogenen Stilisierungsbeispiel in Abbildung 5 hat der Multitask-Benchmark beispielsweise Schwierigkeiten, Stile von Objekten zu unterscheiden, sodass die Objekte in den generierten Ergebnissen reproduziert werden. Aus ähnlichen Gründen schneidet es auch bei Stilübertragungsaufgaben schlecht ab. Diese Beobachtungen unterstreichen den Wert der Feinabstimmung des Unterrichts.
Im Gegensatz zu aktuellen Methoden oder Schulungen, die auf bestimmten Aufgaben basieren, kann Instruct-Imagen kombinierte Aufgaben effizient verwalten (z. B. ohne Feinabstimmung), indem es Anweisungen nutzt, die die Ziele verschiedener Aufgaben kombinieren und Überlegungen im Kontext anstellen. 18,2 dauert Sekunden).
Wie in Abbildung 6 dargestellt, übertrifft Instruct-Imagen immer andere Modelle in Bezug auf die Befehlsfolge und die Ausgabequalität.

Darüber hinaus kann das Multitask-Basismodell bei mehreren Referenzen in einem multimodalen Kontext keine Textanweisungen mit Referenzen korrespondieren, was dazu führt, dass einige multimodale Bedingungen ignoriert werden. Diese Ergebnisse belegen erneut die Wirksamkeit des neu vorgeschlagenen Modells.
Modellanalyse und Ablationsstudie
Das Team analysierte die Einschränkungen und Fehlermodi des Modells.
Zum Beispiel hat das Team herausgefunden, dass fein abgestimmte Instruct-Imagen Bilder bearbeiten können. Wie in Tabelle 2 gezeigt, kann durch Vergleich des vorherigen SDXL-Inpaintings, des fein abgestimmten Imagen im MagicBrush-Datensatz und des fein abgestimmten Instruct-Imagen festgestellt werden, dass das fein abgestimmte Instruct-Imagen deutlich besser ist als das ein speziell für die maskenbasierte Bildbearbeitung entwickeltes Modell.
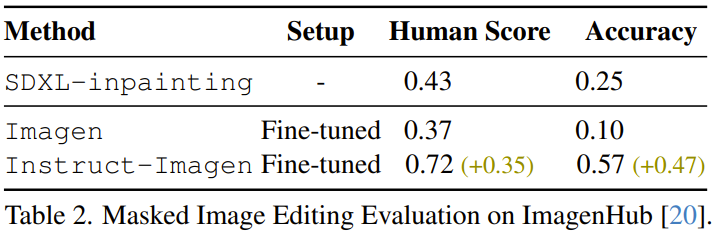
Allerdings erzeugt das fein abgestimmte Instruct-Imagen Artefakte in den bearbeiteten Bildern, insbesondere in der hochauflösenden Ausgabe nach dem Superauflösungsschritt, wie in Abbildung 7 dargestellt. Die Forscher sagen, das liegt daran, dass das Modell bisher nicht gelernt hat, Pixel direkt aus dem Kontext genau zu kopieren.

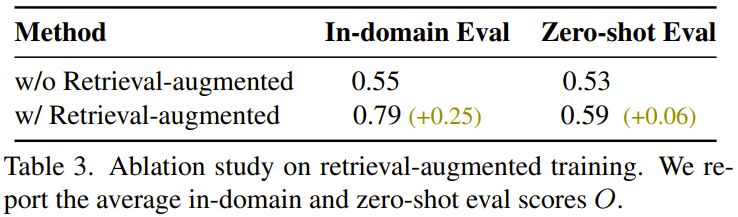
Das Team stellte außerdem fest, dass das Training mit Abrufunterstützung zur Verbesserung der Generalisierungsfähigkeit beitrug. Die Ergebnisse sind in Tabelle 3 aufgeführt.
In Bezug auf den Fehlermodus von Instruct-Imagen stellten die Forscher fest, dass Instruct-Imagen Schwierigkeiten hat, Ergebnisse zu generieren, die den Anweisungen entsprechen, wenn die multimodalen Anweisungen komplexer sind (mindestens 3 multimodale Bedingungen). Abbildung 8 zeigt zwei Beispiele.

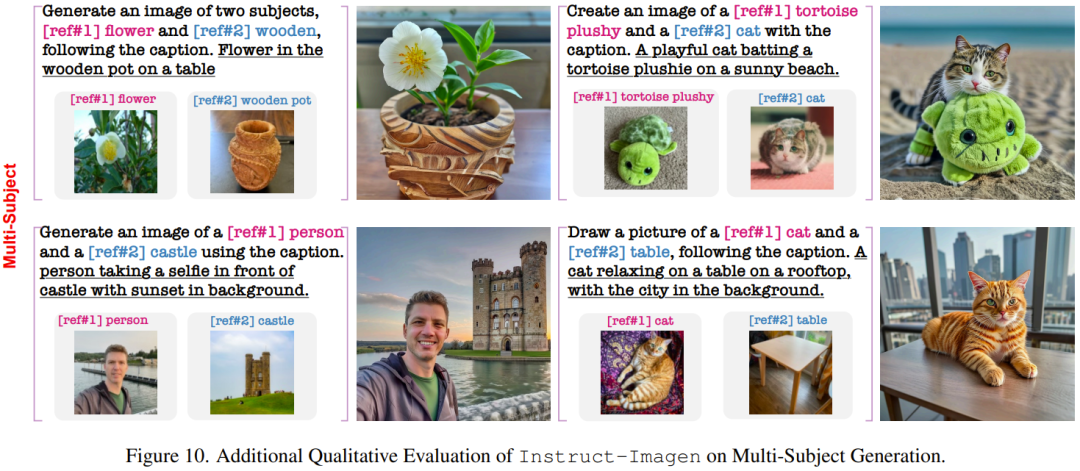
Das Folgende zeigt einige Ergebnisse zu komplexen Aufgaben, die während des Trainings nicht gesehen wurden.


Das Team führte auch Ablationsstudien durch, um die Bedeutung seiner Designkomponenten zu beweisen.
Aus Sicherheitsgründen hat Google den Code und die API dieser Forschung jedoch noch nicht veröffentlicht.
Weitere Einzelheiten finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonLernen Sie multimodale Befehle: Mit der Google-Bildgenerierungs-KI können Sie ganz einfach mitmachen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die Industriekette der künstlichen Intelligenz umfasst
- Neue Regeln für Oktober sind da! Einbeziehung neuer Verkehrszeichen, Industrie der künstlichen Intelligenz usw.
- Tesla plant die Errichtung einer Elektrofahrzeugfabrik in Indien, um die indische Elektrofahrzeugindustrie anzukurbeln
- Baidu bringt Chinas erstes medizinisches Modell auf „industrieller Ebene' auf den Markt „Modell der spirituellen Medizin': Baidu bringt Chinas erstes medizinisches Modell auf „industrieller Ebene' auf den Markt, das „Modell der spirituellen Medizin'
- Lassen Sie uns gemeinsam das digitale Guangxi aufbauen und gemeinsam in eine digitale Zukunft gehen! Die ökologische Konferenz der Industrie für künstliche Intelligenz in Guangxi Kunpeng Shengteng 2023 wurde erfolgreich abgehalten