
Heim >System-Tutorial >LINUX >Optimieren Sie die Effizienz des HDFS-Datenzugriffs: Nutzen Sie Datenwärme und -kälte zur Verwaltung
Optimieren Sie die Effizienz des HDFS-Datenzugriffs: Nutzen Sie Datenwärme und -kälte zur Verwaltung

- 王林nach vorne
- 2024-01-15 09:18:151441Durchsuche
Themeneinführung:
- HDFS-optimierte Speicherfunktionserklärung
- SSM-Systemarchitekturdesign
- SSM-Systemanwendungsszenarioanalyse
Mit der Entwicklung und Popularisierung von Big-Data-Technologien beginnen immer mehr Unternehmen, Plattformsysteme auf Basis von Open-Source-Hadoop zu nutzen. Gleichzeitig migrieren immer mehr Unternehmen und Anwendungen von der traditionellen technischen Architektur zu Big Data Plattformen überlegen. In einer typischen Hadoop-Big-Data-Plattform wird HDFS als Kern der Speicherdienste verwendet.
Zu Beginn der Entwicklung von Big Data war das Hauptanwendungsszenario noch das Offline-Stapelverarbeitungsszenario, und die Nachfrage nach Speicher war auf das Streben nach Durchsatz ausgelegt, und mit der kontinuierlichen Weiterentwicklung der Technologie wurden mehr und mehr Immer mehr Szenarien werden neue Anforderungen an den Speicher stellen, und auch HDFS steht vor neuen Herausforderungen. Es umfasst vor allem mehrere Aspekte:
1. DatenvolumenproblemEinerseits werden mit dem Wachstum des Geschäfts und dem Zugriff auf neue Anwendungen mehr Daten in HDFS übertragen. Andererseits hoffen Benutzer mit der Entwicklung von Deep Learning, künstlicher Intelligenz und anderen Technologien normalerweise, Daten zu sparen über einen längeren Zeitraum, um die Wirkung von Deep Learning zu verbessern. Der schnelle Anstieg der Datenmenge wird dazu führen, dass der Cluster ständig erweitert werden muss, was zu steigenden Speicherkosten führt.
2. Kleines DateiproblemWie wir alle wissen, ist HDFS für die Offline-Stapelverarbeitung großer Dateien konzipiert. Die Verarbeitung kleiner Dateien ist kein Szenario, in dem herkömmliches HDFS gut ist. Die Hauptursache für das Problem kleiner HDFS-Dateien besteht darin, dass die Metadateninformationen der Datei im Speicher eines einzelnen Namenodes gespeichert werden und der Speicherplatz eines einzelnen Computers immer begrenzt ist. Es wird geschätzt, dass die maximale Anzahl von Systemdateien, die ein einzelner Namenode-Cluster aufnehmen kann, etwa 150 Millionen beträgt. Tatsächlich dient die HDFS-Plattform normalerweise als zugrunde liegende Speicherplattform, um mehrere Computing-Frameworks der oberen Schicht und mehrere Geschäftsszenarien zu bedienen, sodass das Problem kleiner Dateien aus geschäftlicher Sicht unvermeidbar ist. Derzeit gibt es Lösungen wie HDFS-Federation, um das Problem der Namenode-Einzelpunkt-Skalierbarkeit zu lösen, aber gleichzeitig wird es auch große Schwierigkeiten beim Betriebs- und Wartungsmanagement mit sich bringen.
3. Problem mit heißen und kalten DatenDa die Datenmenge weiter wächst und sich ansammelt, werden die Daten auch große Unterschiede in der Zugriffspopularität aufweisen. Beispielsweise schreibt eine Plattform kontinuierlich die neuesten Daten, aber normalerweise wird auf die kürzlich geschriebenen Daten viel häufiger zugegriffen als auf die vor langer Zeit geschriebenen Daten. Wenn dieselbe Speicherstrategie verwendet wird, unabhängig davon, ob die Daten heiß oder kalt sind, ist dies eine Verschwendung von Clusterressourcen. Wie das HDFS-Speichersystem basierend auf der Hotness und Coldness der Daten optimiert werden kann, ist ein dringendes Problem, das gelöst werden muss.
2. Vorhandene HDFS-OptimierungstechnologieSeit der Geburt von Hadoop sind mehr als 10 Jahre vergangen. In dieser Zeit wurde die HDFS-Technologie selbst kontinuierlich optimiert und weiterentwickelt. HDFS verfügt über einige vorhandene Technologien, die einige der oben genannten Probleme bis zu einem gewissen Grad lösen können. Hier finden Sie eine kurze Einführung in die heterogene HDFS-Speicher- und HDFS-Erasure-Coding-Technologie.
Heterogener HDFS-Speicher:Hadoop unterstützt heterogene Speicherfunktionen ab Version 2.6.0. Wir wissen, dass die Standardspeicherstrategie von HDFS drei Kopien jedes Datenblocks verwendet und diese auf Festplatten auf verschiedenen Knoten speichert. Die Rolle des heterogenen Speichers besteht darin, verschiedene Arten von Speichermedien auf dem Server zu verwenden (einschließlich HDD-Festplatte, SSD, Speicher usw.), um mehr Speicherstrategien bereitzustellen (z. B. drei Kopien, eine wird auf dem SSD-Medium gespeichert usw.). Die restlichen beiden werden weiterhin auf der HDD-Festplatte gespeichert, wodurch der HDFS-Speicher flexibler und effizienter bei der Reaktion auf verschiedene Anwendungsszenarien wird.
Zu den verschiedenen vordefinierten unterstützten Speichern in HDFS gehören:
-
ARCHIV: Speichermedien mit hoher Speicherdichte, aber geringem Stromverbrauch, wie z. B. Bänder, werden in der Regel zur Speicherung kalter Daten verwendet
-
DISK: Festplattenmedium, dies ist das früheste von HDFS unterstützte Speichermedium
-
SSD: Solid State Drive ist eine neue Art von Speichermedium, das derzeit von vielen Internetunternehmen verwendet wird
-
RAM_DISK: Die Daten werden in den Speicher geschrieben und gleichzeitig wird eine weitere Kopie (asynchron) auf das Speichermedium geschrieben
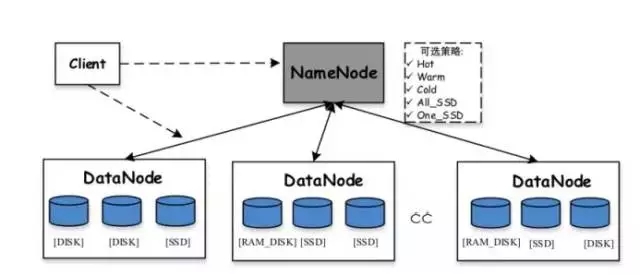
Zu den in HDFS unterstützten Speicherstrategien gehören:
-
Lazy_persist: Eine Kopie bleibt im Speicher RAM_DISK und die restlichen Kopien werden auf der Festplatte gespeichert
-
ALL_SSD: Alle Kopien werden auf SSD gespeichert
-
One_SSD: Eine Kopie wird auf der SSD gespeichert und die restlichen Kopien werden auf der Festplatte gespeichert
-
Hot: Alle Kopien werden auf der Festplatte gespeichert, was auch die Standardspeicherrichtlinie ist
-
Warm: Eine Kopie wird auf der Festplatte gespeichert, die restlichen Kopien werden im Archivspeicher gespeichert
-
Kalt: Alle Kopien werden im Archivspeicher aufbewahrt
Im Allgemeinen liegt der Wert des heterogenen HDFS-Speichers darin, je nach Beliebtheit der Daten unterschiedliche Strategien anzuwenden, um die Gesamteffizienz der Ressourcennutzung des Clusters zu verbessern. Speichern Sie Daten, auf die häufig zugegriffen wird, ganz oder teilweise auf Speichermedien (Speicher oder SSD) mit höherer Zugriffsleistung, um die Lese- und Schreibleistung zu verbessern. Speichern Sie Daten, auf die selten zugegriffen wird, auf Archivspeichermedien, um die Lese- und Schreibgeschwindigkeit zu verringern Leistung. Lagerkosten. Die Konfiguration des heterogenen HDFS-Speichers erfordert jedoch, dass Benutzer entsprechende Richtlinien für Verzeichnisse angeben, d. h. Benutzer müssen die Zugriffspopularität von Dateien in jedem Verzeichnis im Voraus kennen. Bei tatsächlichen Big-Data-Plattformanwendungen ist dies schwieriger.
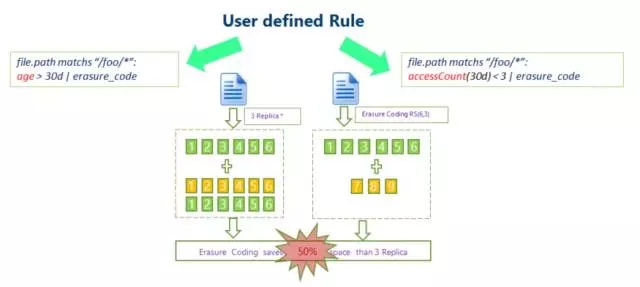
HDFS-Löschcode:Herkömmliche HDFS-Daten verwenden einen Drei-Kopien-Mechanismus, um die Datenzuverlässigkeit sicherzustellen. Das heißt, für jedes 1 TB gespeicherte Daten erreicht die tatsächliche Datenbelegung auf jedem Knoten des Clusters 3 TB, mit einem zusätzlichen Overhead von 200 %. Dies setzt den Festplattenspeicher des Knotens und die Netzwerkübertragung stark unter Druck.
Hadoop 3.0 begann mit der Einführung der Unterstützung für die Löschcodierung auf HDFS-Dateiblockebene, und die zugrunde liegende Schicht verwendet den Reed-Solomon (k, m)-Algorithmus. RS ist ein häufig verwendeter Löschcodierungsalgorithmus. Abhängig von den Werten von k und m können m-Bit-Prüfziffern generiert werden relativ flexible Methode.
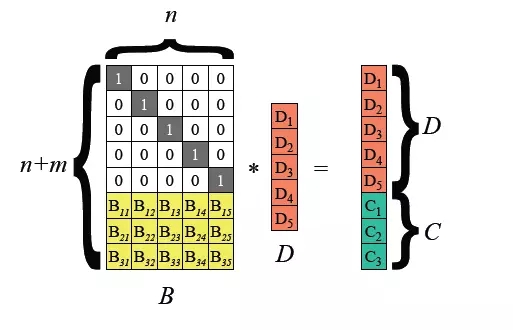
Übliche Algorithmen sind RS(3,2), RS(6,3), RS(10,4), k Dateiblöcke und m Prüfblöcke bilden eine Gruppe, und alle m Datenblöcke können in dieser Verlustgruppe toleriert werden.
Die HDFS-Erasure-Coding-Technologie kann die Redundanz der Datenspeicherung reduzieren. Am Beispiel von RS(3,2) beträgt die Datenredundanz 67 %, was im Vergleich zu Hadoops Standardwert von 200 % deutlich geringer ist. Die Erasure-Coding-Technologie erfordert jedoch den Verbrauch von CPU für die Datenspeicherung und Datenwiederherstellung. Dabei handelt es sich tatsächlich um den Austausch von Zeit gegen Speicherplatz. Daher ist die Speicherung kalter Daten das passendere Szenario. Auf die in Cold Data gespeicherten Daten kann nach dem einmaligen Schreiben oft lange Zeit nicht zugegriffen werden. In diesem Fall kann die Erasure-Coding-Technologie verwendet werden, um die Anzahl der Kopien zu reduzieren. 3. Big-Data-Speicheroptimierung: SSM
Ob heterogener HDFS-Speicher oder zuvor eingeführte Erasure-Coding-Technologie, die Voraussetzung ist, dass Benutzer das Speicherverhalten für bestimmte Daten angeben müssen, was bedeutet, dass Benutzer wissen müssen, welche Daten heiße Daten und welche kalte Daten sind. Gibt es also eine Möglichkeit, den Speicher automatisch zu optimieren?Die Antwort lautet „Ja“. Das hier vorgestellte SSM-System (Smart Storage Management) ruft Metadateninformationen vom zugrunde liegenden Speicher (normalerweise HDFS) ab und ermittelt den Datenwärmestatus durch Analyse der Datenlese- und Schreibzugriffsinformationen, wobei es auf Daten mit unterschiedlichen Wärmeniveaus abzielt. Ergreifen Sie gemäß einer Reihe vorab festgelegter Regeln entsprechende Speicheroptimierungsstrategien, um die Effizienz des gesamten Speichersystems zu verbessern. SSM ist ein von Intel geleitetes Open-Source-Projekt, an dessen Forschung und Entwicklung auch China Mobile beteiligt ist. Das Projekt ist auf Github erhältlich: https://github.com/Intel-bigdata/SSM.
SSM-Positionierung ist ein Speicherperipherie-Optimierungssystem, das eine Server-Agent-Client-Architektur als Ganzes übernimmt. Der Server ist für die Implementierung der Gesamtlogik von SSM verantwortlich, der Agent wird verwendet, um verschiedene Vorgänge im Speichercluster auszuführen Der Client ist die den Benutzern bereitgestellte Datenzugriffsschnittstelle, normalerweise einschließlich der nativen HDFS-Schnittstelle.
Das Hauptframework von SSM-Server ist in der obigen Abbildung dargestellt. Von oben nach unten interagiert StatesManager mit dem HDFS-Cluster, um HDFS-Metadateninformationen zu erhalten und die Zugriffswärmeinformationen jeder Datei zu verwalten. Die Informationen im StatesManager werden in der relationalen Datenbank gespeichert. TiDB wird als zugrunde liegende Speicherdatenbank in SSM verwendet. RuleManager verwaltet und verwaltet regelbezogene Informationen. Benutzer definieren eine Reihe von Speicherregeln für SSM über die Front-End-Schnittstelle, und RuleManager ist für die Analyse und Ausführung der Regeln verantwortlich. CacheManager/StorageManager generiert spezifische Aktionsaufgaben basierend auf Beliebtheit und Regeln. ActionExecutor ist für bestimmte Aktionsaufgaben verantwortlich, weist Agenten Aufgaben zu und führt sie auf Agentenknoten aus. 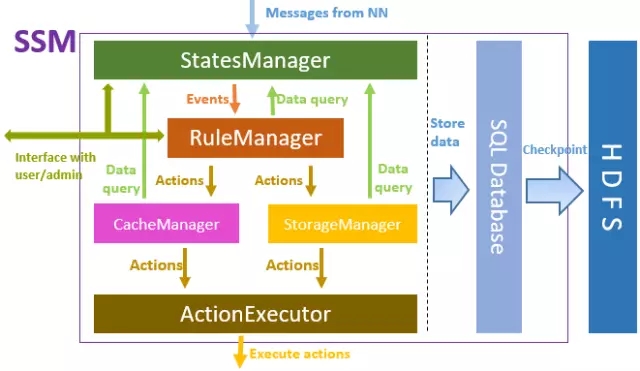
Die interne Logikimplementierung des SSM-Servers basiert auf der Definition von Regeln. Dies erfordert, dass der Administrator über die Front-End-Webseite eine Reihe von Regeln für das SSM-System formuliert. Eine Regel besteht aus mehreren Teilen: 
- Operationsobjekte beziehen sich normalerweise auf Dateien, die bestimmte Bedingungen erfüllen.
- Trigger bezieht sich auf den Zeitpunkt, zu dem die Regel ausgelöst wird, z. B. jeden Tag ein geplanter Trigger.
- Ausführungsbedingungen: Definieren Sie eine Reihe von Bedingungen basierend auf der Beliebtheit, z. B. Anforderungen an die Anzahl der Dateizugriffe innerhalb eines bestimmten Zeitraums.
- Führen Sie Vorgänge aus, führen Sie verwandte Vorgänge für Daten aus, die die Ausführungsbedingungen erfüllen, und geben Sie normalerweise deren Speicherstrategie usw. an.
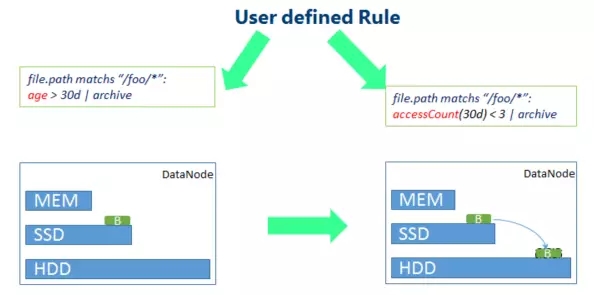
Ein tatsächliches Regelbeispiel:
file.path entspricht „/foo/*“: accessCount(10min) >= 3 |
Diese Regel bedeutet, dass für Dateien im Verzeichnis /foo die Ein-SSD-Speicherstrategie übernommen wird, wenn auf sie mindestens dreimal innerhalb von 10 Minuten zugegriffen wird, d. h. eine Kopie der Daten wird auf der SSD gespeichert , und die restlichen 2 Kopien werden auf der regulären Festplatte gespeichert.4. SSM-Anwendungsszenarien SSM kann verschiedene Speicherstrategien verwenden, um die Hotness und Coldness von Daten zu optimieren. Im Folgenden sind einige typische Anwendungsszenarien aufgeführt:
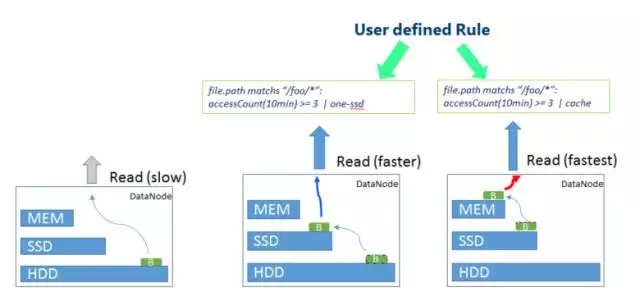

Erwähnenswert ist auch, dass SSM auch über entsprechende Optimierungsmethoden für kleine Dateien verfügt. Diese Funktion befindet sich noch im Entwicklungsprozess. Die allgemeine Logik besteht darin, dass SSM eine Reihe kleiner Dateien in HDFS zu großen Dateien zusammenführt. Gleichzeitig wird die Zuordnungsbeziehung zwischen den ursprünglichen kleinen Dateien und den zusammengeführten großen Dateien sowie der Speicherort jeder kleinen Datei in der großen Datei geändert in den Metadaten des SSM-Offsets aufgezeichnet. Wenn der Benutzer auf eine kleine Datei zugreifen muss, wird die ursprüngliche kleine Datei aus der zusammengeführten Datei über den SSM-spezifischen Client (SmartClient) basierend auf den Zuordnungsinformationen für kleine Dateien in den SSM-Metadaten abgerufen.
Schließlich ist SSM ein Open-Source-Projekt und befindet sich immer noch in einem sehr schnellen iterativen Entwicklungsprozess. Alle interessierten Freunde sind herzlich willkommen, zur Entwicklung des Projekts beizutragen.
Fragen und Antworten
F1: Mit welchem Maßstab sollten wir beginnen, wenn wir HDFS selbst erstellen?
A1: HDFS unterstützt den Pseudoverteilungsmodus. Auch wenn nur ein Knoten vorhanden ist, können Sie ein HDFS-System erstellen. Wenn Sie die verteilte Architektur von HDFS besser erleben und verstehen möchten, wird empfohlen, eine Umgebung mit 3 bis 5 Knoten aufzubauen.
F2: Hat Su Yan SSM in der tatsächlichen Big-Data-Plattform jeder Provinz verwendet?
A2: Noch nicht. Dieses Projekt entwickelt sich noch rasant. Es wird nach und nach in der Produktion eingesetzt, sobald die Tests stabil sind.
F3: Was ist der Unterschied zwischen HDFS und Spark? Was sind die Vor- und Nachteile?
A3: HDFS und Spark sind keine Technologien auf derselben Ebene. HDFS ist ein Speichersystem, während Spark eine Computer-Engine ist. Was wir oft mit Spark vergleichen, ist das Mapreduce-Computing-Framework in Hadoop und nicht das HDFS-Speichersystem. Bei der tatsächlichen Projekterstellung arbeiten HDFS und Spark normalerweise zusammen. HDFS wird für die zugrunde liegende Speicherung und Spark für die Datenverarbeitung auf höherer Ebene verwendet.
Das obige ist der detaillierte Inhalt vonOptimieren Sie die Effizienz des HDFS-Datenzugriffs: Nutzen Sie Datenwärme und -kälte zur Verwaltung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!