In letzter Zeit werden Transformer-basierte Algorithmen häufig für verschiedene Computer-Vision-Aufgaben verwendet. Diese Art von Algorithmus ist jedoch anfällig für Überanpassungsprobleme, wenn die Menge an Trainingsdaten gering ist. Bestehende Vision Transformer führen normalerweise direkt den in CNN häufig verwendeten Dropout-Algorithmus als Regularisierer ein, der zufällige Drops auf der Aufmerksamkeitsgewichtskarte durchführt und eine einheitliche Drop-Wahrscheinlichkeit für die Aufmerksamkeitsschichten unterschiedlicher Tiefe festlegt. Obwohl Dropout sehr einfach ist, gibt es bei dieser Dropout-Methode drei Hauptprobleme. Erstens wird die Durchführung eines zufälligen Drops nach der Softmax-Normalisierung die Wahrscheinlichkeitsverteilung der Aufmerksamkeitsgewichte durchbrechen und Gewichtsspitzen nicht bestrafen, was dazu führt, dass das Modell immer noch zu stark an lokale spezifische Informationen angepasst ist (Abbildung 1). Zweitens führt eine größere Drop-Wahrscheinlichkeit in den tieferen Schichten des Netzwerks zu einem Mangel an semantischen Informationen auf hoher Ebene, während eine geringere Drop-Wahrscheinlichkeit in den flacheren Schichten zu einer Überanpassung an die zugrunde liegenden detaillierten Merkmale führt, sodass eine konstante Drop-Wahrscheinlichkeit zu einem Mangel führt zu Instabilität im Trainingsprozess führen. Schließlich ist die Wirksamkeit der in CNN üblicherweise verwendeten strukturierten Drop-Methode bei Vision Transformer nicht klar. 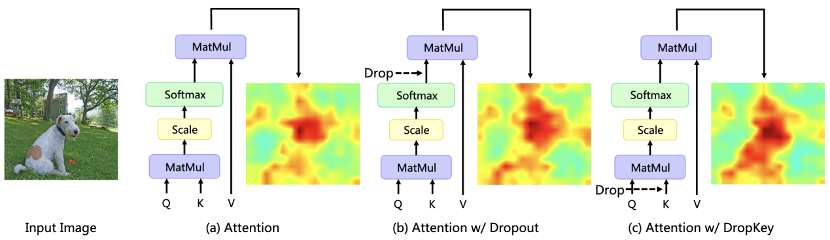
Abbildung 1 Der Einfluss verschiedener Regularisierer auf die Aufmerksamkeitsverteilungskarte Das Meitu Imaging Research Institute (MT Lab) und die University of Chinese Academy of Sciences haben einen Artikel über CVPR 2023 veröffentlicht. Es wird ein neuartiger Plug-and-Play-Regularisierer DropKey vorgeschlagen, der das Überanpassungsproblem in Vision Transformer wirksam lindern kann. 
Papierlink: https://arxiv.org/abs/2208.02646Die folgenden drei Kernthemen werden in dem Artikel untersucht: Erstens: Was sollte in der Aufmerksamkeitsschicht-Information getan werden? Drop-Operation ausführen? Im Gegensatz zum direkten Löschen des Aufmerksamkeitsgewichts führt diese Methode die Drop-Operation vor der Berechnung der Aufmerksamkeitsmatrix aus und verwendet den Schlüssel als Basis-Drop-Einheit. Diese Methode verifiziert theoretisch, dass der Regularisierer DropKey Bereiche mit hoher Aufmerksamkeit bestrafen und anderen Interessenbereichen Aufmerksamkeitsgewichte zuweisen kann, wodurch die Fähigkeit des Modells zur Erfassung globaler Informationen verbessert wird. Zweitens: Wie stellt man die Drop-Wahrscheinlichkeit ein? Im Vergleich dazu, dass alle Schichten die gleiche Drop-Wahrscheinlichkeit haben, schlägt dieser Artikel eine neuartige Methode zur Einstellung der Drop-Wahrscheinlichkeit vor, die den Drop-Wahrscheinlichkeitswert mit zunehmender Tiefe der Selbstaufmerksamkeitsschicht allmählich abschwächt. Drittens ist es notwendig, strukturierte Drop-Operationen wie CNN durchzuführen? Diese Methode versuchte einen strukturierten Drop-Ansatz basierend auf Blockfenstern und Kreuzfenstern und stellte fest, dass diese Technik für den Vision Transformer nicht wichtig war. Vision Transformer (ViT) ist ein neues Paradigma in aktuellen Computer-Vision-Modellen. Es wird häufig für Aufgaben wie Bilderkennung, Bildsegmentierung, Erkennung menschlicher Schlüsselpunkte und gegenseitige Erkennung verwendet Leute. Mitte. Insbesondere unterteilt ViT das Bild in eine feste Anzahl von Bildblöcken, behandelt jeden Bildblock als Grundeinheit und führt einen Mehrkopf-Selbstaufmerksamkeitsmechanismus ein, um Merkmalsinformationen zu extrahieren, die gegenseitige Beziehungen enthalten. Bestehende ViT-ähnliche Methoden leiden jedoch häufig unter Überanpassungsproblemen bei kleinen Datensätzen, d. h. sie nutzen nur lokale Merkmale des Ziels, um bestimmte Aufgaben auszuführen. Um die oben genannten Probleme zu überwinden, schlägt dieses Papier einen Plug-and-Play-Regularisierer DropKey vor, der in nur zwei Codezeilen implementiert werden kann, um das Überanpassungsproblem der ViT-Klassenmethode zu lindern. Im Gegensatz zum bestehenden Dropout legt DropKey den Schlüssel auf das Drop-Objekt fest und hat theoretisch und experimentell bestätigt, dass diese Änderung Teile mit hohen Aufmerksamkeitswerten bestrafen kann, während das Modell gleichzeitig dazu ermutigt wird, anderen Bildfeldern im Zusammenhang mit dem Ziel mehr Aufmerksamkeit zu schenken ist hilfreich, um globale robuste Funktionen zu erfassen. Darüber hinaus schlägt das Papier auch vor, abnehmende Drop-Wahrscheinlichkeiten für immer tiefere Aufmerksamkeitsschichten festzulegen, wodurch verhindert werden kann, dass das Modell Merkmale auf niedriger Ebene überpasst, und gleichzeitig ausreichend Merkmale auf hoher Ebene für ein stabiles Training sichergestellt werden. Darüber hinaus beweist die Arbeit experimentell, dass die Methode des strukturierten Tropfens für ViT nicht erforderlich ist. Um die wesentlichen Gründe zu untersuchen, die das Überanpassungsproblem verursachen, formalisierte diese Forschung zunächst den Aufmerksamkeitsmechanismus in ein einfaches Optimierungsziel und analysierte seine Lagrange-Entwicklungsform. Es wurde festgestellt, dass bei kontinuierlicher Optimierung des Modells Bildfeldern mit einem größeren Aufmerksamkeitsanteil in der aktuellen Iteration in der nächsten Iteration tendenziell ein größeres Aufmerksamkeitsgewicht zugewiesen wird. Um dieses Problem zu lindern, weist DropKey jedem Aufmerksamkeitsblock implizit einen adaptiven Operator zu, indem ein Teil des Schlüssels zufällig gelöscht wird, um die Aufmerksamkeitsverteilung einzuschränken und glatter zu machen. Es ist erwähnenswert, dass DropKey im Vergleich zu anderen Regularisierern, die für bestimmte Aufgaben entwickelt wurden, keinen manuellen Entwurf erfordert. Da während der Trainingsphase zufällige Drops auf Key durchgeführt werden, was zu inkonsistenten Ausgabeerwartungen in der Trainings- und Testphase führt, schlägt diese Methode auch vor, Monte-Carlo-Methoden oder Feinabstimmungstechniken zu verwenden, um die Ausgabeerwartungen auszurichten. Darüber hinaus erfordert die Implementierung dieser Methode nur zwei Codezeilen, wie in Abbildung 2 dargestellt. 
Abbildung 2 DropKey-ImplementierungsmethodeIm Allgemeinen überlagert ViT mehrere Aufmerksamkeitsebenen, um nach und nach hochdimensionale Funktionen zu lernen. Typischerweise extrahieren flachere Schichten niedrigdimensionale visuelle Merkmale, während tiefere Schichten darauf abzielen, grobe, aber komplexe Informationen über den Modellierungsraum zu extrahieren. Daher wird in dieser Studie versucht, eine geringere Drop-Wahrscheinlichkeit für tiefe Schichten festzulegen, um den Verlust wichtiger Informationen des Zielobjekts zu vermeiden. Insbesondere führt DropKey keine zufälligen Drops mit einer festen Wahrscheinlichkeit auf jeder Ebene durch, sondern verringert die Drop-Wahrscheinlichkeit schrittweise mit zunehmender Anzahl der Layer. Darüber hinaus ergab die Studie, dass dieser Ansatz nicht nur mit DropKey funktioniert, sondern auch die Dropout-Leistung erheblich verbessert. Obwohl die strukturierte Drop-Methode in CNN ausführlich untersucht wurde, wurden die Auswirkungen dieser Drop-Methode auf die Leistung auf ViT nicht untersucht. Um zu untersuchen, ob diese Strategie die Leistung weiter verbessert, implementiert das Papier zwei strukturierte Formen von DropKey, nämlich DropKey-Block und DropKey-Cross. Unter diesen löscht DropKey-Block den kontinuierlichen Bereich im quadratischen Fenster mit der Mitte des Startpunkts und DropKey-Cross löscht den kreuzförmigen kontinuierlichen Bereich mit der Mitte des Startpunkts, wie in Abbildung 3 dargestellt. Die Studie ergab jedoch, dass der strukturierte Drop-Ansatz nicht zu Leistungsverbesserungen führte. 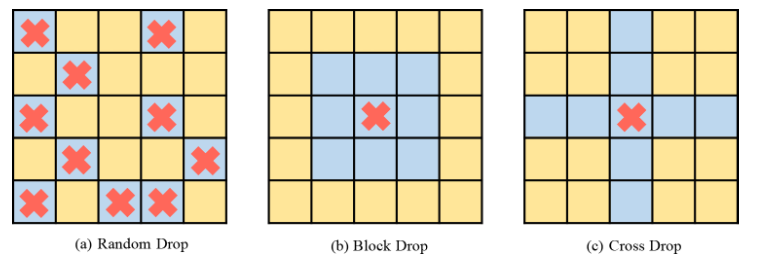
Abbildung 3 Strukturierte Implementierungsmethode von DropKey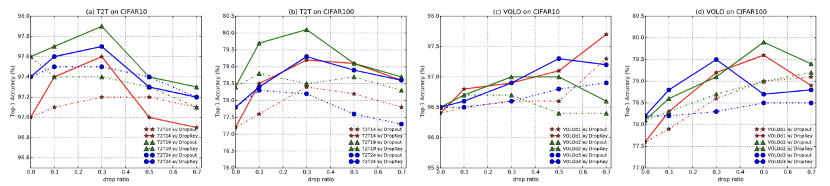
Abbildung 4 DropKey- und Drop-out-Leistungsvergleich auf CIFAR10/100 
Abbildung 5 Vergleich der Aufmerksamkeitskarten-Visualisierungseffekte von DropKey und Dropout auf CIFAR100 Abbildung 7 Leistungsvergleich verschiedener Strategien zur Ausrichtung der Ausgabeerwartungen
Bild 9 Leistungsvergleich von DropKey und Dropout auf ImageNet
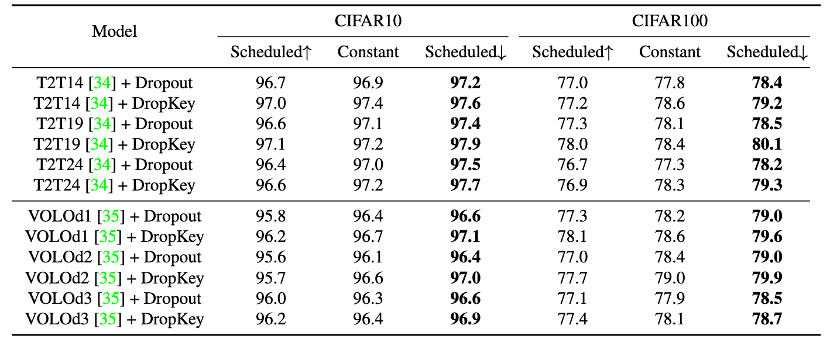
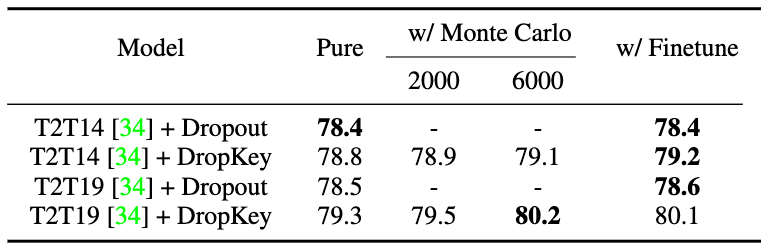 Abbildung 10 Leistungsvergleich von DropKey und Dropout auf COCO
Abbildung 10 Leistungsvergleich von DropKey und Dropout auf COCO
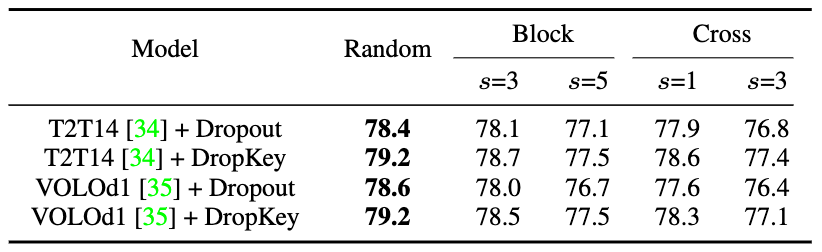
Abbildung 11 Leistungsvergleich von DropKey und Dropout auf HICO-DET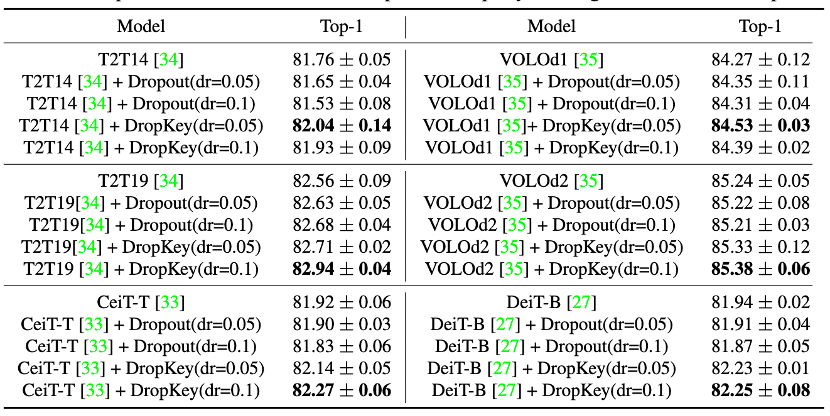
Abbildung Leistungsvergleich von DropKey und Dropout auf HICO-DET
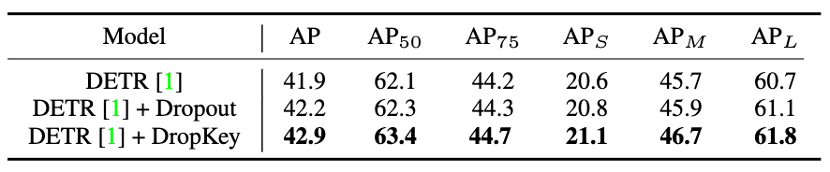
Abbildung 13 Visueller Vergleich der Aufmerksamkeitskarten zwischen DropKey und Dropout auf HICO-DET Problem von ViT. Im Vergleich zu bestehenden Regularisierern kann diese Methode durch einfaches Festlegen von Key als Drop-Objekt eine reibungslose Aufmerksamkeitsverteilung für die Aufmerksamkeitsschicht gewährleisten. Darüber hinaus schlägt das Papier auch eine neuartige Strategie zur Einstellung der Drop-Wahrscheinlichkeit vor, die den Trainingsprozess erfolgreich stabilisiert und gleichzeitig die Überanpassung wirksam lindert. Abschließend untersucht das Papier auch die Auswirkungen strukturierter Drop-Methoden auf die Modellleistung. Das obige ist der detaillierte Inhalt vonCVPR 2023|Meitu und die National University of Science and Technology schlugen gemeinsam die DropKey-Regularisierungsmethode vor: Verwendung von zwei Codezeilen, um das Problem der visuellen Transformer-Überanpassung effektiv zu vermeiden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

