
Heim >System-Tutorial >LINUX >Vergleich der Server-E/A-Leistung von Node, PHP, Java und Go
Vergleich der Server-E/A-Leistung von Node, PHP, Java und Go

- PHPznach vorne
- 2024-01-14 14:36:061233Durchsuche
| Einführung | Das Verständnis des Eingabe-/Ausgabemodells (I/O) einer Anwendung bedeutet den Unterschied zwischen ihrer geplanten Verarbeitungslast und brutalen realen Nutzungsszenarien. Wenn die Anwendung relativ klein ist und keine hohe Auslastung bereitstellt, hat sie möglicherweise nur geringe Auswirkungen. Wenn jedoch die Belastung Ihrer Anwendung allmählich zunimmt, kann die Einführung des falschen E/A-Modells viele Fallstricke und Narben hinterlassen. |
Wie bei den meisten Szenarien, in denen es mehrere Lösungen gibt, kommt es nicht darauf an, welche die bessere ist, sondern vielmehr darum, zu verstehen, wie man die Kompromisse eingeht. Machen wir einen Rundgang durch die I/O-Landschaft und sehen, was wir daraus stehlen können.

In diesem Artikel vergleichen wir Node, Java, Go und PHP mit Apache, diskutieren, wie diese verschiedenen Sprachen ihre E/A modellieren, die Vor- und Nachteile jedes Modells und ziehen einige vorläufige Schlussfolgerungen zum Benchmark. Wenn Sie sich Gedanken über die I/O-Leistung Ihrer nächsten Webanwendung machen, dann haben Sie den richtigen Artikel gefunden.
I/O-Grundlagen: Ein kurzer ÜberblickUm die Faktoren zu verstehen, die eng mit E/A zusammenhängen, müssen wir zunächst die zugrunde liegenden Konzepte des Betriebssystems überprüfen. Obwohl Sie die meisten dieser Konzepte nicht direkt behandeln, haben Sie sie indirekt über die Laufzeitumgebung der Anwendung behandelt. Und der Teufel steckt im Detail.
SystemaufrufZuerst haben wir den Systemaufruf, der wie folgt beschrieben werden kann:
- Ihr Programm (im „Userland“, wie man sagt) muss es dem Betriebssystemkern erlauben, I/O-Vorgänge selbstständig durchzuführen.
- Ein „Systemaufruf“ (Syscall) bedeutet, dass Ihr Programm den Kernel auffordert, etwas zu tun. Verschiedene Betriebssysteme haben unterschiedliche Implementierungsdetails von Systemaufrufen, das Grundkonzept ist jedoch dasselbe. Dies wird einige spezifische Anweisungen enthalten, die die Kontrolle von Ihrem Programm an den Kernel übertragen (ähnlich einem Funktionsaufruf, aber mit einigen speziellen Saucen, die für dieses Szenario entwickelt wurden). Normalerweise blockieren Systemaufrufe, was bedeutet, dass Ihr Programm warten muss, bis der Kernel zu Ihrem Code zurückkehrt.
- Der Kernel führt E/A-Vorgänge auf niedriger Ebene auf sogenannten physischen Geräten (Festplatten, Netzwerkkarten usw.) durch und reagiert auf Systemaufrufe. In der realen Welt muss der Kernel möglicherweise viele Dinge tun, um Ihre Anfrage zu erfüllen, einschließlich Warten darauf, dass das Gerät bereit ist, seinen internen Status aktualisieren usw., aber als Anwendungsentwickler müssen Sie sich keine Sorgen machen über das. So funktioniert der Kernel.
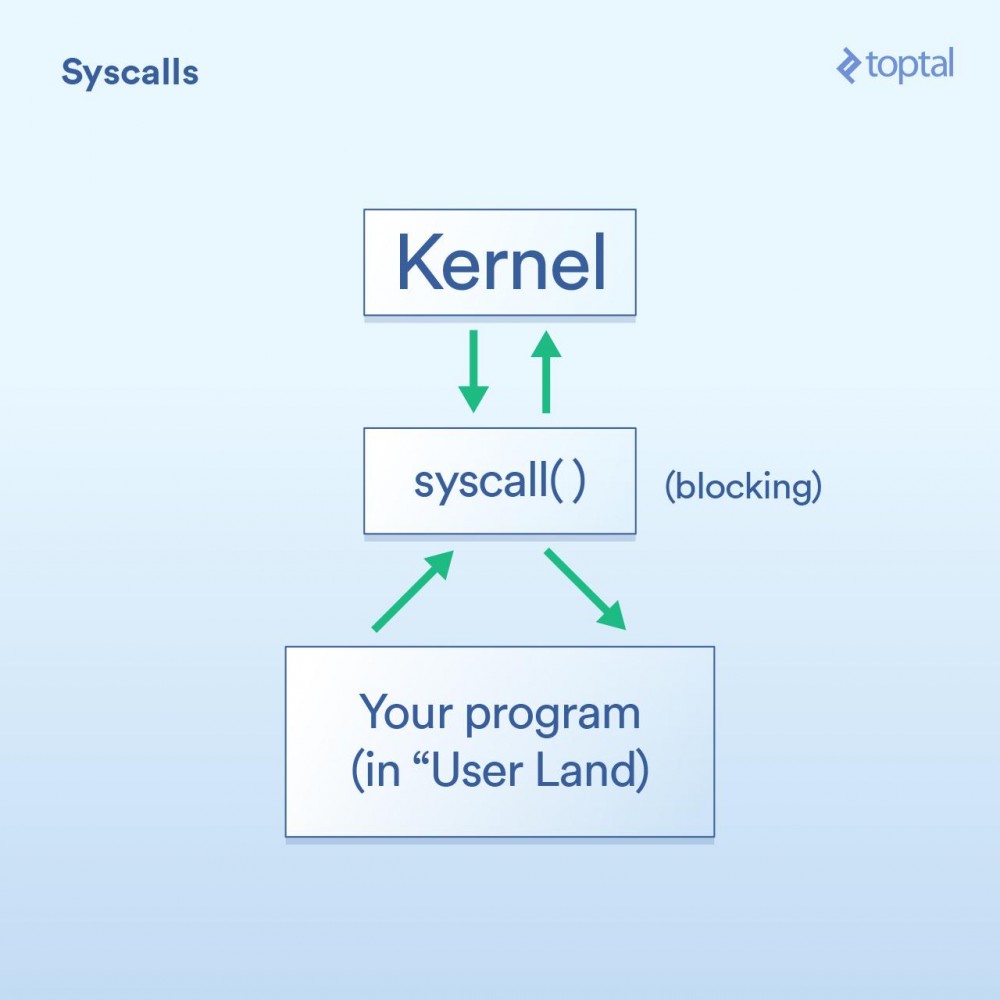
Okay, ich habe oben gerade gesagt, dass Systemaufrufe blockieren. Einige Aufrufe werden jedoch als „nicht blockierend“ klassifiziert, was bedeutet, dass der Kernel Ihre Anfrage empfängt, sie irgendwo in eine Warteschlange oder einen Puffer stellt und dann sofort zurückkehrt, ohne auf den eigentlichen I/O-Aufruf zu warten. Es „blockiert“ also nur für einen sehr kurzen Zeitraum, gerade genug, um Ihre Anfrage in die Warteschlange zu stellen.
Hier sind einige Beispiele (Linux-Systemaufrufe) zur Erläuterung: -read() ist ein blockierender Aufruf – Sie übergeben ihm ein Dateihandle und einen Puffer, um die gelesenen Daten zu speichern, und dann wird der Aufruf zurückgegeben, wenn die Daten vorliegen bereit. Beachten Sie, dass dieser Ansatz den Vorteil von Eleganz und Einfachheit hat. -epoll_create() , epoll_ctl() und epoll_wait() sind Aufrufe, mit denen Sie einen Satz von Handles zum Abhören erstellen, Handles zu diesem Satz hinzufügen/entfernen und dann warten können, bis Aktivität vorliegt Gerade blockiert. Dadurch können Sie eine Reihe von E/A-Vorgängen effizient über einen Thread steuern. Das ist großartig, wenn Sie diese Funktionen benötigen, aber wie Sie sehen, ist die Verwendung sicherlich ziemlich komplex.
Hier ist es wichtig, die Größenordnung des Zeitunterschieds zu verstehen. Wenn ein CPU-Kern ohne Optimierung mit 3 GHz läuft, führt er 3 Milliarden Schleifen pro Sekunde (oder 3 Schleifen pro Nanosekunde) aus. Ein nicht blockierender Systemaufruf kann einen Zeitraum in der Größenordnung von 10 Nanosekunden dauern – oder „relativ wenige Nanosekunden“. Das Blockieren von Anrufen, die Informationen über das Netzwerk empfangen, kann länger dauern – beispielsweise 200 Millisekunden (0,2 Sekunden). Angenommen, der nicht blockierende Anruf dauerte 20 Nanosekunden, dann dauerte der blockierende Anruf 200.000.000 Nanosekunden. Beim Blockieren von Anrufen wartet Ihr Programm 10 Millionen Mal länger.

Der Kernel bietet zwei Methoden: blockierende E/A („Lesen Sie von der Netzwerkverbindung und geben Sie mir die Daten“) und nicht blockierende E/A („Sagen Sie mir, wenn diese Netzwerkverbindungen neue Daten haben“). Je nachdem, welcher Mechanismus verwendet wird, ist die Blockierungszeit des entsprechenden aufrufenden Prozesses offensichtlich unterschiedlich.
TerminplanungDer dritte wichtige Punkt ist, was zu tun ist, wenn eine große Anzahl von Threads oder Prozessen zu blockieren beginnt.
Für unsere Zwecke gibt es keinen großen Unterschied zwischen Threads und Prozessen. Tatsächlich besteht der offensichtlichste ausführungsbezogene Unterschied darin, dass Threads denselben Speicher gemeinsam nutzen, während jeder Prozess über seinen eigenen Speicherplatz verfügt, sodass separate Prozesse häufig große Speichermengen belegen. Aber wenn wir über die Planung sprechen, läuft es letztendlich auf eine Liste von Ereignissen (Threads und Prozesse gleichermaßen) hinaus, wobei jedes Ereignis einen Teil der Ausführungszeit auf einem verfügbaren CPU-Kern erhalten muss. Wenn 300 Threads laufen und Sie auf 8 Kernen laufen, müssen Sie diese Zeit verteilen, damit jeder Thread etwas bekommt, indem Sie jeden Kern für einen kurzen Zeitraum ausführen und dann zum nächsten Thread wechseln. Dies wird durch „Kontextwechsel“ erreicht, der es der CPU ermöglicht, von einem laufenden Thread/Prozess zum nächsten zu wechseln.
Diese Kontextwechsel haben ihren Preis – sie nehmen einige Zeit in Anspruch. Wenn es schnell ist, beträgt es wahrscheinlich weniger als 100 Nanosekunden, es ist jedoch nicht ungewöhnlich, dass es je nach Implementierungsdetails, Prozessorgeschwindigkeit/-architektur, CPU-Cache usw. 1000 Nanosekunden oder mehr dauert.
Je mehr Threads (oder Prozesse) es gibt, desto mehr Kontextwechsel gibt es. Wenn wir über Tausende von Threads sprechen und jeder Wechsel Hunderte von Nanosekunden dauert, wird es sehr langsam sein.
Ein nicht blockierender Aufruf teilt dem Kernel jedoch im Wesentlichen mit: „Rufen Sie mich nur an, wenn Sie neue Daten haben oder bei einer dieser Verbindungen ein Ereignis auftritt.“ Diese nicht blockierenden Aufrufe sind darauf ausgelegt, große E/A-Lasten effizient zu verarbeiten und Kontextwechsel zu reduzieren.
Lesen Sie diesen Artikel bisher noch? Denn jetzt kommt der spaßige Teil: Werfen wir einen Blick darauf, wie einige fließende Sprachen diese Tools verwenden, und ziehen wir einige Schlussfolgerungen über die Kompromisse zwischen Benutzerfreundlichkeit und Leistung ... und andere interessante Kommentare.
Bitte beachten Sie, dass die in diesem Beitrag gezeigten Beispiele zwar trivial sind (und unvollständig sind und nur die relevanten Teile des Codes zeigen), Datenbankzugriffe, externe Caching-Systeme (Memcache usw. alle) und solche, die I/O erfordern, aber alles endet Durchführen einiger zugrunde liegender E/A-Vorgänge, die die gleichen Auswirkungen haben wie die gezeigten Beispiele. Ebenso sind in Situationen, in denen E/A als „blockierend“ beschrieben wird (PHP, Java), das Lesen und Schreiben von HTTP-Anforderungen und -Antworten selbst blockierende Aufrufe: Auch hier sind mehr E/A im System O und den damit verbundenen Daten verborgen Leistungsprobleme müssen berücksichtigt werden.
Bei der Auswahl einer Programmiersprache für Ihr Projekt sind viele Faktoren zu berücksichtigen. Wenn Sie nur die Leistung berücksichtigen, müssen noch mehr Faktoren berücksichtigt werden. Wenn Sie jedoch befürchten, dass Ihr Programm in erster Linie E/A-gebunden ist und die E/A-Leistung für Ihr Projekt von entscheidender Bedeutung ist, müssen Sie Folgendes wissen. Der „Keep it simple“-Ansatz: PHP.
In den 90er Jahren trugen viele Leute Converse-Schuhe und schrieben CGI-Skripte in Perl. Dann erschien PHP und viele Leute nutzten es gerne, was die Erstellung dynamischer Webseiten erleichterte.
Das von PHP verwendete Modell ist recht einfach. Es gibt einige Variationen, aber im Grunde sieht ein PHP-Server so aus:
Die HTTP-Anfrage kommt vom Browser des Benutzers und greift auf Ihren Apache-Webserver zu. Apache erstellt für jede Anfrage einen separaten Prozess und verwendet sie mit einigen Optimierungen wieder, um die Anzahl der erforderlichen Ausführungen zu minimieren (das Erstellen von Prozessen ist relativ langsam). Apache ruft PHP auf und weist es an, die entsprechende .php-Datei auf der Festplatte auszuführen. Der PHP-Code wird ausgeführt und führt einige blockierende E/A-Aufrufe durch. Wenn file_get_contents() in PHP aufgerufen wird, löst es hinter den Kulissen den Systemaufruf read() aus und wartet auf die Rückgabe des Ergebnisses.
Natürlich wird der eigentliche Code einfach in Ihre Seite eingebettet und der Vorgang blockiert:
<?php
// 阻塞的文件I/O
$file_data = file_get_contents('/path/to/file.dat');
// 阻塞的网络I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// 更多阻塞的网络I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>
Über die Integration in das System, etwa so:
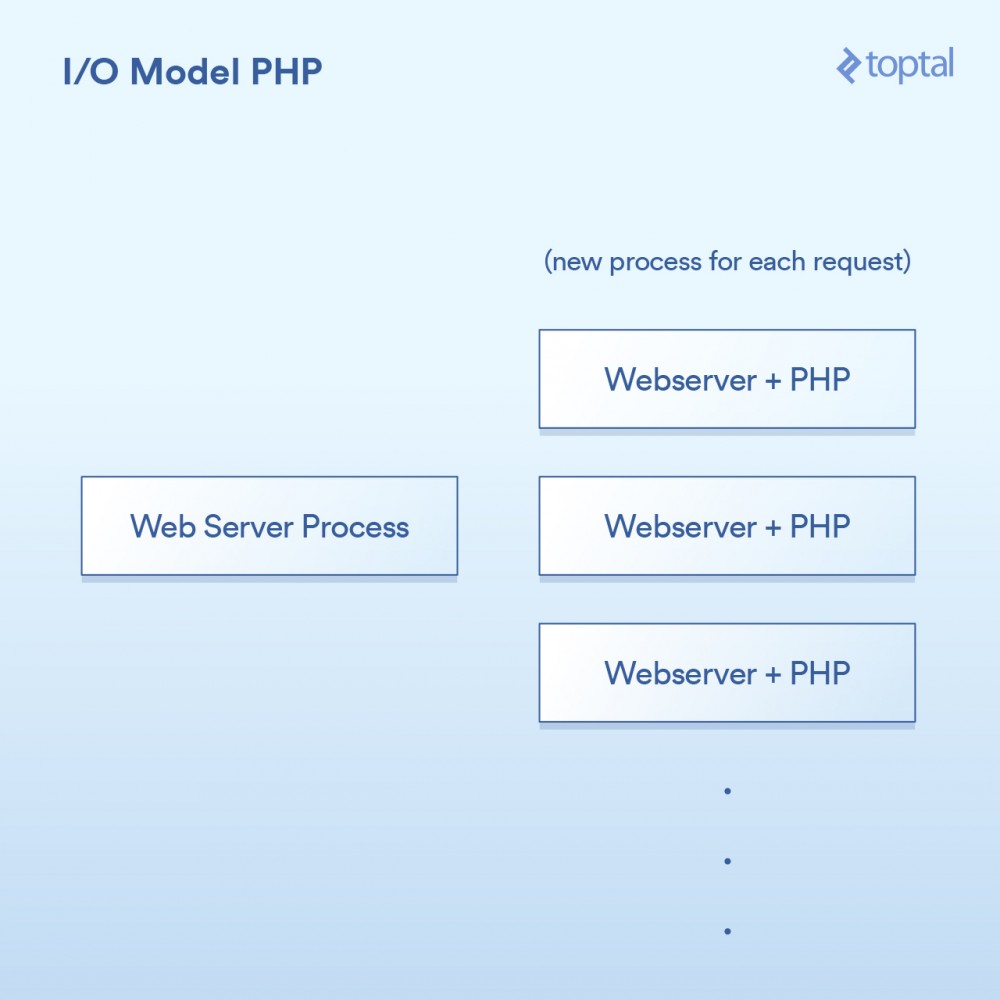
相当简单:一个请求,一个进程。I/O是阻塞的。优点是什么呢?简单,可行。那缺点是什么呢?同时与20,000个客户端连接,你的服务器就挂了。由于内核提供的用于处理大容量I/O(epoll等)的工具没有被使用,所以这种方法不能很好地扩展。更糟糕的是,为每个请求运行一个单独的过程往往会使用大量的系统资源,尤其是内存,这通常是在这样的场景中遇到的第一件事情。
注意:Ruby使用的方法与PHP非常相似,在广泛而普遍的方式下,我们可以将其视为是相同的。
多线程的方式:Java所以就在你买了你的第一个域名的时候,Java来了,并且在一个句子之后随便说一句“dot com”是很酷的。而Java具有语言内置的多线程(特别是在创建时),这一点非常棒。
大多数Java网站服务器通过为每个进来的请求启动一个新的执行线程,然后在该线程中最终调用作为应用程序开发人员的你所编写的函数。
在Java的Servlet中执行I/O操作,往往看起来像是这样:
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// 阻塞的文件I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// 阻塞的网络I/O
URLConnection urlConnection = (new URL("https://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// 更多阻塞的网络I/O
out.println("...");
}
由于我们上面的doGet 方法对应于一个请求并且在自己的线程中运行,而不是每次请求都对应需要有自己专属内存的单独进程,所以我们会有一个单独的线程。这样会有一些不错的优点,例如可以在线程之间共享状态、共享缓存的数据等,因为它们可以相互访问各自的内存,但是它如何与调度进行交互的影响,仍然与前面PHP例子中所做的内容几乎一模一样。每个请求都会产生一个新的线程,而在这个线程中的各种I/O操作会一直阻塞,直到这个请求被完全处理为止。为了最小化创建和销毁它们的成本,线程会被汇集在一起,但是依然,有成千上万个连接就意味着成千上万个线程,这对于调度器是不利的。
一个重要的里程碑是,在Java 1.4 版本(和再次显著升级的1.7 版本)中,获得了执行非阻塞I/O调用的能力。大多数应用程序,网站和其他程序,并没有使用它,但至少它是可获得的。一些Java网站服务器尝试以各种方式利用这一点; 然而,绝大多数已经部署的Java应用程序仍然如上所述那样工作。
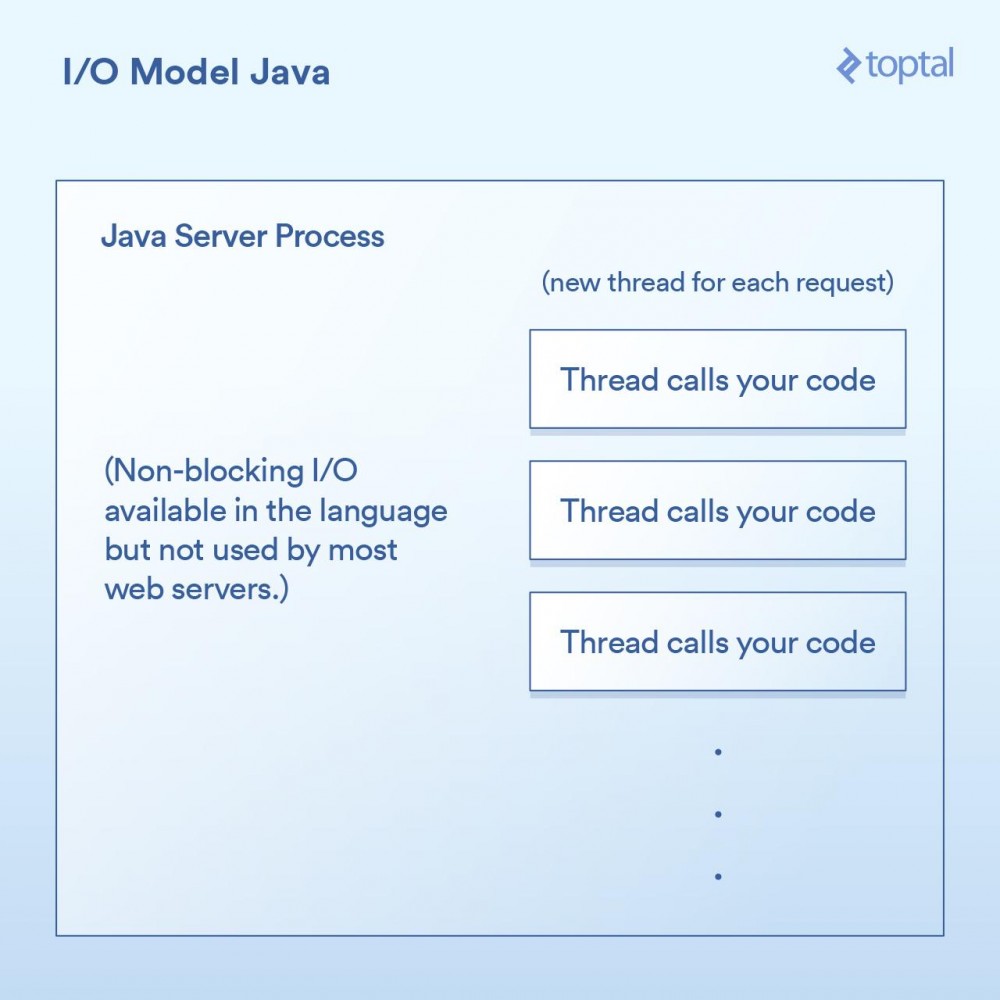
Java让我们更进了一步,当然对于I/O也有一些很好的“开箱即用”的功能,但它仍然没有真正解决问题:当你有一个严重I/O绑定的应用程序正在被数千个阻塞线程狂拽着快要坠落至地面时怎么办。
作为一等公民的非阻塞I/O:Node当谈到更好的I/O时,Node.js无疑是新宠。任何曾经对Node有过最简单了解的人都被告知它是“非阻塞”的,并且它能有效地处理I/O。在一般意义上,这是正确的。但魔鬼藏在细节中,当谈及性能时这个巫术的实现方式至关重要。
本质上,Node实现的范式不是基本上说“在这里编写代码来处理请求”,而是转变成“在这里写代码开始处理请求”。每次你都需要做一些涉及I/O的事情,发出请求或者提供一个当完成时Node会调用的回调函数。
在求中进行I/O操作的典型Node代码,如下所示:
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});
可以看到,这里有两个回调函数。第一个会在请求开始时被调用,而第二个会在文件数据可用时被调用。
这样做的基本上给了Node一个在这些回调函数之间有效地处理I/O的机会。一个更加相关的场景是在Node中进行数据库调用,但我不想再列出这个烦人的例子,因为它是完全一样的原则:启动数据库调用,并提供一个回调函数给Node,它使用非阻塞调用单独执行I/O操作,然后在你所要求的数据可用时调用回调函数。这种I/O调用队列,让Node来处理,然后获取回调函数的机制称为“事件循环”。它工作得非常好。
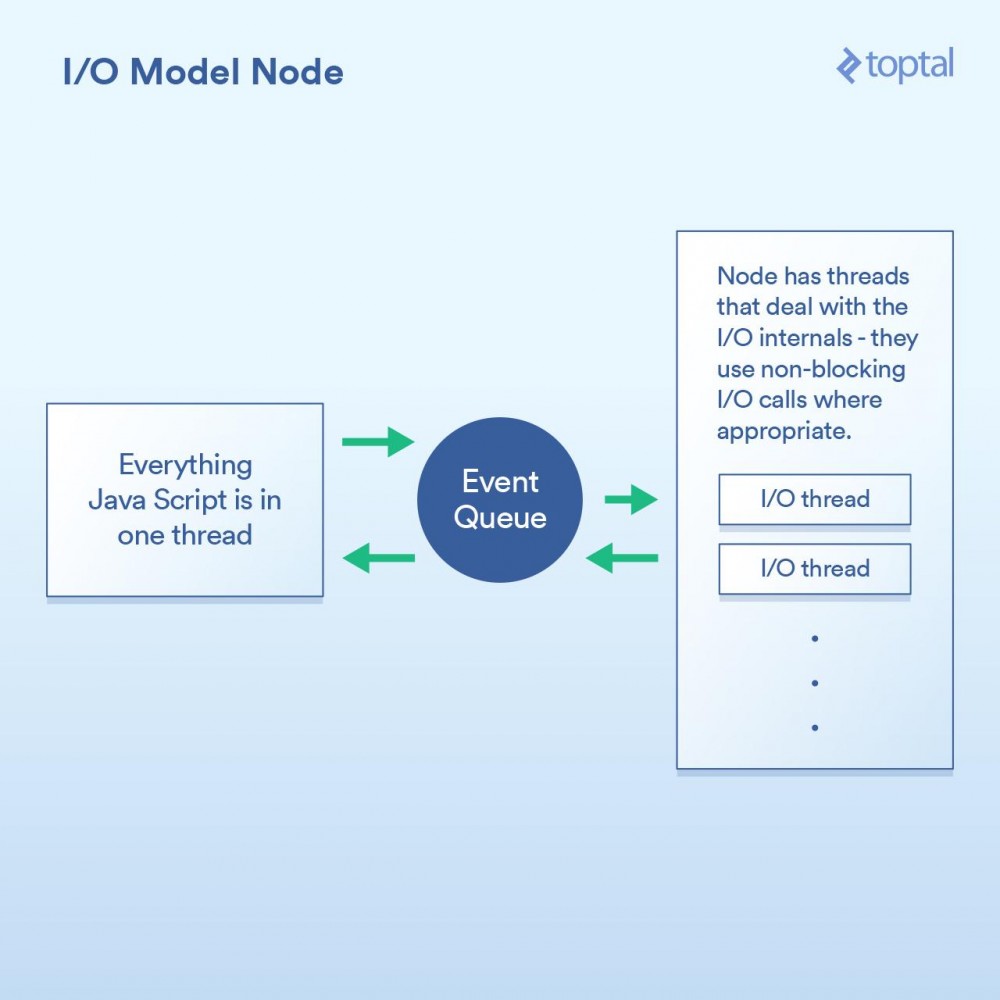
然而,这个模型中有一道关卡。在幕后,究其原因,更多是如何实现JavaScript V8 引擎(Chrome的JS引擎,用于Node)1,而不是其他任何事情。你所编写的JS代码全部都运行在一个线程中。思考一下。这意味着当使用有效的非阻塞技术执行I/O时,正在进行CPU绑定操作的JS可以在运行在单线程中,每个代码块阻塞下一个。 一个常见的例子是循环数据库记录,在输出到客户端前以某种方式处理它们。以下是一个例子,演示了它如何工作:
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// 对每一行纪录进行处理
}
response.end(...); // 输出结果
})
};
虽然Node确实可以有效地处理I/O,但上面的例子中的for 循环使用的是在你主线程中的CPU周期。这意味着,如果你有10,000个连接,该循环有可能会让你整个应用程序慢如蜗牛,具体取决于每次循环需要多长时间。每个请求必须分享在主线程中的一段时间,一次一个。
这个整体概念的前提是I/O操作是最慢的部分,因此最重要是有效地处理这些操作,即使意味着串行进行其他处理。这在某些情况下是正确的,但不是全都正确。
另一点是,虽然这只是一个意见,但是写一堆嵌套的回调可能会令人相当讨厌,有些人认为它使得代码明显无章可循。在Node代码的深处,看到嵌套四层、嵌套五层、甚至更多层级的嵌套并不罕见。
我们再次回到了权衡。如果你主要的性能问题在于I/O,那么Node模型能很好地工作。然而,它的阿喀琉斯之踵(
真正的非阻塞:Go在进入Go这一章节之前,我应该披露我是一名Go粉丝。我已经在许多项目中使用Go,是其生产力优势的公开支持者,并且在使用时我在工作中看到了他们。
也就是说,我们来看看它是如何处理I/O的。Go语言的一个关键特性是它包含自己的调度器。并不是每个线程的执行对应于一个单一的OS线程,Go采用的是“goroutines”这一概念。Go运行时可以将一个goroutine分配给一个OS线程并使其执行,或者把它挂起而不与OS线程关联,这取决于goroutine做的是什么。来自Go的HTTP服务器的每个请求都在单独的Goroutine中处理。
此调度器工作的示意图,如下所示:

这是通过在Go运行时的各个点来实现的,通过将请求写入/读取/连接/等实现I/O调用,让当前的goroutine进入睡眠状态,当可采取进一步行动时用信息把goroutine重新唤醒。
实际上,除了回调机制内置到I/O调用的实现中并自动与调度器交互外,Go运行时做的事情与Node做的事情并没有太多不同。它也不受必须把所有的处理程序代码都运行在同一个线程中这一限制,Go将会根据其调度器的逻辑自动将Goroutine映射到其认为合适的OS线程上。最后代码类似这样:
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 这里底层的网络调用是非阻塞的
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// 处理rows
// 每个请求在它自己的goroutine中
}
w.Write(...) // 输出响应结果,也是非阻塞的
}
正如你在上面见到的,我们的基本代码结构像是更简单的方式,并且在背后实现了非阻塞I/O。
在大多数情况下,这最终是“两个世界中最好的”。非阻塞I/O用于全部重要的事情,但是你的代码看起来像是阻塞,因此往往更容易理解和维护。Go调度器和OS调度器之间的交互处理了剩下的部分。这不是完整的魔法,如果你建立的是一个大型的系统,那么花更多的时间去理解它工作原理的更多细节是值得的; 但与此同时,“开箱即用”的环境可以很好地工作和很好地进行扩展。
Go可能有它的缺点,但一般来说,它处理I/O的方式不在其中。
谎言,诅咒的谎言和基准对这些各种模式的上下文切换进行准确的定时是很困难的。也可以说这对你来没有太大作用。所以取而代之,我会给出一些比较这些服务器环境的HTTP服务器性能的基准。请记住,整个端对端的HTTP请求/响应路径的性能与很多因素有关,而这里我放在一起所提供的数据只是一些样本,以便可以进行基本的比较。
对于这些环境中的每一个,我编写了适当的代码以随机字节读取一个64k大小的文件,运行一个SHA-256哈希N次(N在URL的查询字符串中指定,例如.../test.php?n=100 ),并以十六进制形式打印生成的散列。我选择了这个示例,是因为使用一些一致的I/O和一个受控的方式增加CPU使用率来运行相同的基准测试是一个非常简单的方式。
Weitere Einzelheiten zum Umweltschutz finden Sie in diesen Benchmark-Punkten.
Schauen wir uns zunächst einige Beispiele für geringe Parallelität an. Wenn wir 2000 Iterationen, 300 gleichzeitige Anfragen und nur einmal Hashing pro Anfrage (N = 1) ausführen, erhalten wir:
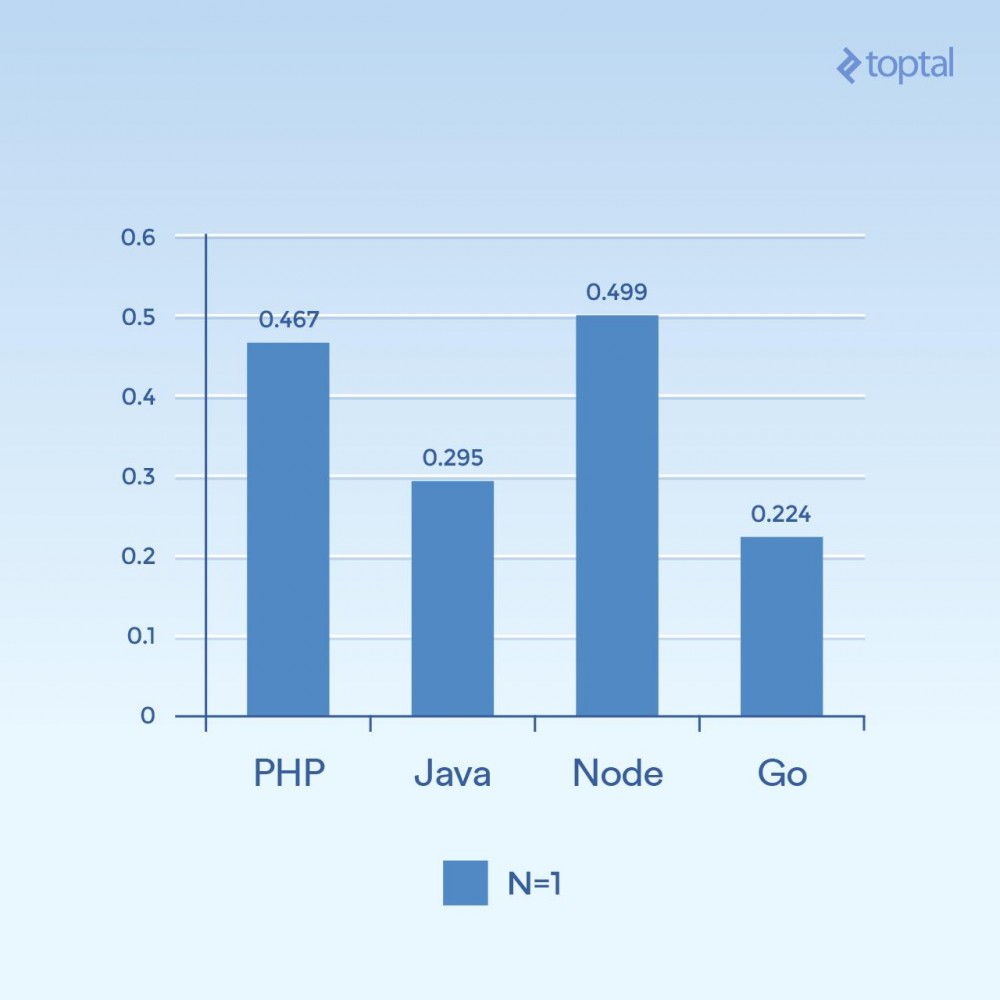
Zeit ist die durchschnittliche Anzahl an Millisekunden, die von allen gleichzeitigen Anfragen benötigt wird, um eine Anfrage abzuschließen. Je niedriger, desto besser.
Es ist schwer, aus nur einem Diagramm Schlussfolgerungen zu ziehen, aber meiner Meinung nach hängt es mit Dingen wie Konnektivität und Berechnung zusammen. Wir sehen, dass die Zeit mehr mit der allgemeinen Ausführung der Sprache selbst zu tun hat, also eher mit der E/A . Beachten Sie, dass Sprachen, die als „Skriptsprachen“ gelten (willkürliche Eingabe, dynamisch interpretiert), die langsamste Leistung erbringen.
Aber was passiert, wenn Sie N auf 1000 erhöhen und immer noch 300 gleichzeitige Anfragen haben – die gleiche Last, aber 100-fache Hash-Iterationen (deutlicher Anstieg der CPU-Last):
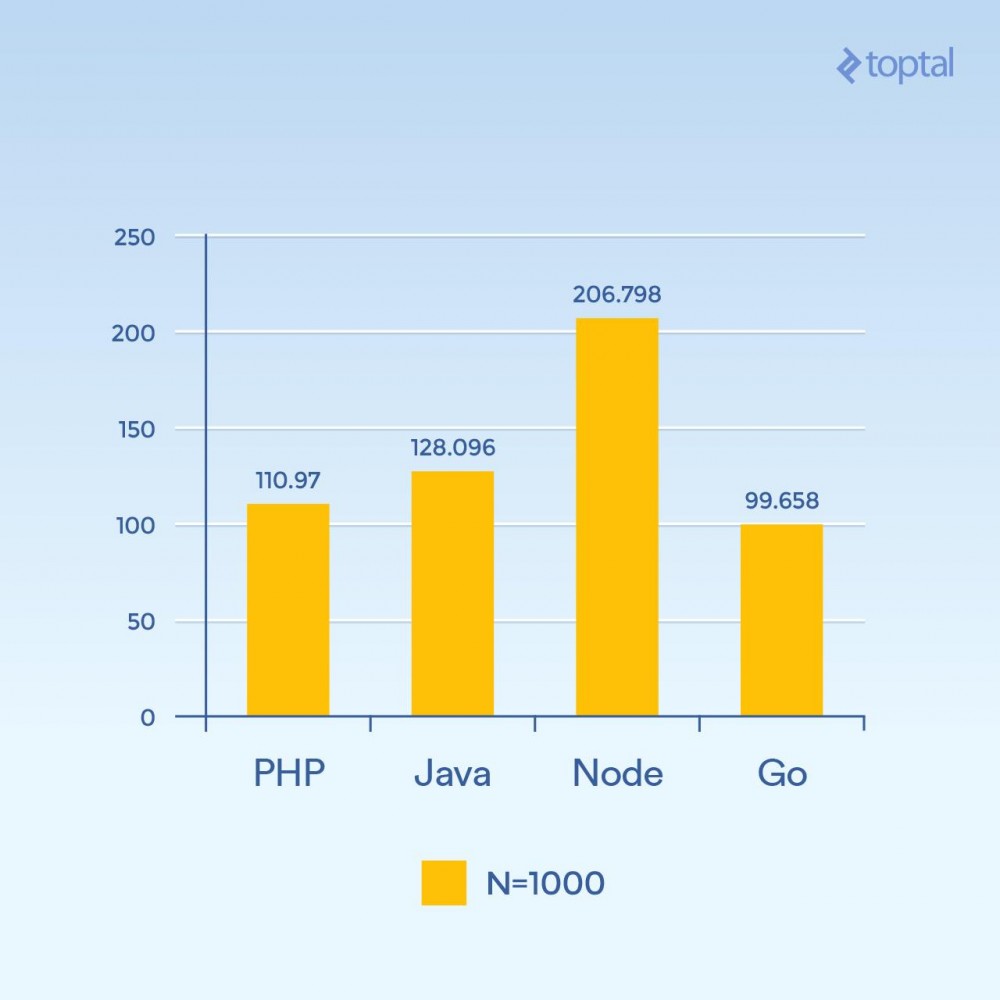
Zeit ist die durchschnittliche Anzahl an Millisekunden, die von allen gleichzeitigen Anfragen benötigt wird, um eine Anfrage abzuschließen. Je niedriger, desto besser.
Plötzlich sank die Leistung von Node erheblich, da sich CPU-intensive Vorgänge in jeder Anfrage gegenseitig blockierten. Interessanterweise schnitt PHP in diesem Test viel besser ab (im Vergleich zu anderen Sprachen) und schlug Java. (Es ist erwähnenswert, dass in PHP, wo die SHA-256-Implementierung in C geschrieben ist, der Ausführungspfad in dieser Schleife mehr Zeit benötigt, da wir dieses Mal 1000 Hash-Iterationen durchführen.)
Jetzt versuchen wir es mit 5000 gleichzeitigen Verbindungen (und N = 1) – oder in der Nähe davon. Leider ist die Ausfallrate in den meisten dieser Umgebungen nicht signifikant. In diesem Diagramm konzentrieren wir uns auf die Gesamtzahl der Anfragen pro Sekunde. Je höher desto besser:
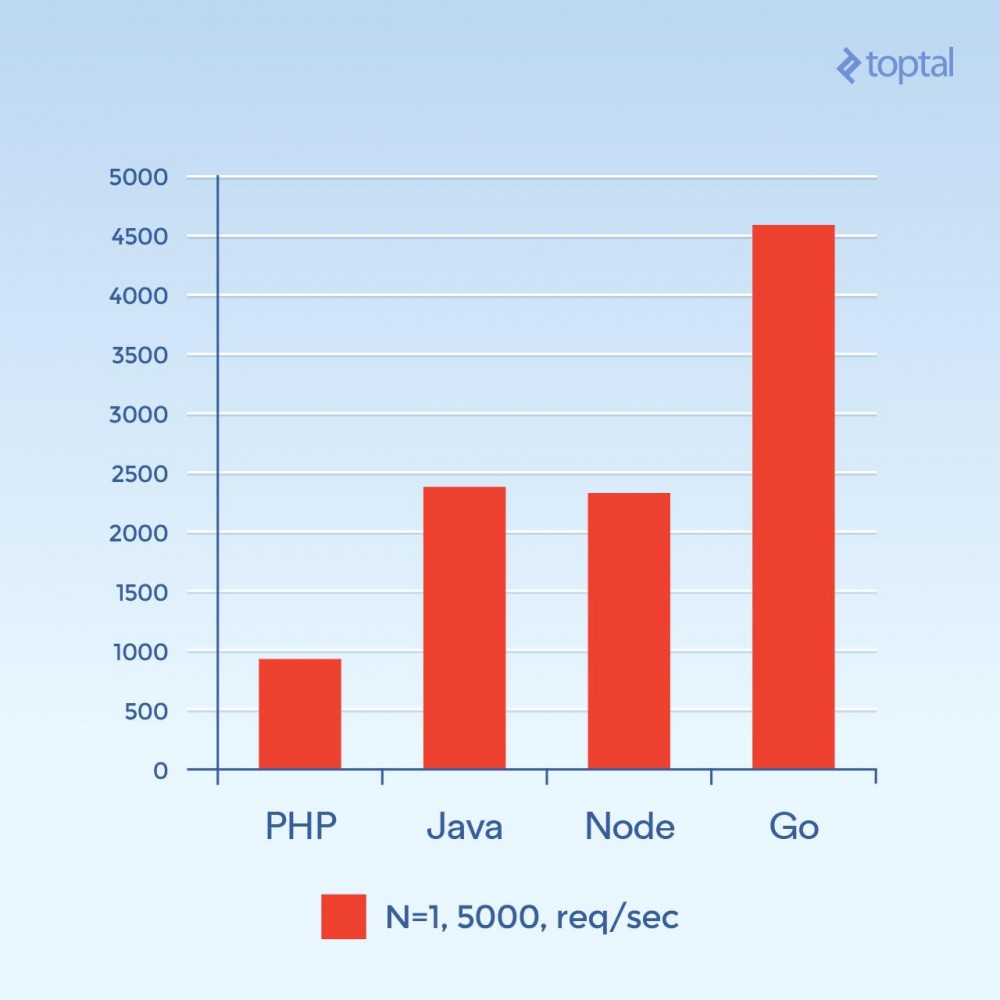
Gesamtzahl der Anfragen pro Sekunde. Je höher desto besser.
Dieses Foto sieht ganz anders aus. Dies ist eine Vermutung, aber es sieht so aus, als ob bei hohen Verbindungsvolumina der Overhead, der mit der Erzeugung eines neuen Prozesses pro Verbindung verbunden ist, und der zusätzliche Speicher, der mit PHP + Apache verbunden ist, der Hauptfaktor zu sein scheint und die Leistung von PHP einschränkt. Hier ist eindeutig Go der Gewinner, gefolgt von Java und Node und schließlich PHP.
FazitZusammenfassend ist klar, dass sich mit der Weiterentwicklung der Sprachen auch die Lösungen für große Anwendungen weiterentwickeln, die große Mengen an I/O verarbeiten.
Der Fairness halber lässt man die Beschreibung dieses Artikels vorerst außer Acht: PHP und Java verfügen über Implementierungen nicht blockierender E/A, die in Webanwendungen verwendet werden können. Diese Methoden sind jedoch nicht so verbreitet wie die oben genannten Methoden, und der damit verbundene Betriebsaufwand für die Wartung des Servers mithilfe dieser Methode muss berücksichtigt werden. Ganz zu schweigen davon, dass Ihr Code so strukturiert sein muss, dass er für diese Umgebungen geeignet ist; „normale“ PHP- oder Java-Webanwendungen unterliegen in solchen Umgebungen im Allgemeinen keinen wesentlichen Änderungen.
Zum Vergleich: Wenn Sie nur ein paar wichtige Faktoren berücksichtigen, die sich auf Leistung und Benutzerfreundlichkeit auswirken, erhalten Sie:
| Sprache | Thread oder Prozess | Nicht blockierende E/A | Benutzerfreundlichkeit | |
|---|---|---|---|---|
| PHP | Prozess | Nein | ||
| Java | Thread | Verfügbar | Benötige einen Rückruf | |
| Node.js | Thread | Ja | Benötige einen Rückruf | |
| Los | Thread (Goroutine) | Ja | Kein Rückruf erforderlich |
Threads sind im Allgemeinen speichereffizienter als Prozesse, da sie denselben Speicherplatz gemeinsam nutzen, Prozesse hingegen nicht. In Kombination mit Faktoren im Zusammenhang mit nicht blockierendem I/O kann man, wenn wir die Liste nach unten zum allgemeinen Start bewegen, der sich auf die Verbesserung von I/O bezieht, mindestens dieselben Faktoren erkennen wie die oben betrachteten. Wenn ich unter den oben genannten Spielen einen Gewinner auswählen müsste, wäre es definitiv Go.
Das heißt, in der Praxis hängt die Umgebung, in der Sie Ihre Anwendung erstellen, eng mit der Vertrautheit Ihres Teams mit dieser Umgebung und der erreichbaren Gesamtproduktivität zusammen. Daher ist es möglicherweise nicht für jedes Team sinnvoll, einfach einzuspringen und mit der Entwicklung von Webanwendungen und -diensten in Node oder Go zu beginnen. Tatsächlich wird die Vertrautheit mit Entwicklern oder internen Teams oft als Hauptgrund dafür genannt, keine andere Sprache und/oder eine andere Umgebung zu verwenden. Mit anderen Worten: Die Zeiten haben sich in den letzten fünfzehn Jahren dramatisch verändert.
Hoffentlich hilft Ihnen das oben Gesagte dabei, ein klareres Bild davon zu bekommen, was hinter den Kulissen vor sich geht, und gibt Ihnen einige Ideen, wie Sie mit der Skalierbarkeit Ihrer Anwendung in der Praxis umgehen können. Viel Spaß beim Input, viel Spaß beim Output!
Das obige ist der detaillierte Inhalt vonVergleich der Server-E/A-Leistung von Node, PHP, Java und Go. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Empfohlene Linux-Videoressourcen für die LAMP-Programmierung (Quellcode-Kursunterlagen)
- Drei Methoden zum Schließen von Linux-Systemports
- So verwenden Sie den Befehl cp zum Kopieren von Dateien unter Linux
- So ändern Sie das Root-Passwort im Linux-System
- Welche Linux-Befehle können zum Lesen von Dateien verwendet werden?