
Heim >System-Tutorial >LINUX >Eine kurze Analyse der MySQL-Architektur
Eine kurze Analyse der MySQL-Architektur

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-14 14:03:141164Durchsuche
| Einführung | Die Datenbank ist der Kern aller Anwendungssysteme, daher hat die Gewährleistung des stabilen, effizienten und sicheren Betriebs der Datenbank oberste Priorität in der täglichen Arbeit aller Unternehmen. Sobald im Datenbanksystem ein Problem auftritt und dieses keine Dienste mehr bereitstellen kann, kann dies dazu führen, dass das gesamte System nicht mehr funktionsfähig ist. Daher muss eine erfolgreiche Datenbankarchitektur auch das Hochverfügbarkeitsdesign vollständig berücksichtigen. Im Folgenden werde ich Ihnen vorstellen, wie Sie ein hochverfügbares MySQL-Datenbanksystem aufbauen. |
Die Datenbank ist das Herzstück aller Anwendungssysteme, daher hat die Gewährleistung des stabilen, effizienten und sicheren Betriebs der Datenbank für alle Unternehmen bei ihrer täglichen Arbeit oberste Priorität. Sobald im Datenbanksystem ein Problem auftritt und dieses keine Dienste mehr bereitstellen kann, kann dies dazu führen, dass das gesamte System nicht mehr funktionsfähig ist. Daher muss eine erfolgreiche Datenbankarchitektur auch das Hochverfügbarkeitsdesign vollständig berücksichtigen. Im Folgenden werde ich Ihnen vorstellen, wie Sie ein hochverfügbares MySQL-Datenbanksystem aufbauen.
Studenten, die DBA oder Betrieb und Wartung absolviert haben, sollten wissen, dass die Existenz eines einzigen Punkts für ein Gerät oder einen Dienst große Risiken mit sich bringt, denn sobald die physische Maschine ausfällt oder das Servicemodul abstürzt, kann nicht so schnell ein Ersatz gefunden werden Zeitaufwand wirkt sich zwangsläufig auf das gesamte Anwendungssystem aus. Daher ist es unsere wichtige Aufgabe, sicherzustellen, dass es keinen einzigen Punkt gibt. Die Verwendung von MySQL-Hochverfügbarkeitslösungen kann dieses Problem im Allgemeinen gut lösen:
1. Verwenden Sie die MySQL-eigene Replikation, um eine hohe Verfügbarkeit zu erreichenDie mit MySQL gelieferte Replikation wird oft als Master-Slave-Replikation (AB-Replikation) bezeichnet. Durch die Erstellung einer Slave-Maschine für den Master-Server kann das Unternehmen bei Ausfall des Master-Servers schnell auf die Slave-Maschine umgestellt werden die normale Nutzung der Anwendung. Hochverfügbarkeitslösungen mit AB-Replikation werden ebenfalls in verschiedene Architekturen unterteilt:
1. Konventionelle MASTER---SLAVE-LösungOrdinary MASTER---SLAVE ist derzeit die von den meisten kleinen und mittleren Unternehmen im In- und Ausland am häufigsten verwendete Architekturlösung. Ihre Hauptvorteile sind Einfachheit, weniger Ausrüstung (geringere Kosten) und einfache Wartung. Diese Architektur kann Einzelpunktprobleme und Systemleistungsprobleme weitgehend lösen. Auf einen MASTER können ein oder mehrere SLAVEs folgen (Master-Slave-Kaskadenreplikation). Diese Architektur erfordert jedoch, dass ein MASTER in der Lage sein muss, alle Schreibanforderungen des Systems zu erfüllen. Andernfalls ist eine horizontale Aufteilung erforderlich, um den Lesedruck zu teilen.
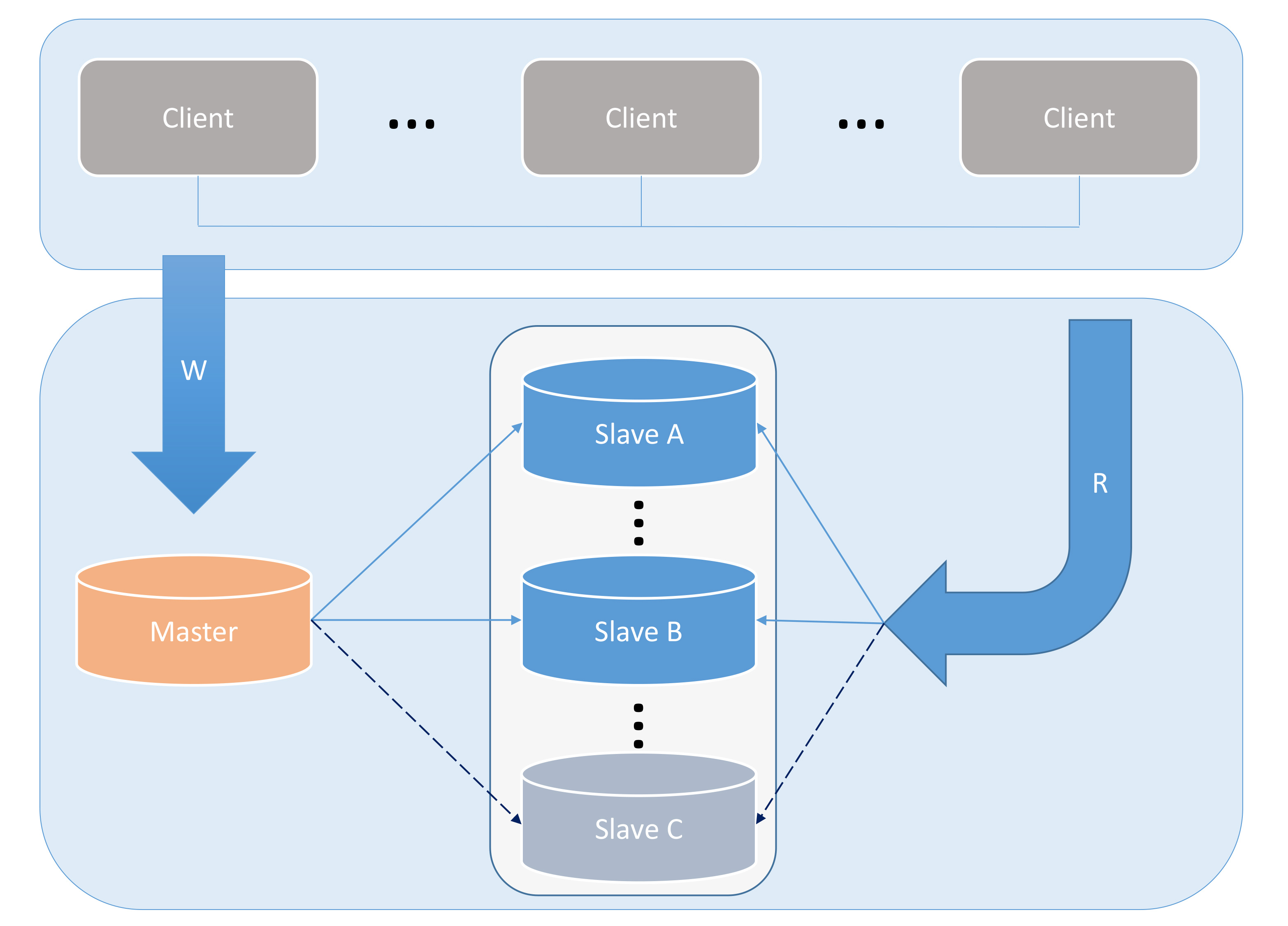
Bild 1
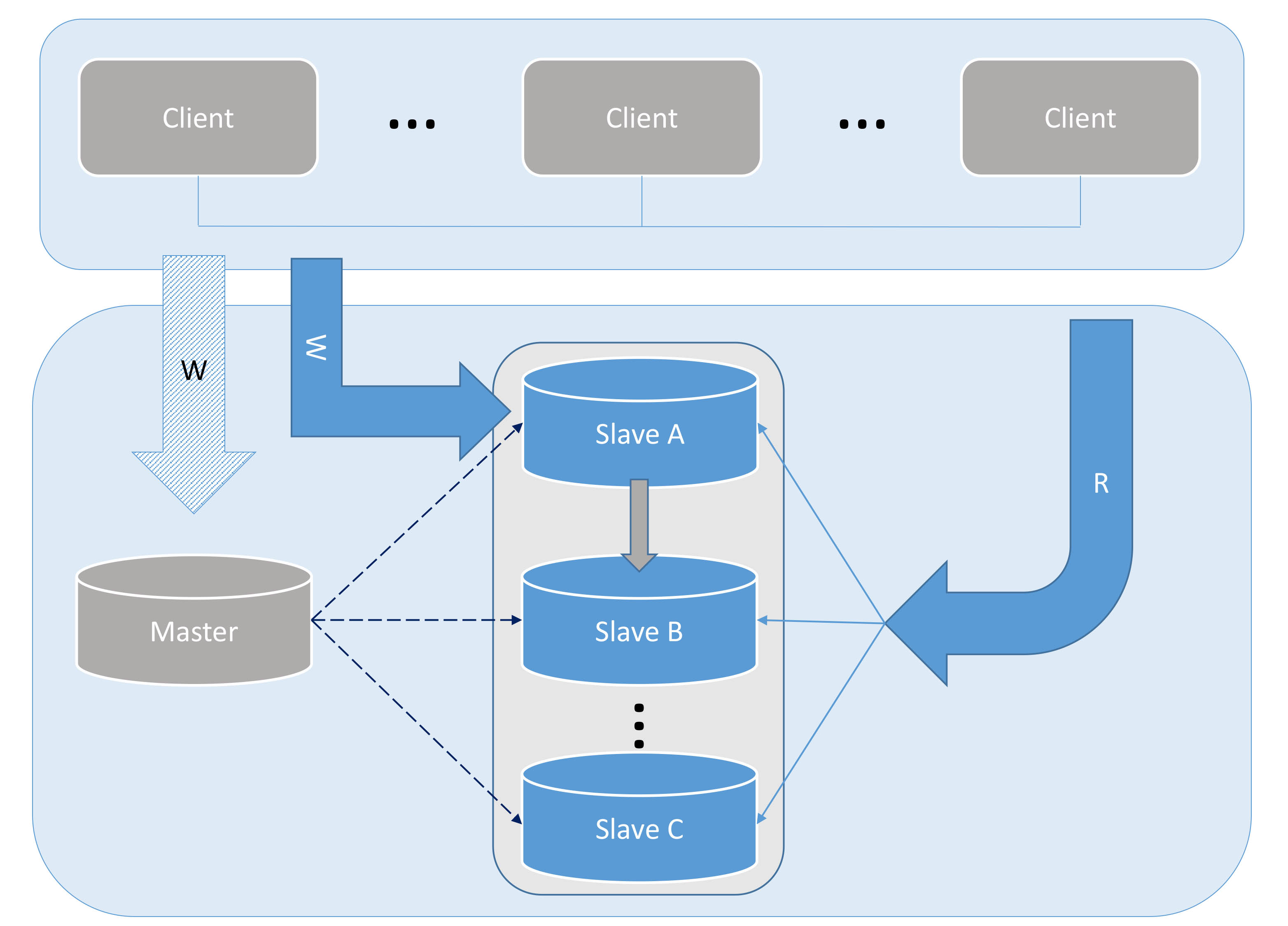
Bild 2
Die Abbildungen 1 bis 2 zeigen den Prozess der Lösung von Einzelpunktproblemen und der Verwendung der Lese- und Schreibtrennung zur Verbesserung der Leistung.
2. Kombination aus DUAL MASTER und Kaskadenreplikation
Dual-Master und mehrere Slaves sind eine sinnvollere Lösung, die aus der oben genannten Lösung abgeleitet ist. Der Vorteil dieser Lösung besteht darin, dass beim Ausfall eines der beiden Hauptserver keine größeren Anpassungen der gesamten Architektur erforderlich sind.
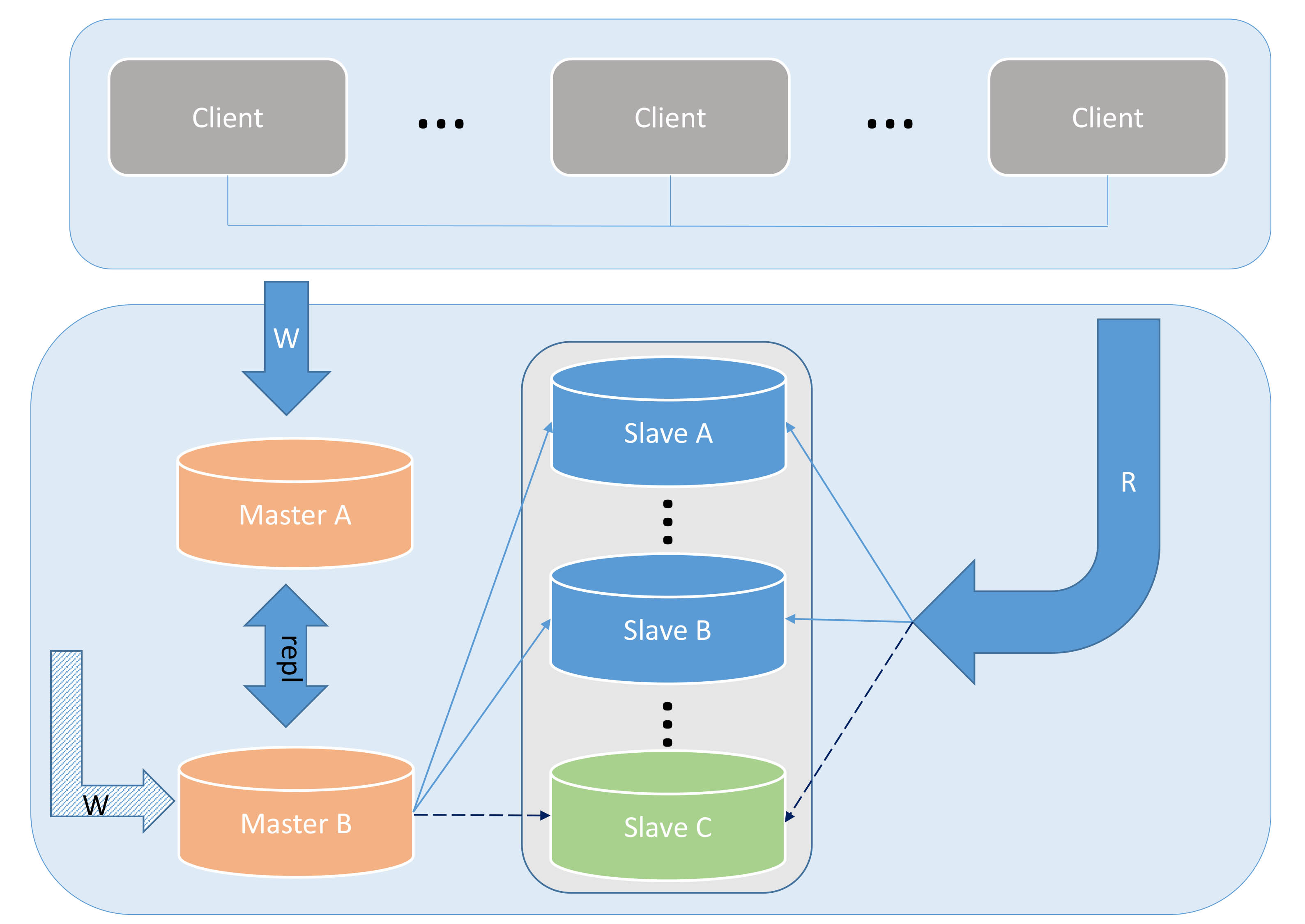
Bild 3
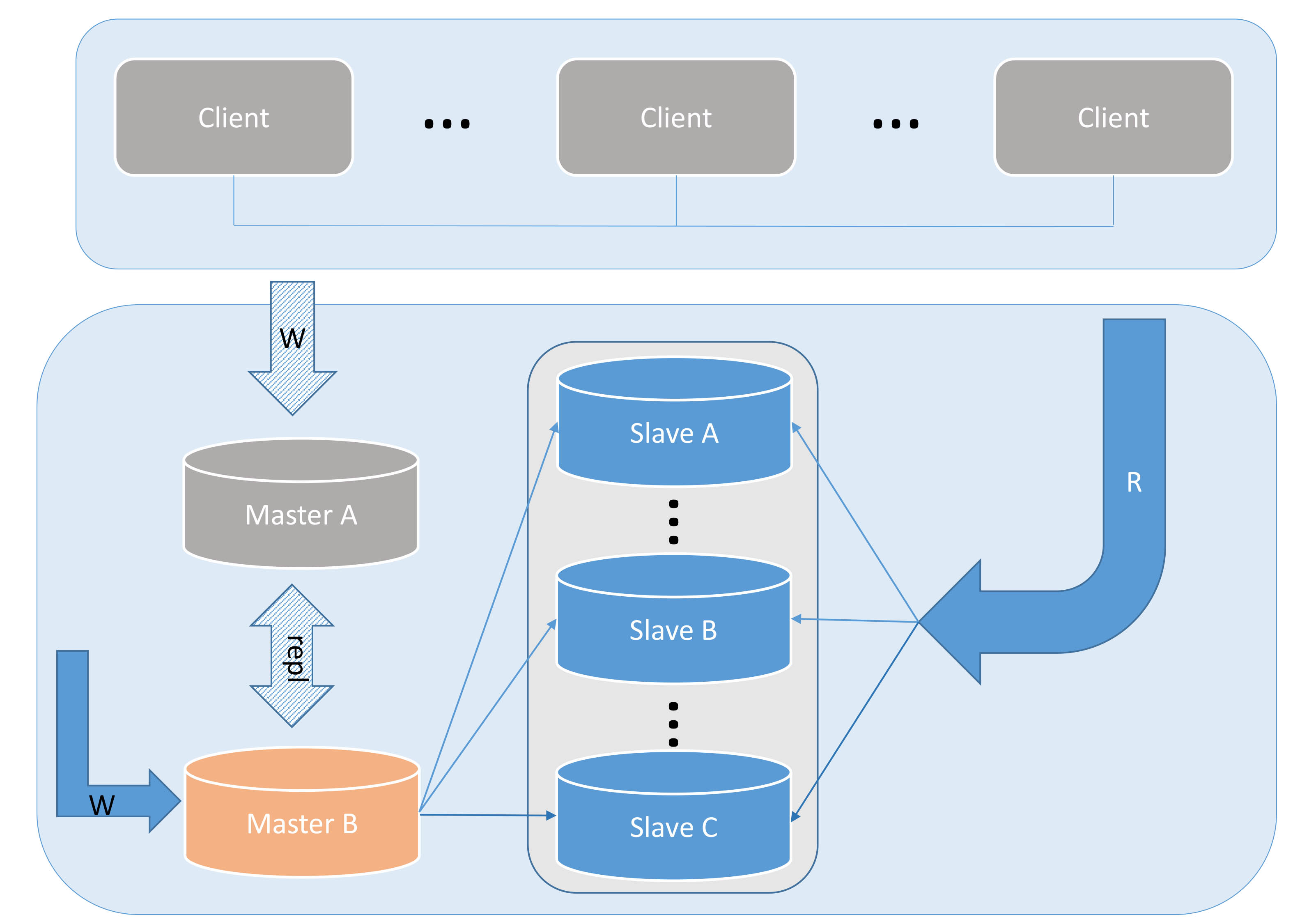
Bild 4
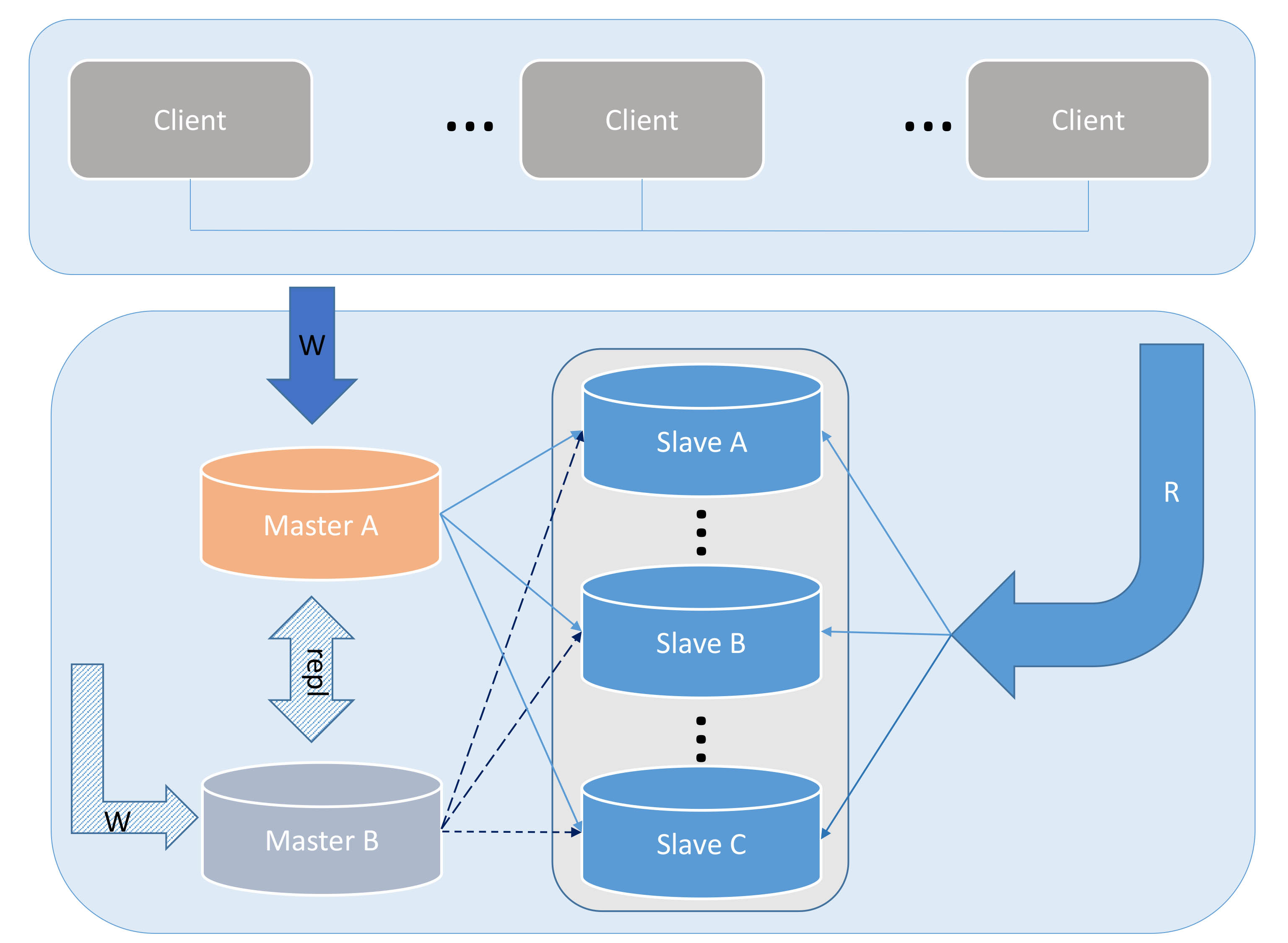
Bild 5
Dieser Vorgang ist im Bild oben dargestellt. Die Situation in Abbildung 5 ist jedoch etwas ganz Besonderes. Was sollen wir tun, wenn MASTER-B ausfällt? Das erste, was festgestellt werden kann, ist, dass alle unsere Schreibanforderungen in keiner Weise beeinträchtigt werden und auf alle Leseanforderungen normal zugegriffen werden kann, aber die gesamte Slave-Replikation unterbrochen wird und die Daten auf dem Slave beginnen, zu verzögern. Was wir zu diesem Zeitpunkt tun müssen, ist, eine CHANGE MASTER TO-Operation für alle Slaves durchzuführen und sie stattdessen von Master A zu kopieren. Da nicht alle Slave-Replikationen vor der ursprünglichen Datenquelle fortschreiten können, kann der genaue Startpunkt der Replikation durch Vergleich der Zeitstempelinformationen im Relay-Protokoll auf dem Slave mit den Zeitstempelinformationen in Master A ermittelt werden, um Datenbeschädigungen oder -verluste zu vermeiden.
2. Verwenden Sie MYSQL CLUSTER, um eine insgesamt hohe Verfügbarkeit zu erreichenDerzeit ist die Lösung, MYSQL-CLUSTER zu verwenden, um eine insgesamt hohe Verfügbarkeit zu erreichen (dh NDB-CLUSTER), bei inländischen Unternehmen nicht sehr beliebt. Der NDB-CLUSTER-Knoten ist eigentlich ein MySQL-Server mit mehreren Knoten, enthält jedoch keine Daten und kann daher auf jedem Computer verwendet werden, sofern er installiert ist. Wenn ein SQL-Knoten im Cluster abstürzt, gehen die Daten nicht verloren, da der Knoten keine bestimmten Daten speichert. Wie in Abbildung 6 dargestellt:
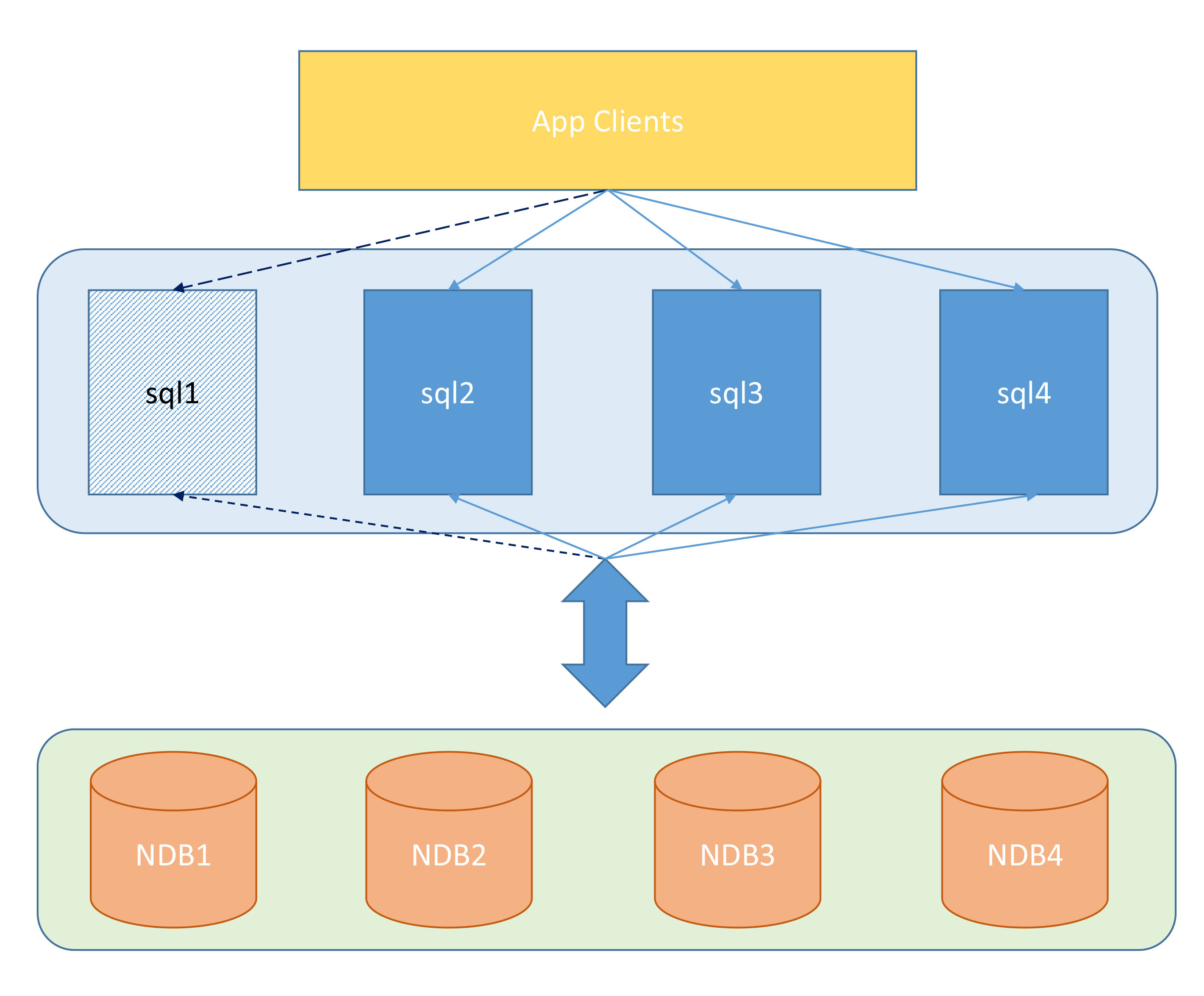
Bild 6
Unter den aktuellen MySQL-Derivaten, die eine hohe Verfügbarkeit erreichen, sind GALERA CLUSTER und PERCONA XTRDB CLUSTER (PXC) die bekanntesten und beliebtesten. Der relevante Inhalt wird in diesem Artikel vorerst nicht beschrieben. Interessierte Studierende können die relevanten Informationen überprüfen, um mehr zu erfahren. Die Implementierungsmethoden dieser beiden Cluster sind ähnlich, wie in Abbildung 7 und Abbildung 8 dargestellt:
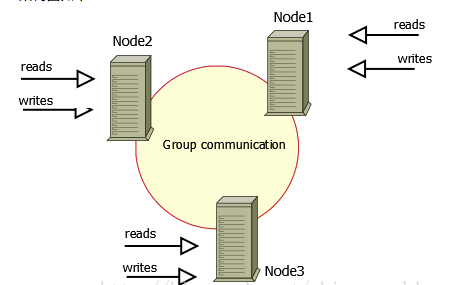
Bild 7
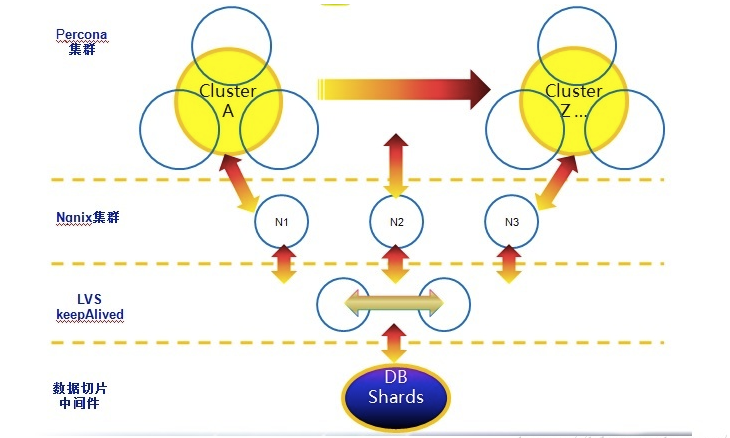
Bild 8
In der vorherigen Einführung zu verschiedenen Hochverfügbarkeits-Designlösungen haben die Leser möglicherweise festgestellt, dass unabhängig von der verwendeten Lösung ihre eigenen einzigartigen Vorteile bestehen, es jedoch auch mehr oder weniger Einschränkungen gibt. In diesem Abschnitt werden die Vor- und Nachteile der oben genannten Hauptoptionen als Referenz für den Auswahlprozess analysiert.
1. MySQL-ReplikationVorteile: Einfache Bereitstellung, einfache Implementierung und unkomplizierte Wartung. Dies ist eine Funktion, die MySQL von Natur aus unterstützt. Und es ist einfach, zwischen der aktiven und der Standby-Maschine zu wechseln. Die Umschaltung zwischen aktiver und Standby-Maschine kann automatisch über Software von Drittanbietern oder selbst geschriebene Skripte erfolgen.
Nachteil: Wenn die Hardware des Master-Hosts ausfällt und nicht wiederhergestellt werden kann, gehen möglicherweise einige Daten verloren, die nicht an den Slave übertragen wurden.
2. MySQL-Cluster (NDB)Vorteile: Sehr hohe Verfügbarkeit und sehr gute Performance. Für jedes Datenelement gibt es mindestens eine Kopie auf verschiedenen Hosts, und redundante Datenkopien werden in Echtzeit synchronisiert.
Nachteile: Die Wartung ist komplizierter, das Produkt ist neuer, es gibt einige Fehler und es ist derzeit möglicherweise nicht für zentrale Online-Systeme geeignet.
3. GALERA CLUSTER und PERCONA XTRDB CLUSTER (PXC)Vorteile: Die Zuverlässigkeit ist sehr hoch. Alle Knoten können alle Daten gleichzeitig lesen und schreiben. Es gibt mindestens eine Kopie auf verschiedenen Hosts und redundante Datenkopien werden in Echtzeit synchronisiert.
Nachteile: Mit zunehmender Clustergröße wird die Leistung immer schlechter.
4. Die DRBD-Festplatten-Netzwerkspiegelungslösung, die erwähnt werden mussArchitektonisch gesehen ähnelt es in gewisser Weise der Replikation, mit der Ausnahme, dass der Datensynchronisierungsprozess über Software von Drittanbietern implementiert wird. Die Zuverlässigkeit ist höher als bei der Replikation, aber es geht auch mit Leistungseinbußen einher.
Vorteile: Die Software ist leistungsstark, Daten werden über physische Hosts auf der zugrunde liegenden Blockgeräteebene gespiegelt und verschiedene Ebenen der Synchronisierung können je nach Leistungs- und Zuverlässigkeitsanforderungen konfiguriert werden. E/A-Operationen sorgen für die Aufrechterhaltung der Ordnung, wodurch die strengen Anforderungen der Datenbank an die Datenkonsistenz erfüllt werden können.
Nachteile: Nicht verteilte Dateisystemumgebungen können die gleichzeitige Sichtbarkeit von Spiegeldaten nicht unterstützen, d. h. Leistung und Zuverlässigkeit widersprechen sich und können nicht auf Umgebungen angewendet werden, in denen strenge Anforderungen an beide gestellt werden. Die Wartungskosten sind höher als bei der MySQL-Replikation.
Nachdem wir über die Vor- und Nachteile verschiedener häufig verwendeter Architekturen gesprochen haben, bleibt die Frage, wie man die geeignete Architektur für den Einsatz in einer realen Produktionsumgebung auswählt. Jeder hat diesbezüglich seine eigenen Vorstellungen und Erfahrungen und welche Lösung die beste ist, ist Ansichtssache. In der täglichen Arbeit gelingt die Verbesserung der Architektur nicht über Nacht, sondern ist ein Prozess der kontinuierlichen Weiterentwicklung, Optimierung und Verbesserung.
Gitui hat auch den Prozess von Single Point zu Master-Slave zu Master-Slave + Hochverfügbarkeit in Bezug auf die Datenbank erlebt. Es hat auch den Prozess von einem einzelnen MySQL+Redis zu MySQL+Redis+es und schließlich zum aktuellen MySQL+ erlebt redis+es +Die Entwicklung von Codis und so weiter. Bei jeder Weiterentwicklung geht es darum, praktische Probleme und Schwachstellen in der Produktionsumgebung zu lösen. Aus Sicht von MySQL allein kann keine Architektur alle Probleme (Schmerzpunkte) lösen, und eine geeignete Architektur muss basierend auf der tatsächlichen Situation ausgewählt werden. Die vom MySQL-Cluster implementierte Lösung ist auch eine Herausforderung für MySQL-Mitarbeiter. Dies ist auch die Motivation für uns, MySQL weiter zu studieren und zu lernen.
Das obige ist der detaillierte Inhalt vonEine kurze Analyse der MySQL-Architektur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was bedeutet cp im Linux-System?
- Welche Methoden gibt es, um den Firewall-Status unter Linux zu überprüfen?
- Was sind die Linux-Dekomprimierungsbefehle?
- Wie filtere und klassifiziere ich Protokolle mit Linux-Befehlszeilentools?
- Erfahren Sie, wie Sie Schriftarten von Drittanbietern unter Red Hat Linux installieren