
Heim >Technologie-Peripheriegeräte >KI >Netizens loben: Transformer führt die vereinfachte Version des Jahrespapiers hier an
Netizens loben: Transformer führt die vereinfachte Version des Jahrespapiers hier an

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-14 13:51:171178Durchsuche
Optimieren Sie ausgehend von den Wurzeln großer Modelle. Man kann sagen, dass die
Transformer-Architektur die treibende Kraft hinter vielen aktuellen Erfolgsgeschichten im Bereich Deep Learning ist. Eine einfache Möglichkeit, eine tiefe Transformer-Architektur aufzubauen, besteht darin, mehrere identische Transformer-„Blöcke“ nacheinander zu stapeln. Allerdings ist jeder „Block“ komplexer und besteht aus vielen verschiedenen Komponenten, die eine bestimmte Anordnung und Kombination erfordern, um eine gute Leistung zu erzielen.
Seit der Geburt der Transformer-Architektur im Jahr 2017 haben Forscher eine große Anzahl darauf basierender abgeleiteter Studien gestartet, es wurden jedoch fast keine Änderungen am Transformer-„Block“ vorgenommen.
Die Frage ist also: Kann der Standard-Transformer-Block vereinfacht werden?
In einem aktuellen Artikel diskutieren Forscher der ETH Zürich, wie der für LLM erforderliche Standard-Transformerblock vereinfacht werden kann, ohne die Konvergenzeigenschaften und die Leistung nachgelagerter Aufgaben zu beeinträchtigen. Basierend auf der Signalausbreitungstheorie und empirischen Beweisen fanden sie heraus, dass einige Teile wie Restverbindungen, Normalisierungsschichten (LayerNorm), Projektions- und Wertparameter sowie „MLP-Serialisierungsunterblöcke“ (bevorzugt paralleles Layout) entfernt werden können, um GPT zu vereinfachen. wie Decoder-Architektur und BERT-Modell im Encoder-Stil. Die Forscher untersuchten, ob die beteiligten Komponenten entfernt werden können, ohne die Trainingsgeschwindigkeit zu beeinträchtigen, und welche architektonischen Änderungen am Transformer-Block vorgenommen werden sollten.
 Link zum Papier: https://arxiv.org/pdf/2311.01906.pdf
Link zum Papier: https://arxiv.org/pdf/2311.01906.pdfDer Gründer und Forscher für maschinelles Lernen, Sebastian Raschka, nennt diese Forschung seine „Lieblingsarbeit des Jahres“ One “:
 Aber einige Forscher fragten: „
Aber einige Forscher fragten: „
sein?“
stimmte zu: „Ja, die Architektur, mit der sie experimentiert haben, ist relativ klein. Ob sich dies auf einen Transformer mit Milliarden von Parametern übertragen lässt, bleibt abzuwarten. Aber er sagte trotzdem, die Arbeit sei beeindruckend und glaubte daran Das erfolgreiche Entfernen verbleibender Verbindungen war völlig vernünftig (angesichts des Initialisierungsschemas). In diesem Zusammenhang kommentierte Turing-Preisträger Yann LeCun: „
Wir haben nur die Oberfläche des Bereichs der Deep-Learning-Architektur berührt. Dies ist ein hochdimensionaler Raum, daher ist das Volumen fast vollständig in der Oberfläche enthalten, aber wir.“ habe nur die Oberfläche berührt. Ein kleiner Teil von‖

Die Forscher sagten, dass die Vereinfachung des Transformer-Blocks ohne Beeinträchtigung der Trainingsgeschwindigkeit ein interessantes Forschungsproblem sei.
Erstens sind moderne neuronale Netzwerkarchitekturen komplex im Design und enthalten viele Komponenten, und die Rolle, die diese verschiedenen Komponenten in der Dynamik des neuronalen Netzwerktrainings spielen und wie sie miteinander interagieren, ist nicht gut verstanden. Diese Frage bezieht sich auf die Kluft zwischen Deep-Learning-Theorie und -Praxis und ist daher sehr wichtig.
Die Signalausbreitungstheorie hat sich als einflussreich erwiesen, da sie praktische Designentscheidungen in tiefen neuronalen Netzwerkarchitekturen motiviert. Die Signalausbreitung untersucht die Entwicklung geometrischer Informationen in neuronalen Netzen bei der Initialisierung, erfasst durch das innere Produkt hierarchischer Darstellungen über Eingaben hinweg, und hat zu vielen beeindruckenden Ergebnissen beim Training tiefer neuronaler Netze geführt.
Allerdings berücksichtigt diese Theorie derzeit nur das Modell während der Initialisierung und oft nur den anfänglichen Vorwärtsdurchlauf, sodass sie viele komplexe Probleme in der Trainingsdynamik tiefer neuronaler Netze, wie etwa den Beitrag von Restverbindungen zur Trainingsgeschwindigkeit, nicht aufdecken kann. Während die Signalausbreitung für die Modifikationsmotivation von entscheidender Bedeutung ist, sagten die Forscher, dass sie aus der Theorie allein kein vereinfachtes Transformer-Modul ableiten könnten und sich auf empirische Erkenntnisse verlassen müssten.
Im Hinblick auf praktische Anwendungen stellen Effizienzverbesserungen in den Trainings- und Inferenzpipelines der Transformer-Architektur angesichts der derzeit hohen Kosten für Training und Bereitstellung großer Transformer-Modelle ein enormes Einsparpotenzial dar. Wenn das Transformer-Modul durch Entfernen unnötiger Komponenten vereinfacht werden kann, kann dies sowohl die Anzahl der Parameter reduzieren als auch den Durchsatz des Modells verbessern.
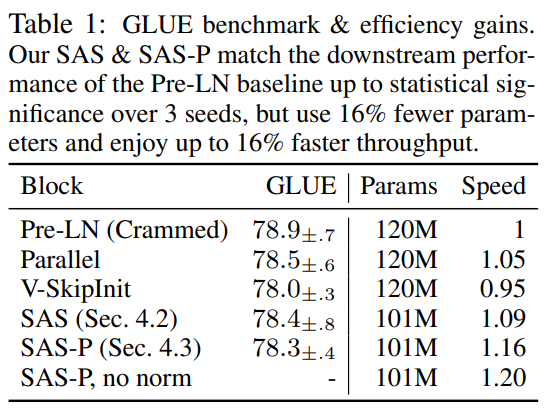
In diesem Artikel wurde auch erwähnt, dass es nach dem Entfernen der Restverbindung, der Wertparameter, der Projektionsparameter und der Serialisierungsunterblöcke hinsichtlich der Trainingsgeschwindigkeit und der Leistung nachgelagerter Aufgaben mit dem Standard-Transformer mithalten kann. Letztendlich reduzierten die Forscher die Anzahl der Parameter um 16 % und beobachteten eine Steigerung des Durchsatzes bei Trainings- und Inferenzzeiten um 16 %.
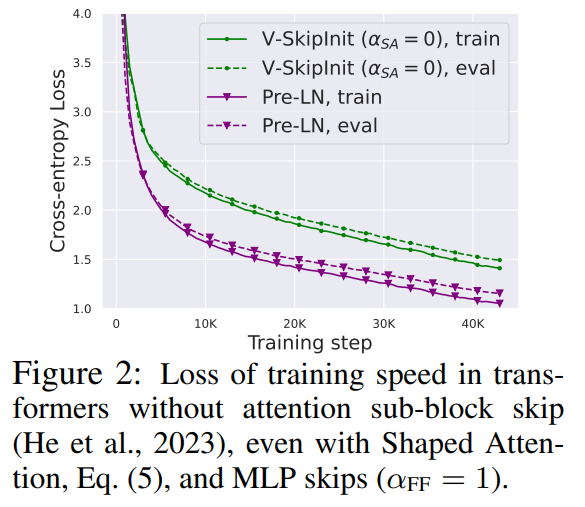
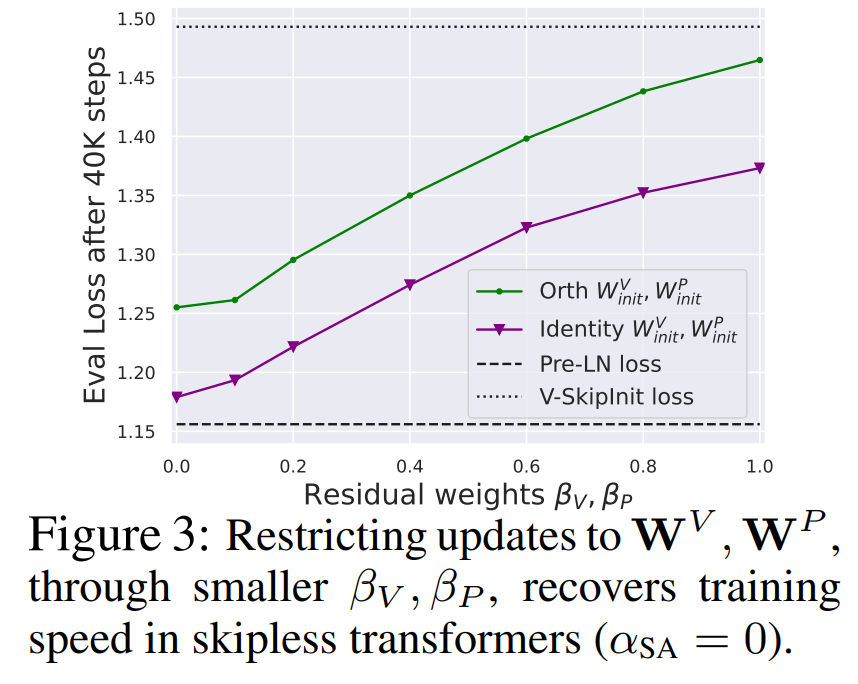
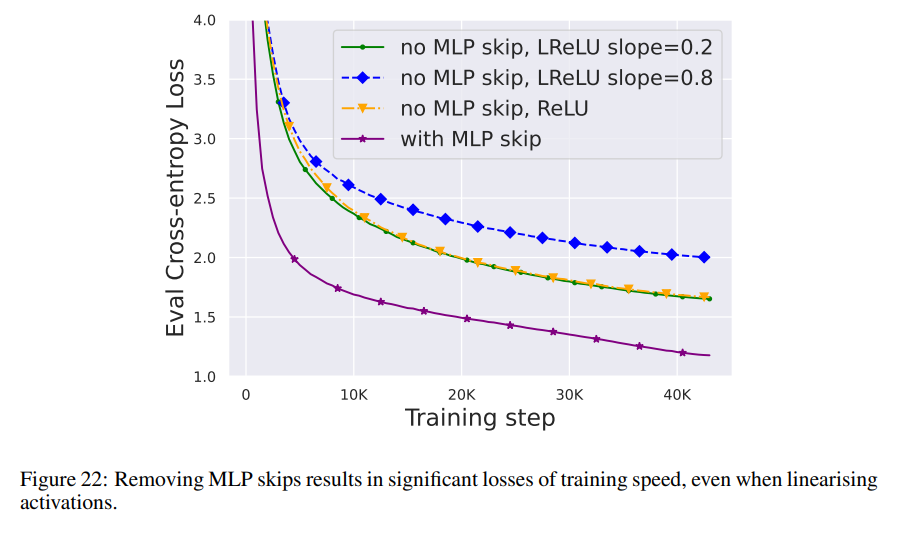
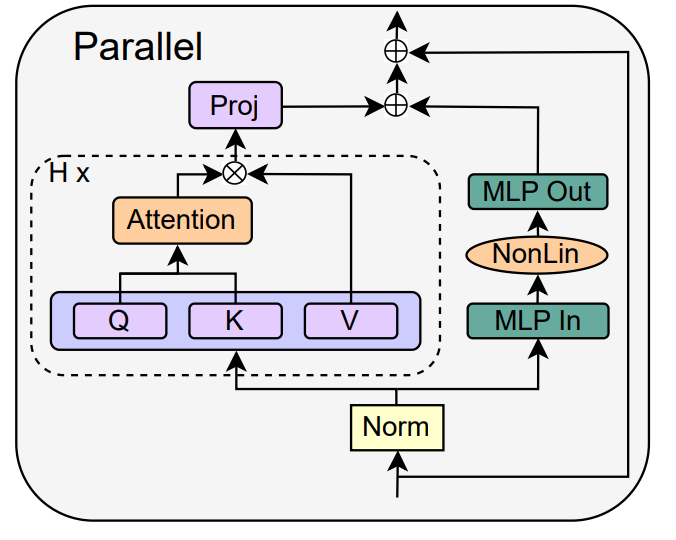
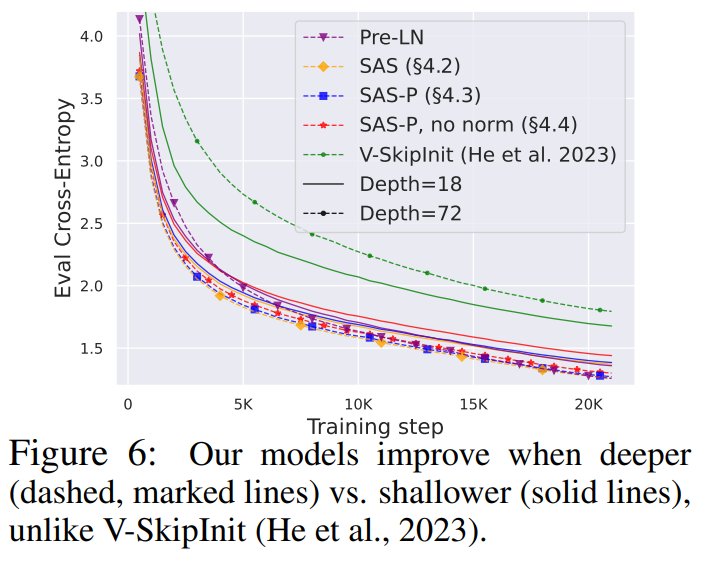
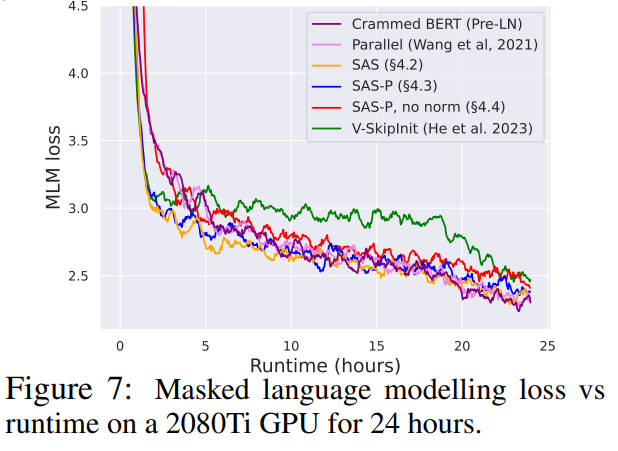
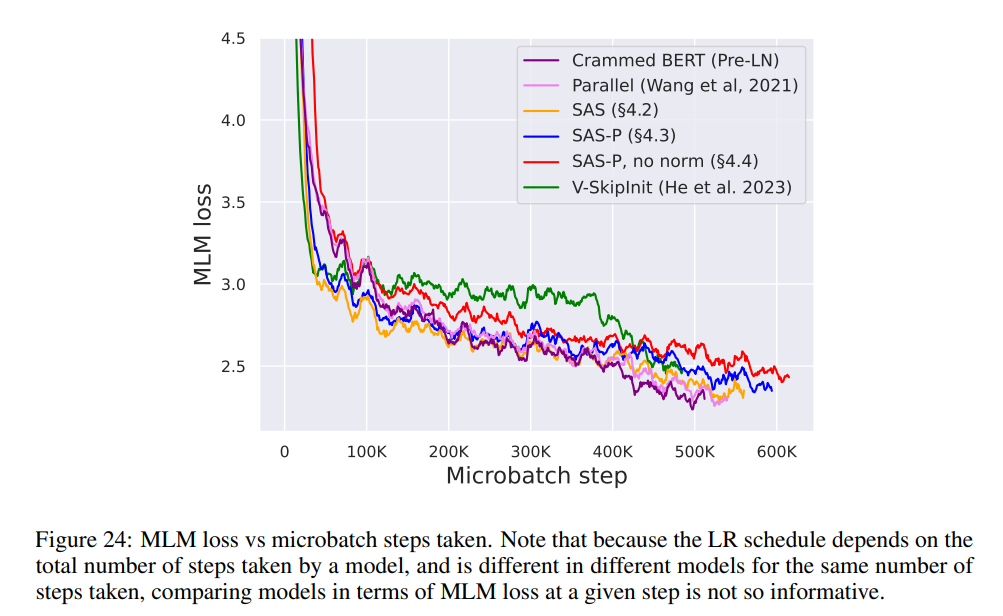
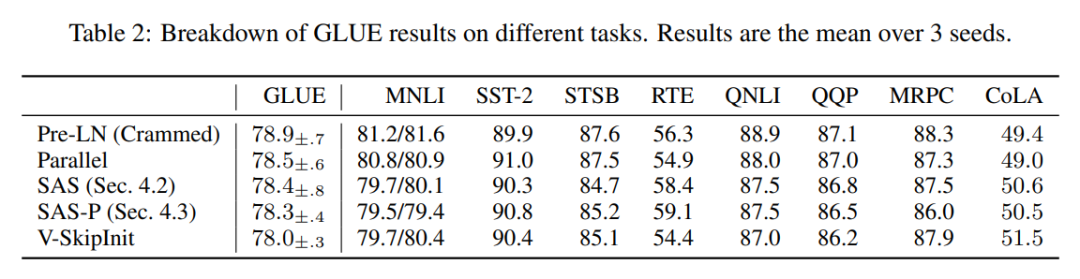
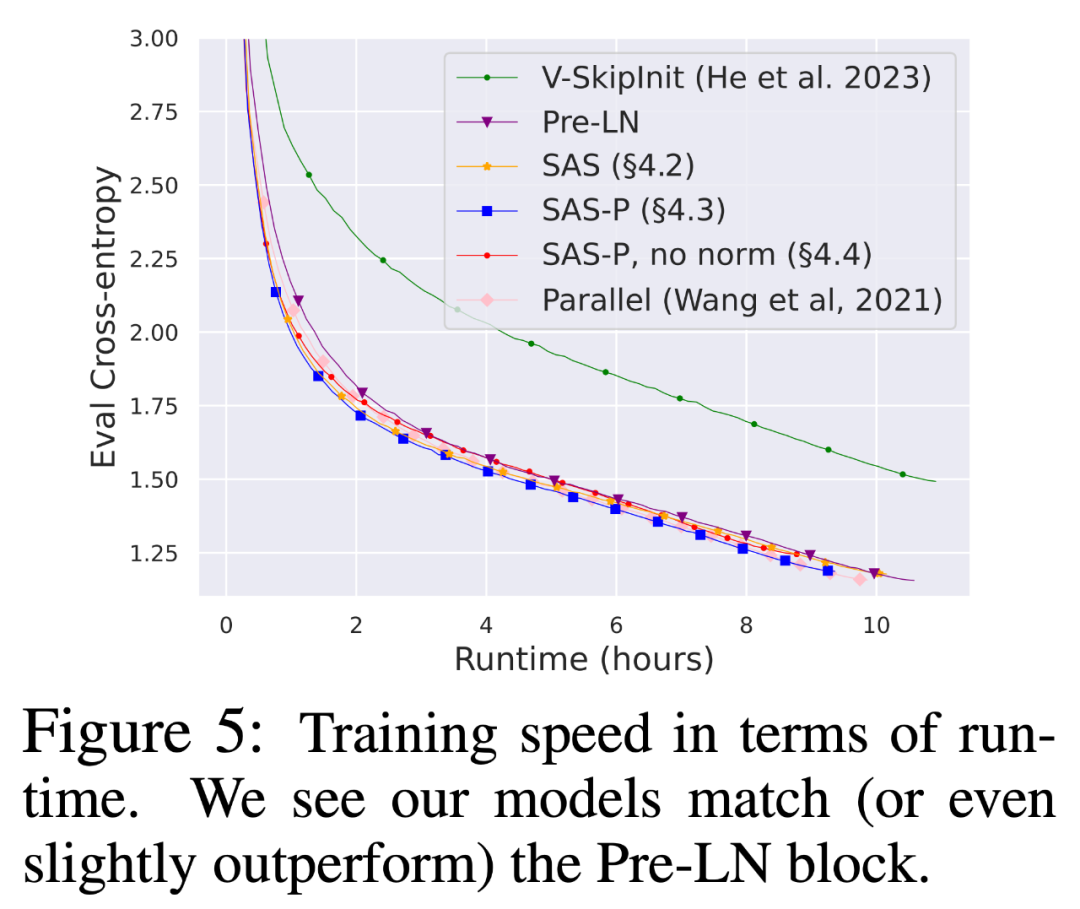
Wie vereinfacht man den Transformer-Block?Basierend auf der Signalausbreitungstheorie und empirischen Beobachtungen stellte der Forscher vor, wie man ausgehend vom Pre-LN-Modul den einfachsten Transformatorblock generiert (wie unten gezeigt). In jedem Abschnitt von Kapitel 4 des Papiers stellt der Autor vor, wie man jeweils eine Blockkomponente löscht, ohne die Trainingsgeschwindigkeit zu beeinträchtigen. Alle Experimente in diesem Teil verwenden ein 18-Block-768-Breite-Kausal-Decoder-only-GPT-Modell auf dem CodeParrot-Datensatz. Dieser Datensatz ist groß genug, sodass die Generalisierungslücke besteht, wenn sich der Autor im Einzeltrainingsepochenmodus befindet sehr klein (siehe Abbildung 2), sodass sie sich auf die Trainingsgeschwindigkeit konzentrieren können. Restverbindungen löschen Die Forscher erwogen zunächst, die Restverbindungen im Aufmerksamkeitsunterblock zu löschen. In der Notation von Gleichung (1) entspricht dies der Festlegung von α_SA auf 0. Das bloße Entfernen verbleibender Aufmerksamkeitsverbindungen kann zu einer Signalverschlechterung, d. h. einem Rangzusammenbruch, führen, was zu einer schlechten Trainierbarkeit führt. In Abschnitt 4.1 der Arbeit erläutern die Forscher ihre Methode ausführlich. Projektions-/Wertparameter entfernen Aus Abbildung 3 kann geschlossen werden, dass eine vollständige Entfernung der Wert- und Projektionsparameter W^V, W^P mit minimalem Verlust der Trainingsgeschwindigkeit pro Aktualisierung möglich ist. Das heißt, wenn β_V = β_P = 0 und die Identität initialisiert wird , kann diese Studie nach der gleichen Anzahl von Trainingsschritten grundsätzlich die Leistung des Pre-LN-Blocks erreichen. In diesem Fall gilt für W^V = W^P = I während des gesamten Trainingsprozesses W^V = W^P = I, d. h. die Werte und Projektionsparameter sind konsistent. Detaillierte Methoden stellen die Autoren in Abschnitt 4.2 vor. Löschen von MLP-Unterblock-Restverbindungen Im Vergleich zu den oben genannten Modulen ist das Löschen von MLP-Unterblock-Restverbindungen eine größere Herausforderung. Wie in früheren Untersuchungen stellten die Autoren fest, dass bei der Verwendung von Adam ohne MLP-Restverbindungen eine linearere Aktivierung von Aktivierungen durch Signalausbreitung immer noch zu einer erheblichen Verringerung der Trainingsgeschwindigkeit pro Aktualisierung führte, wie in Abbildung 22 dargestellt. Sie haben auch verschiedene Variationen der Looks Linear-Initialisierung ausprobiert, darunter Gaußsche Gewichte, orthogonale Gewichte oder Identitätsgewichte, aber ohne Erfolg. Daher verwenden sie während ihrer gesamten Arbeit und Initialisierung in MLP-Unterblöcken Standardaktivierungen (z. B. ReLU). Die Autoren wenden sich dem Konzept paralleler MHA- und MLP-Unterblöcke zu, das sich in mehreren neueren großen Transformatormodellen wie PALM und ViT-22B als beliebt erwiesen hat. Der Paralleltransformatorblock ist in der folgenden Abbildung dargestellt. Der Autor beschreibt den spezifischen Vorgang zum Entfernen von MLP-Unterblock-Restverbindungen in Abschnitt 4.3 des Papiers. Löschen Sie die Normalisierungsebene Als letztes wird die Normalisierungsebene gelöscht, sodass Sie den einfachsten Block in der oberen rechten Ecke von Abbildung 1 erhalten. Aus Sicht der Signalausbreitungsinitialisierung können die Autoren die Normalisierungsschicht in jeder Phase der Vereinfachung in diesem Abschnitt entfernen. Ihre Idee ist, dass die Normalisierung im Pre-LN-Block implizit das Gewicht der Restzweige reduziert und dieser vorteilhafte Effekt ohne die Normalisierungsschicht durch einen anderen Mechanismus repliziert werden kann: Entweder bei Verwendung von Restverbindungen das Gewicht des Restzweigs explizit reduzieren , oder die Aufmerksamkeitsmatrix in Richtung Identität lenken/MLP-Nichtlinearität in „mehr“ Linearität umwandeln. Da der Autor diese Mechanismen während des Änderungsprozesses berücksichtigt hat (z. B. die Reduzierung des Gewichts von MLP β_FF und Shaped Attention), besteht keine Notwendigkeit für eine Normalisierung. Weitere Informationen stellen die Autoren in Abschnitt 4.4 vor. Experimentelle Ergebnisse Tiefenerweiterung Da sich die Signalausbreitungstheorie normalerweise auf große Tiefen konzentriert, kommt es in diesem Fall normalerweise zu einer Signalverschlechterung. Eine natürliche Frage ist also: Lässt sich die verbesserte Trainingsgeschwindigkeit, die durch unseren vereinfachten Transformatorblock erreicht wird, auch auf größere Tiefen übertragen? Aus Abbildung 6 ist ersichtlich, dass nach der Erweiterung der Tiefe von 18 Blöcken auf 72 Blöcke die Leistung sowohl des Modells als auch des Pre-LN-Transformators in dieser Studie verbessert wird, was zeigt, dass das vereinfachte Modell in dieser Studie nicht nur verbessert wird schneller im Training Schneller und in der Lage, die zusätzlichen Fähigkeiten zu nutzen, die eine größere Tiefe bietet. Tatsächlich sind die Trajektorien pro Aktualisierung des vereinfachten Blocks und des Pre-LN in dieser Studie bei Verwendung der Normalisierung in unterschiedlichen Tiefen nahezu nicht zu unterscheiden. BERT Als nächstes zeigen die Autoren, dass ihre vereinfachte Blockleistung neben autoregressiven Decodern auch für verschiedene Datensätze und Architekturen sowie nachgelagerte Aufgaben gilt. Sie wählten die beliebte Einstellung des bidirektionalen Encoder-only-BERT-Modells für die maskierte Sprachmodellierung und verwendeten den nachgeschalteten GLUE-Benchmark. Wie in Abbildung 7 dargestellt, sind die vereinfachten Blöcke dieser Studie innerhalb von 24 Stunden Laufzeit mit der Geschwindigkeit vor dem Training der maskierten Sprachmodellierungsaufgabe im Vergleich zur (überfüllten) Pre-LN-Basislinie vergleichbar. Andererseits führt das Entfernen restlicher Verbindungen ohne erneute Änderung von Werten und Prognosen zu einer deutlichen Verringerung der Trainingsgeschwindigkeit. In Abbildung 24 stellen die Autoren ein entsprechendes Diagramm des Mikrobatch-Schritts bereit. Darüber hinaus stellten die Forscher in Tabelle 1 fest, dass ihre Methode nach der Feinabstimmung am GLUE-Benchmark eine vergleichbare Leistung wie der Crammed BERT-Benchmark erbrachte. Sie schlüsseln die nachgelagerten Aufgaben in Tabelle 2 auf. Für einen fairen Vergleich verwendeten sie dasselbe Feinabstimmungsprotokoll wie Geiping & Goldstein (2023) (5 Epochen, konstante Hyperparameter für jede Aufgabe, Dropout-Regularisierung). Verbesserte Effizienz In Tabelle 1 haben die Forscher auch die Anzahl der Parameter und die Trainingsgeschwindigkeit von Modellen detailliert beschrieben, die verschiedene Transformer-Blöcke in der maskierten Sprachmodellierungsaufgabe verwenden. Sie berechneten die Geschwindigkeit als das Verhältnis der Anzahl der Mikrobatch-Schritte, die während 24 Stunden des Vortrainings durchgeführt wurden, zum Basiswert des Pre-LN Crammed BERT. Die Schlussfolgerung ist, dass das Modell 16 % weniger Parameter verwendet und SAS-P und SAS pro Iteration 16 % bzw. 9 % schneller sind als der Pre-LN-Block. Es ist zu beachten, dass bei der Implementierung hier der Parallelblock nur 5 % schneller ist als der Pre-LN-Block, während die von Chowdhery et al. (2022) beobachtete Trainingsgeschwindigkeit 15 % schneller ist, was zeigt, dass mit a optimiertere Umsetzung, Es ist möglich, dass die gesamte Trainingsgeschwindigkeit weiter erhöht werden kann. Wie Geiping & Goldstein (2023) nutzt auch diese Implementierung die automatische Operator-Fusion-Technologie in PyTorch (Sarofeen et al., 2022). Längeres Training Angesichts des aktuellen Trends, kleinere Modelle auf mehr Daten über längere Zeiträume zu trainieren, diskutierten die Forscher schließlich, ob vereinfachte Blöcke nach langer Trainingsgeschwindigkeit immer noch das Training von Pre-LN-Blöcken erreichen können. Dazu verwenden sie das Modell in Abbildung 5 auf CodeParrot und trainieren mit 3x-Tokens. Um genau zu sein, erfordert das Training etwa 120.000 Schritte (anstelle von 40.000 Schritten) bei einer Stapelgröße von 128 und einer Sequenzlänge von 128, was zu etwa 2B Token führt. Wie aus Abbildung 8 ersichtlich ist, ist die Trainingsgeschwindigkeit der vereinfachten SAS- und SAS-P-Codeblöcke immer noch mit der der PreLN-Codeblöcke vergleichbar oder sogar besser, wenn mehr Token für das Training verwendet werden. Weitere Forschungsdetails finden Sie im Originalpapier. 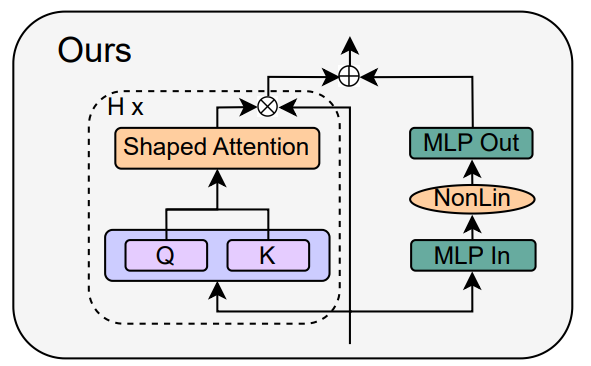
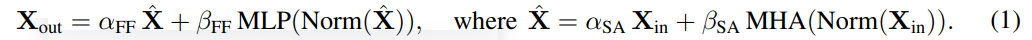
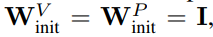
Das obige ist der detaillierte Inhalt vonNetizens loben: Transformer führt die vereinfachte Version des Jahrespapiers hier an. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!