
Heim >Technologie-Peripheriegeräte >KI >Kleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit
Kleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-14 12:27:151552Durchsuche
Derzeit beginnen Forscher, sich auf kompakte und leistungsstarke kleine Modelle zu konzentrieren, obwohl alle große Modelle mit Parameterskalen im zweistelligen oder sogar hunderten Milliardenbereich untersuchen.
Kleine Modelle werden häufig in Edge-Geräten wie Smartphones, IoT-Geräten und eingebetteten Systemen verwendet. Diese Geräte verfügen oft nur über begrenzte Rechenleistung und Speicherplatz und können große Sprachmodelle nicht effizient ausführen. Daher kommt der Untersuchung kleiner Modelle eine besondere Bedeutung zu.
Die beiden Studien, die wir als nächstes vorstellen, könnten Ihren Bedarf an kleinen Modellen decken.
TinyLlama-1.1B
Forscher der Singapore University of Technology and Design (SUTD) haben kürzlich TinyLlama veröffentlicht, ein Sprachmodell mit 1,1 Milliarden Parametern, das auf etwa 3 Billionen Zug-Tokens vorab trainiert wurde.

- Papieradresse: https://arxiv.org/pdf/2401.02385.pdf
- Projektadresse: https://github.com/jzhang38/TinyLlama/blob/main/ README_zh-CN.md
TinyLlama basiert auf der Llama 2-Architektur und dem Tokenizer, was die Integration in viele Open-Source-Projekte mit Llama erleichtert. Darüber hinaus verfügt TinyLlama nur über 1,1 Milliarden Parameter und ist klein, was es ideal für Anwendungen macht, die einen begrenzten Rechen- und Speicherbedarf erfordern.
Die Studie zeigt, dass nur 16 A100-40G-GPUs das Training von TinyLlama in 90 Tagen abschließen können.

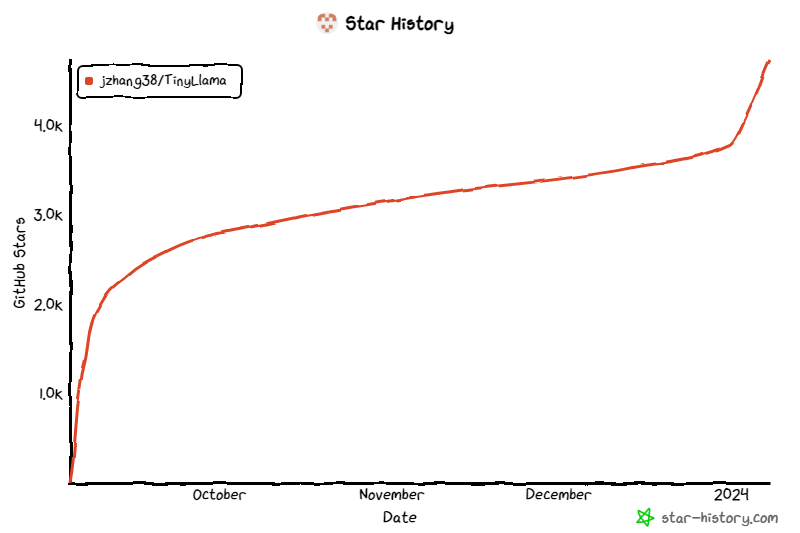
Das Projekt hat seit seiner Einführung weiterhin Aufmerksamkeit erhalten und die aktuelle Anzahl der Sterne hat 4,7.000 erreicht. Die Details zur TinyLlama-Modellarchitektur lauten wie folgt: die Verwendung größerer Daten Potenzial für das Training kleinerer Modelle. Sie konzentrierten sich auf die Untersuchung des Verhaltens kleinerer Modelle, wenn sie mit einer viel größeren Anzahl von Token trainiert wurden, als vom Skalierungsgesetz empfohlen.
 Konkret wurden in der Studie etwa 3 Billionen Token verwendet, um ein Transformer-Modell (nur Decoder) mit 1,1B-Parametern zu trainieren. Unseres Wissens ist dies der erste Versuch, eine so große Datenmenge zu verwenden, um ein Modell mit 1B Parametern zu trainieren.
Konkret wurden in der Studie etwa 3 Billionen Token verwendet, um ein Transformer-Modell (nur Decoder) mit 1,1B-Parametern zu trainieren. Unseres Wissens ist dies der erste Versuch, eine so große Datenmenge zu verwenden, um ein Modell mit 1B Parametern zu trainieren.
Trotz seiner relativ geringen Größe schneidet TinyLlama bei einer Reihe nachgelagerter Aufgaben recht gut ab und übertrifft bestehende Open-Source-Sprachmodelle derselben Größe deutlich. Insbesondere übertrifft TinyLlama OPT-1.3B und Pythia1.4B bei verschiedenen nachgelagerten Aufgaben.

Mit der Unterstützung dieser Technologien erreicht der TinyLlama-Trainingsdurchsatz 24.000 Token pro Sekunde pro A100-40G-GPU. Beispielsweise benötigt das TinyLlama-1.1B-Modell nur 3.456 A100-GPU-Stunden für 300B-Tokens, verglichen mit 4.830 Stunden für Pythia und 7.920 Stunden für MPT. Dies zeigt die Wirksamkeit der Optimierung dieser Studie und das Potenzial, beim groß angelegten Modelltraining erhebliche Zeit- und Ressourceneinsparungen zu erzielen.
 TinyLlama erreicht eine Trainingsgeschwindigkeit von 24.000 Token/Sekunde/A100. Diese Geschwindigkeit entspricht einem Chinchilla-optimalen Modell mit 1,1 Milliarden Parametern und 22 Milliarden Token, die Benutzer in 32 Stunden auf 8 A100 trainieren können. Gleichzeitig reduzieren diese Optimierungen auch die Speichernutzung erheblich. Benutzer können ein 1,1-Milliarden-Parameter-Modell in eine 40-GB-GPU packen und dabei eine Stapelgröße von 16.000 Tokens pro GPU beibehalten. Ändern Sie einfach die Batch-Größe etwas kleiner, und Sie können TinyLlama auf RTX 3090/4090 trainieren.
TinyLlama erreicht eine Trainingsgeschwindigkeit von 24.000 Token/Sekunde/A100. Diese Geschwindigkeit entspricht einem Chinchilla-optimalen Modell mit 1,1 Milliarden Parametern und 22 Milliarden Token, die Benutzer in 32 Stunden auf 8 A100 trainieren können. Gleichzeitig reduzieren diese Optimierungen auch die Speichernutzung erheblich. Benutzer können ein 1,1-Milliarden-Parameter-Modell in eine 40-GB-GPU packen und dabei eine Stapelgröße von 16.000 Tokens pro GPU beibehalten. Ändern Sie einfach die Batch-Größe etwas kleiner, und Sie können TinyLlama auf RTX 3090/4090 trainieren.
In dem Experiment konzentrierte sich diese Forschung hauptsächlich auf Sprachmodelle mit reiner Decoder-Architektur, die etwa 1 Milliarde Parameter enthielten. Konkret verglich die Studie TinyLlama mit OPT-1.3B, Pythia-1.0B und Pythia-1.4B.
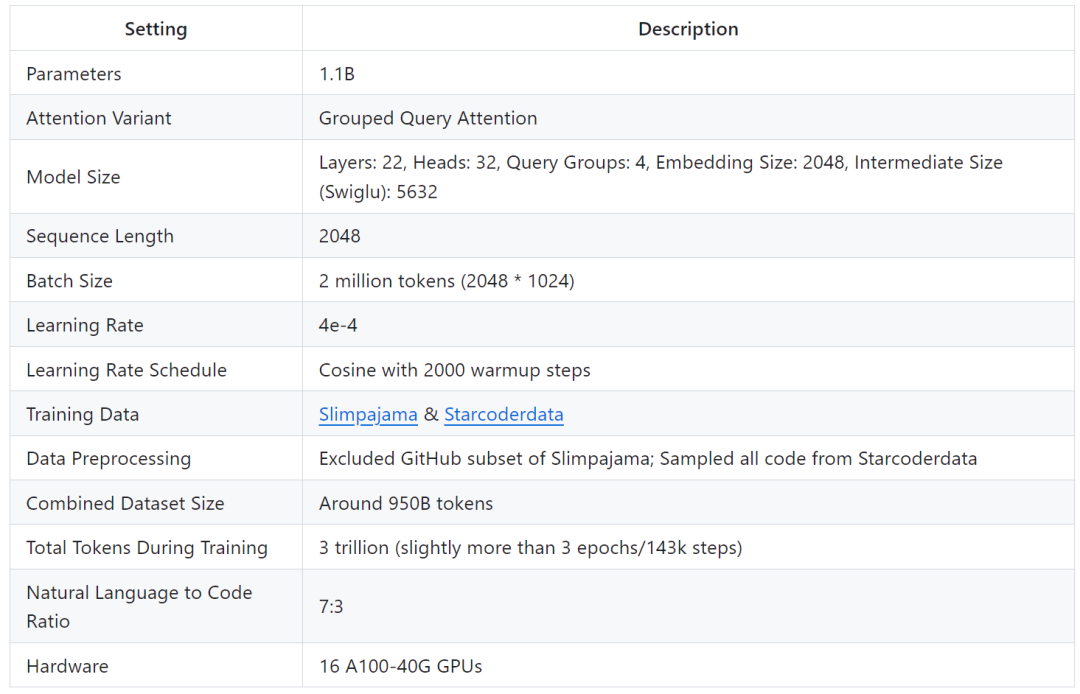
Die Leistung von TinyLlama bei Aufgaben zum gesunden Menschenverstand ist unten dargestellt. Es ist ersichtlich, dass TinyLlama bei vielen Aufgaben besser abschneidet und die höchste Durchschnittspunktzahl erzielt.

Darüber hinaus verfolgten die Forscher die Genauigkeit von TinyLlama anhand von Benchmarks zum gesunden Menschenverstand während des Vortrainings. Wie in Abbildung 2 gezeigt, verbessert sich die Leistung von TinyLlama mit der Erhöhung der Rechenressourcen und übertrifft in den meisten Benchmarks die Genauigkeit von Pythia-1.4B.
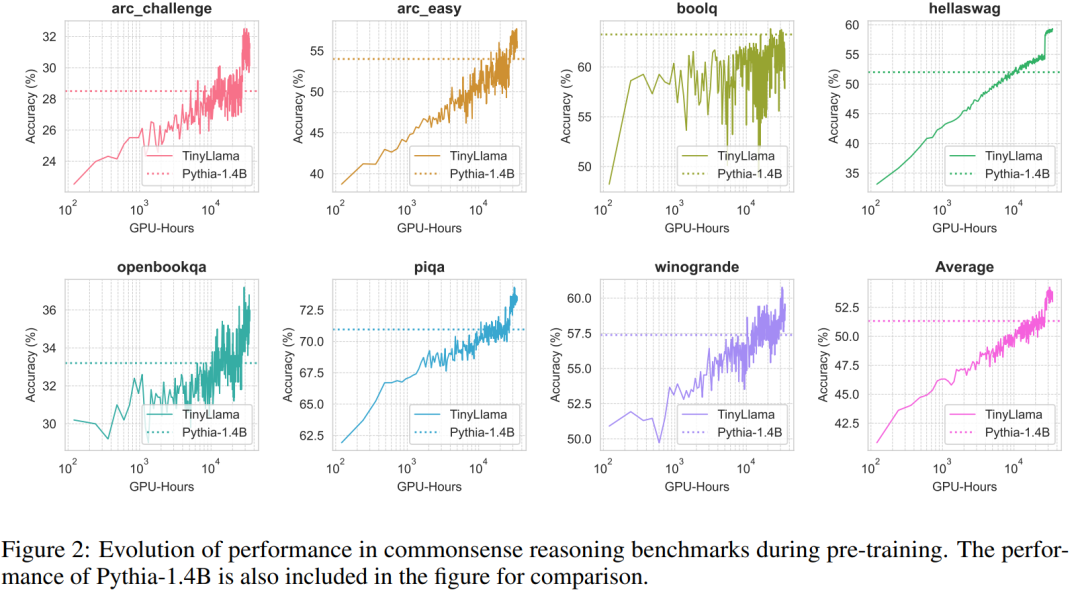
Tabelle 3 zeigt, dass TinyLlama im Vergleich zu bestehenden Modellen bessere Problemlösungsfähigkeiten aufweist.
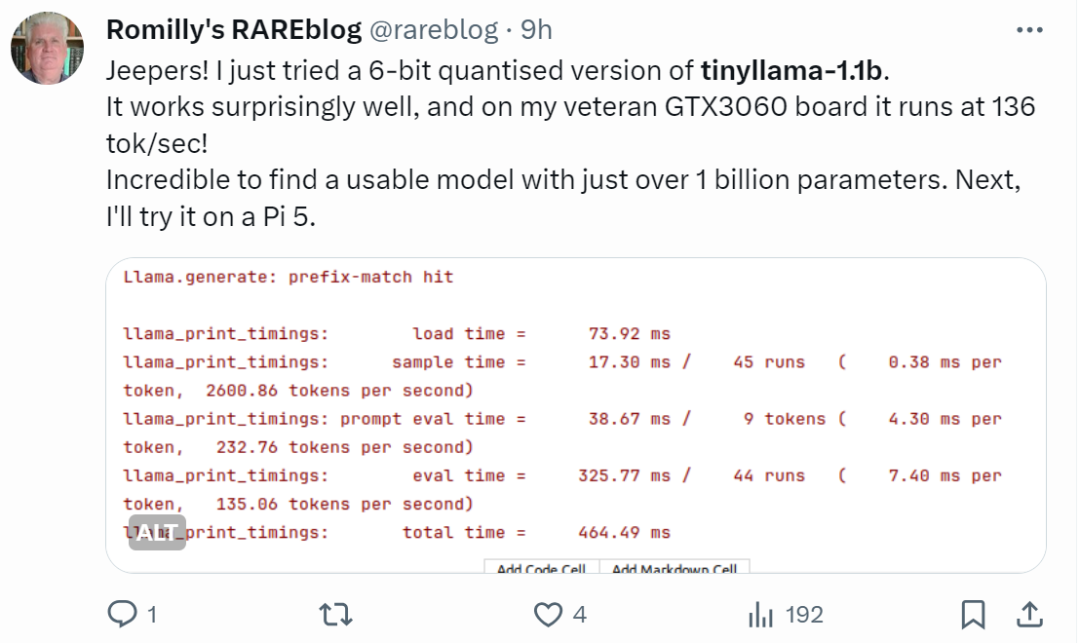
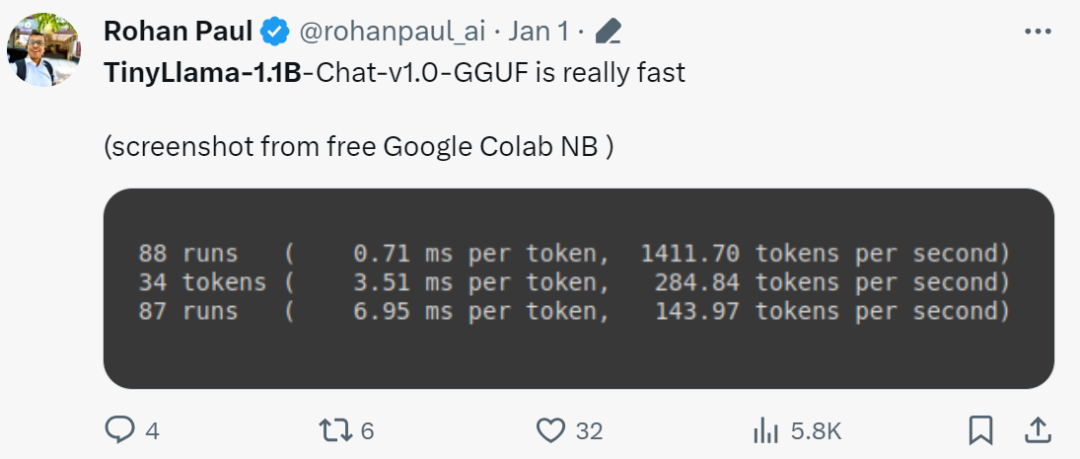
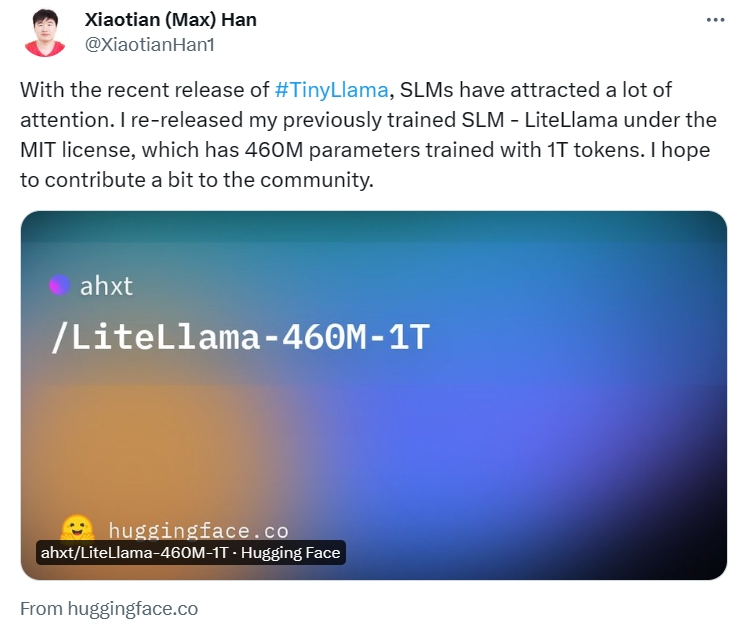
Netizens mit schnellen Händen haben bereits begonnen: Der Laufeffekt ist überraschend gut, mit GTX3060 kann es mit einer Geschwindigkeit von 136 Tok/Sekunde laufen. „Es ist wirklich schnell!“ große Aufmerksamkeit erregen. Xiaotian Han von der Texas Tech und A&M University hat SLM-LiteLlama veröffentlicht. Es verfügt über 460 Millionen Parameter und wird mit 1T-Tokens trainiert. Dies ist ein Open-Source-Fork von LLaMa 2 von Meta AI, jedoch mit einer deutlich kleineren Modellgröße.
Projektadresse: https://huggingface.co/ahxt/LiteLlama-460M-1T
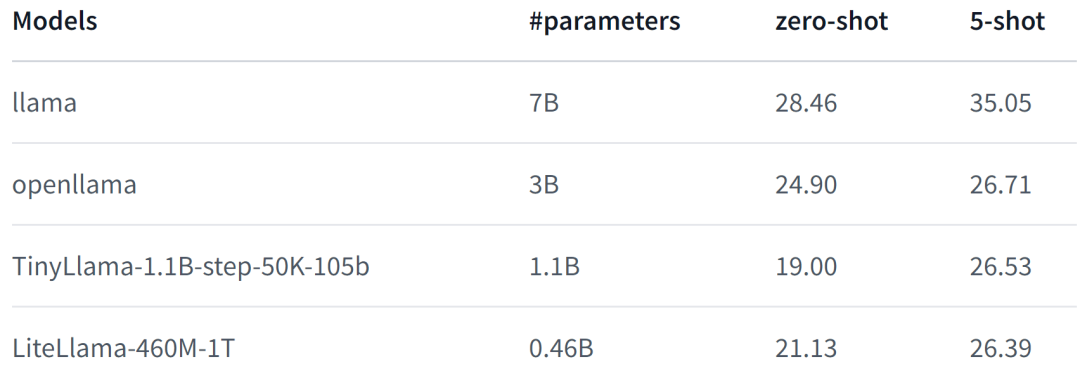
 LiteLlama-460M-1T wird auf dem RedPajama-Datensatz trainiert und verwendet GPT2Tokenizer, um den Text zu tokenisieren. Der Autor hat das Modell anhand der MMLU-Aufgabe bewertet. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Selbst mit einer deutlich reduzierten Anzahl von Parametern kann LiteLlama-460M-1T immer noch Ergebnisse erzielen, die mit anderen Modellen vergleichbar oder besser sind.
LiteLlama-460M-1T wird auf dem RedPajama-Datensatz trainiert und verwendet GPT2Tokenizer, um den Text zu tokenisieren. Der Autor hat das Modell anhand der MMLU-Aufgabe bewertet. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Selbst mit einer deutlich reduzierten Anzahl von Parametern kann LiteLlama-460M-1T immer noch Ergebnisse erzielen, die mit anderen Modellen vergleichbar oder besser sind.
Das Folgende ist die Leistung des Modells. Weitere Details finden Sie unter:
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6
Angesichts der Größe wurde LiteLlama stark verkleinert, und einige Internetnutzer sind neugierig, ob es mit 4 GB Speicher ausgeführt werden kann. Wenn Sie es auch wissen wollen, probieren Sie es doch einfach selbst aus.
Das obige ist der detaillierte Inhalt vonKleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!