
Heim >Technologie-Peripheriegeräte >KI >Reduzieren Sie den Transformer-Rang, um die Leistung zu verbessern und gleichzeitig LLM beizubehalten, ohne die Entfernung von mehr als 90 % der Komponenten in einer bestimmten Schicht zu reduzieren
Reduzieren Sie den Transformer-Rang, um die Leistung zu verbessern und gleichzeitig LLM beizubehalten, ohne die Entfernung von mehr als 90 % der Komponenten in einer bestimmten Schicht zu reduzieren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-13 21:51:06716Durchsuche
MIT und Microsoft führten gemeinsame Untersuchungen durch und stellten fest, dass keine zusätzliche Schulung erforderlich ist, um die Aufgabenleistung großer Sprachmodelle zu verbessern und ihre Größe zu reduzieren.
Im Zeitalter großer Modelle ist Transformer für seine einzigartigen Fähigkeiten zur Unterstützung bekannt gesamten wissenschaftlichen Forschungsbereich. Seit ihrer Einführung haben Transformer-basierte Sprachmodelle (LLM) bei verschiedenen Aufgaben eine hervorragende Leistung gezeigt. Die zugrunde liegende Architektur von Transformer hat sich zur modernsten Technologie für die Modellierung und Argumentation natürlicher Sprache entwickelt und hat in Bereichen wie Computer Vision und Reinforcement Learning gute Aussichten gezeigt
Die aktuelle Transformer-Architektur ist jedoch sehr umfangreich und normalerweise erfordert eine große Menge an Rechenressourcen für Training und Argumentation.
Schreiben Sie es so um: Dies ist sinnvoll, da ein mit mehr Parametern oder Daten trainierter Transformer offensichtlich leistungsfähiger ist als andere Modelle. Immer mehr Untersuchungen zeigen jedoch, dass Transformer-basierte Modelle und neuronale Netze nicht alle Anpassungsparameter beibehalten müssen, um ihre erlernten Hypothesen aufrechtzuerhalten.
Im Allgemeinen scheint eine Überparametrisierung beim Training von Modellen hilfreich zu sein, diese Modelle können jedoch schwerwiegend sein vor der Schlussfolgerung beschnitten. Studien haben gezeigt, dass neuronale Netze oft mehr als 90 % der Gewichte entfernen können, ohne dass es zu nennenswerten Leistungseinbußen kommt. Dieses Phänomen hat das Interesse von Forschern an Bereinigungsstrategien geweckt, die das Modellargumentieren unterstützen
Forscher vom MIT und Microsoft schrieben in dem Artikel „The Truth is in There: Improving Reasoning in Language Models with Layer-Selective Rank Reduction“ einen überraschenden Befund, der vorsichtig ist Das Beschneiden bestimmter Ebenen des Transformer-Modells kann die Leistung des Modells bei bestimmten Aufgaben erheblich verbessern.

Bitte klicken Sie auf den folgenden Link, um das Papier anzusehen: https://arxiv.org/pdf/2312.13558.pdf
-
Papier-Homepage: https://pratyushashama.github.io/laser/
Die Studie nennt diesen einfachen Eingriff LASER (Layer Selective Rank Reduction), der die Leistung von LLM erheblich verbessert, indem er die höherwertigen Komponenten der erlernten Gewichtsmatrix bestimmter Schichten im Transformer-Modell durch Singulärwertzerlegung selektiv reduziert. Dieser Vorgang kann nach Abschluss des Modelltrainings ohne zusätzliche Parameter oder Daten durchgeführt werden
Während des Vorgangs wird die Gewichtsreduzierung in modellspezifischen Gewichtsmatrizen und -schichten durchgeführt. Diese Studie ergab außerdem, dass viele ähnliche Matrizen Gewichte erheblich reduzieren können und typischerweise keine Leistungseinbußen beobachtet werden, bis mehr als 90 % der Komponenten entfernt wurden
Die Studie ergab außerdem, dass diese Reduzierungen die Genauigkeit erheblich verbessern können, ein Befund, der scheinbar nicht begrenzt ist Im Vergleich zur natürlichen Sprache wurden auch Leistungsverbesserungen beim Reinforcement Learning festgestellt.
Darüber hinaus versucht diese Forschung abzuleiten, was in Komponenten höherer Ordnung gespeichert ist, damit es gelöscht werden kann, um die Leistung zu verbessern. Die Studie ergab, dass LASER die richtigen Fragen beantwortete, das ursprüngliche Modell jedoch vor der Intervention hauptsächlich mit hochfrequenten Wörtern (wie „der“, „von“ usw.) antwortete, die nicht einmal vom gleichen semantischen Typ waren wie der Richtige Antwort, und auch Das heißt, diese Komponenten bewirken, dass das Modell ohne Eingriff einige irrelevante hochfrequente Wörter generiert.
Durch eine gewisse Rangreduzierung kann die Antwort des Modells jedoch in eine richtige Antwort umgewandelt werden.
Um dies zu verstehen, untersuchte die Studie auch, was die übrigen Komponenten einzeln kodierten, und sie approximierten die Gewichtsmatrix nur mithilfe ihrer singulären Vektoren höherer Ordnung. Es wurde festgestellt, dass diese Komponenten unterschiedliche Antworten oder häufig vorkommende Wörter in derselben semantischen Kategorie wie die richtige Antwort beschreiben.
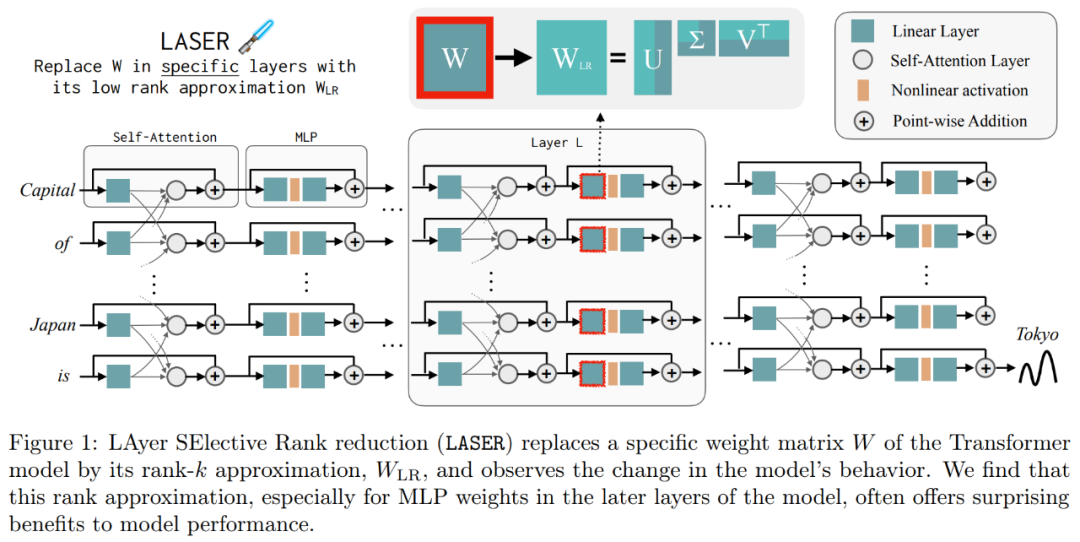
Diese Ergebnisse legen nahe, dass, wenn verrauschte Komponenten höherer Ordnung mit Komponenten niedrigerer Ordnung kombiniert werden, deren widersprüchliche Antworten eine durchschnittliche Antwort ergeben, die möglicherweise falsch ist. Abbildung 1 bietet eine visuelle Darstellung der Transformer-Architektur und des von LASER befolgten Verfahrens. Hier wird die Gewichtsmatrix einer bestimmten Schicht eines mehrschichtigen Perzeptrons (MLP) durch ihre Näherung mit niedrigem Rang ersetzt.
Laser-Übersicht
bietet eine detaillierte Einführung in die LASER-Intervention. Ein einstufiger LASER-Eingriff wird durch das Triplett (τ, ℓ, ρ) definiert, das den Parameter τ, die Anzahl der Schichten ℓ und den reduzierten Rang ρ enthält. Zusammen beschreiben diese Werte die Matrizen, die durch ihre Approximationen mit niedrigem Rang ersetzt werden sollen, sowie den Grad der Approximation. Forscher klassifizieren die Arten von Matrizen, die sie stören werden, basierend auf Parametertypen
Forscher konzentrieren sich auf Matrizen in W = {W_q, W_k, W_v, W_o, U_in, U_out}, die aus Matrizen in MLP und Aufmerksamkeitsschichten bestehen. Die Anzahl der Schichten stellt die Schicht der Forscherintervention dar (die erste Schicht wird beginnend bei 0 indiziert). Zum Beispiel hat Llama-2 32 Schichten, also ℓ ∈ {0, 1, 2,・・・31}.
Letztendlich beschreibt ρ ∈ [0, 1), welcher Teil des maximalen Rangs beibehalten werden sollte, wenn Näherungen mit niedrigem Rang vorgenommen werden. Unter der Annahme 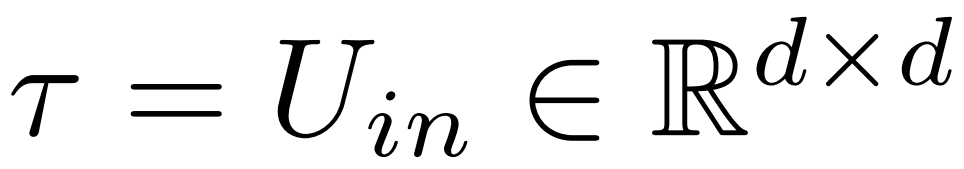 ist der maximale Rang dieser Matrix beispielsweise d. Die Forscher ersetzten es durch die ⌊ρ・d⌋-Näherung.
ist der maximale Rang dieser Matrix beispielsweise d. Die Forscher ersetzten es durch die ⌊ρ・d⌋-Näherung.
Abbildung 1 unten ist ein Beispiel für LASER. In dieser Abbildung stellen τ = U_in und ℓ = L die Aktualisierung der Gewichtsmatrix der ersten Schicht von MLP im Transformer-Block der L^-ten Schicht dar. Ein weiterer Parameter steuert k in der Rang-k-Näherung.
LASER kann den Fluss bestimmter Informationen in einem Netzwerk einschränken und unerwartet erhebliche Leistungsvorteile bewirken. Diese Interventionen können auch problemlos kombiniert werden, beispielsweise durch die Anwendung einer Reihe von Interventionen in beliebiger Reihenfolge 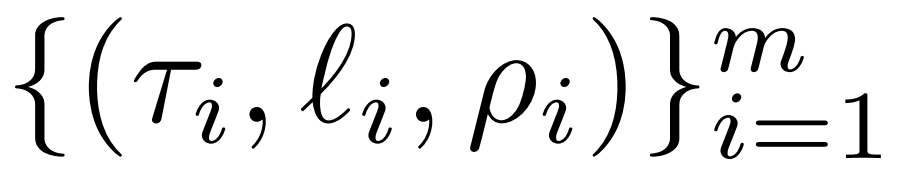 .
.
Die LASER-Methode ist nur eine einfache Suche nach solchen Eingriffen, die so modifiziert sind, dass sie den maximalen Nutzen bringen. Es gibt jedoch viele andere Möglichkeiten, diese Interventionen zu kombinieren, was eine Richtung für die zukünftige Arbeit darstellt.
Um die ursprüngliche Bedeutung beizubehalten, muss der Inhalt ins Chinesische umgeschrieben werden. Der Originalsatz muss nicht angezeigt werden
Im experimentellen Teil verwendete der Forscher das auf dem PILE-Datensatz vorab trainierte GPT-J-Modell. Die Anzahl der Schichten des Modells beträgt 27 und die Parameter betragen 6 Milliarden. Das Verhalten des Modells wird dann anhand des CounterFact-Datensatzes bewertet, der Beispiele von Tripeln (Thema, Beziehung und Antwort) enthält, wobei für jede Frage drei Paraphrasierungsaufforderungen bereitgestellt werden.
Die erste ist die Analyse des GPT-J-Modells auf dem CounterFact-Datensatz. Abbildung 2 unten zeigt die Auswirkungen auf den Klassifizierungsverlust des Datensatzes, wenn auf jede Matrix in der Transformer-Architektur unterschiedliche Grade der Rangreduzierung angewendet werden. Jede der Transformer-Schichten besteht aus einem zweischichtigen kleinen MLP, wobei die Eingabe- und Ausgabematrizen separat angezeigt werden. Unterschiedliche Farben stellen unterschiedliche Prozentsätze der entfernten Komponenten dar.
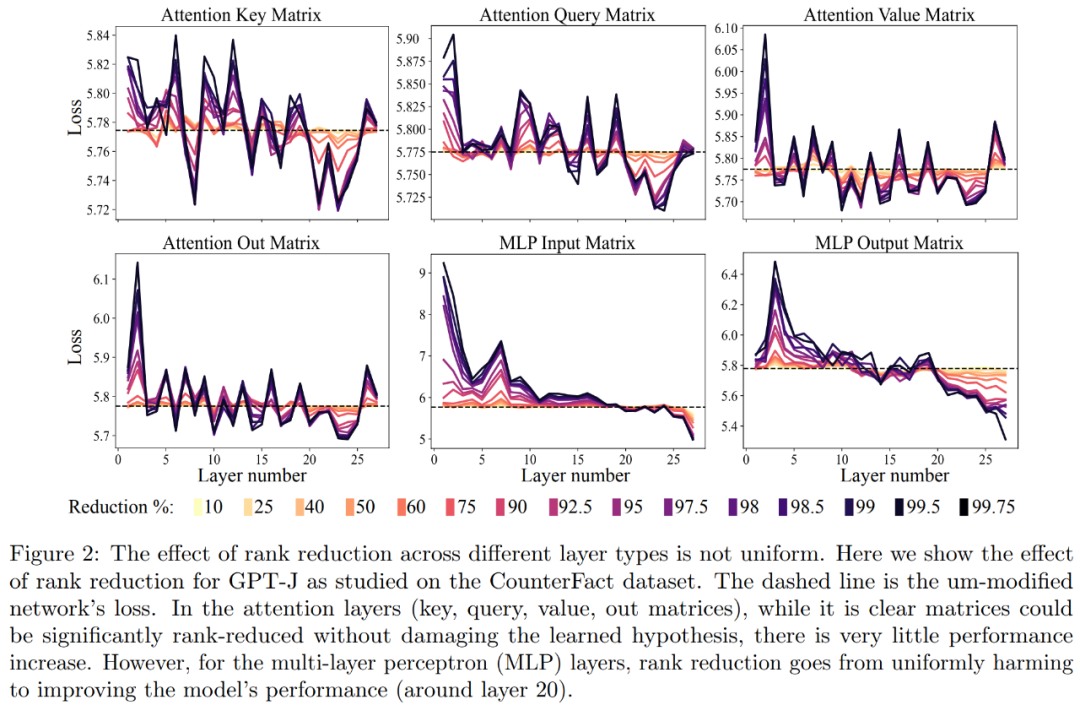
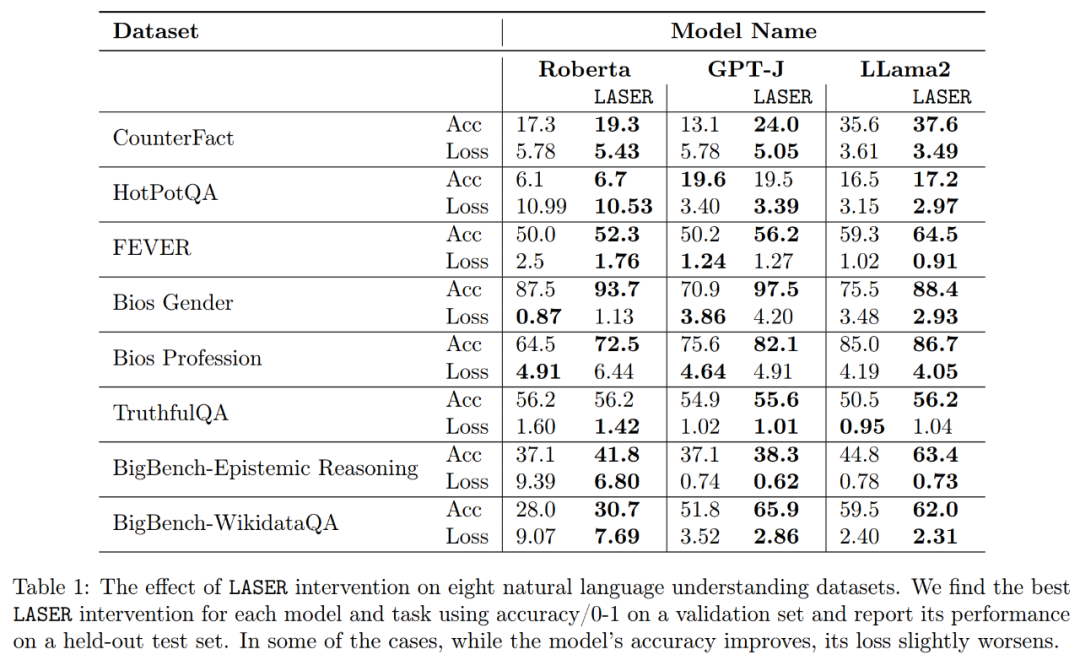
Im Hinblick auf die Verbesserung der Genauigkeit und Robustheit der Interpretation, wie in Abbildung 2 oben und Tabelle 1 unten dargestellt, stellten die Forscher fest, dass bei der Durchführung einer Rangreduzierung auf einer einzelnen Ebene die Tatsache, dass das GPT-J-Modell auf der eine gute Leistung erbringt CounterFact-Datensatz Die Genauigkeit stieg von 13,1 % auf 24,0 %. Es ist wichtig zu beachten, dass diese Verbesserungen nur das Ergebnis einer Rangreduzierung sind und kein weiteres Training oder eine Feinabstimmung des Modells erfordern.
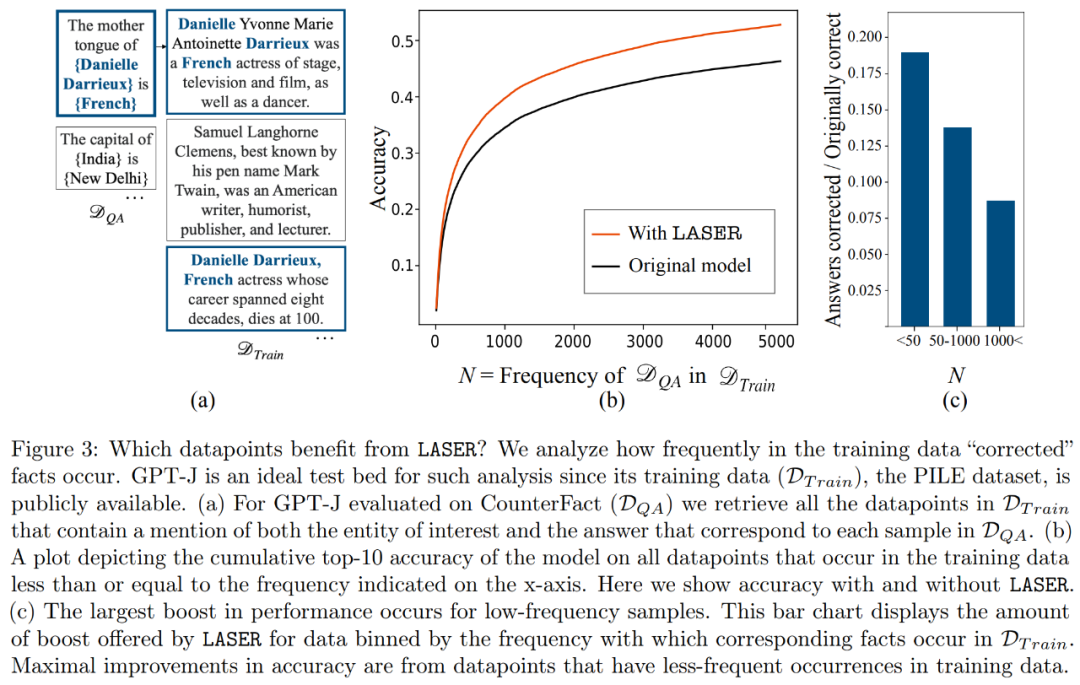
Welche Fakten durch Rangreduzierung im Datensatz wiederhergestellt werden, ist für Forscher zu einem Problem geworden. Die Forscher fanden heraus, dass die Tatsache der Wiederherstellung durch Rangreduzierung selten in den Daten auftauchte, wie in Abbildung 3 dargestellt.
Was speichern Komponenten höherer Ordnung? Im Gegensatz zu LASER verwenden Forscher Komponenten höherer Ordnung zur Annäherung an die endgültige Gewichtsmatrix, wie in Abbildung 5(a) dargestellt. Bei der Approximation der Matrix unter Verwendung einer unterschiedlichen Anzahl von Komponenten höherer Ordnung maßen sie die durchschnittliche Kosinusähnlichkeit zwischen den wahren und vorhergesagten Antworten, wie in Abbildung 5(b) dargestellt LLMs zu mehreren Sprachverständnisaufgaben. Für jede Aufgabe bewerteten sie die Leistung des Modells, indem sie drei Metriken generierten: Genauigkeit, Klassifizierungsgenauigkeit und Verlust. Wie in Tabelle 1 oben gezeigt, führt selbst eine große Rangreduzierung nicht zu einer Verringerung der Modellgenauigkeit, kann jedoch die Modellleistung verbessern.
Das obige ist der detaillierte Inhalt vonReduzieren Sie den Transformer-Rang, um die Leistung zu verbessern und gleichzeitig LLM beizubehalten, ohne die Entfernung von mehr als 90 % der Komponenten in einer bestimmten Schicht zu reduzieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was macht ein Datenpflegeingenieur?
- So schreiben Sie einen Lebenslauf für einen Web-Frontend-Ingenieur
- Bringen Sie Ihnen Schritt für Schritt bei, wie Sie ein Maven-Projekt in vscode erstellen (Kombination aus Grafiken und Text).
- Lassen Sie uns darüber sprechen, wie Sie das Springboot-Projekt ordnungsgemäß in vscode ausführen können