
Heim >Technologie-Peripheriegeräte >KI >Durchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben
Durchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-12 17:24:06621Durchsuche

Neu formatiert|.
Papierlink: https://doi.org/10.1007/s10489-023-05048-8Zugehöriger Code: https://github.com/AILBC/BiG2S Der Autor verwendet Ein Diagramm des aktuellen Aufstiegs auf dem Gebiet der templatfreien Retrosynthese. Basierend auf dem Sequenzmodell-Framework versuchen wir außerdem, ein Modell BiG2S (Bidirektionaler Graph zur Sequenz) zu erstellen, das gleichzeitig die Aufgaben der Retrosynthese-Vorhersage und der Vorwärtsreaktionsvorhersage in einem einzigen löst Modell auf derselben Parameterskala. Gleichzeitig untersucht der Autor auch die Mainstream-Inverse. Eine vorläufige Analyse wurde am synthetischen Datensatz USPTO-50k durchgeführt, um den Unterschied in der Vorhersageschwierigkeit verschiedener SMILES-Segmente während des Trainingsprozesses und der Fluktuation zu untersuchen der Top-k-Übereinstimmungsrate des Modells im Validierungssatz wurde ein Ungleichgewichtsverlust eingeführt, um diese Funktionsprobleme zu beheben und die Modellensemble- und Strahlsuchstrategien zu verbessern Reaktionsvorhersageaufgaben und durch umfassende Ablationsexperimente an den oben genannten Modulen ist BiG2S in der Lage, Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben mit einem einzigen Modell auf geeigneten Parameterskalen zu bewältigen. Im Vergleich zu bestehenden vorlagenfreien Methoden, die auf Vortraining und Datenverbesserung basieren, ist die allgemeine Vorhersagefähigkeit von BiG2S gleichermaßen hervorragend. Hintergrund der Forschung: Retrosynthese und Vorwärtssynthese sind organische Chemie, computergestützte Syntheseplanung (CASP). ) Und grundlegende Herausforderungen im Bereich des computergestützten Arzneimitteldesigns (CADD)
Der Autor verwendet Ein Diagramm des aktuellen Aufstiegs auf dem Gebiet der templatfreien Retrosynthese. Basierend auf dem Sequenzmodell-Framework versuchen wir außerdem, ein Modell BiG2S (Bidirektionaler Graph zur Sequenz) zu erstellen, das gleichzeitig die Aufgaben der Retrosynthese-Vorhersage und der Vorwärtsreaktionsvorhersage in einem einzigen löst Modell auf derselben Parameterskala. Gleichzeitig untersucht der Autor auch die Mainstream-Inverse. Eine vorläufige Analyse wurde am synthetischen Datensatz USPTO-50k durchgeführt, um den Unterschied in der Vorhersageschwierigkeit verschiedener SMILES-Segmente während des Trainingsprozesses und der Fluktuation zu untersuchen der Top-k-Übereinstimmungsrate des Modells im Validierungssatz wurde ein Ungleichgewichtsverlust eingeführt, um diese Funktionsprobleme zu beheben und die Modellensemble- und Strahlsuchstrategien zu verbessern Reaktionsvorhersageaufgaben und durch umfassende Ablationsexperimente an den oben genannten Modulen ist BiG2S in der Lage, Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben mit einem einzigen Modell auf geeigneten Parameterskalen zu bewältigen. Im Vergleich zu bestehenden vorlagenfreien Methoden, die auf Vortraining und Datenverbesserung basieren, ist die allgemeine Vorhersagefähigkeit von BiG2S gleichermaßen hervorragend. Hintergrund der Forschung: Retrosynthese und Vorwärtssynthese sind organische Chemie, computergestützte Syntheseplanung (CASP). ) Und grundlegende Herausforderungen im Bereich des computergestützten Arzneimitteldesigns (CADD)
Derzeit sind die Eingabe und Ausgabe der meisten templatfreien Retrosynthesemodelle SMILES-Molekülketten, d. h. sie verwenden einen Sequenz-zu-Sequenz-Prozess (Seq2Seq). Diese Methode kann das vorhandene Modellgerüst im Bereich der Verarbeitung natürlicher Sprache sowie den ausgereiften Datenverarbeitungsfluss für die SMILES-Darstellungsmethode gut nutzen. Da SMILES jedoch eine eindimensionale Zeichenfolgenfolge nicht gut darstellen und nutzen kann In diesem Bereich tauchen nach und nach zweidimensionale/dreidimensionale Strukturinformationen auf, die in molekularen Graphen enthalten sind, Graph-to-Sequence (Graph2Seq)-Methoden, die molekulare Graphen anstelle von SMILES als Modelleingabe verwenden, oder die zusätzlichen strukturellen Informationen von molekularen Graphen werden eingebettet in SMILES-Sequenzen umwandeln. Beide Methoden können die reichhaltigen Strukturmerkmale molekularer Graphen gut nutzen
Auf dieser Grundlage basiert dieser Artikel auf der neuen Graph-to-Sequence-Methode und trainiert die Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben gleichzeitig auf dem ursprünglichen SMILES-basierten Modell Basierend auf den relevanten Explorations-Benchmarks untersuchen wir den Aufbau und die Experimente dieser Art von Dual-Task-Modell weiter und untersuchen und analysieren vorläufig auch das Schwierigkeitsungleichgewicht und die Top-k-Matching-Rate-Schwankungen, die das Modell während des Trainingsprozesses anzeigt. ;Das auf dieser Basis aufgebaute BiG2S-Modell kann Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben in Mainstream-Datensätzen besser bewältigen und erreicht Reaktionsvorhersagefunktionen, die mit anderen vorlagenfreien Retrosynthesemodellen konsistent sind, ohne Datenverbesserung zu verwenden
Das Gesamtgerüst muss neu geschrieben werdenDie Gesamtstruktur von BiG2S ist ein End-to-End-Encoder-Decoder, wie in Abbildung 1 dargestellt. Die Encoder-Seite verwendet ein lokal gerichtetes Message-Passing-Graph-Netzwerk und einen globalen Graph-Transformer, der Informationen zur Graphstruktur-Bias einbezieht, um die endgültige molekulare Graph-Knotendarstellung zu generieren. Der Decoder verwendet einen Standard-Transformer-Decoder, um die SMILES-Sequenz des Zielmoleküls auf autoregressive Weise zu generieren
Es ist zu beachten, dass die Eingabe in den Decoder zusätzlich Doppel- enthält, um gleichzeitig Retrosynthese und Vorwärtsreaktionsvorhersage zu lernen. Ziffernfolgen ohne Hinzufügen von Positionsinformationen. Gleichzeitig verfügen die Normalisierungsschicht und die letzte lineare Schicht auf der Decoderseite über zwei Parametersätze, die zum Erlernen der Retrosyntheseaufgabe bzw. der Vorwärtsreaktionsvorhersageaufgabe verwendet werden
Abbildung 1: BiG2S-GesamtrahmendiagrammErfordert einen Trainingsrahmen für zwei Aufgaben
Retrosynthese und Vorwärtsreaktionsvorhersage sind zwei verwandte Aufgaben. Die Retrosyntheseaufgabe verwendet Produkte als Eingabe und Reaktanten als Zielausgabe, während die Vorwärtsreaktionsvorhersageaufgabe das Gegenteil bewirkt. Es besteht eine enge Verbindung zwischen diesen beiden Aufgaben, da sie durch Austausch der Eingabe und Zielausgabe der Retrosyntheseaufgabe in eine Vorwärtsreaktionsvorhersageaufgabe umgewandelt werden können. Daher haben einige auf SMILES basierende vorlagenfreie Modelle versucht, Synthese und Weiterleitung durchzuführen Reaktionsvorhersagen werden als Trainingsziele verwendet, um das Verständnis chemischer Reaktionen zu verbessern und bestimmte Ergebnisse zu erzielen. Basierend auf dieser Idee versuchte der Autor außerdem, Dual-Task-Training in das Graph-to-Sequence-Modell einzuführen
Insbesondere basierte der Autor auf der Parameter-Sharing-Strategie, die zuvor bei anderen Methoden in der Normalisierungsschicht des Decoders verwendet wurde Letzte lineare Schicht Es werden zwei Sätze aufgabenspezifischer Parameter erstellt. In anderen Modulen teilen sich die beiden Aufgabentypen eine Reihe von Parametern. Gleichzeitig werden den Eingabeknoten des Molekulargraphen und der anfänglichen Eingabesequenz des Decoders zusätzliche Dual-Task-Markierungen hinzugefügt. Auf diese Weise kann das Modell auch bei gleichzeitiger Steuerung der Gesamtmodellgröße zwischen den beiden Aufgabentypen unterscheiden und ihre unterschiedlichen Datenverteilungen lernen
Erfordert Training und InferenzoptimierungWährend des Trainingsprozesses hat der Autor weiter aufgezeichnet und analysierte die beiden Arten von Problemen des Modells, die sich im Trainingsprozess widerspiegelten
Zuerst zeichnete der Autor die Häufigkeit des Auftretens verschiedener SMILES-Zeichen in USPTO-50k und ihre entsprechende Vorhersagegenauigkeit während des Trainings auf, wie in Abbildung 2 dargestellt. Während des Trainingsprozesses erreichte der absolute Unterschied in der Gesamtvorhersagegenauigkeit für S und Br, die 0,4 % bzw. 0,3 % im Trainingssatz ausmachten, 8 %. Dies zeigt zunächst, dass es offensichtliche Unterschiede in der Vorhersageschwierigkeit zwischen verschiedenen molekularen Strukturen/Fragmenten gibt. Daher lindert der Autor solche Probleme durch die Einführung einer unausgeglichenen Verlustfunktion (z. B. Focal Loss), damit das Modell dem mehr Aufmerksamkeit schenken kann Genauigkeit während des Trainings.
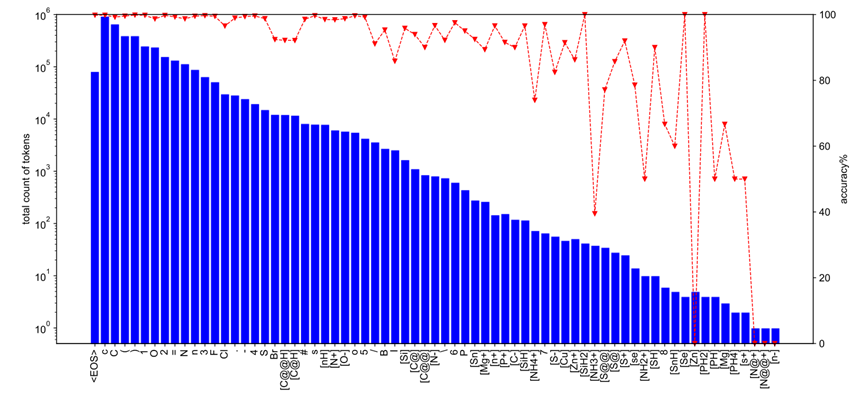 Abbildung 2: Im USPTO-50k-Trainingssatz die Häufigkeit des Auftretens verschiedener SMILES-Zeichen und ihre allgemeine Vorhersagegenauigkeit während des Trainings
Abbildung 2: Im USPTO-50k-Trainingssatz die Häufigkeit des Auftretens verschiedener SMILES-Zeichen und ihre allgemeine Vorhersagegenauigkeit während des Trainings
Darüber hinaus hat der Autor auch die Validierung aufgezeichnet Das Modell während des Trainings Die Qualität der Vorhersageergebnisse der Menge ändert sich, wie in Abbildung 3 dargestellt. Der Autor stellte fest, dass sich in der mittleren und späten Trainingsphase des USPTO-50k-Datensatzes die Top-1-Genauigkeit des Modells im Validierungssatz immer noch verbesserte, die Vorhersagequalität von Top-3 und Top-5 jedoch abnahm , und Top-10 Signifikanter Rückgang
Um die Top-1-Vorhersagequalität des Modells zu verbessern und gleichzeitig die Gesamtqualität der Top-10-Reaktantengenerierungsergebnisse des Modells beizubehalten, haben wir zusätzlich eine Art Modellintegrationsstrategie basierend auf benutzerdefinierten Bewertungsindikatoren entwickelt . Konkret erstellen wir eine Warteschlange zum Speichern von Modellen und sortieren die gespeicherten Modelle nach vordefinierten Bewertungsindikatoren (wie Top-1-Genauigkeit, gewichtete Top-k-Genauigkeit usw.). Während des gesamten Trainingsprozesses speichern wir Kandidatenmodelle dynamisch und generieren automatisch Ensemblemodelle basierend auf den Top 3–5 in der Warteschlange, wodurch die Top-k-Modelle mit der höchsten Vorhersagequalität beibehalten werden. In der Inferenzphase haben wir auch die Strahlsuchstrategie basierend auf dem neuen Framework neu aufgebaut und uns mehr auf die Suchbreite konzentriert, um die Gesamtqualität der von Top-k generierten Ergebnisse des Modells zu verbessern
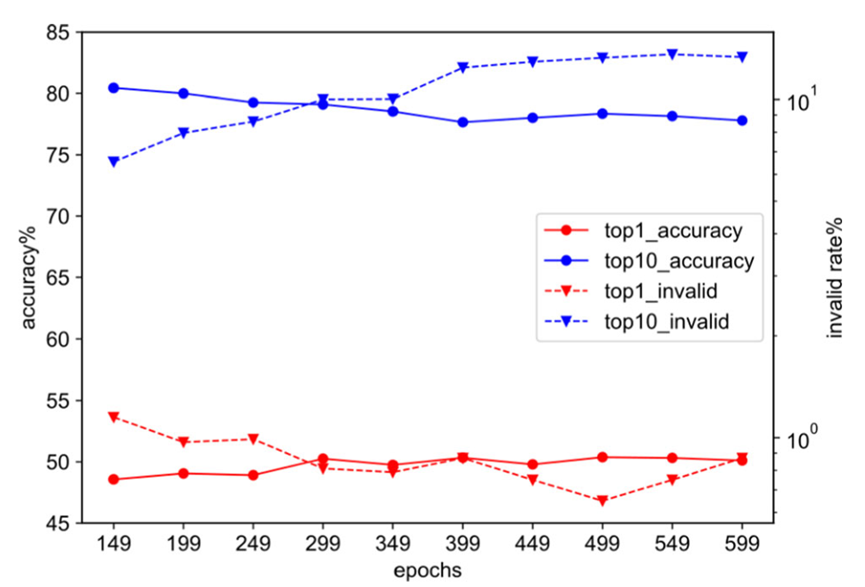 Abbildung 3: Während des Trainings im USPTO- 50k-Datensatz Die Änderungskurve der Top-k-Übereinstimmungsrate des Modells im Validierungssatz und der Anteil der Top-k-ungültig generierten Moleküle
Abbildung 3: Während des Trainings im USPTO- 50k-Datensatz Die Änderungskurve der Top-k-Übereinstimmungsrate des Modells im Validierungssatz und der Anteil der Top-k-ungültig generierten Moleküle
Der Autor hat durchgeführt es in der Retrosyntheseaufgabe und der Vorwärtsreaktionsvorhersageaufgabe. Das Experiment wurde unter Verwendung der Datensätze USPTO-50k, USPTO-MIT und USPTO-full durchgeführt, die 50.000, 500.000 und 1 Million chemische Reaktionsdaten enthielten. Im Experiment wurde die Leistung des Dual-Task-Modells und des Single-Task-Modells verglichen. Gemäß den Testergebnissen in Abbildung 4:
Im kleinen Datensatz erreichte BiG2S eine führende Vorhersagegenauigkeit bei der Retrosyntheseaufgabe basierend auf dem Dual-Task-Training und behielt gleichzeitig eine hohe Vorwärtsreaktionsvorhersagegenauigkeit bei, war jedoch verzerrt Im USPTO-MIT-Datensatz zur Reaktionsvorhersage und im groß angelegten Datensatz USPTO-full ist die Leistung des Modells nach dem Dual-Task-Training aufgrund der Begrenzung der Gesamtparametermenge beeinträchtigt verringert. Dennoch wurde die Fähigkeit, die Retrosyntheseaufgabe und die Vorwärtsreaktionsvorhersageaufgabe gleichzeitig zu verarbeiten, aus dem Dual-Task-Modell mit nahezu der gleichen Anzahl von Parametern und einer geringfügigen Verringerung der Antwortvorhersagefähigkeit erhalten (der absolute Unterschied in der Top-k-Genauigkeit beträgt ca 0,5 %). Aus Sicht der Fähigkeiten hat das BiG2S-Modell die erwarteten Ziele erreicht die Verwendung von Einzelaufgaben Das Modell führt jeweils zwei Arten von Aufgaben aus
Analysieren Sie das Ablationsexperiment erneut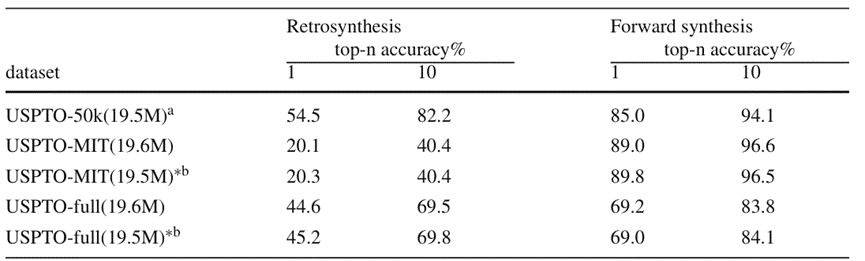
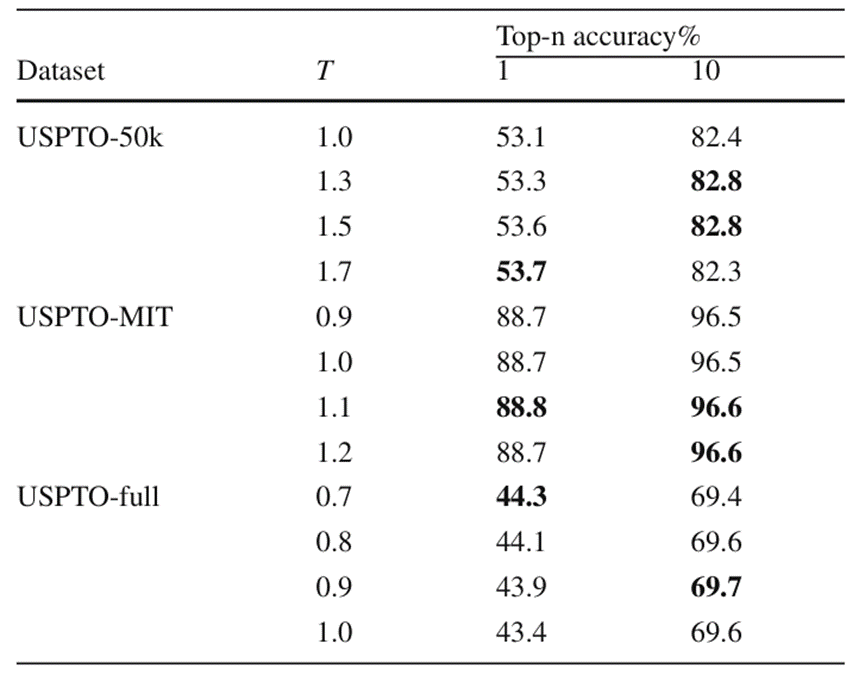
Der Autor verifizierte außerdem den neuen Strahlsuchalgorithmus und die optimalen Temperaturhyperparameter von BiG2S bei der Vorhersage in verschiedenen Datensätzen nach Verwendung von Ungleichgewichtsverlusten durch Ablationsexperimente. Der Temperatur-Hyperparameter bezieht sich hier auf den Temperaturparameter T, der in Softmax zur Steuerung der Ausgabewahrscheinlichkeitsverteilung verwendet wird. Die experimentellen Ergebnisse sind in Abbildung 5 und Abbildung 6 dargestellt
Im Experiment zum Strahlsuchalgorithmus kann beobachtet werden, dass OpenNMT die Suchbreite auf das Dreifache erweiterte, während sich die Suchzeit bei der neuen Strahlsuche nur auf das 1,74-fache erweiterte Algorithmus Wenn die Top-1-Genauigkeit mit OpenNMT übereinstimmt, erhöht sich die Gesamtsuchzeit um das 1-2-fache, aber in Bezug auf die Qualität der Top-10-Vorhersageergebnisse hat der neue Strahlsuchalgorithmus einen absoluten Genauigkeitsvorteil von mindestens 3 % im Vergleich zu OpenNMT. Neben einem effektiven Molekülverhältnisvorteil von 2 % kann man sagen, dass der neue Strahlsuchalgorithmus die Qualität der gesamten Top-k-Suchergebnisse des Modells auf Kosten der Suchzeit erheblich verbessert hat
Bei der Durchführung von Experimenten zu Temperatur-Hyperparametern stellten die Forscher fest, dass die Verwendung größerer Temperaturparameter in kleinen Datensätzen die Gesamtgenauigkeit der Top-k-Vorhersage erheblich verbessern kann. Da sich die BiG2S-Modellgröße bei größeren Datensätzen nicht vollständig an alle Reaktionsdaten anpassen kann, hilft die Auswahl kleinerer Temperaturparameter zu diesem Zeitpunkt oft bei der Modellsuche

 Die Schlussfolgerung der Studie zeigt...
Die Schlussfolgerung der Studie zeigt...
Um die Probleme der ungleichmäßigen Vorhersageschwierigkeit verschiedener SMILES-Zeichen und der Schwankungen der Top-k-Vorhersagegenauigkeit während des Modelltrainings zu lösen, führte der Autor einen Ungleichgewichtsverlust, eine automatische Modellintegrationsstrategie basierend auf benutzerdefinierten Bewertungsindikatoren und einen Strahlsuchalgorithmus basierend auf a ein Neues Framework zur Linderung dieser Probleme
BiG2S hat gute Dual-Task-Vorhersagefähigkeiten für drei Mainstream-Datensätze unterschiedlicher Größe gezeigt, und weitere Ablationsexperimente haben auch die Wirksamkeit der zusätzlich eingeführten Trainings- und Inferenzstrategien bewiesenDas obige ist der detaillierte Inhalt vonDurchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!