Animate124, verwandeln Sie ganz einfach ein einzelnes Bild in ein 3D-Video.
Im vergangenen Jahr hat DreamFusion einen neuen Trend angeführt, nämlich die Generierung statischer 3D-Objekte und -Szenen, der im Bereich der Generierungstechnologie große Aufmerksamkeit erregt hat. Wenn wir auf das vergangene Jahr zurückblicken, konnten wir erhebliche Fortschritte bei der Qualität und Kontrolle der 3D-Statikerzeugungstechnologie beobachten. Die Technologieentwicklung begann mit der textbasierten Generierung, wurde schrittweise in Einzelansichtsbilder integriert und entwickelte sich dann zur Integration mehrerer Steuersignale. Im Vergleich dazu steckt die Generierung dynamischer 3D-Szenen noch in den Kinderschuhen. Anfang 2023 startete Meta MAV3D und markierte damit den ersten Versuch, 3D-Videos basierend auf Text zu generieren. Aufgrund des Mangels an Open-Source-Videogenerierungsmodellen waren die Fortschritte in diesem Bereich jedoch relativ langsam. Jetzt wurde jedoch eine 3D-Videogenerierungstechnologie veröffentlicht, die auf der Kombination von Grafiken und Text basiert! Obwohl die textbasierte 3D-Videogenerierung in der Lage ist, vielfältige Inhalte zu produzieren, gibt es immer noch Einschränkungen bei der Kontrolle der Details und Posen von Objekten. Im Bereich der statischen 3D-Generierung können 3D-Objekte mithilfe eines einzelnen Bildes als Eingabe effektiv rekonstruiert werden. Davon inspiriert schlug das Forschungsteam der National University of Singapore (NUS) und Huawei das Animate124-Modell vor. Dieses Modell kombiniert ein einzelnes Bild mit einer entsprechenden Aktionsbeschreibung, um eine präzise Steuerung der 3D-Videoerzeugung zu ermöglichen. 
- Projekthomepage: https://animate124.github.io/
- Papieradresse: https://arxiv.org/abs/2311.14603
-
Code: https://github. com/HeliosZhao/Animate124 unterteilt die 3D-Videogenerierung in drei Phasen : 1) Statische Generierungsphase: Verwenden Sie das Vincentian-Graph- und 3D-Graph-Diffusionsmodell, um 3D-Objekte aus einem einzelnen Bild zu generieren. 2) Dynamische Grobgenerierungsphase: Verwenden Sie das Vincentian-Videomodell, um Aktionen gemäß der Sprachbeschreibung zu optimieren. Darüber hinaus wird die personalisierte Feinabstimmung von ControlNet verwendet, um die durch die Sprachbeschreibung der zweiten Stufe verursachten Abweichungen im Erscheinungsbild zu optimieren und zu verbessern. Abbildung 1: Gesamtrahmen Null – 1-zu-3 ) Generieren Sie statische Objekte basierend auf Bildern:

Für die Perspektive, die dem bedingten Bild entspricht, verwenden Sie zusätzlich die Verlustfunktion zur Optimierung:
Durch die beiden oben genannten Optimierungsziele werden mehrere Perspektiven erhalten 3D-konsistente statische Objekte (dieser Schritt wird im Rahmendiagramm weggelassen).
Dynamische grobe Generierung
Diese Phase verwendet hauptsächlich das 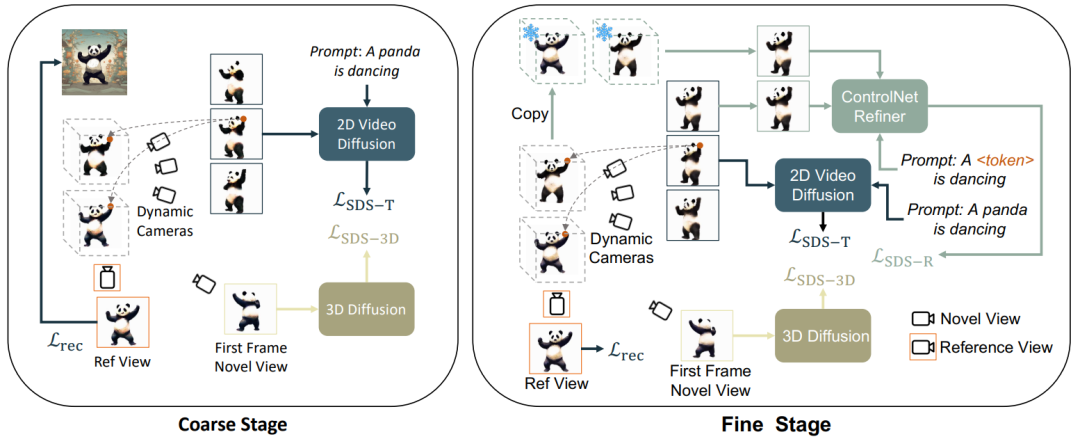 Vinson-Videodiffusionsmodell
Vinson-Videodiffusionsmodell
, das statisches 3D als Ausgangsbild behandelt und Aktionen basierend auf Sprachbeschreibungen generiert. Insbesondere rendert das dynamische 3D-Modell (dynamisches NeRF) ein Multi-Frame-Video mit kontinuierlichen Zeitstempeln und gibt dieses Video in das Vincent-Videodiffusionsmodell ein, wobei der SDS-Destillationsverlust zur Optimierung des dynamischen 3D-Modells verwendet wird:
Nur mit Vincent Video Der Destillationsverlust führt dazu, dass das 3D-Modell den Inhalt des Bildes vergisst, und zufällige Stichproben führen zu unzureichendem Training in der Anfangs- und Endphase des Videos. Daher haben die Forscher in diesem Artikel die Start- und Endzeitstempel übermäßig abgetastet. Und beim Abtasten des Anfangsrahmens werden zusätzliche statische Funktionen zur Optimierung verwendet (SDS-Destillationsverlust von 3D-Diagrammen): Daher lautet die Verlustfunktion in dieser Phase: 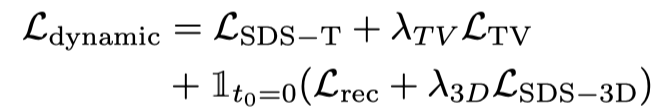
Selbst mit anfänglicher Frame-Überabtastung und zusätzlicher Überwachung wird während des Optimierungsprozesses mithilfe des Vincent-Videodiffusionsmodells das The des Objekts ermittelt Das Erscheinungsbild wird weiterhin durch den Text beeinflusst, der das Referenzbild versetzt. Daher schlägt dieser Artikel eine semantische Optimierungsphase vor, um den semantischen Offset durch ein personalisiertes Modell zu verbessern. Da es nur ein einzelnes Bild gibt, kann das Vincent-Videomodell nicht personalisiert trainiert werden. In diesem Artikel wird ein auf Bildern und Text basierendes Diffusionsmodell vorgestellt und eine personalisierte Feinabstimmung dieses Diffusionsmodells durchgeführt. Dieses Verbreitungsmodell soll den Inhalt und die Aktionen des Originalvideos nicht verändern, sondern lediglich das Erscheinungsbild anpassen. Daher übernimmt dieser Artikel das ControlNet-Tile-Grafikmodell, verwendet die in der vorherigen Phase generierten Videobilder als Bedingungen und optimiert entsprechend der Sprache. ControlNet basiert auf dem Stable Diffusion-Modell. Es muss lediglich eine personalisierte Feinabstimmung (Textinversion) der Stable Diffusion durchgeführt werden, um die semantischen Informationen im Referenzbild zu extrahieren. Behandeln Sie das Video nach der personalisierten Feinabstimmung als Mehrbildbild und verwenden Sie ControlNet, um ein einzelnes Bild zu überwachen: 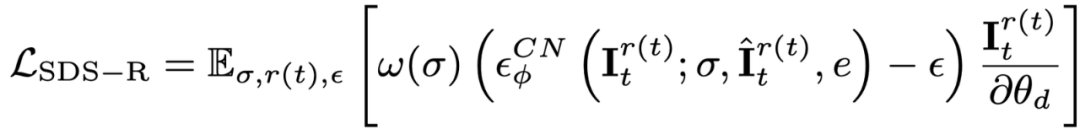
Da ControlNet außerdem grobe Bilder als Bedingungen verwendet, kann die klassifikatorfreie Führung (CFG) verwendet werden Normalbereich (10 links und rechts), anstatt einen sehr großen Wert (normalerweise 100) wie beim Vincentian-Diagramm und den Vincentian-Videomodellen zu verwenden. Ein zu großer CFG führt zu einer Übersättigung des Bildes. Daher kann die Verwendung des ControlNet-Diffusionsmodells das Übersättigungsphänomen lindern und bessere Generierungsergebnisse erzielen. Die Überwachung dieser Phase wird durch den dynamischen Phasenverlust und die ControlNet-Überwachung kombiniert: 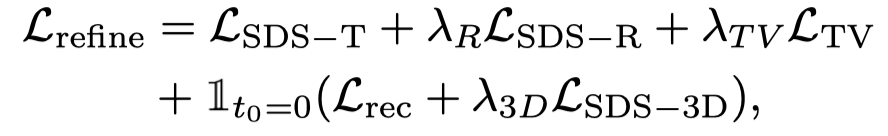
Experimentelle ErgebnisseAls erstes Bild-Text-basiertes 3D-Videogenerierungsmodell wird dieser Artikel mit zwei Basislinien verglichen Modelle und MAV3D wurden verglichen. Animate124 liefert im Vergleich zu anderen Methoden bessere Ergebnisse. Vergleich der visuellen Ergebnisse 3D Vincent 3D-Video Abbildung 3.1. Genauigkeit, Ähnlichkeit mit Bildern und zeitliche Konsistenz. Zu den manuellen Bewertungsindikatoren gehören Textähnlichkeit, Bildähnlichkeit, Videoqualität, Bewegungsrealismus und Bewegungsamplitude. Die manuelle Bewertung wird durch das Verhältnis eines einzelnen Modells zur Auswahl von Animate124 für die entsprechende Metrik dargestellt. 
Im Vergleich zu den beiden Basismodellen erzielt Animate124 sowohl bei der CLIP- als auch bei der manuellen Auswertung bessere Ergebnisse. Tabelle 1: Quantitativer Vergleich zwischen Animate124 und zwei Basislinien 3D basierend auf Textbeschreibung Videomethode. Es verwendet mehrere Diffusionsmodelle zur Überwachung und Anleitung und optimiert das dynamische 4D-Darstellungsnetzwerk, um hochwertige 3D-Videos zu generieren. Das obige ist der detaillierte Inhalt vonMit nur einem Bild und einem Aktionsbefehl kann Animate124 ganz einfach ein 3D-Video erstellen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

