

 Technologie-PeripheriegeräteKIDas Klettern entlang des Netzwerkkabels ist zur Realität geworden, Audio2Photoreal kann durch Dialoge realistische Ausdrücke und Bewegungen erzeugen
Technologie-PeripheriegeräteKIDas Klettern entlang des Netzwerkkabels ist zur Realität geworden, Audio2Photoreal kann durch Dialoge realistische Ausdrücke und Bewegungen erzeugen
Wenn Sie und Ihre Freunde über den kalten Handybildschirm chatten, müssen Sie den Tonfall der anderen Person erraten. Wenn er spricht, können seine Ausdrücke und sogar seine Handlungen in Ihrem Kopf sichtbar werden. Natürlich wäre es am besten, wenn Sie einen Videoanruf tätigen könnten, aber in tatsächlichen Situationen können Sie zu keinem Zeitpunkt Videoanrufe tätigen.
Wenn Sie mit einem entfernten Freund chatten, geschieht dies nicht über einen kalten Bildschirmtext oder einen Avatar ohne Ausdruck, sondern über eine realistische, dynamische und ausdrucksstarke digitale virtuelle Person. Diese virtuelle Person kann nicht nur das Lächeln, die Augen und sogar subtile Körperbewegungen Ihres Freundes perfekt reproduzieren. Werden Sie sich freundlicher und warmer fühlen? Es verkörpert wirklich den Satz „Ich werde am Netzwerkkabel entlang kriechen, um dich zu finden.“
Das ist keine Science-Fiction-Fantasie, sondern eine Technologie, die in die Realität umgesetzt werden kann.
Mimik und Körperbewegungen enthalten eine große Menge an Informationen, die die Bedeutung des Inhalts stark beeinflussen. Wenn man beispielsweise beim ständigen Blick auf den Gesprächspartner spricht, hat man ein ganz anderes Gefühl als beim Sprechen ohne Augenkontakt, was sich auch auf das Verständnis des Gesprächspartners für den Kommunikationsinhalt auswirkt. Wir haben eine äußerst ausgeprägte Fähigkeit, diese subtilen Ausdrücke und Bewegungen während der Kommunikation zu erkennen und sie zu nutzen, um ein umfassendes Verständnis für die Absicht, das Wohlbefinden oder das Verständnis des Gesprächspartners zu entwickeln. Daher ist die Entwicklung äußerst realistischer Konversations-Avatare, die diese Feinheiten einfangen, für die Interaktion von entscheidender Bedeutung.
Zu diesem Zweck haben Forscher von Meta und der University of California eine Methode vorgeschlagen, um realistische virtuelle Menschen basierend auf dem Sprachaudio eines Gesprächs zwischen zwei Personen zu generieren. Es kann eine Vielzahl hochfrequenter Gesten und ausdrucksstarker Gesichtsbewegungen synthetisieren, die eng mit der Sprache synchronisiert sind. Für Körper und Hand nutzen sie die Vorteile eines autoregressiven VQ-basierten Ansatzes und eines Diffusionsmodells. Für Gesichter verwenden sie ein auf Audio basierendes Diffusionsmodell. Die vorhergesagten Gesichts-, Körper- und Handbewegungen werden dann in realistische virtuelle Menschen übertragen. Wir zeigen, dass das Hinzufügen von geführten Gestenbedingungen zum Diffusionsmodell vielfältigere und sinnvollere Konversationsgesten erzeugen kann als frühere Arbeiten.

- Papieradresse: https://huggingface.co/papers/2401.01885
- Projektadresse: https://people.eecs.berkeley.edu/~evonne_ng / project/audio2photoreal/
Die Forscher sagen, dass sie das erste Team sind, das untersucht, wie man realistische Gesichts-, Körper- und Handbewegungen für zwischenmenschliche Gespräche erzeugt. Im Vergleich zu früheren Studien synthetisierten die Forscher realistischere und vielfältigere Aktionen auf der Grundlage von VQ- und Diffusionsmethoden.
Überblick über die Methode
Die Forscher extrahierten latente Ausdruckscodes aus aufgezeichneten Multi-View-Daten, um Gesichter darzustellen, und verwendeten Gelenkwinkel im kinematischen Skelett, um Körperhaltungen darzustellen. Wie in Abbildung 3 dargestellt, besteht dieses System aus zwei generativen Modellen, die Ausdruckscodes und Körperhaltungssequenzen generieren, wenn Audiodaten für Zweipersonengespräche eingegeben werden. Der Ausdruckscode und die Körperhaltungssequenzen können dann Bild für Bild mit dem Neural Avatar Renderer gerendert werden, der aus einer bestimmten Kameraansicht einen vollständig texturierten Avatar mit Gesicht, Körper und Händen generieren kann.
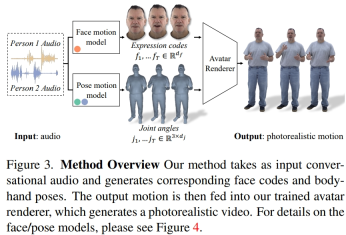
Es ist zu beachten, dass die Dynamik von Körper und Gesicht sehr unterschiedlich ist. Erstens korrelieren Gesichter stark mit Eingabeaudio, insbesondere Lippenbewegungen, während Körper nur schwach mit Sprache korrelieren. Dies führt zu einer komplexeren Vielfalt an Körpergesten in einer bestimmten Spracheingabe. Zweitens folgen Gesichter und Körper jeweils unterschiedlichen zeitlichen Dynamiken, da sie in zwei unterschiedlichen Räumen dargestellt werden. Daher verwendeten die Forscher zwei unabhängige Bewegungsmodelle, um Gesicht und Körper zu simulieren. Auf diese Weise kann sich das Gesichtsmodell auf Gesichtsdetails „fokussieren“, die mit der Sprache übereinstimmen, während sich das Körpermodell mehr auf die Erzeugung vielfältiger, aber sinnvoller Körperbewegungen konzentrieren kann.
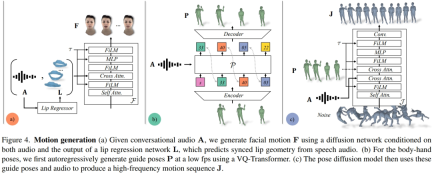
Das Gesichtsbewegungsmodell ist ein Diffusionsmodell, das auf Eingabeaudio und Lippenscheitelpunkten basiert, die von einem vorab trainierten Lippenregressor generiert werden (Abbildung 4a). Für das Bewegungsmodell der Gliedmaßen stellten die Forscher fest, dass die Bewegung, die durch das reine Diffusionsmodell erzeugt wurde, das nur auf Audio bedingt war, nicht vielfältig genug war und in der zeitlichen Abfolge nicht ausreichend koordiniert war. Die Qualität verbesserte sich jedoch, wenn die Forscher unterschiedliche Führungshaltungen verwendeten. Daher teilen sie das Körperbewegungsmodell in zwei Teile auf: Zuerst sagt der autoregressive Audio-Conditioner grobe Führungspositionen bei 1 fp voraus (Abb. 4b), und dann nutzt das Diffusionsmodell diese groben Führungspositionen, um feinkörnige und hochpräzise Positionen auszufüllen. Frequenzbewegungen (Abb. 4c). Weitere Einzelheiten zu den Methodeneinstellungen finden Sie im Originalartikel.
Experimente und Ergebnisse
Die Forscher bewerteten quantitativ die Fähigkeit von Audio2Photoreal, realistische Dialogaktionen auf der Grundlage realer Daten effektiv zu generieren. Es wurden auch Wahrnehmungsbewertungen durchgeführt, um die quantitativen Ergebnisse zu bestätigen und die Eignung von Audio2Photoreal bei der Generierung von Gesten in einem bestimmten Gesprächskontext zu messen. Experimentelle Ergebnisse zeigten, dass die Prüfer empfindlicher auf subtile Gesten reagierten, wenn die Gesten auf einem realistischen Avatar statt auf einem 3D-Netz dargestellt wurden.
Die Forscher verglichen die generierten Ergebnisse dieser Methode mit drei Basismethoden: KNN, SHOW und LDA, basierend auf zufälligen Bewegungssequenzen im Trainingssatz. Es wurden Ablationsexperimente durchgeführt, um die Wirksamkeit jeder Komponente von Audio2Photoreal ohne Audio oder geführte Gesten, ohne geführte Gesten, aber basierend auf Audio, und ohne Audio, aber basierend auf geführten Gesten, zu testen.
Quantitative Ergebnisse
Tabelle 1 zeigt, dass unsere Methode im Vergleich zu früheren Studien den niedrigsten FD-Score bei der Erzeugung von Bewegung mit der höchsten Diversität aufweist. Während Random eine gute Diversität aufweist, die mit GT übereinstimmt, stimmen Zufallssegmente nicht mit der entsprechenden Konversationsdynamik überein, was zu einem hohen FD_g führt.

Abbildung 5 zeigt die Vielfalt der durch unsere Methode generierten Führungsposen. VQ-basiertes Transformer-P-Sampling ermöglicht die Generierung sehr unterschiedlicher Gesten mit demselben Audioeingang.

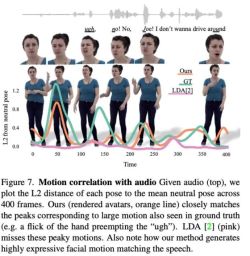
Wie in Abbildung 6 gezeigt, lernt das Diffusionsmodell, dynamische Aktionen zu generieren, wobei die Aktionen besser zum Gesprächsaudio passen.

Abbildung 7 zeigt, dass es der durch LDA erzeugten Bewegung an Vitalität mangelt und sie weniger Bewegung hat. Im Gegensatz dazu stimmen die mit dieser Methode synthetisierten Bewegungsänderungen besser mit der tatsächlichen Situation überein.
Darüber hinaus analysierten die Forscher auch die Genauigkeit dieser Methode bei der Erzeugung von Lippenbewegungen. Wie die Statistiken in Tabelle 2 zeigen, übertrifft Audio2Photoreal die Basismethode SHOW deutlich, ebenso die Leistung nach Entfernung des vortrainierten Lippenregressors in den Ablationsexperimenten. Dieses Design verbessert die Synchronisation der Mundformen beim Sprechen, vermeidet effektiv zufällige Öffnungs- und Schließbewegungen des Mundes, wenn nicht gesprochen wird, ermöglicht dem Modell eine bessere Rekonstruktion der Lippenbewegungen und reduziert gleichzeitig den Fehler der Gesichtsnetzscheitelpunkte (Gitter L2). .

Qualitative Bewertung
Da die Kohärenz von Gesten in Gesprächen schwer zu quantifizieren ist, verwendeten die Forscher qualitative Methoden zur Bewertung. Sie führten zwei Sätze A/B-Tests auf MTurk durch. Konkret baten sie die Gutachter, sich die generierten Ergebnisse unserer Methode und der Basismethode oder das Videopaar unserer Methode und der realen Szene anzusehen und zu bewerten, welches Video in welcher Bewegung vernünftiger aussah.
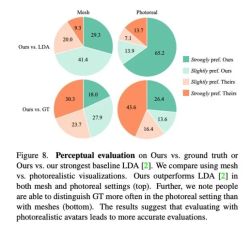
Wie in Abbildung 8 dargestellt, ist diese Methode deutlich besser als die vorherige Basismethode LDA, und etwa 70 % der Rezensenten bevorzugen Audio2Photoreal in Bezug auf Raster und Realismus.
Wie im oberen Diagramm von Abbildung 8 dargestellt, änderte sich die Bewertung dieser Methode durch die Bewerter im Vergleich zu LDA von „eher eher“ zu „mag ich sehr“. Im Vergleich zur realen Situation ergibt sich die gleiche Bewertung. Dennoch bevorzugten die Bewerter das Original gegenüber Audio2Photoreal, wenn es um Realismus ging.
Für weitere technische Details lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonDas Klettern entlang des Netzwerkkabels ist zur Realität geworden, Audio2Photoreal kann durch Dialoge realistische Ausdrücke und Bewegungen erzeugen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Lassen Sie uns tanzen: Strukturierte Bewegung, um unsere menschlichen neuronalen Netze zu optimierenApr 27, 2025 am 11:09 AM
Lassen Sie uns tanzen: Strukturierte Bewegung, um unsere menschlichen neuronalen Netze zu optimierenApr 27, 2025 am 11:09 AMWissenschaftler haben ausführlich menschliche und einfachere neuronale Netzwerke (wie die in C. elegans) untersucht, um ihre Funktionalität zu verstehen. Es stellt sich jedoch eine entscheidende Frage: Wie passen wir unsere eigenen neuronalen Netze an, um neben neuartigen Ai S effektiv zu arbeiten
 Neues Google Leak zeigt Abonnementänderungen für Gemini AIApr 27, 2025 am 11:08 AM
Neues Google Leak zeigt Abonnementänderungen für Gemini AIApr 27, 2025 am 11:08 AMGoogles Gemini Advanced: Neue Abonnements am Horizont Der Zugriff auf Gemini Advanced erfordert derzeit einen Google One AI -Premium -Plan von 19,99 USD/Monat. Ein Bericht von Android Authority hat jedoch auf bevorstehende Änderungen hinweist. Code im neuesten Google P.
 Wie die Beschleunigung der Datenanalyse löst den versteckten Engpass von AIApr 27, 2025 am 11:07 AM
Wie die Beschleunigung der Datenanalyse löst den versteckten Engpass von AIApr 27, 2025 am 11:07 AMTrotz des Hype um fortgeschrittene KI -Funktionen lauert eine erhebliche Herausforderung in den Bereitstellungen von Enterprise AI: Datenverarbeitung Engpässe. Während CEOs KI -Fortschritte feiern, kreischen sich die Ingenieure mit langsamen Abfragen, überladenen Pipelines, a
 Markitdown MCP kann jedes Dokument in Markdowns umwandeln!Apr 27, 2025 am 09:47 AM
Markitdown MCP kann jedes Dokument in Markdowns umwandeln!Apr 27, 2025 am 09:47 AMUm Dokumente zu handeln, geht es nicht mehr nur darum, Dateien in Ihren KI -Projekten zu öffnen, sondern darum, das Chaos in Klarheit zu verwandeln. Dokumente wie PDFs, Powerpoints und Wort überfluten unsere Workflows in jeder Form und Größe. Strukturiert abrufen
 Wie benutze ich Google ADK für Bauagenten? - Analytics VidhyaApr 27, 2025 am 09:42 AM
Wie benutze ich Google ADK für Bauagenten? - Analytics VidhyaApr 27, 2025 am 09:42 AMNutzen Sie die Macht des Google Agent Development Kit (ADK), um intelligente Agenten mit realen Funktionen zu erstellen! Dieses Tutorial führt Sie durch den Bau von Konversationsagenten mit ADK und unterstützt verschiedene Sprachmodelle wie Gemini und GPT. W
 Verwendung von SLM über LLM für eine effektive Problemlösung - Analytics VidhyaApr 27, 2025 am 09:27 AM
Verwendung von SLM über LLM für eine effektive Problemlösung - Analytics VidhyaApr 27, 2025 am 09:27 AMZusammenfassung: SLM (Small Language Model) ist für die Effizienz ausgelegt. Sie sind besser als das große Sprachmodell (LLM) in Ressourcenmangel-, Echtzeit- und Datenschutz-sensitiven Umgebungen. Am besten für fokussierte Aufgaben, insbesondere für Domänenspezifität, -kontrollierbarkeit und Interpretierbarkeit wichtiger als allgemeines Wissen oder Kreativität. SLMs sind kein Ersatz für LLMs, aber sie sind ideal, wenn Präzision, Geschwindigkeit und Kostenwirksamkeit kritisch sind. Technologie hilft uns, mehr mit weniger Ressourcen zu erreichen. Es war schon immer ein Promoter, kein Fahrer. Von der Dampfmaschine -Ära bis zur Internetblase -Ära liegt die Kraft der Technologie in dem Ausmaß, in dem sie uns hilft, Probleme zu lösen. Künstliche Intelligenz (KI) und in jüngerer Zeit generativer KI sind keine Ausnahme
 Wie benutze ich Google Gemini -Modelle für Computer Vision -Aufgaben? - Analytics VidhyaApr 27, 2025 am 09:26 AM
Wie benutze ich Google Gemini -Modelle für Computer Vision -Aufgaben? - Analytics VidhyaApr 27, 2025 am 09:26 AMNutzen Sie die Kraft von Google Gemini für Computer Vision: einen umfassenden Leitfaden Google Gemini, ein führender KI -Chatbot, erweitert seine Fähigkeiten über die Konversation hinaus, um leistungsstarke Funktionen von Computer Visionen zu umfassen. In dieser Anleitung wird beschrieben, wie man verwendet wird
 Gemini 2.0 Flash gegen O4-Mini: Kann Google besser als OpenAI machen?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash gegen O4-Mini: Kann Google besser als OpenAI machen?Apr 27, 2025 am 09:20 AMDie KI-Landschaft von 2025 ist mit der Ankunft von Googles Gemini 2.0 Flash und Openai's O4-Mini elektrisierend. Diese modernen Modelle, die in Abstand von Wochen veröffentlicht wurden, bieten vergleichbare fortschrittliche Funktionen und beeindruckende Benchmark-Ergebnisse. Diese eingehende Vergleiche


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Dreamweaver CS6
Visuelle Webentwicklungstools

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

