
 Technologie-PeripheriegeräteKIGroßes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler
Technologie-PeripheriegeräteKIGroßes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer WissenschaftlerGroßes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler

Die herausragenden Fähigkeiten großer Modelle sind für alle offensichtlich, und wenn sie in Roboter integriert werden, wird erwartet, dass Roboter ein intelligenteres Gehirn haben, was neue Möglichkeiten in den Bereich der Robotik bringt, wie zum Beispiel autonomes Fahren, Heimroboter und Industrieroboter Roboter, Hilfsroboter, Medizinroboter, Feldroboter und Multirobotersysteme.
Vorab trainiertes Large Language Model (LLM), Large Vision-Language Model (VLM), Large Audio-Language Model (ALM) und Large Visual Navigation Model (VNM) können verwendet werden, um verschiedene Probleme im Bereich der Robotik besser zu bewältigen Aufgabe. Die Integration grundlegender Modelle in die Robotik ist ein schnell wachsendes Feld, und die Robotik-Community hat vor kurzem damit begonnen, den Einsatz dieser großen Modelle in Robotikbereichen zu erforschen, die neu geschrieben werden müssen: Wahrnehmung, Vorhersage, Planung und Kontrolle.
Kürzlich hat ein gemeinsames Forschungsteam bestehend aus der Stanford University, der Princeton University, NVIDIA, Google DeepMind und anderen Unternehmen einen Übersichtsbericht veröffentlicht, der die Entwicklung und zukünftige Herausforderungen grundlegender Modelle im Bereich der Robotikforschung zusammenfasst

Papier Adresse: https://arxiv.org/pdf/2312.07843.pdf
Der neu geschriebene Inhalt ist: Papierbibliothek: https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
Unter den Teammitgliedern gibt es viele uns bekannte chinesische Gelehrte, darunter Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu usw.
Grundlegende Modelle, die anhand umfangreicher Daten umfassend vorab trainiert wurden, können nach der Feinabstimmung auf verschiedene nachgelagerte Aufgaben angewendet werden. Diese Grundmodelle haben große Durchbrüche in den Bereichen Seh- und Sprachverarbeitung erzielt, einschließlich verwandter Modelle wie BERT, GPT-3, GPT-4, CLIP, DALL-E und PaLM-E
Vor dem Aufkommen der Grundmodelle für Roboter Herkömmliche Deep-Learning-Modelle werden mithilfe begrenzter Datensätze trainiert, die für verschiedene Aufgaben gesammelt wurden. Im Gegensatz dazu werden Basismodelle unter Verwendung einer breiten Palette unterschiedlicher Daten vorab trainiert und haben Anpassungsfähigkeit, Generalisierung und Gesamtleistung in anderen Bereichen wie der Verarbeitung natürlicher Sprache, Computer Vision und dem Gesundheitswesen bewiesen. Schließlich soll das Basismodell auch im Bereich der Robotik sein Potenzial zeigen. Abbildung 1 zeigt einen Überblick über das Grundmodell im Bereich Robotik.
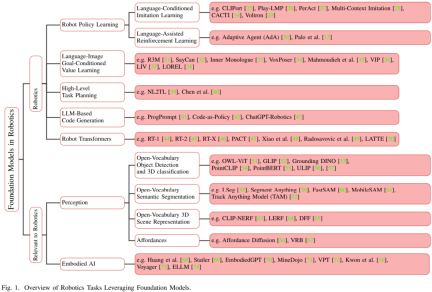
Im Vergleich zu aufgabenspezifischen Modellen hat der Wissenstransfer aus Basismodellen das Potenzial, Trainingszeit und Rechenressourcen zu reduzieren. Insbesondere in robotikbezogenen Bereichen können multimodale Basismodelle multimodale heterogene Daten, die von verschiedenen Sensoren gesammelt wurden, zu kompakten homogenen Darstellungen verschmelzen und ausrichten, die für das Verständnis und Denken von Robotern erforderlich sind. Die erlernten Darstellungen können in jedem Teil des Automatisierungstechnologie-Stacks verwendet werden, einschließlich derjenigen, die neu geschrieben werden müssen: Wahrnehmung, Entscheidungsfindung und Kontrolle.
Darüber hinaus kann das Basismodell auch Zero-Shot-Lernfunktionen bieten, die es dem KI-System ermöglichen, Aufgaben ohne Beispiele oder gezieltes Training auszuführen. Dadurch kann der Roboter das erlernte Wissen auf neue Anwendungsfälle übertragen und so seine Anpassungsfähigkeit und Flexibilität in unstrukturierten Umgebungen verbessern.
Die Integration des Grundmodells in das Robotersystem kann die Fähigkeit des Roboters verbessern, die Umgebung wahrzunehmen und mit der Umgebung zu interagieren. Es ist möglich, den Kontext zu erkennen, der neu geschrieben werden muss: das Wahrnehmungsrobotersystem.
Was beispielsweise neu geschrieben werden muss, ist: Im Bereich der Wahrnehmung können groß angelegte visuelle Sprachmodelle (VLM) die Assoziation zwischen visuellen und Textdaten lernen, um über modalübergreifende Verständnisfähigkeiten zu verfügen und so zu helfen Zero-Shot-Bildklassifizierung, Aufgaben wie Zero-Sample-Objekterkennung und 3D-Klassifizierung. Als weiteres Beispiel kann die Spracherdung (d. h. die Ausrichtung des VLM-Kontextverständnisses auf die reale 3D-Welt) in der 3D-Welt die räumlichen Bedürfnisse des Roboters verbessern, indem Äußerungen mit bestimmten Objekten, Orten oder Aktionen in der 3D-Umgebung verknüpft werden. Neu geschrieben: Wahrnehmungsfähigkeit .
Im Bereich der Entscheidungsfindung oder Planung hat die Forschung herausgefunden, dass LLM und VLM Roboter bei der Spezifizierung von Aufgaben unterstützen können, die eine Planung auf hoher Ebene erfordern.
Durch die Nutzung sprachlicher Hinweise im Zusammenhang mit Bedienung, Navigation und Interaktion können Roboter komplexere Aufgaben ausführen. Beispielsweise scheint das Grundmodell für Roboterpolitik-Lerntechnologien wie Nachahmungslernen und Verstärkungslernen in der Lage zu sein, die Dateneffizienz und das Kontextverständnis zu verbessern. Insbesondere sprachgesteuerte Belohnungen können Agenten des verstärkenden Lernens durch die Bereitstellung geformter Belohnungen anleiten.
Darüber hinaus nutzen Forscher bereits Sprachmodelle, um Feedback für die Politiklerntechnologie zu geben. Einige Studien haben gezeigt, dass die visuellen Fragebeantwortungsfunktionen (VQA) von VLM-Modellen für Anwendungsfälle in der Robotik genutzt werden können. Beispielsweise haben Forscher VLM verwendet, um Fragen zu visuellen Inhalten zu beantworten, um Robotern bei der Erledigung von Aufgaben zu helfen. Darüber hinaus verwenden einige Forscher VLM, um bei der Datenanmerkung zu helfen und Beschreibungsbezeichnungen für visuelle Inhalte zu generieren.
Obwohl das Basismodell über transformative Fähigkeiten in der Seh- und Sprachverarbeitung verfügt, ist die Verallgemeinerung und Feinabstimmung des Basismodells für reale Robotikaufgaben immer noch eine große Herausforderung.
Zu diesen Herausforderungen gehören:
1) Datenmangel: Wie erhält man Daten im Internetmaßstab zur Unterstützung von Aufgaben wie Roboterbetrieb, Positionierung und Navigation und wie nutzt man diese Daten für selbstüberwachtes Training
2) Riesige Unterschiede: Wie man mit der enormen Vielfalt physischer Umgebungen, physischer Roboterplattformen und potenzieller Roboteraufgaben umgeht und gleichzeitig die erforderliche Allgemeingültigkeit des zugrunde liegenden Modells beibehält
3) Das Problem der Quantifizierung der Unsicherheit: Wie man Unsicherheiten auf Instanzebene löst (wie Sprachmehrdeutigkeit oder LLM-Illusion), Unsicherheit auf Verteilungsebene und Verteilungsverschiebungsprobleme, insbesondere das Verteilungsverschiebungsproblem, das durch den Einsatz von Robotern mit geschlossenem Regelkreis verursacht wird.
4) Sicherheitsbewertung: So testen Sie das Robotersystem basierend auf dem Basismodell vor der Bereitstellung, während des Aktualisierungsprozesses und während des Arbeitsprozesses gründlich.
5) Echtzeitleistung: Wie man mit der langen Inferenzzeit einiger Basismodelle umgeht, die den Einsatz von Basismodellen auf Robotern behindert, und wie man die Inferenz von Basismodellen beschleunigt, die für Online-Entscheidungen erforderlich ist. Herstellung.
Dieses Übersichtspapier fasst die aktuelle Verwendung grundlegender Modelle im Bereich der Robotik zusammen. Die Forscher untersuchen aktuelle Methoden, Anwendungen und Herausforderungen und schlagen zukünftige Forschungsrichtungen vor, um diese Herausforderungen anzugehen. Sie wiesen auch auf die potenziellen Risiken hin, die bei der Verwendung des Basismodells zur Erreichung der Roboterautonomie bestehen können. Das Training eines so großen und komplexen Modells ist sehr kostspielig. Auch die Kosten für die Erfassung, Verarbeitung und Verwaltung von Daten können hoch sein. Sein Trainingsprozess erfordert eine große Menge an Rechenressourcen, erfordert den Einsatz dedizierter Hardware wie GPU oder TPU und erfordert außerdem Software und Infrastruktur für das Modelltraining, die alle finanzielle Investitionen erfordern. Zudem ist auch die Einarbeitungszeit des Basismodells sehr lang, was ebenfalls zu hohen Kosten führt. Daher werden diese Modelle häufig als steckbare Module verwendet, d. h. zur Integration des Basismodells in verschiedene Anwendungen ohne umfangreiche Anpassungsarbeiten.
Tabelle 1 enthält Einzelheiten zu häufig verwendeten Basismodellen.
Dieser Abschnitt konzentriert sich auf LLM, visuellen Transformer, VLM, verkörpertes multimodales Sprachmodell und visuelles generatives Modell. Darüber hinaus werden auch verschiedene Trainingsmethoden vorgestellt, die zum Trainieren des Basismodells verwendet werden. Zunächst werden einige verwandte Terminologien und mathematische Kenntnisse vorgestellt, darunter Tokenisierung, generative Modelle, diskriminierende Modelle, Transformatorarchitektur, autoregressive Modelle, maskierte automatische Kodierung und kontrastives Lernen und Diffusionsmodelle.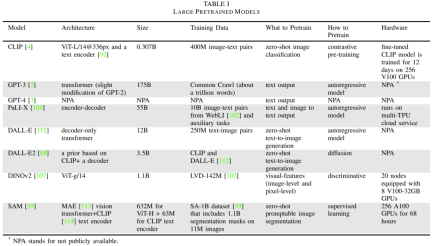 Dann stellen sie Beispiele und historische Hintergründe von Large Language Models (LLM) vor. Anschließend wurden der visuelle Transformer, das multimodale Vision-Sprachmodell (VLM), das verkörperte multimodale Sprachmodell und das visuelle generative Modell hervorgehoben.
Dann stellen sie Beispiele und historische Hintergründe von Large Language Models (LLM) vor. Anschließend wurden der visuelle Transformer, das multimodale Vision-Sprachmodell (VLM), das verkörperte multimodale Sprachmodell und das visuelle generative Modell hervorgehoben.
Dieser Abschnitt konzentriert sich auf die Entscheidungsfindung, Planung und Steuerung von Robotern. In diesem Bereich haben sowohl große Sprachmodelle (LLM) als auch visuelle Sprachmodelle (VLM) das Potenzial, die Fähigkeiten von Robotern zu verbessern. LLM kann beispielsweise den Aufgabenspezifikationsprozess erleichtern, sodass Roboter übergeordnete Anweisungen von Menschen empfangen und interpretieren können.
VLM wird voraussichtlich auch einen Beitrag zu diesem Bereich leisten. VLM zeichnet sich durch die Analyse visueller Daten aus. Damit Roboter fundierte Entscheidungen treffen und komplexe Aufgaben ausführen können, ist visuelles Verständnis von entscheidender Bedeutung. Jetzt können Roboter natürliche Sprachsignale nutzen, um ihre Fähigkeit zur Ausführung von Aufgaben im Zusammenhang mit Manipulation, Navigation und Interaktion zu verbessern. Zielbasiertes visuell-linguistisches Politiklernen (sei es durch Nachahmungslernen oder Verstärkungslernen) wird voraussichtlich durch das Basismodell verbessert. Sprachmodelle können auch Feedback für politische Lerntechniken liefern. Diese Rückkopplungsschleife trägt dazu bei, die Entscheidungsfähigkeit des Roboters kontinuierlich zu verbessern, da der Roboter seine Aktionen basierend auf dem Feedback, das er vom LLM erhält, optimieren kann.
Dieser Abschnitt konzentriert sich auf die Anwendung von LLM und VLM im Bereich der Roboterentscheidungsfindung.
Dieser Abschnitt ist in sechs Teile unterteilt. Im ersten Teil wird das politische Lernen für Entscheidungsfindung und Kontrolle sowie Roboter vorgestellt, einschließlich sprachbasiertes Nachahmungslernen und sprachgestütztes Verstärkungslernen.
Der zweite Teil ist das zielorientierte Erlernen von Sprach-Bild-Werten.
Der dritte Teil stellt die Verwendung großer Sprachmodelle zur Planung von Roboteraufgaben vor. Dazu gehört die Erklärung von Aufgaben durch Sprachanweisungen und die Verwendung von Sprachmodellen zur Generierung von Code für die Aufgabenplanung.
Der vierte Teil ist kontextuelles Lernen (ICL) zur Entscheidungsfindung.
Als nächstes wird Robot Transformers vorgestellt.
Der sechste Teil ist die Roboternavigation und Bedienung der offenen Vokabularbibliothek.
Tabelle 2 enthält einige grundlegende roboterspezifische Modelle, meldet Modellgröße und -architektur, Aufgaben vor dem Training, Inferenzzeit und Hardware-Setup.
Was neu geschrieben werden muss ist: Wahrnehmung
Roboter, die mit der Umgebung interagieren, empfangen sensorische Informationen in verschiedenen Modalitäten, wie zum Beispiel Bilder, Videos, Audio und Sprache. Diese hochdimensionalen Daten sind für Roboter von entscheidender Bedeutung, um ihre Umgebung zu verstehen, zu denken und mit ihr zu interagieren. Einfache Modelle können diese hochdimensionalen Eingaben in abstrakte strukturierte Darstellungen umwandeln, die leicht zu interpretieren und zu manipulieren sind. Insbesondere multimodale Basismodelle ermöglichen es Robotern, Eingaben verschiedener Sinne in eine einheitliche Darstellung zu integrieren, die semantische, räumliche, zeitliche und Erschwinglichkeitsinformationen enthält. Diese multimodalen Modelle erfordern modalübergreifende Interaktionen und erfordern häufig die Ausrichtung von Elementen verschiedener Modalitäten, um Konsistenz und gegenseitige Übereinstimmung sicherzustellen. Bildbeschreibungsaufgaben erfordern beispielsweise die Ausrichtung von Text- und Bilddaten.
Dieser Abschnitt konzentriert sich auf das, was Roboter neu schreiben müssen: eine Reihe von Aufgaben im Zusammenhang mit der Wahrnehmung, die durch die Verwendung grundlegender Modelle zur Ausrichtung der Modalitäten verbessert werden können. Der Schwerpunkt liegt auf Vision und Sprache.
Dieser Abschnitt ist in fünf Teile unterteilt: Zuerst erfolgt die Zielerkennung und 3D-Klassifizierung des offenen Vokabulars, dann die semantische Segmentierung des offenen Vokabulars, dann die 3D-Szene und Zieldarstellung des offenen Vokabulars und dann die erlernte Angebote und schließlich Vorhersagemodelle.
Verkörperte KI
Kürzlich haben einige Studien gezeigt, dass LLM erfolgreich im Bereich der verkörperten KI eingesetzt werden kann, wobei sich „verkörpert“ normalerweise auf die virtuelle Verkörperung im Weltsimulator bezieht und nicht auf einen physischen Roboterkörper.
In diesem Bereich sind einige interessante Frameworks, Datensätze und Modelle entstanden. Besonders hervorzuheben ist die Nutzung des Minecraft-Spiels als Plattform für die Ausbildung verkörperter Agenten. Voyager verwendet beispielsweise GPT-4, um Agenten bei der Erkundung von Minecraft-Umgebungen anzuleiten. Es kann durch kontextbezogenes Eingabeaufforderungsdesign mit GPT-4 interagieren, ohne dass eine Feinabstimmung der Modellparameter von GPT-4 erforderlich ist.
Reinforcement Learning ist eine wichtige Forschungsrichtung im Bereich des Roboterlernens. Forscher versuchen, Basismodelle zu verwenden, um Belohnungsfunktionen zu entwerfen, um Reinforcement Learning zu optimieren.
Damit Roboter eine Planung auf hoher Ebene durchführen können, haben Forscher die Verwendung von Basismodellen untersucht Modelle zur Unterstützung. Darüber hinaus versuchen einige Forscher, auf der Denkkette basierende Methoden zur Argumentation und Handlungsgenerierung auf die verkörperte Intelligenz anzuwenden. Das Team wird auch zukünftige Forschungsrichtungen erkunden, die diese Herausforderungen angehen könnten.
Die erste Herausforderung besteht darin, das Problem der Datenknappheit beim Training von Basismodellen für Roboter zu überwinden. Dazu gehört: 1 Erweiterung des Roboterlernens mithilfe unstrukturierter Spieldaten und unbeschrifteter menschlicher Videos
2
3. Überwinden Sie das Problem des Mangels an 3D-Daten beim Training von 3D-Basismodellen
4 Generieren Sie synthetische Daten durch High-Fidelity-Simulation
5 Die Verwendung von VLM zur Datenerweiterung ist eine effektive Methode .
Die dritte Herausforderung betrifft die Grenzen der multimodalen Darstellung.
Die vierte Herausforderung besteht darin, die Unsicherheit auf verschiedenen Ebenen zu quantifizieren, beispielsweise auf der Instanzebene und der Verteilungsebene. Dazu gehört auch das Problem der Kalibrierung und des Umgangs mit Verteilungsverschiebungen.
Die fünfte Herausforderung umfasst die Sicherheitsbewertung, einschließlich Sicherheitstests vor der Bereitstellung sowie Laufzeitüberwachung und Erkennung von Out-of-Distribution-Situationen.
Die sechste Herausforderung besteht darin, zu entscheiden: ein vorhandenes Basismodell verwenden oder ein neues Basismodell für den Roboter erstellen?
Die siebte Herausforderung beinhaltet eine hohe Variabilität im Roboter-Setup.
Die achte Herausforderung besteht darin, Benchmarking durchzuführen und die Reproduzierbarkeit in einer Roboterumgebung sicherzustellen.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGroßes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Was ist Denkdiagramm in der schnellen IngenieurwesenApr 13, 2025 am 11:53 AM
Was ist Denkdiagramm in der schnellen IngenieurwesenApr 13, 2025 am 11:53 AMEinführung In prompt Engineering bezieht sich „Graph of Denk“ auf einen neuartigen Ansatz, der die Grafik Theorie verwendet, um die Argumentationsprozess von AI zu strukturieren und zu leiten. Im Gegensatz zu herkömmlichen Methoden, bei denen es sich häufig um lineare handelt
 Optimieren Sie die E -Mail -Marketing Ihres Unternehmens mit Genai -AgentenApr 13, 2025 am 11:44 AM
Optimieren Sie die E -Mail -Marketing Ihres Unternehmens mit Genai -AgentenApr 13, 2025 am 11:44 AMEinführung Glückwunsch! Sie führen ein erfolgreiches Geschäft. Über Ihre Webseiten, Social -Media -Kampagnen, Webinare, Konferenzen, kostenlose Ressourcen und andere Quellen sammeln Sie täglich 5000 E -Mail -IDs. Der nächste offensichtliche Schritt ist
 Echtzeit-App-Leistungsüberwachung mit Apache PinotApr 13, 2025 am 11:40 AM
Echtzeit-App-Leistungsüberwachung mit Apache PinotApr 13, 2025 am 11:40 AMEinführung In der heutigen schnelllebigen Softwareentwicklungsumgebung ist die Gewährleistung einer optimalen Anwendungsleistung von entscheidender Bedeutung. Die Überwachung von Echtzeitmetriken wie Antwortzeiten, Fehlerraten und Ressourcenauslastung kann die Hauptstufe unterstützen
 Chatgpt trifft 1 Milliarde Benutzer? 'In nur wenigen Wochen verdoppelt', sagt OpenAI -CEOApr 13, 2025 am 11:23 AM
Chatgpt trifft 1 Milliarde Benutzer? 'In nur wenigen Wochen verdoppelt', sagt OpenAI -CEOApr 13, 2025 am 11:23 AM"Wie viele Benutzer haben Sie?" er stapte. "Ich denke, das letzte Mal, als wir sagten, wächst 500 Millionen wöchentliche Wirkstoffe, und es wächst sehr schnell", antwortete Altman. "Du hast mir gesagt, dass es sich in nur wenigen Wochen verdoppelt hat", fuhr Anderson fort. „Ich habe das Privat gesagt
 Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics VidhyaApr 13, 2025 am 11:20 AM
Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics VidhyaApr 13, 2025 am 11:20 AMEinführung Mistral hat sein erstes multimodales Modell veröffentlicht, nämlich den Pixtral-12b-2409. Dieses Modell basiert auf dem 12 -Milliarden -Parameter von Mistral, NEMO 12b. Was unterscheidet dieses Modell? Es kann jetzt sowohl Bilder als auch Tex aufnehmen
 Agentenrahmen für generative KI -Anwendungen - Analytics VidhyaApr 13, 2025 am 11:13 AM
Agentenrahmen für generative KI -Anwendungen - Analytics VidhyaApr 13, 2025 am 11:13 AMStellen Sie sich vor, Sie hätten einen AS-Assistenten mit KI, der nicht nur auf Ihre Abfragen reagiert, sondern auch autonom Informationen sammelt, Aufgaben ausführt und sogar mehrere Arten von Daten ausführt-Text, Bilder und Code. Klingt futuristisch? In diesem a
 Anwendungen der Generativen KI im FinanzsektorApr 13, 2025 am 11:12 AM
Anwendungen der Generativen KI im FinanzsektorApr 13, 2025 am 11:12 AMEinführung Die Finanzbranche ist der Eckpfeiler der Entwicklung eines Landes, da sie das Wirtschaftswachstum fördert, indem sie effiziente Transaktionen und Kreditverfügbarkeit erleichtert. Die Leichtigkeit, mit der Transaktionen auftreten und Krediten auftreten
 Leitfaden für Online-Lernen und passiv-aggressive AlgorithmenApr 13, 2025 am 11:09 AM
Leitfaden für Online-Lernen und passiv-aggressive AlgorithmenApr 13, 2025 am 11:09 AMEinführung Daten werden mit beispielloser Geschwindigkeit aus Quellen wie Social Media, Finanztransaktionen und E-Commerce-Plattformen generiert. Der Umgang mit diesem kontinuierlichen Informationsstrom ist eine Herausforderung, aber sie bietet eine


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

