
Heim >Technologie-Peripheriegeräte >KI >„Famous Scenes from Huaguo Mountain' hat eine hochauflösende Version, und NTU schlägt ein Video-Super-Resolution-Framework Upscale-A-Video vor
„Famous Scenes from Huaguo Mountain' hat eine hochauflösende Version, und NTU schlägt ein Video-Super-Resolution-Framework Upscale-A-Video vor

- 王林nach vorne
- 2024-01-11 19:57:301245Durchsuche
Diffusionsmodelle haben bemerkenswerte Erfolge bei der Bilderzeugung erzielt, aber es gibt immer noch Herausforderungen bei der Anwendung auf Video-Superauflösung. Die Superauflösung von Videos erfordert Ausgabetreue und zeitliche Konsistenz, was durch die inhärente Stochastik von Diffusionsmodellen erschwert wird. Daher bleibt die effektive Anwendung von Diffusionsmodellen auf Video-Superauflösung eine herausfordernde Aufgabe.
Ein Forschungsteam vom S-Lab der Nanyang Technological University schlug ein textgesteuertes Latentdiffusions-Framework namens Upscale-A-Video für Video-Superauflösung vor. Das Framework gewährleistet zeitliche Konsistenz durch zwei Schlüsselmechanismen. Erstens werden auf lokaler Ebene zeitliche Schichten in U-Net und VAE-Decoder integriert, um die Konsistenz kurzer Sequenzen aufrechtzuerhalten. Zweitens führt das Framework auf globaler Ebene ein flussgesteuertes, wiederkehrendes Latentausbreitungsmodul ein, das Latentsignale in der gesamten Sequenz ohne Training ausbreitet und verschmilzt und so die allgemeine Videostabilität verbessert. Der Vorschlag dieses Frameworks bietet eine neue Lösung für Video-Superauflösung mit besserer zeitlicher Konsistenz und Gesamtstabilität.

Papieradresse: https://arxiv.org/abs/2312.06640
Upscale-A-Video gewinnt durch das Diffusionsparadigma an großer Flexibilität. Es ermöglicht die Verwendung von Textaufforderungen zur Steuerung der Texturerstellung, und die Rauschpegel können angepasst werden, um Wiedergabetreue und Qualität zwischen Wiederherstellung und Generierung auszugleichen. Diese Funktion ermöglicht es der Technologie, Details zu verfeinern und gleichzeitig die Bedeutung des Originalinhalts beizubehalten, was zu präziseren Ergebnissen führt.
Experimentelle Ergebnisse zeigen, dass Upscale-A-Video bestehende Methoden bei synthetischen und realen Benchmarks übertrifft und beeindruckenden visuellen Realismus und zeitliche Konsistenz bietet.
Schauen wir uns zunächst einige konkrete Beispiele an. Mithilfe von Upscale-A-Video gibt es beispielsweise eine hochauflösende Version von „Famous Scenes from Huaguo Mountain“:

Verglichen mit StableSR, Upscale -A-Video macht das Video Die Eichhörnchenhaartextur ist deutlich sichtbar in:

Methodeneinführung
Einige Studien optimieren Bilddiffusionsmodelle, um sie an Videoaufgaben anzupassen, indem sie Strategien zur zeitlichen Konsistenz einführen. Diese Strategien umfassen die folgenden zwei Methoden: Erstens die Feinabstimmung von Videomodellen über zeitliche Schichten wie 3D-Faltung und zeitliche Aufmerksamkeit, um die Videoverarbeitungsleistung zu verbessern. Zweitens werden Zero-Shot-Mechanismen wie Cross-Frame-Aufmerksamkeit und flussgesteuerte Aufmerksamkeit verwendet, um das vorab trainierte Modell abzustimmen und die Leistung bei Videoaufgaben zu verbessern. Die Einführung dieser Methoden ermöglicht es dem Bilddiffusionsmodell, Videoaufgaben besser zu bewältigen und dadurch den Effekt der Videoverarbeitung zu verbessern.
Obwohl diese Lösungen die Videostabilität erheblich verbessern, bestehen immer noch zwei Hauptprobleme:
Aktuelle Methoden, die in U-Net-Funktionen oder latenten Räumen arbeiten, haben Schwierigkeiten, eine niedrige Konsistenz aufrechtzuerhalten, und es bestehen immer noch Probleme wie Texturflimmern.
Bestehende zeitliche Schichten und Aufmerksamkeitsmechanismen können nur kurzen lokalen Eingabesequenzen Beschränkungen auferlegen, was ihre Fähigkeit, globale zeitliche Konsistenz in längeren Videos sicherzustellen, einschränkt.
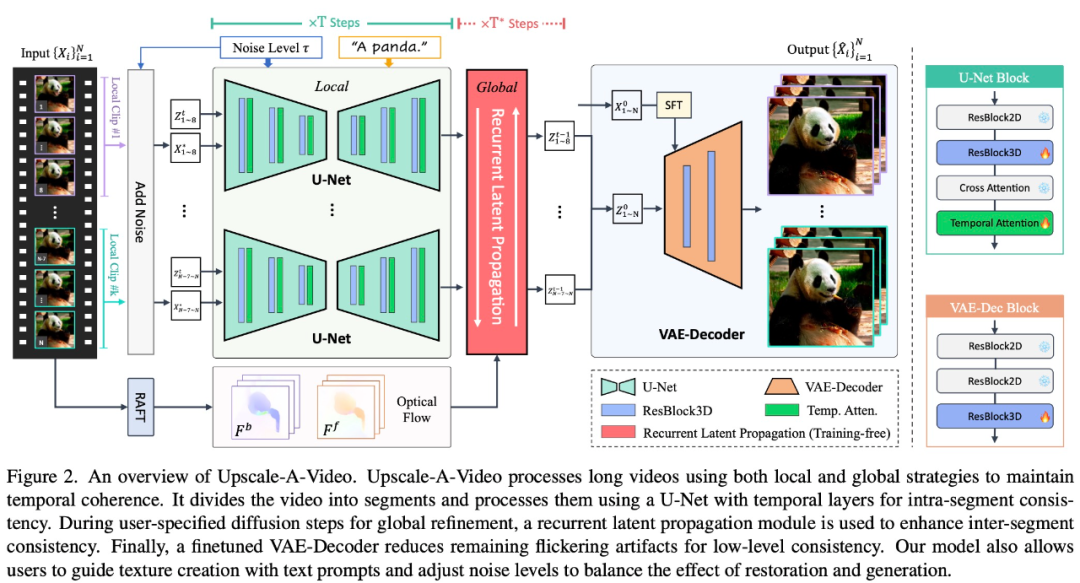
Um diese Probleme zu lösen, wendet Upscale-A-Video eine lokal-globale Strategie an, um die zeitliche Konsistenz bei der Videorekonstruktion aufrechtzuerhalten, wobei der Schwerpunkt auf feinkörniger Textur und Gesamtkonsistenz liegt. Bei lokalen Videoclips untersucht diese Studie die Verwendung zusätzlicher zeitlicher Schichten auf Videodaten, um ein vorab trainiertes Bild ×4-Superauflösungsmodell zu optimieren.
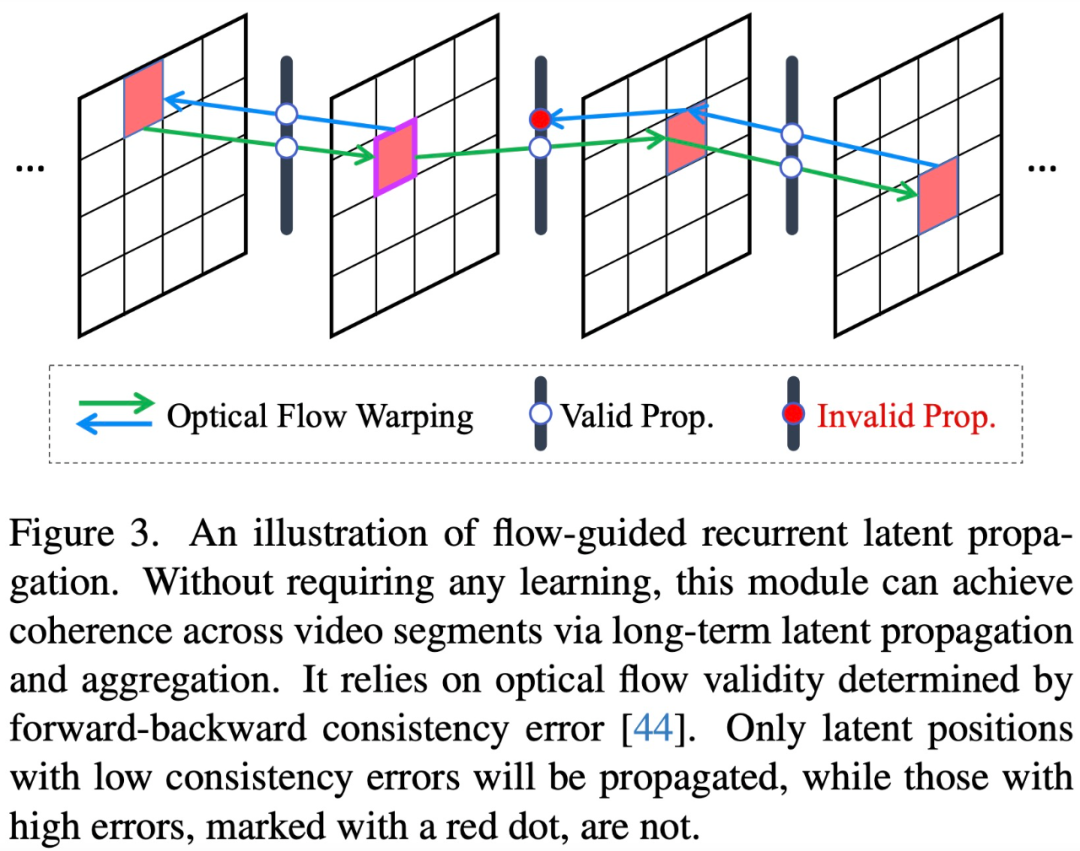
Insbesondere innerhalb des latenten Diffusionsrahmens optimiert diese Studie zunächst U-Net mithilfe integrierter 3D-Faltung und zeitlicher Aufmerksamkeitsschichten und verwendet dann videokonditionierte Eingaben und 3D-Faltung, um den VAE-Decoder abzustimmen. Ersteres sorgt für eine erhebliche strukturelle Stabilität lokaler Sequenzen, und letzteres verbessert die Konsistenz auf niedriger Ebene weiter und reduziert das Flimmern der Textur. Auf globaler Ebene stellt diese Studie ein neuartiges, trainingsfreies, flussgesteuertes, wiederkehrendes Latentausbreitungsmodul vor, das während der Inferenz eine Frame-für-Frame-Ausbreitung und Latentfusion in beide Richtungen durchführt und so die Gesamtstabilität langer Videos fördert.
Das Upscale-A-Video-Modell kann Textaufforderungen als optionale Bedingungen verwenden, um das Modell anzuleiten, realistischere und qualitativ hochwertigere Details zu erzeugen, wie in Abbildung 1 dargestellt.

Upscale-A-Video unterteilt das Video in Segmente und verarbeitet sie mithilfe von U-Net mit zeitlichen Schichten, um eine Konsistenz innerhalb der Segmente zu erreichen. Ein wiederkehrendes latentes Ausbreitungsmodul wird verwendet, um die Konsistenz zwischen Fragmenten während der vom Benutzer angegebenen globalen Verfeinerungsdiffusion zu verbessern. Schließlich reduziert ein fein abgestimmter VAE-Decoder Flimmerartefakte und erreicht eine Konsistenz auf niedrigem Niveau.
Experimentelle Ergebnisse
Upscale-A-Video erreicht SOTA-Leistung bei bestehenden Benchmarks und demonstriert hervorragenden visuellen Realismus und zeitliche Konsistenz.
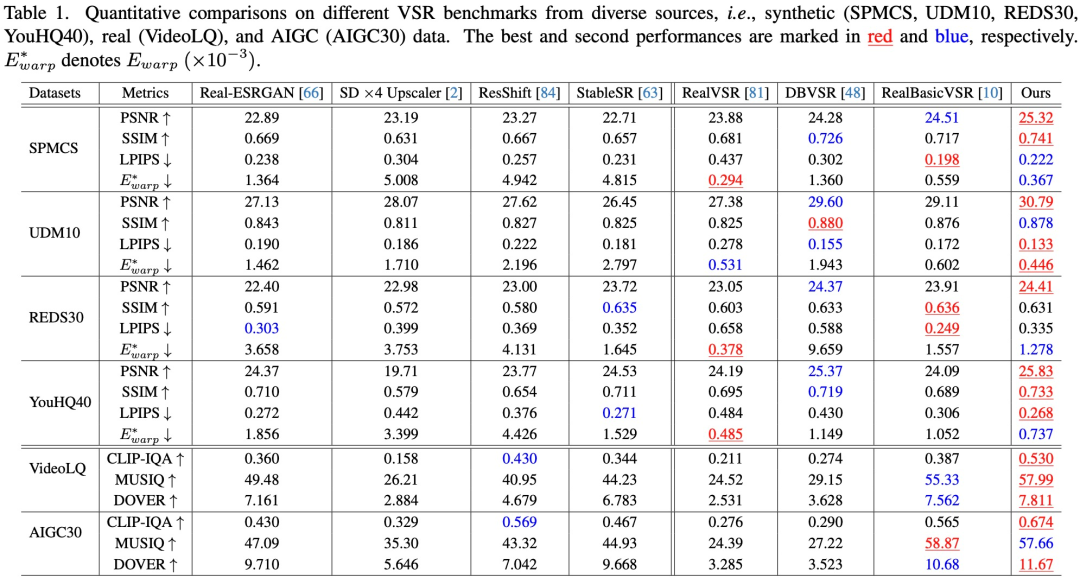
Quantitative Bewertung. Wie in Tabelle 1 gezeigt, erreicht Upscale-A-Video das höchste PSNR in allen vier synthetischen Datensätzen, was auf seine hervorragenden Rekonstruktionsfähigkeiten hinweist.
Qualitative Beurteilung. Die Studie zeigt die visuellen Ergebnisse synthetischer und realer Videos in den Abbildungen 4 und 5. Upscale-A-Video übertrifft bestehende CNN- und diffusionsbasierte Methoden sowohl bei der Artefaktentfernung als auch bei der Detailgenerierung deutlich.


Das obige ist der detaillierte Inhalt von„Famous Scenes from Huaguo Mountain' hat eine hochauflösende Version, und NTU schlägt ein Video-Super-Resolution-Framework Upscale-A-Video vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Schritte zum Erstellen eines neuen vollständigen C++-Projekts in VS2015
- Fragen zum Xiaomi Senior PHP Engineer im Vorstellungsgespräch 2022 (Mock Exam Paper)
- Was sind die Anforderungen an einen guten Front-End-Entwicklungsingenieur?
- Was bedeutet Python Full Stack Engineer?
- Was macht ein Golang-Entwicklungsingenieur?