

 Technologie-PeripheriegeräteKIDie von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!
Technologie-PeripheriegeräteKIDie von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!
In den letzten zwei Jahren ist mit der Öffnung großer Bild- und Textdatensätze wie LAION-5B eine Reihe von Methoden mit erstaunlichen Effekten im Bereich der Bilderzeugung entstanden, wie beispielsweise Stable Diffusion, DALL-E 2, ControlNet und Composer. Das Aufkommen dieser Methoden hat zu großen Durchbrüchen und Fortschritten auf dem Gebiet der Bilderzeugung geführt. Der Bereich der Bilderzeugung hat sich in den letzten zwei Jahren rasant entwickelt.
Allerdings steht die Videogenerierung immer noch vor großen Herausforderungen. Erstens muss die Videogenerierung im Vergleich zur Bildgenerierung höherdimensionale Daten verarbeiten und die zusätzliche Zeitdimension berücksichtigen, was das Problem der Zeitmodellierung mit sich bringt. Um das Lernen der zeitlichen Dynamik voranzutreiben, benötigen wir mehr Video-Text-Paardaten. Allerdings ist die genaue zeitliche Annotation von Videos sehr kostspielig, was die Größe von Videotext-Datensätzen begrenzt. Derzeit enthält der vorhandene WebVid10M-Videodatensatz nur 10,7 Millionen Videotextpaare. Im Vergleich zum LAION-5B-Bilddatensatz ist die Datengröße deutlich unterschiedlich. Dies schränkt die Möglichkeit einer groß angelegten Erweiterung von Videogenerierungsmodellen erheblich ein.
Um die oben genannten Probleme zu lösen, hat das gemeinsame Forschungsteam der Huazhong University of Science and Technology, der Alibaba Group, der Zhejiang University und der Ant Group kürzlich die TF-T2V-Videolösung veröffentlicht:

Paper Adresse: https://arxiv.org/abs/2312.15770
Projekthomepage: https://tf-t2v.github.io/
Quellcode wird bald veröffentlicht: https://github.com /ali-vilab/i2vgen -xl (VGen-Projekt).
Diese Lösung verfolgt einen neuen Ansatz und schlägt die Videogenerierung auf der Grundlage umfangreicher, textfreier, kommentierter Videodaten vor, die eine reichhaltige Bewegungsdynamik erlernen können.
Werfen wir zunächst einen Blick auf den Videogenerierungseffekt von TF-T2V:
Vincent-Videoaufgabe
Prompte Worte: Erzeugen Sie ein Video einer großen frostähnlichen Kreatur im Schnee. überdachtes Land.

Eingabewort: Erstellen Sie ein animiertes Video einer Cartoon-Biene.

Promptwort: Erstelle ein Video mit einem futuristischen Fantasy-Motorrad.

Promptwort: Erstellen Sie ein Video von einem kleinen Jungen, der glücklich lächelt.

Promptwort: Erstellen Sie ein Video von einem alten Mann, der Kopfschmerzen hat.

Kombinierte Videogenerierungsaufgabe
Mit Text und Tiefenkarte oder Text und Skizzenskizze ist TF-T2V in der Lage, steuerbare Videos zu generieren:

Auch verfügbar Auflösung der Videosynthese:
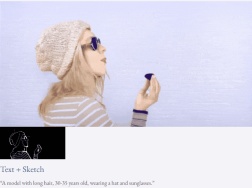
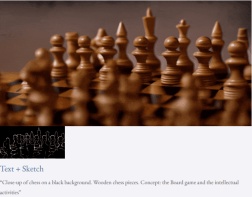

Halbüberwachte Einstellung
Mit der TF-T2V-Methode können in der halbüberwachten Einstellung auch Videos generiert werden, die der Textbeschreibung der Bewegung entsprechen, z. B. „Menschen laufen von rechts nach links.“


Einführung in die Methode
Die Kernidee von TF-T2V besteht darin, das Modell in einen Bewegungszweig und einen Erscheinungszweig zu unterteilen. Der Bewegungszweig wird zur Modellierung der Bewegungsdynamik verwendet Der Erscheinungszweig wird zum Erlernen scheinbarer Informationen verwendet. Diese beiden Zweige werden gemeinsam trainiert und können schließlich eine textgesteuerte Videogenerierung erreichen.
Um die zeitliche Konsistenz generierter Videos zu verbessern, schlug das Autorenteam außerdem einen zeitlichen Konsistenzverlust vor, um die Kontinuität zwischen Videobildern explizit zu lernen.
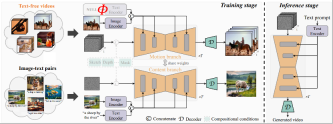
Es ist erwähnenswert, dass TF-T2V ein allgemeines Framework ist, das nicht nur für Vincent-Videoaufgaben, sondern auch für kombinierte Videogenerierungsaufgaben wie Sketch-to-Video, Video-Inpainting und erstes Bild geeignet ist -zu-Video usw.
Spezifische Details und weitere experimentelle Ergebnisse finden Sie im Originalpapier oder auf der Projekthomepage.
Darüber hinaus verwendete das Autorenteam auch TF-T2V als Lehrermodell und verwendete eine konsistente Destillationstechnologie, um das VideoLCM-Modell zu erhalten:

Papieradresse: https://arxiv.org/abs/ 2312.09109
Projekthomepage: https://tf-t2v.github.io/
Quellcode wird bald veröffentlicht: https://github.com/ali-vilab/i2vgen-xl (VGen-Projekt) .
Im Gegensatz zur vorherigen Videogenerierungsmethode, die etwa 50 DDIM-Entrauschungsschritte erforderte, kann die auf TF-T2V basierende VideoLCM-Methode High-Fidelity-Videos mit nur etwa 4 Inferenzentrauschungsschritten erzeugen, was die Effizienz der Videogenerierung erheblich verbessert. Effizienz.
Werfen wir einen Blick auf die Ergebnisse der 4-stufigen Rauschunterdrückungsinferenz von VideoLCM:
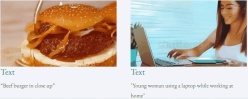

Für spezifische Details und weitere experimentelle Ergebnisse lesen Sie bitte das Originalpapier von VideoLCM oder das Projekt Startseite.
Alles in allem bringt die TF-T2V-Lösung neue Ideen in den Bereich der Videogenerierung und überwindet die Herausforderungen, die durch Probleme mit der Datensatzgröße und der Kennzeichnung entstehen. TF-T2V nutzt große, textfreie Anmerkungsvideodaten und ist in der Lage, qualitativ hochwertige Videos zu generieren, und kann für eine Vielzahl von Videogenerierungsaufgaben eingesetzt werden. Diese Innovation wird die Entwicklung der Videoerzeugungstechnologie vorantreiben und umfassendere Anwendungsszenarien und Geschäftsmöglichkeiten für alle Lebensbereiche eröffnen.
Das obige ist der detaillierte Inhalt vonDie von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Die meisten verwendeten 10 Power BI -Diagramme - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Die meisten verwendeten 10 Power BI -Diagramme - Analytics VidhyaApr 16, 2025 pm 12:05 PMNutzung der Leistung der Datenvisualisierung mit Microsoft Power BI -Diagrammen In der heutigen datengesteuerten Welt ist es entscheidend, komplexe Informationen effektiv mit nicht-technischem Publikum zu kommunizieren. Die Datenvisualisierung schließt diese Lücke und transformiert Rohdaten i
 Expertensysteme in KIApr 16, 2025 pm 12:00 PM
Expertensysteme in KIApr 16, 2025 pm 12:00 PMExpertensysteme: Ein tiefes Eintauchen in die Entscheidungsfunktion der KI Stellen Sie sich vor, Zugang zu Expertenberatung zu irgendetwas, von medizinischen Diagnosen bis hin zur Finanzplanung. Das ist die Kraft von Expertensystemen in der künstlichen Intelligenz. Diese Systeme imitieren den Profi
 Drei der besten Vibe -Codierer brechen diese KI -Revolution im Code aufApr 16, 2025 am 11:58 AM
Drei der besten Vibe -Codierer brechen diese KI -Revolution im Code aufApr 16, 2025 am 11:58 AMZunächst ist es offensichtlich, dass dies schnell passiert. Verschiedene Unternehmen sprechen über die Proportionen ihres Code, die derzeit von KI verfasst wurden, und diese nehmen mit einem schnellen Clip zu. Es gibt bereits viel Arbeitsplatzverschiebung
 Runway Ai's Gen-4: Wie kann eine Montage über Absurd hinausgehenApr 16, 2025 am 11:45 AM
Runway Ai's Gen-4: Wie kann eine Montage über Absurd hinausgehenApr 16, 2025 am 11:45 AMDie Filmindustrie befindet sich neben allen kreativen Sektoren vom digitalen Marketing bis hin zu sozialen Medien an einer technologischen Kreuzung. Als künstliche Intelligenz beginnt, jeden Aspekt des visuellen Geschichtenerzählens umzugestiegen und die Landschaft der Unterhaltung zu verändern
 Wie kann man sich 5 Tage lang anmelden. - Analytics VidhyaApr 16, 2025 am 11:43 AM
Wie kann man sich 5 Tage lang anmelden. - Analytics VidhyaApr 16, 2025 am 11:43 AMDer kostenlose KI/ML -Online -Kurs von ISRO: Ein Tor zu Geospatial Technology Innovation Die Indian Space Research Organization (ISRO) bietet durch ihr indisches Institut für Fernerkundung (IIRS) eine fantastische Gelegenheit für Studenten und Fachkräfte
 Lokale Suchalgorithmen in KIApr 16, 2025 am 11:40 AM
Lokale Suchalgorithmen in KIApr 16, 2025 am 11:40 AMLokale Suchalgorithmen: Ein umfassender Leitfaden Die Planung eines groß angelegten Ereignisses erfordert eine effiziente Verteilung der Arbeitsbelastung. Wenn herkömmliche Ansätze scheitern, bieten lokale Suchalgorithmen eine leistungsstarke Lösung. In diesem Artikel wird Hill Climbing und Simul untersucht
 OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und KosteneffizienzApr 16, 2025 am 11:37 AM
OpenAI-Verschiebungen Fokus mit GPT-4.1, priorisiert die Codierung und KosteneffizienzApr 16, 2025 am 11:37 AMDie Veröffentlichung umfasst drei verschiedene Modelle, GPT-4.1, GPT-4.1 Mini und GPT-4.1-Nano, die einen Zug zu aufgabenspezifischen Optimierungen innerhalb der Landschaft des Großsprachenmodells signalisieren. Diese Modelle ersetzen nicht sofort benutzergerichtete Schnittstellen wie
 Die Eingabeaufforderung: Chatgpt generiert gefälschte PässeApr 16, 2025 am 11:35 AM
Die Eingabeaufforderung: Chatgpt generiert gefälschte PässeApr 16, 2025 am 11:35 AMDer Chip Giant Nvidia sagte am Montag, es werde zum ersten Mal in den USA die Herstellung von KI -Supercomputern - Maschinen mit der Verarbeitung reichlicher Daten herstellen und komplexe Algorithmen ausführen. Die Ankündigung erfolgt nach Präsident Trump SI


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver Mac
Visuelle Webentwicklungstools

