

 Technologie-PeripheriegeräteKINeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste domänenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich
Technologie-PeripheriegeräteKINeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste domänenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich
Oben geschrieben und die persönliche Zusammenfassung des Autors
Die Erkennung aus der Vogelperspektive (BEV) ist eine Erkennungsmethode, die mehrere Surround-View-Kameras zusammenführt. Die meisten aktuellen Algorithmen werden anhand desselben Datensatzes trainiert und ausgewertet, was dazu führt, dass diese Algorithmen an die unveränderten internen Parameter der Kamera (Kameratyp) und externen Parameter (Kameraplatzierung) überpassen. In diesem Artikel wird ein BEV-Erkennungsframework vorgeschlagen, das auf implizitem Rendering basiert und das Problem der Objekterkennung in unbekannten Domänen lösen kann. Das Framework verwendet implizites Rendering, um die Beziehung zwischen der 3D-Position des Objekts und der perspektivischen Position einer einzelnen Ansicht herzustellen, die zur Korrektur der perspektivischen Verzerrung verwendet werden kann. Mit dieser Methode werden erhebliche Leistungsverbesserungen bei der Domänengeneralisierung (DG) und der unüberwachten Domänenanpassung (UDA) erzielt. Diese Methode ist der erste Versuch, ausschließlich virtuelle Datensätze für das Training und die Bewertung der BEV-Erkennung in realen Szenarien zu verwenden, wodurch die Grenzen zwischen virtuell und real durchbrochen werden können, um Tests im geschlossenen Regelkreis durchzuführen.
- Papier-Link: https://arxiv.org/pdf/2310.11346.pdf
- Code-Link: https://github.com/EnVision-Research/Generalizable-BEV

BEV-Erkennungsdomäne allgemein Problemhintergrund
Multikameraerkennung bezieht sich auf die Aufgabe, mithilfe mehrerer Kameras Objekte im dreidimensionalen Raum zu erkennen und zu lokalisieren. Durch die Kombination von Informationen aus verschiedenen Blickwinkeln kann die 3D-Objekterkennung mit mehreren Kameras genauere und robustere Objekterkennungsergebnisse liefern, insbesondere in Situationen, in denen Ziele aus bestimmten Blickwinkeln möglicherweise verdeckt oder teilweise sichtbar sind. In den letzten Jahren hat die Bird-Eye-View-Methode (BEV) große Aufmerksamkeit bei Erkennungsaufgaben mit mehreren Kameras erhalten. Obwohl diese Methoden bei der Informationsfusion mit mehreren Kameras Vorteile bieten, kann die Leistung dieser Methoden erheblich beeinträchtigt werden, wenn sich die Testumgebung erheblich von der Trainingsumgebung unterscheidet.
Derzeit werden die meisten BEV-Erkennungsalgorithmen anhand desselben Datensatzes trainiert und ausgewertet, was dazu führt, dass diese Algorithmen zu empfindlich auf Änderungen interner und externer Kameraparameter und städtischer Straßenbedingungen reagieren, was zu schwerwiegenden Überanpassungsproblemen führt. In praktischen Anwendungen müssen BEV-Erkennungsalgorithmen jedoch häufig an verschiedene neue Modelle und neue Kameras angepasst werden, was zum Versagen dieser Algorithmen führt. Daher ist es wichtig, die Generalisierbarkeit der BEV-Erkennung zu untersuchen. Darüber hinaus ist die Closed-Loop-Simulation auch für das autonome Fahren sehr wichtig, kann jedoch derzeit nur in virtuellen Motoren wie Carla ausgewertet werden. Daher ist es notwendig, das Problem der Domänenunterschiede zwischen virtuellen Engines und realen Szenen zu lösen. Domänengeneralisierung (DG) und unbeaufsichtigte Domänenanpassung (UDA) sind zwei vielversprechende Methoden, um Verteilungsrichtungsverschiebungen zu mildern. DG-Methoden entkoppeln und eliminieren häufig domänenspezifische Merkmale und verbessern so die Generalisierungsleistung in unsichtbaren Domänen. Für UDA mildern neuere Methoden die Domänenverschiebung durch die Generierung von Pseudobezeichnungen oder die Ausrichtung latenter Merkmalsverteilungen. Allerdings ist das Erlernen von aussichts- und umgebungsunabhängigen Funktionen für die reine visuelle Wahrnehmung ohne die Verwendung von Daten aus verschiedenen Blickwinkeln, Kameraparametern und Umgebungen eine große Herausforderung.
Beobachtungen zeigen, dass die 2D-Erkennung aus einer einzigen Perspektive (Kameraebene) tendenziell stärkere Generalisierungsfähigkeiten aufweist als die 3D-Objekterkennung aus mehreren Perspektiven, wie in der Abbildung dargestellt. Einige Studien haben die Integration der 2D-Erkennung in die BEV-Erkennung untersucht, beispielsweise die Fusion von 2D-Informationen in 3D-Detektoren oder die Herstellung einer 2D-3D-Konsistenz. Die 2D-Informationsfusion ist eher eine lernbasierte Methode als eine Mechanismusmodellierungsmethode und wird immer noch stark von der Domänenmigration beeinträchtigt. Bestehende 2D-3D-Konsistenzmethoden projizieren die 3D-Ergebnisse auf eine zweidimensionale Ebene und stellen Konsistenz her. Diese Einschränkung kann die semantischen Informationen in der Zieldomäne schädigen, anstatt die geometrischen Informationen der Zieldomäne zu ändern. Darüber hinaus macht dieser 2D-3D-Konsistenzansatz einen einheitlichen Ansatz für alle Erkennungsköpfe zu einer Herausforderung.
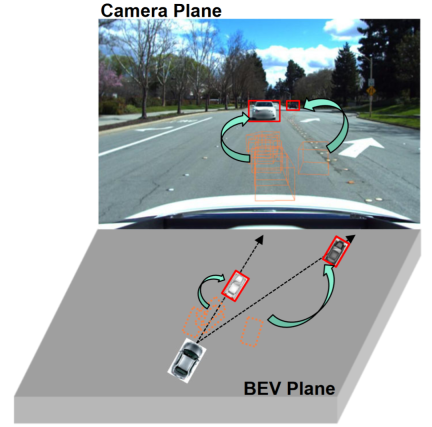
Dieser Artikel schlägt ein verallgemeinertes BEV-Erkennungsframework vor, das auf Perspektivdebiasing basiert. Dieses Framework kann dem Modell nicht nur dabei helfen, Perspektiven und kontextinvariante Merkmale in der Quelldomäne zu lernen. Zweidimensionale Detektoren können auch verwendet werden, um falsche geometrische Merkmale im Zielbereich weiter zu korrigieren.
- Dieses Papier ist der erste Versuch, die unbeaufsichtigte Domänenanpassung bei der BEV-Erkennung zu untersuchen und einen Benchmark festzulegen. Sowohl mit UDA- als auch mit DG-Protokollen werden hochmoderne Ergebnisse erzielt.
- In diesem Artikel wird erstmals das Training an einem virtuellen Motor ohne reale Szenenanmerkungen untersucht, um reale BEV-Erkennungsaufgaben zu erfüllen.
Problemdefinition
Die Forschung konzentriert sich hauptsächlich auf die Verbesserung der Generalisierung der BEV-Erkennung. Um dieses Ziel zu erreichen, untersucht dieses Papier zwei Protokolle mit weit verbreiteter praktischer Anwendung, nämlich Domänengeneralisierung (DG) und unüberwachte Domänenanpassung (UDA):
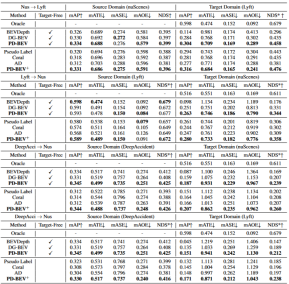
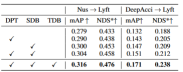
Durch BEV-Generalisierung (DG) erkannte Domänen:Trainieren Sie einen BEV-Erkennungsalgorithmus in einem vorhandenen Datensatz (Quelldomäne), um die Erkennungsleistung in einem unbekannten Datensatz (Zieldomäne) zu verbessern. Beispielsweise kann das Training eines BEV-Erkennungsmodells in einem bestimmten Fahrzeug oder Szenario direkt auf eine Vielzahl unterschiedlicher Fahrzeuge und Szenarien übertragen werden. Unüberwachte Domänenanpassung (UDA) für die BEV-Erkennung: Trainieren Sie einen BEV-Erkennungsalgorithmus anhand eines vorhandenen Datensatzes (Quelldomäne) und verwenden Sie unbeschriftete Daten in der Zieldomäne, um die Erkennungsleistung zu verbessern. Beispielsweise kann in einem neuen Fahrzeug oder in einer neuen Stadt allein das Sammeln einiger unbeaufsichtigter Daten die Leistung des Modells im neuen Fahrzeug und in der neuen Umgebung verbessern. Es ist erwähnenswert, dass der einzige Unterschied zwischen DG und UDA darin besteht, ob unbeschriftete Daten der Zieldomäne verwendet werden können. Um das unbekannte L=[x,y,z] des Objekts zu erkennen, bestehen die meisten BEV-Erkennungen aus zwei Schlüsselteilen: (1) Erhalten Sie Bildmerkmale aus verschiedenen Betrachtungswinkeln; 2) Fusion dieser Bilder. Merkmale werden in den BEV-Raum übertragen und das endgültige Vorhersageergebnis wird erhalten: Die obige Formel beschreibt, dass die Domänenabweichung aus der Phase der Merkmalsextraktion oder der Phase der BEV-Fusion stammen kann. Dann wurde dieser Artikel im Anhang vorangetrieben und die Betrachtungswinkelabweichung des endgültigen 3D-Vorhersageergebnisses projiziert auf das 2D-Ergebnis wie folgt erhalten: wobei k_u, b_u, k_v und b_v mit dem Domänenoffset des BEV-Encoders zusammenhängen, d (u, v) ist die endgültige vorhergesagte Tiefeninformation des Modells. c_u und c_v stellen die Koordinaten des optischen Zentrums der Kamera auf der UV-Bildebene dar. Die obige Gleichung liefert mehrere wichtige Folgerungen: (1) Das Vorhandensein eines endgültigen Positionsversatzes führt zu einer perspektivischen Verzerrung, was zeigt, dass die Optimierung der perspektivischen Verzerrung dazu beitragen kann, den Domänenversatz zu verringern. (2) Sogar die Position des Punktes auf dem optischen Mittelstrahl der Kamera in der Einzelansicht-Bildebene verschiebt sich. Intuitiv ändert die Domänenverschiebung die Position von BEV-Features, was auf eine Überanpassung aufgrund begrenzter Trainingsdaten-Ansichtspunkte und Kameraparameter zurückzuführen ist. Um dieses Problem zu lösen, ist es wichtig, neue Ansichtsbilder von BEV-Funktionen erneut zu rendern, damit das Netzwerk ansichts- und umgebungsunabhängige Funktionen lernen kann. Vor diesem Hintergrund zielt diese Forschung darauf ab, die perspektivische Abweichung im Zusammenhang mit verschiedenen Rendering-Standpunkten zu lösen, um die Generalisierungsfähigkeit des Modells zu verbessern. Detaillierte Erläuterung des PD-BEV-Algorithmus. PD-BEV ist in drei Teile unterteilt: Semantik Rendering, Quelldomänenentfernungs-Bias und Zieldomänen-Debiasing sind in Abbildung 1 dargestellt. Semantisches Rendering erläutert, wie durch BEV-Funktionen die perspektivische Beziehung zwischen 2D und 3D hergestellt wird. Beim Debiasing der Quelldomäne wird beschrieben, wie die Fähigkeiten zur Modellgeneralisierung durch semantisches Rendering in der Quelldomäne verbessert werden können. Zieldomänen-Debiasing beschreibt die Verwendung unbeschrifteter Daten in der Zieldomäne, um die Fähigkeiten zur Modellgeneralisierung durch semantisches Rendering zu verbessern. Semantisches Rendering Um die Generalisierungsleistung des Modells zu verbessern, müssen in der Quelldomäne mehrere wichtige Punkte verbessert werden. Erstens können die Heatmap und die Eigenschaften der neuen gerenderten Ansicht mithilfe der 3D-Box der Quelldomäne überwacht werden, um perspektivische Verzerrungen zu reduzieren. Zweitens können normalisierte Tiefeninformationen verwendet werden, um Bildkodierern dabei zu helfen, geometrische Informationen besser zu lernen. Diese Verbesserungen werden dazu beitragen, die Generalisierungsleistung des Modells zu verbessern. Durch diesen Vorgang kann die Überanpassung interner und externer Parameter der Kamera reduziert und die Robustheit gegenüber neuen Perspektiven verbessert werden. Es ist erwähnenswert, dass in diesem Artikel das überwachte Lernen von RGB-Bildern in Wärmekarten von Objektzentren umgewandelt wird, um die Mängel des Mangels an neuer perspektivischer RGB-Überwachung im Bereich des unbemannten Fahrens zu vermeiden. Geometrische Überwachung: Die Bereitstellung expliziter Tiefeninformationen kann effektiv sein Verbessern Sie die Leistung der 3D-Objekterkennung mit mehreren Kameras. Die Tiefe der Netzwerkvorhersagen tendiert jedoch dazu, die intrinsischen Parameter zu stark anzupassen. Daher basiert dieser Artikel auf einem virtuellen Tiefenansatz: wobei BCE() den binären Kreuzentropieverlust darstellt und D_{pre} die vorhergesagte Tiefe von DepthNet darstellt. f_u und f_v sind die u- bzw. v-Brennweiten der Bildebene, und U ist eine Konstante. Es ist erwähnenswert, dass es sich bei der Tiefe hier um die Tiefeninformationen im Vordergrund handelt, die durch die Verwendung von 3D-Boxen anstelle von Punktwolken bereitgestellt werden. Auf diese Weise konzentriert sich DepthNet eher auf die Tiefe von Vordergrundobjekten. Schließlich wird die virtuelle Tiefe wieder in die tatsächliche Tiefe umgewandelt, wenn die semantischen Merkmale mithilfe der tatsächlichen Tiefeninformationen auf die BEV-Ebene angehoben werden. Debiasing der Zieldomäne In der Zieldomäne gibt es keine Beschriftung, daher kann die 3D-Box-Überwachung nicht zur Verbesserung der Generalisierungsfähigkeit des Modells verwendet werden. In diesem Artikel wird daher erläutert, dass 2D-Erkennungsergebnisse robuster sind als 3D-Ergebnisse. Daher verwendet dieser Artikel vorab trainierte 2D-Detektoren im Quellbereich zur Überwachung der gerenderten Perspektive und verwendet außerdem den Pseudo-Label-Mechanismus: Dieser Vorgang kann die genaue 2D-Erkennung effektiv nutzen, um die Vordergrundzielposition im BEV-Raum zu korrigieren, was eine unbeaufsichtigte Regularisierung der Zieldomäne darstellt. Um die Korrekturfähigkeit der 2D-Vorhersage weiter zu verbessern, wird eine Pseudomethode verwendet, um die Zuverlässigkeit der vorhergesagten Wärmekarte zu erhöhen. Dieses Papier liefert mathematische Beweise in 3.2 und ergänzende Materialien, um die Ursache von 2D-Projektionsfehlern in 3D-Ergebnissen zu erklären. Es wird auch erklärt, warum Voreingenommenheit auf diese Weise beseitigt werden kann. Einzelheiten finden Sie im Originalpapier. Obwohl in diesem Artikel einige Netzwerke hinzugefügt wurden, um das Training zu erleichtern, sind diese Netzwerke während der Inferenz nicht erforderlich. Mit anderen Worten, unsere Methode ist auf Situationen anwendbar, in denen die meisten BEV-Erkennungsmethoden perspektivinvariante Merkmale lernen. Um die Wirksamkeit unseres Frameworks zu testen, verwenden wir BEVDepth zur Bewertung. Der ursprüngliche Verlust von BEVDepth wird in der Quelldomäne als Hauptüberwachung für die 3D-Erkennung verwendet. Zusammenfassend ist der endgültige Verlust des Algorithmus: Tabelle 1 zeigt den Vergleich der Auswirkungen verschiedener Methoden unter den Protokollen Domänengeneralisierung (DG) und unbeaufsichtigte Domänenanpassung (UDA). Unter diesen repräsentiert Target-Free das DG-Protokoll, und Pseudo Label, Coral und AD sind einige gängige UDA-Methoden. Wie aus der Grafik ersichtlich ist, erzielen diese Methoden allesamt deutliche Verbesserungen im Zielbereich. Dies legt nahe, dass semantisches Rendering als Brücke dient, um das Erlernen perspektivinvarianter Merkmale gegenüber Domänenverschiebungen zu unterstützen. Darüber hinaus beeinträchtigen diese Methoden nicht die Leistung der Quelldomäne und bieten in den meisten Fällen sogar einige Verbesserungen. Es sollte insbesondere erwähnt werden, dass DeepAccident auf der Grundlage der virtuellen Carla-Engine entwickelt wurde. Nach dem Training mit DeepAccident hat der Algorithmus zufriedenstellende Generalisierungsfähigkeiten erreicht. Darüber hinaus wurden andere BEV-Erkennungsmethoden getestet, deren Generalisierungsleistung jedoch ohne spezielles Design sehr schlecht ist. Um die Fähigkeit zur Nutzung unbeaufsichtigter Datensätze in der Zieldomäne weiter zu überprüfen, wurde außerdem ein UDA-Benchmark erstellt und UDA-Methoden (einschließlich Pseudo Label, Coral und AD) auf DG-BEV angewendet. Experimente zeigen, dass diese Methoden erhebliche Leistungsverbesserungen mit sich bringen. Beim impliziten Rendering werden 2D-Detektoren mit besserer Generalisierungsleistung voll ausgenutzt, um die falschen geometrischen Informationen von 3D-Detektoren zu korrigieren. Darüber hinaus wurde festgestellt, dass die meisten Algorithmen dazu neigen, die Leistung der Quelldomäne zu beeinträchtigen, während unsere Methode relativ mild ist. Es ist erwähnenswert, dass AD und Coral beim Übergang von virtuellen zu realen Datensätzen deutliche Verbesserungen zeigen, in realen Tests jedoch Leistungseinbußen zeigen. Dies liegt daran, dass diese beiden Algorithmen für die Verarbeitung von Stiländerungen konzipiert sind, in Szenen mit kleinen Stiländerungen jedoch möglicherweise semantische Informationen zerstören. Der Pseudo-Label-Algorithmus kann die Generalisierungsleistung des Modells verbessern, indem er das Vertrauen in einige relativ gute Zieldomänen erhöht. Eine blinde Erhöhung des Vertrauens in die Zieldomäne führt jedoch tatsächlich zu einer Verschlechterung des Modells. Die experimentellen Ergebnisse beweisen, dass dieser Algorithmus eine signifikante Leistungsverbesserung in DG und UDA erzielt hat. Die experimentellen Ergebnisse der Ablation für drei Schlüsselkomponenten sind in Tabelle 2 dargestellt: 2D-Detektor-Pre-Training (DPT), Source Domain Removal Biasing (SDB) und Target Domain Debiasing (TDB). Die experimentellen Ergebnisse zeigen, dass jede Komponente verbessert wurde, wobei SDB und TDB relativ signifikante Auswirkungen zeigen Tabelle 3 zeigt, dass der Algorithmus auf die Algorithmen BEVFormer und FB-OCC migriert werden kann. Da dieser Algorithmus nur zusätzliche Operationen an Bildfunktionen und BEV-Funktionen erfordert, kann er Algorithmen mit BEV-Funktionen verbessern. Abbildung 5 zeigt die erkannten unbeschrifteten Objekte. Die erste Zeile ist das 3D-Feld des Etiketts und die zweite Zeile ist das Erkennungsergebnis des Algorithmus. Blaue Kästchen zeigen an, dass der Algorithmus einige unbeschriftete Kästchen erkennen kann. Dies zeigt, dass die Methode sogar unbeschriftete Proben im Zielbereich erkennen kann, beispielsweise zu weit entfernte Fahrzeuge oder in Gebäuden auf beiden Straßenseiten. In diesem Artikel wird ein universelles 3D-Objekterkennungsframework mit mehreren Kameras vorgeschlagen, das auf perspektivischer Depolarisation basiert und das Objekterkennungsproblem in unbekannten Feldern lösen kann. Das Framework erreicht eine konsistente und genaue Erkennung, indem es 3D-Erkennungsergebnisse auf eine 2D-Kameraebene projiziert und perspektivische Verzerrungen korrigiert. Darüber hinaus führt das Framework auch eine Strategie zur Perspektivdebiasierung ein, um die Robustheit des Modells durch die Darstellung von Bildern aus verschiedenen Perspektiven zu verbessern. Experimentelle Ergebnisse zeigen, dass diese Methode erhebliche Leistungsverbesserungen bei der Domänengeneralisierung und der unbeaufsichtigten Domänenanpassung erzielt. Darüber hinaus kann diese Methode auch an virtuellen Datensätzen trainiert werden, ohne dass eine Anmerkung zu realen Szenen erforderlich ist, was Komfort für Echtzeitanwendungen und den Einsatz in großem Maßstab bietet. Diese Highlights veranschaulichen die Herausforderungen und das Potenzial der Methode bei der Lösung der 3D-Objekterkennung mit mehreren Kameras. In diesem Artikel wird versucht, die Ideen von Nerf zu nutzen, um die Generalisierungsfähigkeit von BEV zu verbessern, und es können auch gekennzeichnete Quelldomänendaten und unbeschriftete Zieldomänendaten verwendet werden. Darüber hinaus wurde das experimentelle Paradigma von Sim2Real ausprobiert, das potenziellen Wert für das autonome Fahren im geschlossenen Regelkreis hat. Sowohl qualitativ als auch quantitativ gibt es gute Ergebnisse, und der Open-Source-Code ist einen Blick wert Originallink: https://mp.weixin.qq.com/s/GRLu_JW6qZ_nQ9sLiE0p2gBetrachtungswinkelabweichungsdefinition
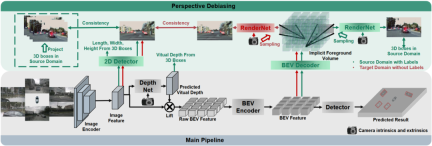 Da viele Algorithmen das BEV-Volumen in zweidimensionale Merkmale komprimieren, verwenden wir zunächst den BEV-Decoder, um die BEV-Merkmale in ein Volumen umzuwandeln:
Da viele Algorithmen das BEV-Volumen in zweidimensionale Merkmale komprimieren, verwenden wir zunächst den BEV-Decoder, um die BEV-Merkmale in ein Volumen umzuwandeln: Die obige Formel ist eigentlich die BEV-Ebene Zur Verbesserung wurde eine Höhenbemaßung hinzugefügt. Dann können die internen und externen Parameter der Kamera in diesem Volumen abgetastet werden, um eine 2D-Feature-Map zu erstellen, und dann werden die 2D-Feature-Map und die internen und externen Parameter der Kamera an ein RenderNet gesendet, um die Heatmap und die Objekteigenschaften vorherzusagen die entsprechende Perspektive. Durch solche Operationen ähnlich wie bei Nerf kann eine Brücke zwischen 2D und 3D geschlagen werden.
Debiasing der Quelldomäne
Perspektivische semantische Überwachung: Basierend auf semantischem Rendering werden Heatmaps und Attribute aus verschiedenen Perspektiven gerendert (Ausgabe von RenderNet). Gleichzeitig werden die internen und externen Parameter einer Kamera zufällig abgetastet und der Objektkasten anhand dieser internen und externen Parameter aus den 3D-Koordinaten in die zweidimensionale Kameraebene projiziert. Verwenden Sie dann Fokusverlust und L1-Verlust, um die projizierte 2D-Box und die Renderergebnisse einzuschränken:
Gesamtaufsicht
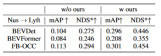
Domänenübergreifende experimentelle Ergebnisse
Zusammenfassung

Das obige ist der detaillierte Inhalt vonNeRFs Durchbruch bei der BEV-Generalisierungsleistung: Der erste domänenübergreifende Open-Source-Code implementiert Sim2Real erfolgreich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AM
Gemma Scope: Das Mikroskop von Google, um in den Denkprozess von AI zu blickenApr 17, 2025 am 11:55 AMErforschen der inneren Funktionsweise von Sprachmodellen mit Gemma -Umfang Das Verständnis der Komplexität von KI -Sprachmodellen ist eine bedeutende Herausforderung. Die Veröffentlichung von Gemma Scope durch Google, ein umfassendes Toolkit, bietet Forschern eine leistungsstarke Möglichkeit, sich einzuschütteln
 Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AM
Wer ist ein Business Intelligence Analyst und wie kann man einer werden?Apr 17, 2025 am 11:44 AMErschließung des Geschäftserfolgs: Ein Leitfaden zum Analyst für Business Intelligence -Analyst Stellen Sie sich vor, Rohdaten verwandeln in umsetzbare Erkenntnisse, die das organisatorische Wachstum vorantreiben. Dies ist die Macht eines Business Intelligence -Analysts (BI) - eine entscheidende Rolle in Gu
 Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AM
Wie füge ich eine Spalte in SQL hinzu? - Analytics VidhyaApr 17, 2025 am 11:43 AMSQL -Änderungstabellanweisung: Dynamisches Hinzufügen von Spalten zu Ihrer Datenbank Im Datenmanagement ist die Anpassungsfähigkeit von SQL von entscheidender Bedeutung. Müssen Sie Ihre Datenbankstruktur im laufenden Flug anpassen? Die Änderungstabelleerklärung ist Ihre Lösung. Diese Anleitung Details Hinzufügen von Colu
 Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AM
Business Analyst vs. Data AnalystApr 17, 2025 am 11:38 AMEinführung Stellen Sie sich ein lebhaftes Büro vor, in dem zwei Fachleute an einem kritischen Projekt zusammenarbeiten. Der Business Analyst konzentriert sich auf die Ziele des Unternehmens, die Ermittlung von Verbesserungsbereichen und die strategische Übereinstimmung mit Markttrends. Simu
 Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AM
Was sind Count und Counta in Excel? - Analytics VidhyaApr 17, 2025 am 11:34 AMExcel -Datenzählung und -analyse: Detaillierte Erläuterung von Count- und Counta -Funktionen Eine genaue Datenzählung und -analyse sind in Excel kritisch, insbesondere bei der Arbeit mit großen Datensätzen. Excel bietet eine Vielzahl von Funktionen, um dies zu erreichen. Die Funktionen von Count- und Counta sind wichtige Instrumente zum Zählen der Anzahl der Zellen unter verschiedenen Bedingungen. Obwohl beide Funktionen zum Zählen von Zellen verwendet werden, sind ihre Designziele auf verschiedene Datentypen ausgerichtet. Lassen Sie uns mit den spezifischen Details der Count- und Counta -Funktionen ausgrenzen, ihre einzigartigen Merkmale und Unterschiede hervorheben und lernen, wie Sie sie in der Datenanalyse anwenden. Überblick über die wichtigsten Punkte Graf und Cou verstehen
 Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AM
Chrome ist hier mit KI: Tag zu erleben, täglich etwas Neues !!Apr 17, 2025 am 11:29 AMDie KI -Revolution von Google Chrome: Eine personalisierte und effiziente Browsing -Erfahrung Künstliche Intelligenz (KI) verändert schnell unser tägliches Leben, und Google Chrome leitet die Anklage in der Web -Browsing -Arena. Dieser Artikel untersucht die Exciti
 Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AM
Die menschliche Seite von Ai: Wohlbefinden und VierfacheApr 17, 2025 am 11:28 AMImpacting Impact: Das vierfache Endergebnis Zu lange wurde das Gespräch von einer engen Sicht auf die Auswirkungen der KI dominiert, die sich hauptsächlich auf das Gewinn des Gewinns konzentrierte. Ein ganzheitlicherer Ansatz erkennt jedoch die Vernetzung von BU an
 5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AM
5 verwendende Anwendungsfälle für Quantum Computing, über die Sie wissen solltenApr 17, 2025 am 11:24 AMDie Dinge bewegen sich stetig zu diesem Punkt. Die Investition, die in Quantendienstleister und Startups einfließt, zeigt, dass die Industrie ihre Bedeutung versteht. Und eine wachsende Anzahl realer Anwendungsfälle entsteht, um seinen Wert zu demonstrieren


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

SublimeText3 Linux neue Version
SublimeText3 Linux neueste Version

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

