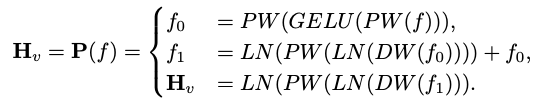Die Welle großer Modelle, die auf das mobile Endgerät kommen, wird immer stärker, und endlich hat jemand multimodale große Modelle auf das mobile Endgerät übertragen. Kürzlich haben Meituan, die Zhejiang-Universität usw. multimodale Großmodelle auf den Markt gebracht, die auf mobilen Endgeräten bereitgestellt werden können, einschließlich des gesamten Prozesses des LLM-Basistrainings, SFT und VLM. Vielleicht kann in naher Zukunft jeder bequem, schnell und kostengünstig sein eigenes Großmodell besitzen.
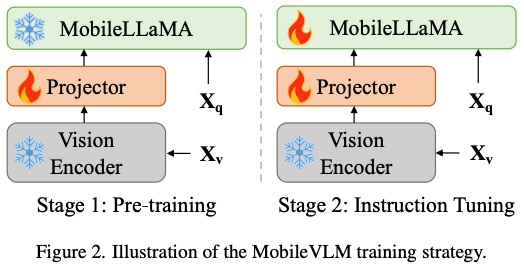
MobileVLM ist ein schneller, leistungsstarker und offener visueller Sprachassistent, der für mobile Geräte entwickelt wurde. Es kombiniert Architekturdesign und Technologie für mobile Geräte, einschließlich von Grund auf trainierter 1,4B- und 2,7B-Parameter-Sprachmodelle, multimodaler Visionsmodelle, die auf CLIP-Art vortrainiert wurden, und effiziente modalübergreifende Interaktion durch Projektion. Die Leistung von MobileVLM ist bei verschiedenen visuellen Sprachbenchmarks mit großen Modellen vergleichbar. Darüber hinaus werden die höchsten Inferenzgeschwindigkeiten auf der Qualcomm Snapdragon 888-CPU und der NVIDIA Jeston Orin-GPU erzielt. 
- Papieradresse: https://arxiv.org/pdf/2312.16886.pdf
- Codeadresse: https://github.com/Meituan-AutoML/MobileVLM
Groß angelegte multimodale Modelle (LMMs), insbesondere die Familie der visuellen Sprachmodelle (VLMs), sind aufgrund ihrer deutlich verbesserten Wahrnehmungs- und Argumentationsfähigkeiten zu einer vielversprechenden Forschungsrichtung für die Entwicklung universeller Assistenten geworden. Allerdings war es schon immer ein Problem, die Darstellungen von vorab trainierten großen Sprachmodellen (LLMs) und visuellen Modellen zu verbinden, modalübergreifende Merkmale zu extrahieren und Aufgaben wie visuelle Beantwortung von Fragen, Bilduntertitel, visuelle Wissensbegründung und Dialog zu erledigen . Die hervorragende Leistung von GPT-4V und Gemini bei dieser Aufgabe wurde vielfach bewiesen. Allerdings sind die technischen Umsetzungsdetails dieser proprietären Modelle noch wenig verstanden. Gleichzeitig hat die Forschungsgemeinschaft auch eine Reihe von Methoden zur Sprachanpassung vorgeschlagen. Flamingo nutzt beispielsweise visuelle Token, um eingefrorene Sprachmodelle durch geschlossene Queraufmerksamkeitsebenen zu konditionieren. BLIP-2 hält diese Interaktion für unzureichend und führt einen leichten Abfragetransformator (Q-Former genannt) ein, der die nützlichsten Funktionen aus dem eingefrorenen visuellen Encoder extrahiert und sie direkt in das eingefrorene LLM einspeist. MiniGPT-4 koppelt den eingefrorenen visuellen Encoder von BLIP-2 über eine Projektionsebene mit dem eingefrorenen Sprachmodell Vicuna. Darüber hinaus wendet LLaVA ein einfaches trainierbares Mapping-Netzwerk an, um visuelle Merkmale in Einbettungs-Tokens mit denselben Abmessungen wie die Worteinbettungen umzuwandeln, die vom Sprachmodell verarbeitet werden sollen. Es ist erwähnenswert, dass sich die Trainingsstrategien allmählich ändern, um sich an die Vielfalt großer multimodaler Daten anzupassen. LLaVA könnte der erste Versuch sein, das Instruktionsoptimierungsparadigma von LLM auf ein multimodales Szenario zu übertragen. Um multimodale Befehlsverfolgungsdaten zu generieren, gibt LLaVA Textinformationen, wie den Beschreibungssatz des Bildes und die Begrenzungsrahmenkoordinaten des Bildes, in das reine Sprachmodell GPT-4 ein. MiniGPT-4 wird zunächst anhand eines umfassenden Datensatzes von Bildbeschreibungssätzen trainiert und anschließend anhand eines Kalibrierungsdatensatzes von [Bild-Text]-Paaren verfeinert. InstructBLIP führt eine visuelle Sprachbefehlsoptimierung basierend auf dem vorab trainierten BLIP-2-Modell durch, und Q-Former wird anhand verschiedener Datensätze trainiert, die in einem befehlsabgestimmten Format organisiert sind. mPLUG-Owl führt eine zweistufige Trainingsstrategie ein: Trainieren Sie zunächst den visuellen Teil vor und verwenden Sie dann LoRA, um das große Sprachmodell LLaMA auf der Grundlage von Befehlsdaten aus verschiedenen Quellen zu verfeinern. Trotz der oben genannten Fortschritte von VLM besteht auch die Notwendigkeit, modalübergreifende Funktionen unter begrenzten Rechenressourcen zu nutzen. Gemini übertrifft Sota bei einer Reihe multimodaler Benchmarks und führt mobiles VLM mit 1,8B- und 3,25B-Parametern für Geräte mit geringem Speicher ein. Und Gemini nutzt auch gängige Kompressionstechniken wie Destillation und Quantisierung. Ziel dieses Artikels ist es, das erste offene VLM für Mobilgeräte zu erstellen, das mithilfe öffentlicher Datensätze und verfügbarer Technologien für visuelle Wahrnehmung und Argumentation trainiert und auf Plattformen mit eingeschränkten Ressourcen zugeschnitten ist. Die Beiträge dieses Artikels sind wie folgt:
- Dieser Artikel schlägt MobileVLM vor, eine Full-Stack-Transformation eines multimodalen visuellen Sprachmodells, das für mobile Szenarien angepasst ist. Laut den Autoren ist dies das erste visuelle Sprachmodell, das von Grund auf eine detaillierte, reproduzierbare und leistungsstarke Leistung liefert. Durch kontrollierte und Open-Source-Datensätze haben Forscher eine Reihe leistungsstarker grundlegender Sprachmodelle und multimodaler Modelle erstellt.
- Dieser Artikel führt umfangreiche Ablationsexperimente zum Design visueller Encoder durch und bewertet systematisch die Leistungsempfindlichkeit von VLMs gegenüber verschiedenen Trainingsparadigmen, Eingabeauflösungen und Modellgrößen.
- Dieser Artikel entwirft ein effizientes Zuordnungsnetzwerk zwischen visuellen Merkmalen und Textmerkmalen, das multimodale Merkmale besser ausrichten und gleichzeitig den Argumentationsverbrauch reduzieren kann.
- Das in diesem Artikel entworfene Modell kann effizient auf Mobilgeräten mit geringem Stromverbrauch laufen, mit einer gemessenen Geschwindigkeit von 21,5 Token/s auf der mobilen CPU und dem 65,5-Zoll-Prozessor von Qualcomm.
- MobileVLM und eine Vielzahl multimodaler Großmodelle schneiden bei Benchmarks gleichermaßen gut ab und beweisen ihr Einsatzpotenzial in vielen praktischen Aufgaben. Während sich dieser Artikel auf Edge-Szenarien konzentriert, übertrifft MobileVLM viele hochmoderne VLMs, die nur von leistungsstarken GPUs in der Cloud unterstützt werden können. Gesamtarchitekturdesign von LMoBilevlmo
Unter Berücksichtigung des Hauptziels, mit begrenzten Ressourcen eine effiziente visuelle Wahrnehmung und Argumentation für die Randausrüstung zu erreichen, haben Forscher die Gesamtarchitektur von Mobilevlm entworfen. Wie in Abbildung 1 dargestellt, enthält das Modell drei Komponenten: 1 ) visueller Encoder, 2) angepasstes LLM-Edge-Gerät (MobileLLaMA) und 3) effizientes Mapping-Netzwerk (im Artikel als „Lightweight Downsampling Mapping“ bezeichnet, LDP) zur Ausrichtung des visuellen und textuellen Raums.
Nehmen Sie ein Bild als Eingabe und der visuelle Encoder F_enc extrahiert daraus die visuelle Einbettung für die Bildwahrnehmung, wobei N_v = HW/P^2 die Anzahl der Bildfelder und D_v die Größe der verborgenen Ebene der visuellen Einbettung darstellt. Um das Effizienzproblem bei der Verarbeitung von Bild-Tokens zu lindern, entwarfen die Forscher ein leichtes Kartennetzwerk P für die Komprimierung visueller Merkmale und die modale Ausrichtung von visuellem Text. Es wandelt f in den Worteinbettungsraum um und stellt geeignete Eingabedimensionen für das nachfolgende Sprachmodell bereit, wie folgt:
Auf diese Weise erhalten wir die Token des Bildes und die Token des Textes, wobei N_t darstellt Der Text ist die Anzahl der Token. D_t repräsentiert die Größe des Worteinbettungsraums. Im aktuellen MLLM-Designparadigma weist LLM den größten Rechenaufwand und Speicherverbrauch auf. Aus diesem Grund stellt dieser Artikel eine Reihe von inferenzfreundlichen LLM für mobile Anwendungen vor, die erhebliche Geschwindigkeitsvorteile bieten und autoregressive Methoden durchführen können multimodale Eingabe , wobei L die Länge der Ausgabe-Tokens darstellt. Dieser Prozess kann als ausgedrückt werden. Gemäß der empirischen Analyse in Abschnitt 5.1 des Originalartikels verwendete der Forscher den vorab trainierten CLIP ViT-L/14 mit einer Auflösung von 336×336 as der visuelle Encoder F_enc . Der Visual Transformer (ViT) unterteilt das Bild in Bildblöcke einheitlicher Größe und führt eine lineare Einbettung für jeden Bildblock durch. Nach der anschließenden Integration mit der Positionskodierung wird die resultierende Vektorsequenz in den regulären Transformationskodierer eingespeist. Typischerweise werden zur Klassifizierung verwendete Token für nachfolgende Klassifizierungsaufgaben zur Sequenz hinzugefügt. Für das Sprachmodell reduziert dieser Artikel die Größe von LLaMA, um die Bereitstellung zu erleichtern. Das heißt, das in diesem Artikel vorgeschlagene Modell kann nahezu alle gängigen Inferenz-Frameworks nahtlos unterstützen. Darüber hinaus bewerteten die Forscher auch die Modelllatenz auf Edge-Geräten, um eine geeignete Modellarchitektur auszuwählen. Neural Architecture Search (NAS) ist eine gute Wahl, aber derzeit haben Forscher sie nicht sofort auf aktuelle Modelle angewendet. Tabelle 2 zeigt die detaillierten Einstellungen der Architektur dieses Dokuments. In diesem Artikel wird insbesondere der Satzstück-Tokenizer in LLaMA2 mit einer Vokabulargröße von 32000 verwendet und die Einbettungsschicht von Grund auf trainiert. Dies erleichtert die anschließende Destillation. Aufgrund begrenzter Ressourcen beträgt die von allen Modellen in der Vortrainingsphase verwendete Kontextlänge 2 KB. Wie in „Kontextfenster großer Sprachmodelle durch Positionsinterpolation erweitern“ beschrieben, kann das Kontextfenster während der Inferenz jedoch weiter auf 8 KB erweitert werden. Detaillierte Einstellungen für andere Komponenten sind wie folgt.
- RoPE anwenden, um Standortinformationen einzufügen.
- Wenden Sie eine Vornormalisierung an, um das Training zu stabilisieren. Insbesondere verwendet dieses Dokument RMSNorm anstelle der Schichtnormalisierung und das MLP-Erweiterungsverhältnis verwendet 8/3 anstelle von 4.
- Verwenden Sie die SwiGLU-Aktivierungsfunktion anstelle von GELU.
Effizientes Mapping-NetzwerkDas Mapping-Netzwerk zwischen dem visuellen Encoder und dem Sprachmodell ist entscheidend für die Ausrichtung multimodaler Funktionen. Es gibt zwei vorhandene Modi: Q-Former und MLP-Projektion. Q-Former steuert explizit die Anzahl der in jeder Abfrage enthaltenen visuellen Token, um die Extraktion der relevantesten visuellen Informationen zu erzwingen. Allerdings geht bei dieser Methode zwangsläufig die räumliche Standortinformation des Tokens verloren und die Konvergenzgeschwindigkeit ist langsam. Darüber hinaus ist es für die Inferenz auf Edge-Geräten nicht effizient. Im Gegensatz dazu behält MLP räumliche Informationen bei, enthält jedoch häufig nutzlose Token wie den Hintergrund. Für ein Bild mit einer Patchgröße von P müssen N_v = HW/P^2 visuelle Token in das LLM eingefügt werden, was die Gesamtinferenzgeschwindigkeit erheblich verringert. Inspiriert durch den bedingten Positionscodierungsalgorithmus CPVT von ViT nutzen Forscher Faltungen, um Positionsinformationen zu verbessern und lokale Interaktionen visueller Encoder zu fördern. Insbesondere haben wir mobilfreundliche Vorgänge untersucht, die auf tiefen Faltungen (der einfachsten Form von PEG) basieren und sowohl effizient sind als auch von einer Vielzahl von Edge-Geräten gut unterstützt werden. Um räumliche Informationen zu bewahren und die Rechenkosten zu minimieren, verwendet dieser Artikel eine Faltung mit einer Schrittweite von 2, wodurch die Anzahl der visuellen Token um 75 % reduziert wird. Dieses Design verbessert die Gesamtinferenzgeschwindigkeit erheblich. Experimentelle Ergebnisse zeigen jedoch, dass eine Reduzierung der Anzahl der Token-Proben die Leistung nachgelagerter Aufgaben wie OCR erheblich beeinträchtigt. Um diesen Effekt abzuschwächen, entwickelten die Forscher ein leistungsfähigeres Netzwerk als Ersatz für ein einzelnes PEG. Die detaillierte Architektur eines effizienten Mapping-Netzwerks namens Lightweight Downsampling Mapping (LDP) ist in Abbildung 2 dargestellt. Bemerkenswert ist, dass dieses Mapping-Netzwerk weniger als 20 Millionen Parameter enthält und etwa 81-mal schneller läuft als der visuelle Encoder.
Dieser Artikel verwendet „Layer-Normalisierung“ anstelle von „Batch-Normalisierung“, damit das Training nicht von der Batch-Größe beeinflusst wird. Formal nimmt LDP (bezeichnet als P) als Eingabe eine visuelle Einbettung und gibt ein effizient extrahiertes und ausgerichtetes visuelles Token aus. Die Formel lautet wie folgt: Experimentelle Ergebnisse Forscher Dieser Artikel wurde anhand des Benchmarks für natürliche Sprache überprüft Das vorgeschlagene Modell wurde umfassend anhand von zwei Benchmarks evaluiert, die jeweils auf das Sprachverständnis und das logische Denken abzielten. Bei der Bewertung des ersteren wird in diesem Artikel das Language Model Evaluation Harness verwendet. Experimentelle Ergebnisse zeigen, dass MobileLLaMA 1.4B den neuesten Open-Source-Modellen wie TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B und Pythia 1.4B ebenbürtig ist. Es ist erwähnenswert, dass MobileLLaMA 1.4B TinyLLaMA 1.1B übertrifft, das auf 2T-Level-Tokens trainiert wird und doppelt so schnell ist wie MobileLLaMA 1.4B. Auf der 3B-Ebene zeigt MobileLLaMA 2.7B auch eine vergleichbare Leistung wie INCITE 3B (V1) und OpenLLaMA 3B (V1), wie in Tabelle 5 gezeigt. Auf der Snapdragon 888-CPU ist MobileLLaMA 2.7B etwa 40 % schneller als OpenLLaMA 3B.
Vergleich mit SOTA VLM
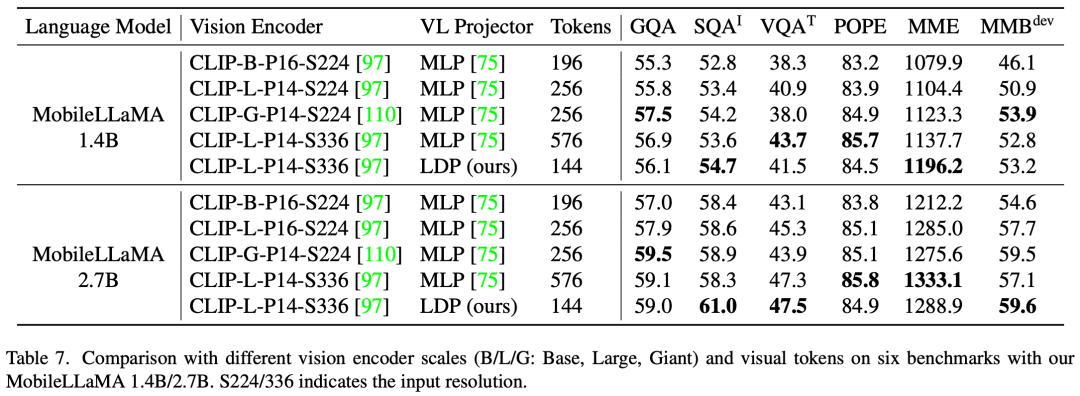
Dieses Papier bewertet die multimodale Leistung von LLaVA bei GQA, ScienceQA, TextVQA, POPE und MME. Darüber hinaus wird in diesem Artikel auch ein umfassender Vergleich mit MMBench durchgeführt. Wie in Tabelle 4 gezeigt, erreicht MobileVLM trotz reduzierter Parameter und begrenzter Trainingsdaten eine wettbewerbsfähige Leistung. In einigen Fällen übertreffen seine Metriken sogar frühere multimodale visuelle Sprachmodelle auf dem neuesten Stand der Technik. Low-Rank Adaptation (LoRA) kann die gleiche oder sogar eine bessere Leistung erzielen als ein vollständig fein abgestimmtes LLM mit weniger trainierbaren Parametern. In diesem Artikel wird eine empirische Studie dieser Praxis durchgeführt, um ihre multimodale Leistung zu validieren. Insbesondere während der Anpassungsphase der visuellen VLM-Anweisungen friert dieses Dokument alle LLM-Parameter mit Ausnahme der LoRA-Matrix ein. In MobileLLaMA 1.4B und MobileLLaMA 2.7B betragen die aktualisierten Parameter nur 8,87 % bzw. 7,41 % des gesamten LLM. Für LoRA setzt dieser Artikel lora_r auf 128 und lora_α auf 256. Die Ergebnisse sind in Tabelle 4 dargestellt. Es ist ersichtlich, dass MobileVLM mit LoRA bei 6 Benchmarks eine mit der vollständigen Feinabstimmung vergleichbare Leistung erzielt, was mit den Ergebnissen von LoRA übereinstimmt. Latenztest auf MobilgerätenDie Forscher bewerteten die Inferenzlatenz von MobileLLaMA und MobileVLM auf Realme GT-Mobiltelefonen und der NVIDIA Jetson AGX Orin-Plattform. Das Telefon wird von einem Snapdragon 888 SoC und 8 GB RAM angetrieben, was eine Rechenleistung von 26 TOPS liefert. Orin verfügt über 32 GB Arbeitsspeicher und liefert erstaunliche 275 TOPS Rechenleistung. Es nutzt CUDA Version 11.4 und unterstützt die neueste Parallel-Computing-Technologie für verbesserte Leistung. Visuelles Backbone-NetzwerkIn Tabelle 7 verglichen die Forscher die multimodale Leistung bei verschiedenen Maßstäben und unterschiedlicher Anzahl visueller Token. Alle Experimente verwendeten CLIP ViT als visuellen Encoder.
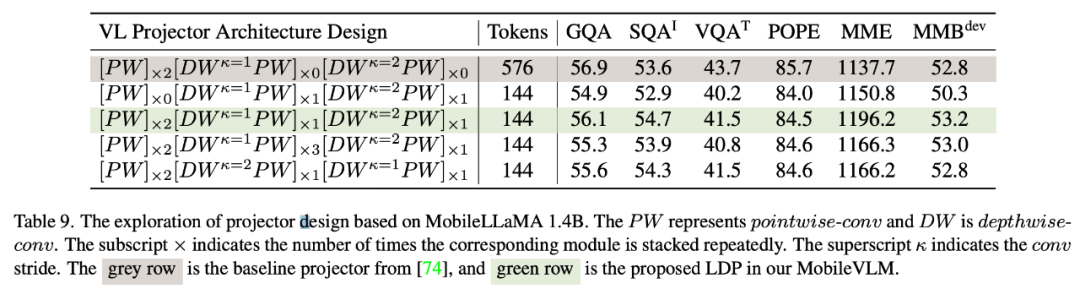
Da sowohl die Feature-Interaktion als auch die Token-Interaktion von Vorteil sind, verwendeten die Forscher für ersteres die Tiefenfaltung und für letzteres die Punktfaltung. Tabelle 9 zeigt die Leistung verschiedener VL-zugeordneter Netzwerke. Zeile 1 in Tabelle 9 ist das in LLaVA verwendete Modul, das den Merkmalsraum nur durch zwei lineare Schichten transformiert. Zeile 2 fügt vor jedem PW (punktweise) eine DW-Faltung (tiefenweise) für die Token-Interaktion hinzu, die ein 2-faches Downsampling mit einem Schritt von 2 verwendet. Das Hinzufügen von zwei Front-End-PW-Schichten führt zu mehr Interaktionen auf Funktionsebene und gleicht so den Leistungsverlust aus, der durch die Reduzierung der Token verursacht wird. Die Zeilen 4 und 5 zeigen, dass das Hinzufügen weiterer Parameter nicht den gewünschten Effekt erzielt. Die Zeilen 4 und 6 zeigen, dass das Downsampling von Tokens am Ende des Mapping-Netzwerks einen positiven Effekt hat.
Visuelle Auflösung und Anzahl der TokenDa sich die Anzahl der visuellen Token direkt auf die Inferenzgeschwindigkeit des gesamten multimodalen Modells auswirkt, werden in diesem Artikel zwei Entwurfsoptionen verglichen: Reduzieren der Eingabeauflösung (RIR ) und mit Lightweight Downsampling Projektor (LDP). Quantitative Analyse von SFT
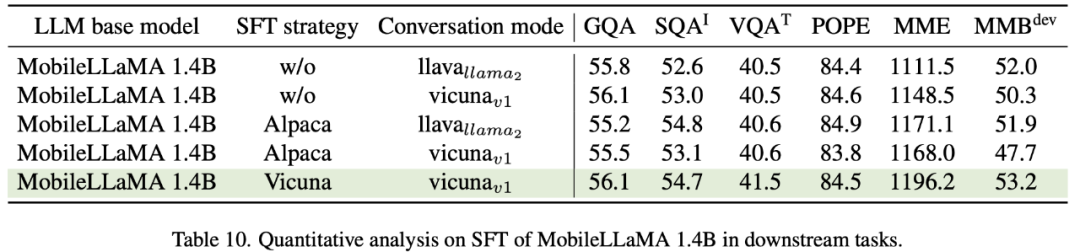
Vicuna, fein abgestimmt auf LLaMA, wird häufig für große multimodale Modelle verwendet. Tabelle 10 vergleicht zwei gängige SFT-Paradigmen, Alpaka und Vicuna. Die Forscher fanden heraus, dass sich die Ergebnisse von SQA, VQA, MME und MMBench alle deutlich verbesserten. Dies zeigt, dass die Feinabstimmung großer Sprachmodelle mithilfe von Daten aus ShareGPT im Vicuna-Konversationsmodus letztendlich die beste Leistung liefert. Um das Eingabeaufforderungsformat von SFT besser in das Training nachgelagerter Aufgaben zu integrieren, entfernt dieses Dokument den Konversationsmodus auf MobileVLM und stellt fest, dass vicunav1 die beste Leistung erbringt.
Kurz gesagt handelt es sich bei MobileVLM um eine Reihe effizienter und leistungsstarker mobiler visueller Sprachmodelle, die speziell auf Mobil- und IoT-Geräte zugeschnitten sind. In diesem Artikel werden das Sprachmodell und das visuelle Zuordnungsnetzwerk neu definiert. Die Forscher führten umfangreiche Experimente durch, um ein geeignetes visuelles Backbone-Netzwerk auszuwählen, ein effizientes Mapping-Netzwerk zu entwerfen und die Modellfähigkeiten durch Trainingslösungen wie Sprachmodell-SFT (eine zweistufige Trainingsstrategie einschließlich Vortraining und Befehlsanpassung) und LoRA-Feinanpassung zu verbessern. Tuning. Die Forscher haben die Leistung von MobileVLM anhand gängiger VLM-Benchmarks gründlich bewertet. MobileVLM zeigt auch beispiellose Geschwindigkeiten auf typischen Mobil- und IoT-Geräten. Die Forscher glauben, dass MobileVLM neue Möglichkeiten für eine Vielzahl von Anwendungen eröffnen wird, beispielsweise für multimodale Assistenten, die auf mobilen Geräten oder autonomen Fahrzeugen eingesetzt werden, sowie für Roboter mit künstlicher Intelligenz im weiteren Sinne. Das obige ist der detaillierte Inhalt vonMeituan, die Zhejiang-Universität und andere arbeiten zusammen, um ein voll prozessfähiges mobiles multimodales Großmodell MobileVLM zu entwickeln, das in Echtzeit ausgeführt werden kann und den Snapdragon 888-Prozessor verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!



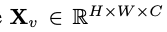 als Eingabe und der visuelle Encoder F_enc extrahiert daraus die visuelle Einbettung
als Eingabe und der visuelle Encoder F_enc extrahiert daraus die visuelle Einbettung 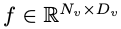 für die Bildwahrnehmung, wobei N_v = HW/P^2 die Anzahl der Bildfelder und D_v die Größe der verborgenen Ebene der visuellen Einbettung darstellt. Um das Effizienzproblem bei der Verarbeitung von Bild-Tokens zu lindern, entwarfen die Forscher ein leichtes Kartennetzwerk P für die Komprimierung visueller Merkmale und die modale Ausrichtung von visuellem Text. Es wandelt f in den Worteinbettungsraum um und stellt geeignete Eingabedimensionen für das nachfolgende Sprachmodell bereit, wie folgt:
für die Bildwahrnehmung, wobei N_v = HW/P^2 die Anzahl der Bildfelder und D_v die Größe der verborgenen Ebene der visuellen Einbettung darstellt. Um das Effizienzproblem bei der Verarbeitung von Bild-Tokens zu lindern, entwarfen die Forscher ein leichtes Kartennetzwerk P für die Komprimierung visueller Merkmale und die modale Ausrichtung von visuellem Text. Es wandelt f in den Worteinbettungsraum um und stellt geeignete Eingabedimensionen für das nachfolgende Sprachmodell bereit, wie folgt: 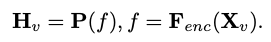
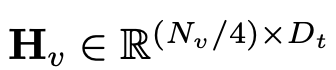 und die Token des Textes
und die Token des Textes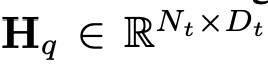 , wobei N_t darstellt Der Text ist die Anzahl der Token. D_t repräsentiert die Größe des Worteinbettungsraums. Im aktuellen MLLM-Designparadigma weist LLM den größten Rechenaufwand und Speicherverbrauch auf. Aus diesem Grund stellt dieser Artikel eine Reihe von inferenzfreundlichen LLM für mobile Anwendungen vor, die erhebliche Geschwindigkeitsvorteile bieten und autoregressive Methoden durchführen können multimodale Eingabe
, wobei N_t darstellt Der Text ist die Anzahl der Token. D_t repräsentiert die Größe des Worteinbettungsraums. Im aktuellen MLLM-Designparadigma weist LLM den größten Rechenaufwand und Speicherverbrauch auf. Aus diesem Grund stellt dieser Artikel eine Reihe von inferenzfreundlichen LLM für mobile Anwendungen vor, die erhebliche Geschwindigkeitsvorteile bieten und autoregressive Methoden durchführen können multimodale Eingabe 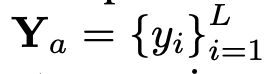 , wobei L die Länge der Ausgabe-Tokens darstellt. Dieser Prozess kann als
, wobei L die Länge der Ausgabe-Tokens darstellt. Dieser Prozess kann als 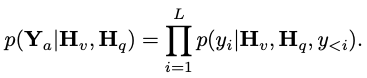 ausgedrückt werden.
ausgedrückt werden. 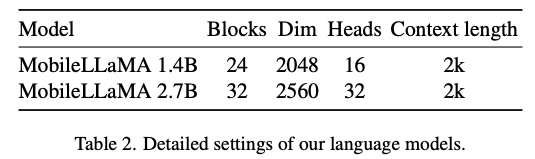
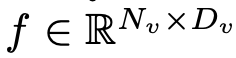 und gibt ein effizient extrahiertes und ausgerichtetes visuelles Token
und gibt ein effizient extrahiertes und ausgerichtetes visuelles Token 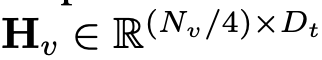 aus. Die Formel lautet wie folgt: Experimentelle Ergebnisse Forscher Dieser Artikel wurde anhand des Benchmarks für natürliche Sprache überprüft Das vorgeschlagene Modell wurde umfassend anhand von zwei Benchmarks evaluiert, die jeweils auf das Sprachverständnis und das logische Denken abzielten. Bei der Bewertung des ersteren wird in diesem Artikel das Language Model Evaluation Harness verwendet. Experimentelle Ergebnisse zeigen, dass MobileLLaMA 1.4B den neuesten Open-Source-Modellen wie TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B und Pythia 1.4B ebenbürtig ist. Es ist erwähnenswert, dass MobileLLaMA 1.4B TinyLLaMA 1.1B übertrifft, das auf 2T-Level-Tokens trainiert wird und doppelt so schnell ist wie MobileLLaMA 1.4B. Auf der 3B-Ebene zeigt MobileLLaMA 2.7B auch eine vergleichbare Leistung wie INCITE 3B (V1) und OpenLLaMA 3B (V1), wie in Tabelle 5 gezeigt. Auf der Snapdragon 888-CPU ist MobileLLaMA 2.7B etwa 40 % schneller als OpenLLaMA 3B.
aus. Die Formel lautet wie folgt: Experimentelle Ergebnisse Forscher Dieser Artikel wurde anhand des Benchmarks für natürliche Sprache überprüft Das vorgeschlagene Modell wurde umfassend anhand von zwei Benchmarks evaluiert, die jeweils auf das Sprachverständnis und das logische Denken abzielten. Bei der Bewertung des ersteren wird in diesem Artikel das Language Model Evaluation Harness verwendet. Experimentelle Ergebnisse zeigen, dass MobileLLaMA 1.4B den neuesten Open-Source-Modellen wie TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B und Pythia 1.4B ebenbürtig ist. Es ist erwähnenswert, dass MobileLLaMA 1.4B TinyLLaMA 1.1B übertrifft, das auf 2T-Level-Tokens trainiert wird und doppelt so schnell ist wie MobileLLaMA 1.4B. Auf der 3B-Ebene zeigt MobileLLaMA 2.7B auch eine vergleichbare Leistung wie INCITE 3B (V1) und OpenLLaMA 3B (V1), wie in Tabelle 5 gezeigt. Auf der Snapdragon 888-CPU ist MobileLLaMA 2.7B etwa 40 % schneller als OpenLLaMA 3B.