
Heim >System-Tutorial >LINUX >Python-Crawler analysiert die Filmkritik zu „Wolf Warrior'.
Python-Crawler analysiert die Filmkritik zu „Wolf Warrior'.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-05 21:44:121180Durchsuche
| Einführung | Seit dem 20. August, dem 25. Tag seiner Veröffentlichung, hat „Wolf Warrior II“ mehr als 5 Milliarden Yuan an den Kinokassen eingespielt und ist damit wirklich der einzige asiatische Film, der es in der Weltfilmgeschichte in die Top 100 der Kinokassen geschafft hat. In diesem Artikel werden Python-Crawler verwendet, um Daten abzurufen, Douban-Filmrezensionen zu analysieren und ein Cloud-Image der Douban-Filmrezensionen zu erstellen. Werfen wir nun einen Blick darauf, welche interessanten Untertexte sich in den Rezensionen zu „Wolf Warrior II“ verbergen. |

Abgesehen von den explosiven Einspielergebnissen löste der Film auch verschiedene Emotionen beim Publikum aus. Einige Leute sagten sogar harsch: Wer es wagt, „Wolf Warrior II“ zu kritisieren, ist entweder geistig zurückgeblieben oder ein Staatsfeind.
Jeder hat gemischte Kritiken zu „Wolf Warrior II“ abgegeben und Kommentare zu Douban hinterlassen, um seine Meinung zum Film zu äußern. Obwohl verschiedene Kommentare veröffentlicht wurden und die Medien viel Aufhebens machten, konnte das Publikum immer noch nicht sagen, welche Meinung verlässlicher war.
Bisher gab es mehr als 150.000 Kommentare. Wenn Sie die Kommentare lesen, sehen Sie möglicherweise für einen bestimmten Zeitraum entweder lobende oder abwertende Kommentare. Daher ist es schwierig, anhand der Kommentare zu sagen, wie die allgemeine Meinung aller zu diesem Film ist. Lassen Sie uns nun mithilfe der Datenanalyse herausfinden, welche interessanten Dinge in diesen Kommentaren passiert sind!
Dieser Artikel verwendet einen Python-Crawler, um Daten abzurufen, Douban-Filmrezensionen zu analysieren und ein Cloud-Image der Douban-Filmrezensionen zu erstellen. Werfen wir nun einen Blick darauf, welche interessanten Untertexte sich in den Rezensionen zu „Wolf Warrior II“ verbergen.
DatenerfassungDieser Artikel verwendet die vom Python-Crawler erhaltenen Daten. Er verwendet hauptsächlich das Anforderungspaket und das reguläre Paket re. Dieses Programm verarbeitet den Bestätigungscode nicht. Ich habe Doubans Webseite schon einmal gecrawlt. Da der gecrawlte Inhalt damals klein war, bin ich nicht auf den Bestätigungscode gestoßen. Als ich diesen Crawler schrieb, dachte ich, dass es keinen Bestätigungscode geben würde, aber als etwa 15.000 Kommentare gecrawlt wurden, tauchte der Bestätigungscode auf.
Dann dachte ich, sind es nicht nur 120.000? Ich habe den Bestätigungscode höchstens etwa ein Dutzend Mal eingegeben, sodass ich mich nicht mit dem Bestätigungscode herumschlagen musste. Aber was als nächstes passierte, war für mich etwas verwirrend. Als ich etwa 15.000 Kommentare durchsuchte und den Bestätigungscode eingab, dachte ich, dass es etwa 30.000 sein würden, aber nachdem ich etwa 3.000 gecrawlt hatte, musste ich immer noch den eingeben Bestätigungscode. .
Dann ging es einfach weiter und stolperte herum. Manchmal dauerte es lange, bis ein Bestätigungscode benötigt wurde, und manchmal auch nicht. Aber am Ende wurden die Kommentare gecrawlt. Der gecrawlte Inhalt umfasst hauptsächlich: Benutzername, ob Sie ihn gesehen haben, die Anzahl der Sterne des Kommentars, die Zeit des Kommentars, die Anzahl der Personen, die ihn nützlich fanden, und den Inhalt des Kommentars. Das Folgende ist der Code des Python-Crawlers:
Anfragen importieren<br>
re<br> importieren
Pandas als PD importieren<br>
url_first='https://movie.douban.com/subject/26363254/comments?start=0'<br>
head={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36'}<br>
html=requests.get(url_first,headers=head,cookies=cookies)<br>
Cookies={'Cookie':'Ihr eigenes Cookie'} #Das heißt, finden Sie das Cookie, das Ihrem Konto entspricht<br>
reg=re.compile(r'') #Nächste Seite<br>
ren=re.compile(r'<span>(.*?)</span>.*?comment">(.*?).*?.*?<span .>(.*?).*?<span>(.*?)</span>.* ?title="(.*?)"></span>.*?title="(.*?)">.*?class=""> (.*?)n',re.S) #Kommentare und andere Inhalte <br>
während html.status_code==200:<br>
url_next='https://movie.douban.com/subject/26363254/comments'+re.findall(reg,html.text)[0]<br>
zhanlang=re.findall(ren,html.text)<br>
data=pd.DataFrame(zhanlang)<br>
data.to_csv('/home/wajuejiprince/document/zhanlang/zhanlangpinglun.csv', header=False,index=False,mode='a+') #Schreiben Sie eine CSV-Datei, 'a+' ist der Anhängemodus<br>
data=[]<br>
zhanlang=[]<br>
html=requests.get(url_next,cookies=cookies,headers=head)
Legen Sie im obigen Code bitte Ihren eigenen Benutzeragenten, Cookie, CSV-Speicherpfad usw. fest und speichern Sie den gecrawlten Inhalt in einer Datei im CSV-Format.
Dieser Artikel verwendet die R-Sprache zum Verarbeiten von Daten. Obwohl wir beim Crawlen großen Wert auf die Struktur des gecrawlten Inhalts gelegt haben, ist es unvermeidlich, dass es einige Werte gibt, die nicht unseren Wünschen entsprechen. Beispielsweise werden einige Kommentarinhalte im Kommentatorelement angezeigt, sodass die Daten weiterhin bereinigt werden müssen.
Laden Sie zunächst alle Pakete, die Sie verwenden möchten:
Bibliothek(data.table)<br>
Bibliothek(plotly)<br>
Bibliothek(stringr)<br>
Bibliothek(jiebaR)<br>
Bibliothek(wordcloud2)<br>
Bibliothek(magrittr)
Daten importieren und bereinigen:
dt
Schauen wir uns zunächst die Kommentare anhand der Anzahl der Sterne an:
plot_ly(my_dt[,.(.N),by=.(五星数)],type = 'bar',x=~五星数,y=~N)plot_ly(my_dt[,.(.N),by=.(Fünf-Sterne-Zahl)],type = 'bar',x=~Fünf-Sterne-Zahl,y=~N)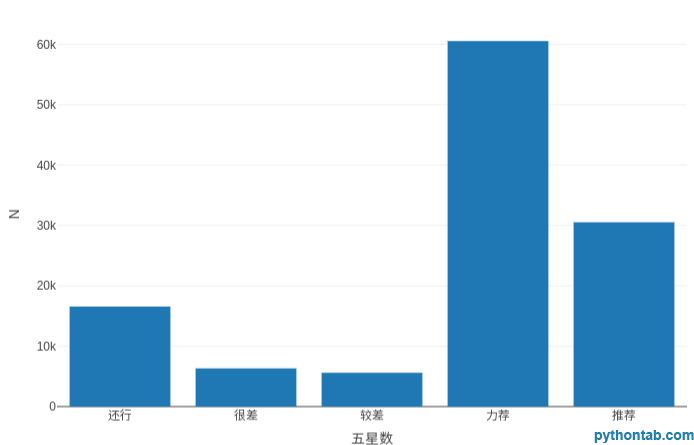
Die Anzahl der fünfzackigen Sterne entspricht 5 Stufen, 5 Sterne bedeuten sehr empfehlenswert, 4 Sterne bedeuten empfohlen, 3 Sterne bedeuten okay, 2 Sterne bedeuten schlecht und 1 Stern bedeutet sehr schlecht.
Aus den Kritiken zu Pentagram geht hervor, dass wir Grund zu der Annahme haben, dass die überwiegende Mehrheit der Zuschauer mit diesem Film zufrieden sein wird.
Zuerst sollten wir die Kommentare segmentieren:
Woche <br>
Gesamtbewertung der Wolkenanzeige: <br>
<code>Wörter%data.table()<br>
setnames(words, „N“, „pinshu“)<br>
Wörter[pinshu>1000] #Entferne Wörter mit geringerer Häufigkeit (weniger als 1000)<br>
wordcloud2(words[pinshu>1000], size = 2, fontFamily = „Microsoft Yahei“, color = „random-light“, backgroundColor = „grey“)
Da zu viele Daten vorhanden waren, fror mein kaputter Computer ein, sodass ich bei der Erstellung des Wolkendiagramms Wörter mit Häufigkeiten unter 1.000 entfernte. Die Ergebnisse des Wolkenbildes lauten wie folgt:

Alle Kommentare zu diesem Video sind insgesamt ziemlich gut! Themen wie Handlung, Action und Patriotismus stehen im Mittelpunkt der Diskussion.
Bewertungsschlüsselwörter: Wu Jing, persönlicher Heldentum, Hauptthema, China, Aura des Protagonisten, Sekretär Dakang, sehr brennend.
Man sieht, dass „Brennen“ nicht die beliebteste Reaktion nach dem Anschauen ist. Das Publikum ist mehr daran interessiert, Wu Jing selbst zu bewundern und Patriotismus und Individualismus zu kommentieren.
Wolkenbildanzeige mit verschiedenen KommentarebenenAber wie würde es aussehen, wenn die Kommentare von Personen mit unterschiedlichen Bewertungen separat angezeigt würden? Das heißt, ein Wolkendiagramm für den Überprüfungsinhalt von fünf Ebenen zu erstellen (dringend empfohlen, empfohlen, in Ordnung, schlecht, sehr schlecht). Der Code lautet wie folgt (ändern Sie einfach den Code in „dringend empfohlen“ in „Andere“).
1. Kommentarwolke mit sehr empfehlenswerten Rezensenten




Den Wortsegmentierungsergebnissen verschiedener Kommentare nach zu urteilen, haben sie alle ein gemeinsames Thema: Patriotismus.
Die Anzahl patriotischer Themen in sehr empfohlenen Kommentaren kann höher sein als in schlecht empfohlenen Kommentaren. In sehr empfohlenen Kommentaren sind die Leute eher bereit, über andere Dinge als patriotische Themen zu diskutieren. Die meisten negativen Kommentare betrafen patriotische Themen. Und ihr Anteil ist sehr interessant: Von denen, die es wärmstens empfehlen, bis hin zu denen, die schlechte Kritiken haben, nimmt der Anteil patriotischer Themen allmählich zu.
Wir können nicht subjektiv darüber nachdenken, wer Recht oder Unrecht hat. Wir können nur sagen, dass sie aus unterschiedlichen Perspektiven stehen, daher sind auch die Ergebnisse, die sie sehen, unterschiedlich. Wenn wir mit anderen nicht einverstanden sind, vertreten wir oft unterschiedliche Perspektiven. Leute mit schlechten Kommentaren denken möglicherweise mehr über patriotische Themen nach (dies ist nur eine Diskussion über patriotische Themen, nicht darüber, wer das Land liebt oder nicht mag)! !
Nach der Analyse ist der Hauptgrund, warum dieser „Wolf Warrior 2“ von so vielen Menschen unterstützt wurde, dass er in der Produktion eine Szene auf amerikanischem Blockbuster-Niveau erreicht hat, die „Wolf Warrior 1“ nicht hatte, und gleichzeitig Es hat den Patriotismus geweckt und die Herzen der Menschen erweckt.
Das obige ist der detaillierte Inhalt vonPython-Crawler analysiert die Filmkritik zu „Wolf Warrior'.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!