
Heim >System-Tutorial >LINUX >Tipps zur MySQL-Datenwiederherstellung mithilfe von IBD-Dateien?
Tipps zur MySQL-Datenwiederherstellung mithilfe von IBD-Dateien?

- PHPznach vorne
- 2024-01-02 10:42:091708Durchsuche
| Einführung | Fehlerhafte Festplattensektoren, Stromausfälle und andere Unfälle sind nicht normal, aber schon die Begegnung mit ihnen macht Sie „aufregend“! Was soll ich tun, wenn die Daten aufgrund einer Datenbankbeschädigung verloren gehen und Binlog nicht mehr verfügbar ist? Um Daten in kurzer Zeit verlustfrei wiederherzustellen und die Geschäftsstabilität zu gewährleisten, haben wir zusätzlich zur Verwendung von Binlog auch eine neue Wiederherstellungsfähigkeit geübt! |
Erinnern Sie sich daran, was wir zuvor geschrieben haben: „Nur ein Trick, um außer Kontrolle geratene Forschungs- und Entwicklungsabteilungen dazu zu bringen, sich in Sie zu verlieben“? Wie bereits erwähnt, sind die beiden Methoden zur Datenbankwiederherstellung, die wir täglich am häufigsten verwenden:
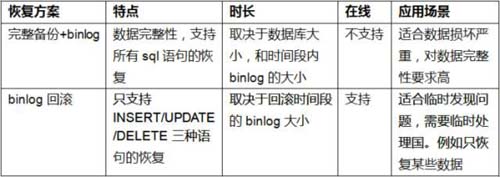
Mit beiden oben genannten Methoden kann ein Echtzeit-Rollback erreicht werden. Glauben Sie jedoch, dass diese beiden Fähigkeiten ausreichen?
Nein….!
In dieser komplizierten Online-Architektur gibt es tatsächlich viele unbekannte Gründe, die wir nicht vorhersagen können. Zum Beispiel:
Festplatten, die aufgrund harter Arbeit ihre Lebensdauer verloren haben, entwickeln fehlerhafte Sektoren, was zu Datenbankschäden führt. Und es passierte, dass die ibdata-Datei und die binlog-Datei beschädigt wurden. Wenn Sie also immer noch über die Lösung einer geplanten Sicherung + Binlog-Wiederherstellung nachdenken, ist es unmöglich, zur Wiederherstellung nur eine Festkomma-Sicherung zu verwenden. Nach sorgfältiger Überlegung werden wir als Betriebs- und Wartungspersonal niemals einen verlustbehafteten Rollback als letzten Ausweg implementieren, da dies große Auswirkungen auf das Geschäft haben wird. Aber was können wir sonst noch tun? Als nächstes werden wir einen großen Schritt veröffentlichen! ! !
Überprüfen Sie zunächst die Datenbankumgebung, um festzustellen, ob der unabhängige Tabellenbereich aktiviert ist. Herzlichen Glückwunsch, es besteht eine große Chance, dass alle Daten wiederhergestellt werden können. Wir können uns auf die FRM- und IBD-Dateien in jedem Datenbankverzeichnis verlassen, um eine Datenwiederherstellung zu erreichen. Wenn InnoDB verwendet wird, aber der unabhängige Tabellenbereich nicht aktiviert ist, werden alle Datenbanktabelleninformationen und Metadaten in die IBDATA-Datei geschrieben Bei längerer Ausführung wird die ibdata-Datei immer größer und die Datenbankleistung nimmt ab. InnoDB stellt den Parameter zum Aktivieren eines unabhängigen Tabellenbereichs bereit, der die unabhängige Speicherung von Daten ermöglicht. Auf diese Weise wird die ibdata-Datei nur zum Speichern einiger Engine-bezogener Indexinformationen verwendet, und die tatsächlichen Daten werden in unabhängige frm- und ibd-Dateien geschrieben.
Okay, mit den frm- und ibd-Dateien können wir mit der Datenwiederherstellung beginnen. Der Prozess ist spannender und interessanter als die Binlog-Wiederherstellung! Werfen wir zunächst einen Blick auf die Anweisungen zu ibd und frm:
.frm-Datei: Speichert die Metadaten jeder Tabelle, einschließlich der Definition der Tabellenstruktur usw. Diese Datei hat nichts mit der Datenbank-Engine zu tun.
.ibd-Datei: Die von der InnoDB-Engine generierte Datei, wenn der unabhängige Tabellenbereich aktiviert ist (innodb_file_per_table = 1 in my.ini), um die Daten und Indizes der Tabelle zu speichern.
Wir alle wissen, dass die Datenbank nicht erkannt wird, wenn Sie bei der InnoDB-Datenbank nicht das gesamte Datenverzeichnis, sondern nur das angegebene Datenbankverzeichnis in die neue Instanz kopieren. Wie kann man also die Datenbank basierend auf diesen beiden Dateien wiederherstellen?
Erholungsideen:Da einige Indexinformationen über die Engine in der ibdata-Datei gespeichert sind, ist die ibdata-Datei beschädigt, was dazu führt, dass der Tabellennamenindex verloren geht und nicht gestartet werden kann. Dann können wir zuerst das gesamte alte Datenverzeichnis umbenennen und sichern, dann die Datenbank neu initialisieren, um eine neue ibdata-Datei zu generieren, dann die ursprüngliche Datenbank und die entsprechenden Tabellen neu erstellen und schließlich die ID-Nummer des Sicherungstabellenbereichs in ändern neue Tabellenbereichs-ID-Nummer (die ibdata-Datei enthält eine eindeutige Tabellenbereichsindex-ID für jede Tabelle, die um die Anzahl der neu erstellten Tabellen erhöht wird), damit die ursprüngliche Datenbank wiederhergestellt werden kann.
Zum Beispiel:
Bibliotheksname: test_restore
Tabellenstruktur: db_struc.sql
Tabellendateien: G_RESTORE.ibd, G_RESTORE.frm
#mysql -uroot –p**** -e „Datenbank test_restore erstellen“
#mysql -uroot –p**** test_restore 2. Sehen und ändern Sie die ID der Tabelle in der test_restore-Bibliothek in der neuen Instanz
#vim -b /data/database/mysql/test_restore/G_RESTORE.ibd
Öffnen Sie es direkt als verstümmelte Zeichen und konvertieren Sie es zur Anzeige in Hexadezimal. Führen Sie :%!xxd in Vi aus, um in Hexadezimal zu konvertieren. Das Ergebnis ist:
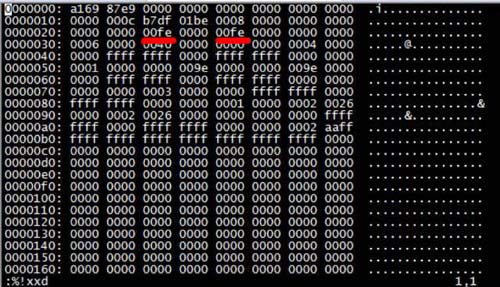
Wie im Bild gezeigt. Die ID der G_RESTORE-Tabelle in der MySQL-Datenbank ist 00fe.
Ändern Sie die gesicherte Datei G_RESTORE.ibd. Der Vorgang ist derselbe wie oben, beachten Sie jedoch, dass Sie zuerst eine Sicherungskopie erstellen müssen.
#cp G_RESTORE.ibd{,_back}
#vim -v G_RESTORE.ibd
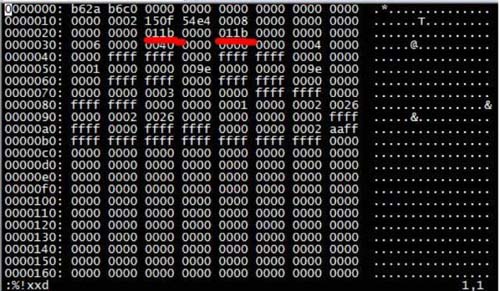
Ändern Sie 011b in 00fe. Beachten. Nachdem die Änderung abgeschlossen ist, müssen Sie sie zuerst in vim ausführen: %!xxd -r
Wq erneut, um die Datei zu speichern und zu beenden. Andernfalls wird als Ergebnis die Hexadezimalansicht gespeichert.
Speichern Sie die Ergebnisse wie folgt:
Ersetzen Sie die geänderte Datei G_RESTORE.ibd durch die Datei G_RESTORE.ibd in der neuen Datenbank.
Erklärung zur ibdata-Tabellen-ID:

参考官方文档解释,每个表空间分配了4个字节存储了表空间id信息,最后偏移量地址为38。还有一组预留的表空间id,同样是4个字节,最后偏移量地址为42。
3. 验证并还原mysql数据关闭mysql。修改my.conf。
innodb_force_recovery=6 innodb_purge_threads=0
启动数据库。如果不修改。数据库会认为G_RESTORE已被损坏。
Select 一下,即可查看到还原结果,但此时插入数据会报错,应尽快将数据dump出来 ,导回原来的实例中。
导出数据,再导入数据,恢复完毕!
#mysqldump -uroot –p****** test_restore > test_restore.sql
#mysql -uroot –p****** test_restore
<p>说明:变更了新的space id后的.ibd表文件,启动数据库后只能认出数据,但不能写入,这是因为原ibdata文件不仅保存了space id索引,还同时保存了一些其它的元数据。为了使元数据补全,所以采取导出、再导入的操作。</p>
<p>以上举例为单个库表的恢复过程,看到这里大家一定会产生另一个疑问吧?线上的场景不可能是只有一个表的,数据库表很多的情况下,这样一个个表的修改,速度无疑是太慢了。那么存在大量表的情况下如何恢复呢?思路是,取得备份的ibd文件的id值,按id值顺序来建表,中间跨度随便建表语句来凑够数(每个表空间索引id由创建新表的数量依次递增)。实现方式如下:</p>
<p><span style="color: #339966;"><strong>1. 获取备份数据库ibd文件的space id号,并排序。</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/
生成的ibd.txt文件,格式如下:(库名–表名–SpaceId)
2. 新建表,查看当前表空间id(假设space id为10)
#mysql -uroot –p****** -e”create table test.tt(a bool)”
#hexdump -C mysql/test/tt.ibd |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’
3. 先创建所有库,准备所有表结构,写脚本,依据space id号自动创建新表
准备好数据库表结构,可以从备份文件里取出来(我们备份方式是把结构和数据分开备份的),或者从其他有相同表结构的服务器上备份再拷贝过来。
参考备份语句:
mysqldump -uroot –p****** -d ${db} –T /data/backup/${db}/
创建原有的数据库:
mysql -uroot –p****** -e “create database ${db}”
恢复表id创建表脚本:
#!/bin/bash
#因为前面假设为10,所以从11开始创建
oid=11
#打开前面生成的ibd.txt文件,按行读取”库名–表名–SpaceId”
cat /tmp/ibd.txt | while read db tb id ;do
#假如我们需要恢复catetory表,他的id为415,基于id是创表自增的原则,即415-11=404,
#我们还需要循环创建404个表后,才真正导入catetory表结构。
for ((oid;oid<id do mysql table test.t bool echo ok done let oid="oid+1">
<p><span style="color: #339966;"><strong>4. 检查表空间id 和备份的是否一致</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/ibd2.txt
确认一致后,拷贝备份的.ibd文件到新数据库实例目录下,修改my.cnf
innodb_force_recovery=6
innodb_purge_threads=0
启动数据库。后续步骤如同单表恢复,直接导出恢复到原来实例中即可。
当然,这种方式是在数据库出现极端情况下,不得不采取的一种方式,线上最重要的还是做好主从同步和定时备份,从而规避此类风险。
关于InnoDB引擎独立表空间说明:使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构、表索引、表数据空间。我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作。然而当你使用InnoDB的时候,一切都变了。
InnoDB默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。通常只能将数据使用mysqldump导出,然后再导入解决这个问题。
但是可以通过修改MySQL配置文件[mysqld]部分中innodb_file_per_table的参数来开启独立表空间模式,每个数据库的每个表都会生成一个数据空间。
优点:1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
Nachteile:Der einzelne Tisch ist zu groß, z. B. mehr als 100 G.
Fazit:Gemeinsam genutzte Tabellenbereiche bieten bei Einfügevorgängen nur wenige Vorteile. Andere sind nicht so leistungsfähig wie unabhängige Tabellenbereiche. Wenn Sie unabhängige Tabellenbereiche aktivieren, passen Sie diese bitte entsprechend an: innodb_open_files.
Konfigurationsmethode:
1.innodb_file_per_table-Einstellung. So aktivieren Sie es:
Eingestellt unter [mysqld] in my.cnf
innodb_file_per_table=1
2. Prüfen Sie, ob es aktiviert ist:
mysql> zeigt Variablen wie „%per_table%“;
3. Schließen Sie den exklusiven Tischbereich
innodb_file_per_table=0 schließt den unabhängigen Tabellenbereich
mysql> Variablen wie „%per_table%“ anzeigen;
Das obige ist der detaillierte Inhalt vonTipps zur MySQL-Datenwiederherstellung mithilfe von IBD-Dateien?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!